正文内容 评论(0)

2006年10月底11月初,NVIDIA迎接DirectX 10的到来发布全新一代架构G80, 首次采用统一渲染架构(Unified Shader Architecture),是DX10时代具有革命意义的产品!
G80之前,显示芯片厂商在设计GPU时,根据常见游戏的情况将顶点管线相对放得少一些,多放一些像素渲染管线。在DX10时代,传统“管线”形式的显示芯片开始呈现出力不从心的状态,想在这种架构下提高性能,只能去提高频率,或是增加渲染管线的数目,可是以这种方法实现性能的提升却是非常痛苦的。而G80的设计是通过很多功能相同的流处理器来动态分配给各种操作,以达到每个处理单元都参与运算,从而提高效率的目的。
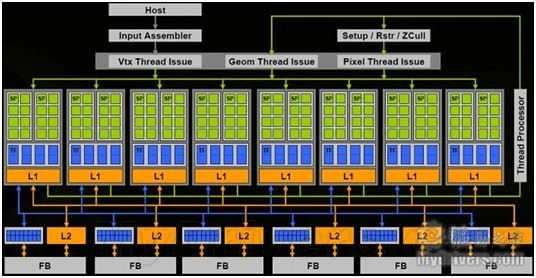
G80架构图
通过以上架构图我们可以发现,没有了Vertex Shader和PixelShader的结构,取而代之的是8组并行的单元,每个单元中有16个流处理器和8个纹理单元。而为了应对处理3D图形数据时做的大量运算,G80在现实核心集成了128个浮点运算处理器。
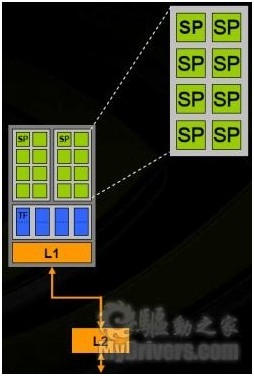
每阵列结构
另外,G80还开启了GPU计算的新时代。有关显卡的通用计算NVIDIA并不是首创,ATI在Folding@Home项目上都比NVIDIA起步要早,但在DX10统一渲染器出现之前显卡通用计算技术的发展一直处于较低水平,流处理器的出现使其有了充当CPU的可能,而在支持环境上,CUDA的出现解决了软件开发环境的问题。过去GPGPU方式使用GPU做通用计算,是使用图形API来将计算模拟为图形操作,因此在效率和便利性上都有严重的问题,而且GPGPU流式计算方法也不利于充分发挥GPU的能力。
G80在计算架构上第一次实现了统一的shader架构,增加了片内的存储空间,程序员可以把G80 GPU当成一个真正的通用处理器对待。另外,G80的每个SP都采用了标量架构,因此在通用计算上效率远胜于传统的矢量结构运算单元,配合NVIDIA CUDA C,真正实现了在GPU上运行C这样的高级语言,实现了GPU计算的全新开始。
本文收录在
#快讯
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...