正文内容 评论(0)

Fermi 是 GPU 架构的代号,而实际的 GPU 代号则是 GF100,即基于 Fermi 架构的最高端图形产品,G 在这里指图形,100 是指产品级别。GF100 GPU 具备 512 CUDA Core,是上一代 GPU GT200 的两倍以上,拥有针对 8x MSAA 加强设计的 ROP,而纹理过滤单元数量则有所削减。在画面品质方面,Fermi 引入了新的 CSAA 模式,支持 24 个 coverage 取样,最高支持 32 倍 CSAA,并且加入了 Alpha-to-Coverage 的支持,对 DX10 游戏游戏来说这是不错的好消息。

Fermi
在解读DirectX 11 中我们又提到,Tessellation 是DX11重大革命技术,在启用之后,游戏的几何体细节度将会显著增强,随之而来带来的问题是几何处理性能的需求大幅度提高。Fermi此时为其有做哪些改变呢?下面,我们就让我们再次解读Fermi架构!
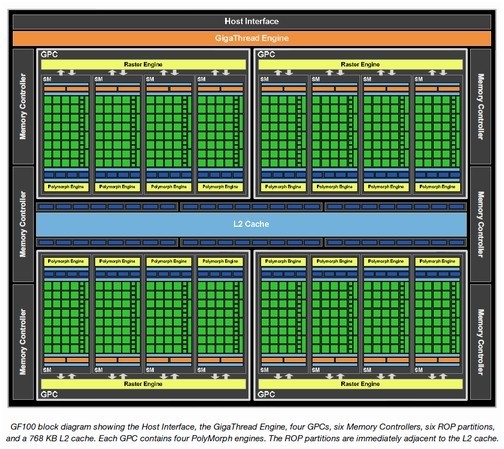
Fermi架构图
从以上Fermi架构图中可以看出,一个GPC由四组SM阵列组成,每一组SM阵列具备32个流处理器、一个PolyMorph Engine多形体引擎、16个Store单元、四个SFU单元和纹理单元、两个Warp调度器和指令发送器、能配置为48KB Shared Memory+16KB L1缓存或者16KB Shared Memory+48KB L1缓存的共享内存/L1缓存。在AMD统一渲染架构的GPU中,类似SM等级的部件是SIMD Core,例如RV870拥有20个SIMD Core。
在浮点运算方面,G80、GT200的单精度运算都是采用IEEE 754-1985标准的浮点算法,而GF100在单精度浮点指令上提供了对次常数以及IEEE754-2008标准的所有模式的支持。
l GPC
GF100被NVIDIA定义为新一代CUDA计算图形架构,并且舍弃了TPC(Texture Processing Cluster)概念,引入全新的GPC(Graphic Processing Cluster)图形处理器集群概念。GF100中的GPC由4个SM单元和1个Raster Engine引擎所组成,将顶点、几何、光栅、纹理以及像素处理资源进行有机整合。NVIDIA 在 GF100 中引入了 GPC 的设计,将 GPU 的处理单元划分为除了 ROP、内存控制器外若干相对独立的完整模块,这其实就是一个多核设计。
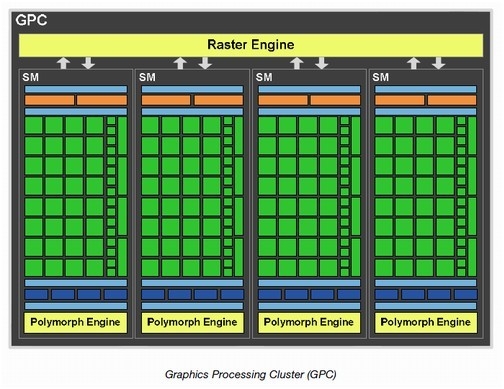
每个GPC具备一个完整的光栅引擎用来处理三角形的 setup、光栅化和 z-cull 处理,GF100 有 4 个 GPC,和同样规模的旧式架构相比,GF100 的三角形 setup 吞吐率提高了三倍,很好地满足了 DirectX 11 中新增 tessellation 支持带来的几何处理剧增问题。
l Raster Engine和Polymorph Engine
GF100 的 GPC 内拥有 4 个 SM,每个 SM 有一个 PolyMorph Engine,每个 PolyMorph Engine 具备专门的硬件用于处理顶点拾取、Tessellation、Viewport Transform、Attribute Setup、Stream Output。
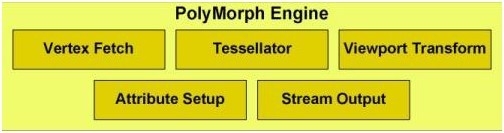
Polymorph Engine运算过程

Raster Engine运算过程
每个Polymorph Engine都拥有专属的顶点获取单元以及tessellator,很大得提高了几何性能。另外,四个并行的Raster Engine与之遥相呼应,他们在每个时钟周期内设置最多四个三角形。
l 纹理单元
在GF100中,每个SM配备了4个纹理单元,与上一代GT200以及竞争对手Crypress相比,不但没有提升反而下降了。NVIDIA认为,单纯的添加纹理单元的数量并不能有效提升GPU的纹理贴图能力。所以,在我们看到的GF100中,NVIDIA通过将纹理单元移植到SM中的设计来提升纹理单元的使用效率和时钟频率。
l Shared Memory和L1/L2 cache
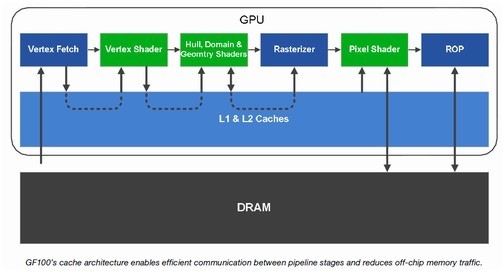
Fermi 架构的一个重要特点就是引入了可读写的 L1 cache 和 L2 cache 设计,这个设计不仅在 GPU Computing 的时候能发挥作用,在执行游戏图形的也能有所作为,例如在图形模式的时候 L1 cache 会被配置为每个 SM 具备 16KB L1 cache 作为寄存器溢出缓存,对于使用大量寄存器的游戏图形应用能发挥一定的作用。
Fermi 的可读写统一 L2 cache 被用来取代以往专门的 L2 纹理 cache、ROP cache 以及各类片上 FIFO 缓存,cache 的利用率更高,并且在整个渲染过程中都能提供减少访问主内存的动作。
l ROP单元
NVIDIA对ROP单元也进行了全新设计。GF100包含了6个ROP分区,一个分区包含了8个ROP单元,共计48个ROP单元。而GT200具备8个ROP分区,并与8个64-bit的显存控制器绑定,一个ROP分区包含了四个ROP单元。
由于要开拓 GPU Computing 市场,Fermi 引入了许多以前的 GPU 从未有过的技术,例如片上存储器 ECC,可读写 L2/L1 cache;为了加强 DirectX 11 的性能表现,引入了多 GPC 设计,这其实就是多核版 GPU 架构,即 GPU 上有多个相对独立的 GPC,能同时并行处理多个三角形,这在之前的 GPU 上是无法实现的。不难看出来,DX11的降临Fermi的应运而生,与G80相较变化非常之大。那DX11上的AMD呢?
本文收录在
#快讯
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...