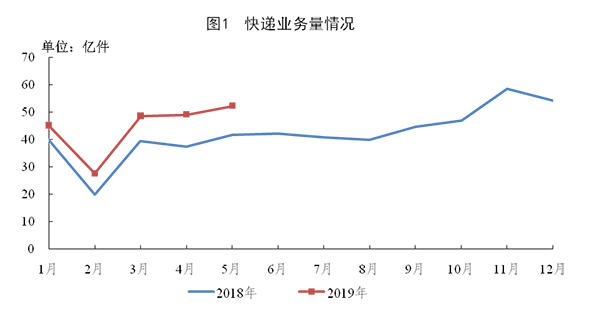
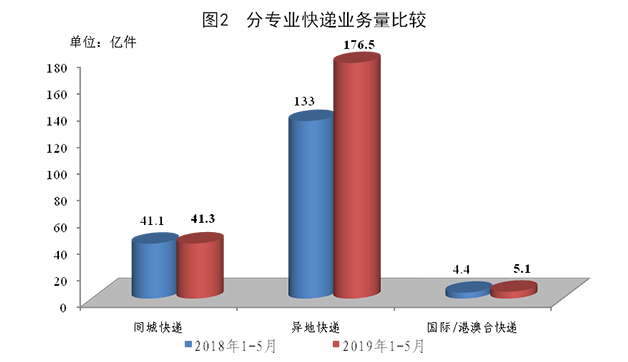
вЛФъЖрРДЃЌЮвУЧвЛжБЕыФюзХAMDЕФЯТвЛДњДІРэЦїВњЦЗЁЃаТЕФchipletЩшМЦБЛШЯЮЊЪЧдкЧ§ЖЏадФмКЭПЩРЉеЙадЗНУцЕФжиДѓЭЛЦЦЃЌЬиБ№ЪЧдкдНРДдНаЁЕФЙЄвеНкЕуЩЯжЦдьИпЦЕДѓаОЦЌБфЕУдНРДдНРЇФбЕФЧщПіЯТЁЃAMDдЄМЦНЋЭЈЙ§RyzenКЭEPYCдкЦфДІРэЦїЯЕСажаВПЪ№ЦфchipletЗЖЪНЃЌетаЉchipletУПИіЖМга8ИіЯТвЛДњZen 2КЫаФЁЃНёЬьЃЌAMDИќЯъЯИЕиНщЩмСЫZen 2КЫаФЃЌЮЊЙЋЫОЩЯжмдкComputexЩЯеЙЪОЕФБШЩЯвЛДњВњЦЗЬсИп15%ЕФЪБжгадФмЬсЙЉСЫРэгЩЁЃ

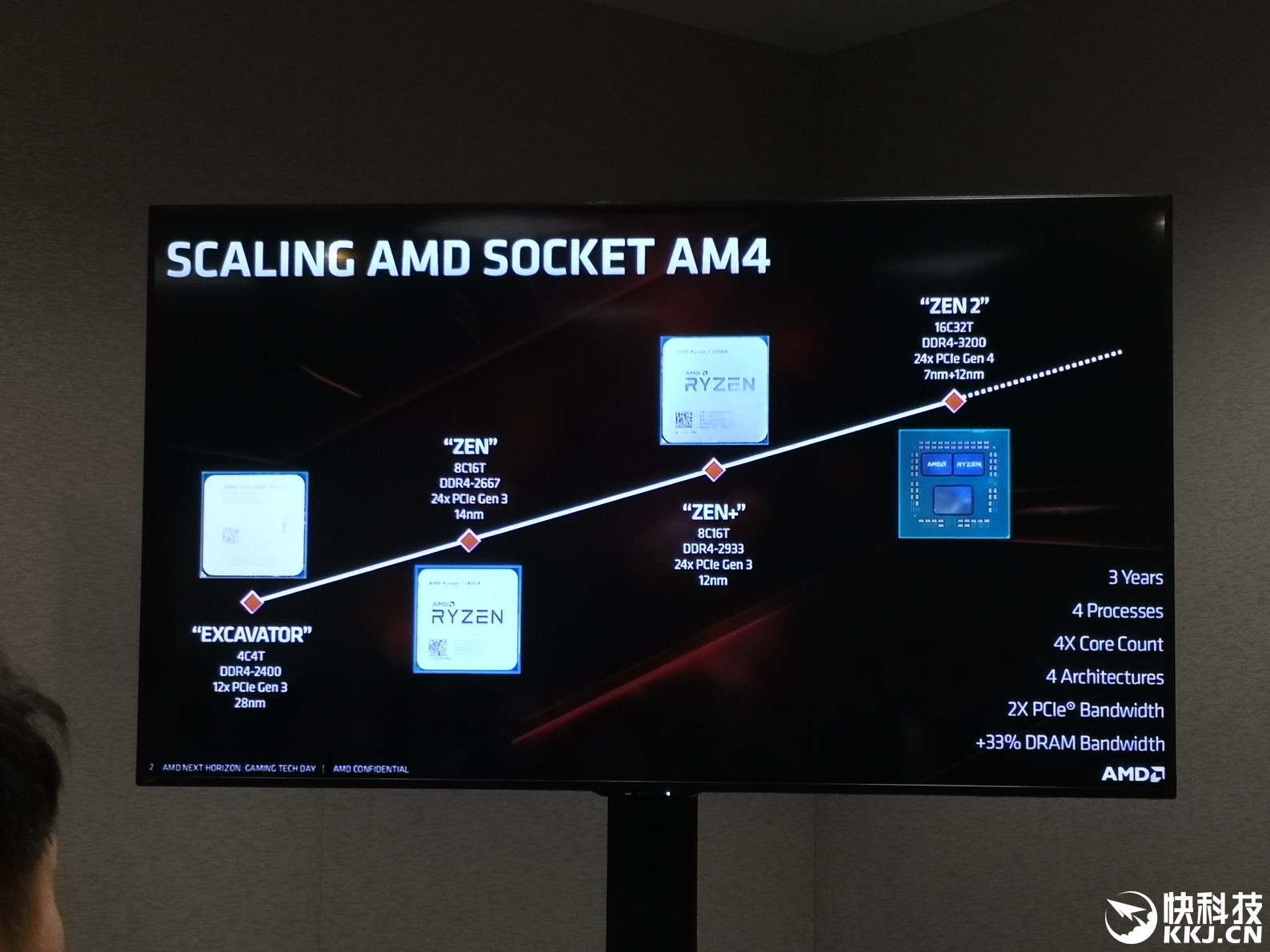
AMDЕФZen 2ВњЦЗзщКЯ
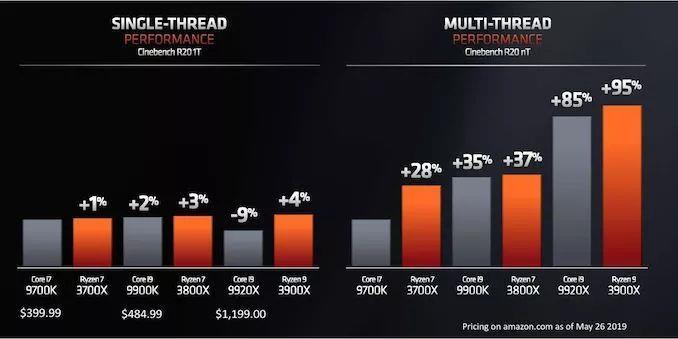
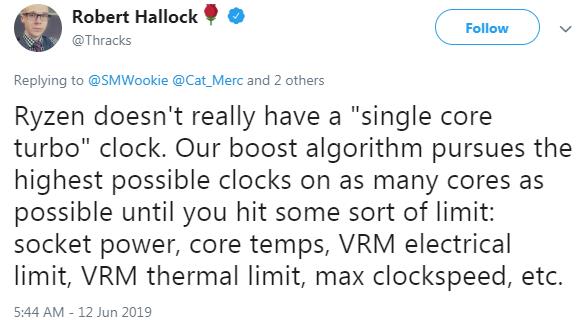
ФПЧАAMDаћВМгЕгаZen 2КЫаФЕФВњЦЗАќРЈRyzenЕкШ§ДњЯћЗбМЖCPUЃЌМДRyzen 3000ЯЕСаЃЌвдМАAMDЯТвЛДњЦѓвЕEPYCДІРэЦїЃЌМДRomeЁЃЕНФПЧАЮЊжЙЃЌAMDвбОЙЋВМСЫ6ПюЯћЗбМЖRyzen 3000ДІРэЦїЕФЯъЯИаХЯЂЃЌАќРЈКЫаФЪ§СПЁЂЦЕТЪЁЂФкДцжЇГжКЭЕчдДЁЃЙигкЗўЮёЦїДІРэЦїЕФЯИНкЃЌГ§СЫвЛаЉЗхжЕжЎЭтЃЌдЄМЦНЋдкЮДРДМИИідТЕФЪЪЕБЪБКђЙЋВМЁЃ
гыЕквЛДњZenЯрБШЃЌZen 2ЕФЩшМЦЗЖЪНвбОЗЂЩњСЫЯджјЕФБфЛЏЁЃ аТЦНЬЈКЭКЫаФЪЕЯжЪЧЮЇШЦЬЈЛ§Еч7nmЙЄвеЕФаЁаЭ8КЫchipletЩшМЦЕФЃЌГпДчдМ74~80ЦНЗНКСУзЁЃдкетаЉchipletЩЯгаСНзщЫФКЫзщГЩЕФ“КЫаФИДКЯЬх”ЃЈCCXЃЉЃЌЦфжаАќКЌет4ИіКЫаФКЭвЛзщL3ЛКДц——Zen 2ЕФL3ЛКДцЪЧ Zen 1ЕФСНБЖЁЃ
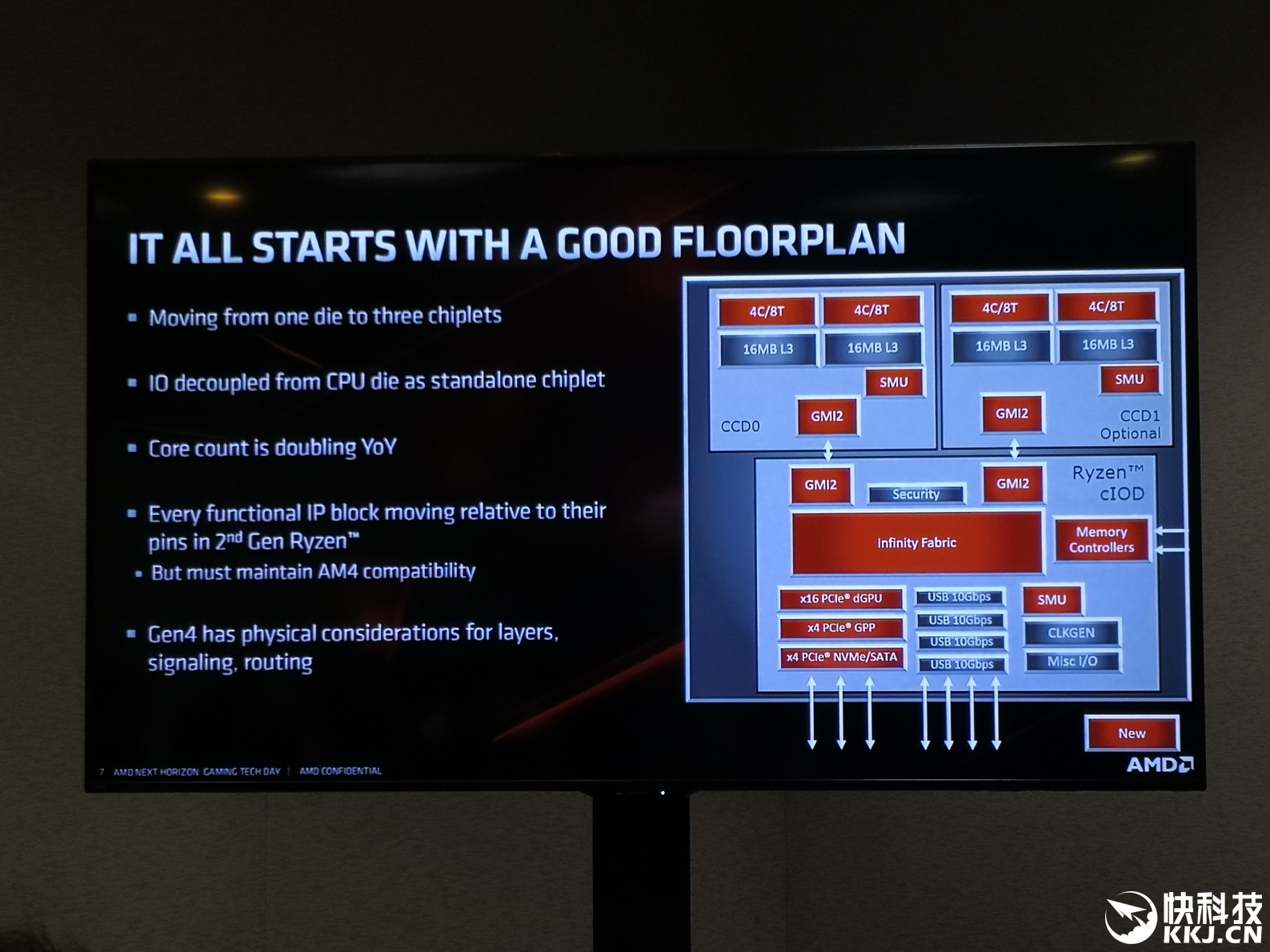
УПИіЭъећЕФCPUЃЌЮоТлЫќгаЖрЩйchipletЃЌЖМЭЈЙ§Infinity FabricСДТЗгыжабыIOаОЦЌХфЖдЁЃIOаОЦЌГфЕБЫљгаЦЌЭтЭЈаХЕФжааФЪрХІЃЌвђЮЊЫќАќКЌДІРэЦїЕФЫљгаPCIeЭЈЕРЁЂФкДцЭЈЕРЃЌвдМАгыЦфЫћchipletКЭЦфЫћCPUжЎМфЕФInfinity FabricСДТЗЁЃEPYC RomeДІРэЦїЕФIOаОЦЌЛљгкЬЈЛ§ЕчЕФ14nmЙЄвежЦдьЃЌЖјЯћЗбРрДІРэЦїIOаОЦЌЃЈЬхЛ§ИќаЁЃЌЙІФмИќЩйЃЉдђЛљгкGlobalFoundriesЕФ12nmЙЄвежЦдьЁЃ
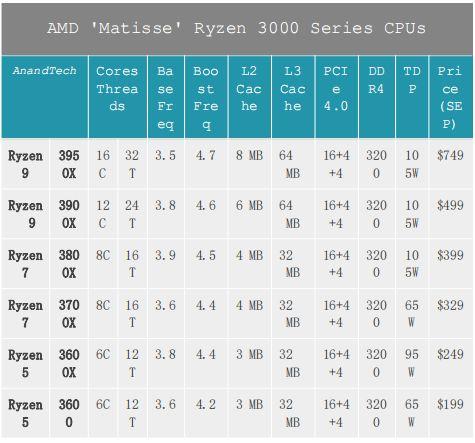
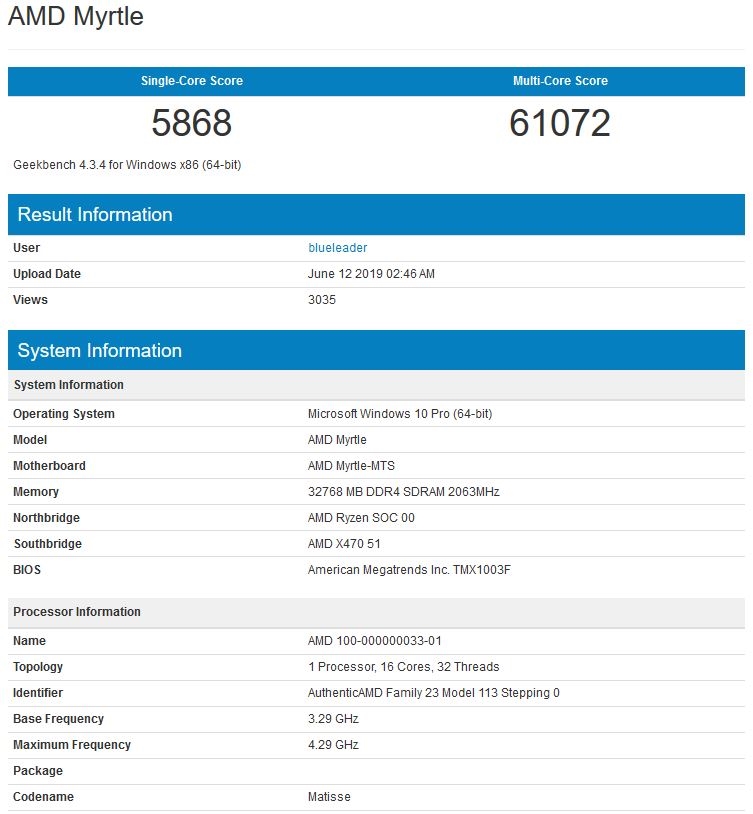
етПюУћЮЊ“Matisse”ЃЈЛђГЦRyzen 3rd GenЁЂRyzen 3000ЯЕСаЃЉЕФЯћЗбМЖДІРэЦїгЕгазюЖрСНИіchipletЃЌ16ИіФкКЫЁЃAMDНЋдк7дТ7ШеЭЦГі6ИіАцБОЕФMatisseЃЌДг6КЫЕН16КЫВЛЕШЁЃ6КЫДІРэЦїКЭ8КЫДІРэЦїгавЛИіchipletЃЌ8КЫвдЩЯЕФДІРэЦїгаСНИіchipletЃЌЕЋдкЫљгаЧщПіЯТIOаОЦЌЖМЪЧЯрЭЌЕФЁЃетвтЮЖзХУПИіЛљгкZen 2ЕФRyzen 3000ДІРэЦїЖМПЩвдЗУЮЪ24ИіPCIe 4.0ЭЈЕРКЭЫЋЭЈЕРФкДцЁЃИљОнНёЬьЕФЙЋИцЃЌRyzen 5 3600ЕФМлИёНЋДг199УРдЊЕН16КЫЕФ700УРдЊвдЩЯЃЈЮвУЧе§дкЕШД§етИіМлИёЕФзюжеШЗШЯЃЉЁЃ

ЛљгкZen 2 chipletЙЙНЈЕФEPYC RomeДІРэЦїгЕгаЖрДя8ИіДІРэЦїЃЌЪЙвЛИіЦНЬЈПЩвджЇГжЖрДя64ИіКЫаФЁЃгыЯћЗбМЖДІРэЦївЛбљЃЌchipletВЛПЩвджБНгЯрЛЅЭЈаХ——УПИіchipletжЛФмжБНгСЌНгЕНжабыIOаОЦЌЁЃIOаОЦЌАќКЌ8ИіФкДцЭЈЕРЕФСДТЗЃЌвдМАЖрДя128ИіPCIe 4.0СЌНгЭЈЕРЁЃ
AMDЕФТЗЯпЭМ
дкЬжТлаТВњЦЗЯпжЎЧАЃЌгаБивЊЛиЙЫвЛЯТЮвУЧФПЧАдкAMDЕФМЦЛЎТЗЯпЭМжаЫљДІЕФЮЛжУЁЃ

AMDжЎЧАЕФТЗЯпЭМеЙЪОСЫДгZenЕНZen 2ЁЂZen 3ЕФзЊБфЃЌAMDНтЪЭЫЕЃЌетИіНсЙЙвбгаЖрФъЃЌ2017ФъЗЂВМZenЃЌ2019ФъЗЂВМZen 2ЃЌ2021ФъЗЂВМZen 3ЁЃНкзрВЂВЛЭъШЋЪЧвЛФъвЛДњЃЌвђЮЊетвРРЕгкAMDЕФЩшМЦКЭжЦдьФмСІЃЌвдМАгыДњЙЄГЇКЯзїЛяАщЕФавщКЭЕБЧАЕФЪаГЁСІСПЁЃ
AMDдјБэЪОЃЌZen 2ЕФМЦЛЎЪМжеЪЧдк7nmЙЄвеЩЯЭЦГіЃЌзюжеЪЙгУЬЈЛ§ЕчЕФ7nmжЦГЬЃЈGlobal FoundriesЮДФмМАЪБзМБИКУ7nmЙЄвеЃЌВЂзюжеЗХЦњСЫетвЛМЦЛЎЃЉЁЃЯТвЛДњZen 3дЄМЦНЋгыИќаТЕФ7nmЙЄвеБЃГжвЛжТЃЌФПЧАAMDЩаЮДЖдЧБдкЕФ“Zen 2+”ЩшМЦЗЂБэШЮКЮЦРТлЃЌОЁЙмФПЧАЮвУЧВЂВЛЦкЭћПДЕНЫќЁЃ

Г§СЫZen 3жЎЭтЃЌAMDвбОЩљУїZen 4КЭZen 5ФПЧАе§ДІгкИїздЩшМЦЕФВЛЭЌНзЖЮЃЌЕЋЪЧAMDУЛгаГаХЕЬиЖЈЕФЪБМфПђМмЛђЙЄвеНкЕуММЪѕЁЃAMDЙ§ШЅдјБэЪОЃЌетаЉЦНЬЈКЭДІРэЦїЩшМЦЕФЗЖЪНЖМЪЧЬсЧА3~5ФъжЦЖЈЕФЃЌЙЋЫОБиаыдкУПвЛДњВњЦЗЩЯЖМЯТДѓЖФзЂЃЌвдШЗБЃздМКФмЙЛБЃГжОКељСІЁЃ
ЮЊСЫЩюШыСЫНтZen 4ЃЌдкComputexЩЯЃЌAMDЧЖШыЪНКЭАыЖЈжЦзщЕФИпМЖИБзмВУForrest NorrodдкВЩЗУжаЯђAnandTechЖРМвЭИТЖСЫAMD Zen 4 EPYCДІРэЦїЕФДњКХЃКGenoaЁЃ
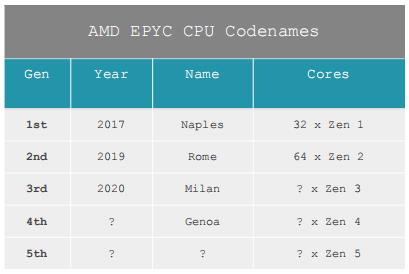
ForrestНтЪЭЫЕЃЌZen 5ЕФДњКХзёбРрЫЦЕФФЃЪНЃЌЕЋЫћВЛдИЖдZen 4ВњЦЗЕФЪБМфПђМмЗЂБэЦРТлЁЃМјгкZen 3ЕФЩшМЦдЄМЦНЋдк2020ФъФъжаЭЦГіЃЌШчЙћAMDзёбетвЛНкзрЃЌФЧУДZen 4НЋдк2021ФъФЉ/2022ФъГѕЭЦГіЁЃФПЧАЛЙВЛЧхГўЫќНЋШчКЮНјШыAMDЕФЯћЗбМЖТЗЯпЭММЦЛЎЃЌЫќНЋШЁОігкAMDШчКЮНгНќЦфаОЦЌЗЖЪНКЭЮДРДЖдЗтзАММЪѕЕФЕїећЃЌвдЪЕЯжНјвЛВНЕФадФмИФНјЁЃ
Zen 2ЕФадФмЩљУї
дкComputexЩЯЃЌAMDаћВМЫћУЧвбОЩшМЦГіСЫZen 2ЃЌЕББШНЯЯрЭЌЦЕТЪЕФZen 2КЭZen+ЪБЃЌZen 2ПЩвдЬсЙЉБШZen+ЦНЬЈИп15%ЕФдЪМадФмЁЃгыДЫЭЌЪБЃЌAMDЛЙЩљГЦЃЌдкЯрЭЌЕФЙІТЪЯТЃЌZen 2ПЩвдЬсЙЉ1.25БЖвдЩЯЕФадФмдівцЃЌЛђдкЭЌбљЕФадФмЯТжЛгавЛАыЕФЙІКФЁЃНсКЯетвЛЕуЃЌОЭЬиЖЈЛљзМЖјбдЃЌAMDЩљГЦЦфУПЭпадФмБШЦфЩЯвЛДњВњЦЗИп75%ЃЌБШОКељЖдЪжИп45%ЁЃ
етаЉЪ§зжЮвУЧФПЧАЮоЗЈКЫЪЕЃЌвђЮЊЮвУЧЪжЭЗУЛгаЯрЙиВњЦЗЃЌЕБ7дТ7ШеНћСюНтГ§ЪБЃЌЮвУЧЛсШЗЖЈЛљзМВтЪдНсЙћЁЃAMDШЗЪЕЛЈСЫДѓСПЕФЪБМфРДбаОПZen 2ЮЂМмЙЙЕФаТБфЛЏЃЌвдМАЦНЬЈМЖБ№ЕФБфЛЏЃЌвдеЙЪОИУВњЦЗгыЩЯвЛДњВњЦЗЯрБШЪЧШчКЮИФНјЕФЁЃ
ЛЙгІИУзЂвтЕФЪЧЃЌдкAMDзюНќЕФММЪѕШеЦкМфЃЌИУЙЋЫОЖрДЮБэЪОЃЌЫћУЧЮовтгыжївЊОКељЖдЪждкНЅНјЪНИќаТЩЯЗДИДРОтЃЌЪдЭМДђАмЖдЗНЃЌетПЩФмЛсЕМжТММЪѕЭЃжЭВЛЧАЁЃAMDЕФИпЙмУЧБэЪОЃЌЮоТлОКељЖдЪжЪЧЫЃЌAMDЖМНЋНпОЁЫљФмЕиЬєеНУПвЛДњВњЦЗЕФадФмМЋЯоЁЃЪзЯЏжДааЙйLisa SuВЉЪПКЭЪзЯЏММЪѕЙйMark PapermasterЖМБэЪОЃЌЫћУЧдЄМЦZen 2ВњЦЗзщКЯЭЦГіЕФЪБМфБэНЋгыОКељМЄСвЕФгЂЬиЖћ10nmВњЦЗЯпНЛВцЁЃОЁЙмЧщПіВЂЗЧШчДЫЃЌAMDЕФИпЙмУЧБэЪОЃЌЫћУЧШддкАДМЦЛЎЭЦНјЫћУЧЕФТЗЯпЭМЁЃ
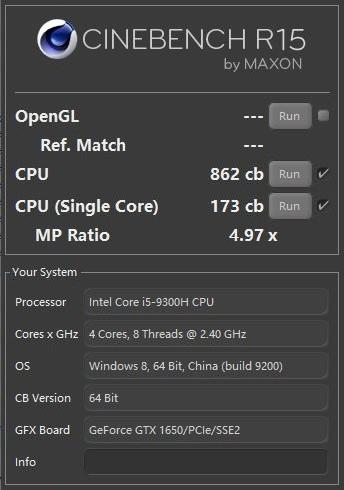
AMDдкеЙЪОЦфМДНЋЭЦГіЕФMatisseДІРэЦїЕФадФмЪБЃЌбЁдёЕФЛљзМЪЧCinebenchЁЃCinebenchЪЧвЛжжИЁЕуЛљзМВтЪдЃЌИУЙЋЫОдкетЗНУцвЛжБзіЕУКмКУЃЌЫќЧуЯђгкМьВтCPU FPадФмвдМАЛКДцадФмЃЌОЁЙмЫќЭЈГЃВЛЩцМАКмЖрФкДцзгЯЕЭГЁЃ
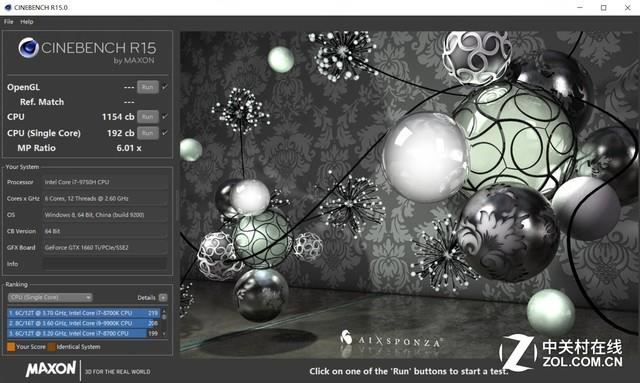
дчдкНёФъ1дТЕФCES 2019ЩЯЃЌAMDОЭеЙЪОСЫвЛПюЮДУќУћЕФ8КЫZen 2ДІРэЦїЃЌгыгЂЬиЖћЕФИпЖЫ8КЫДІРэЦїi9-9900KЯрБШЃЌЖўепдкCinebench R15ЩЯЕФЯЕЭГЕУЗжДѓжТЯрЭЌЃЌЕЋAMDШЋЯЕЭГЕФКФЕчСПдМЮЊгЂЬиЖћЕФ1/3ЛђИќЩйЁЃдк5дТЗнЕФComputexЩЯЃЌAMDЙЋВМСЫКмЖр8КЫКЭ12КЫЕФЯИНкЃЌвдМАетаЉаОЦЌдкЕЅЯпГЬКЭЖрЯпГЬCinebench R20НсЙћжаЕФБШНЯЁЃ
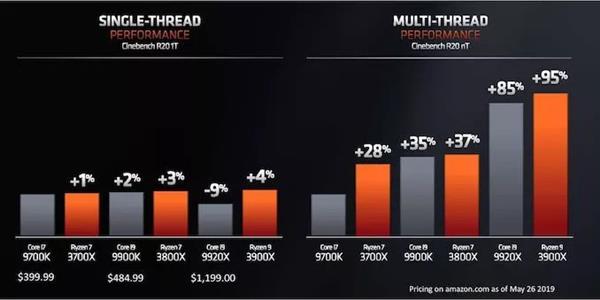
AMDБэЪОЃЌдкБШНЯВЛЭЌФкКЫЪ§СПЪБЃЌЫќЕФаТДІРэЦїдкCPUЛљзМВтЪдЗНУцЬсЙЉСЫИќКУЕФЕЅЯпГЬадФмЁЂИќКУЕФЖрЯпГЬадФмЁЂИќЕЭЕФЙІКФКЭИќЕЭЕФМлИёЁЃ
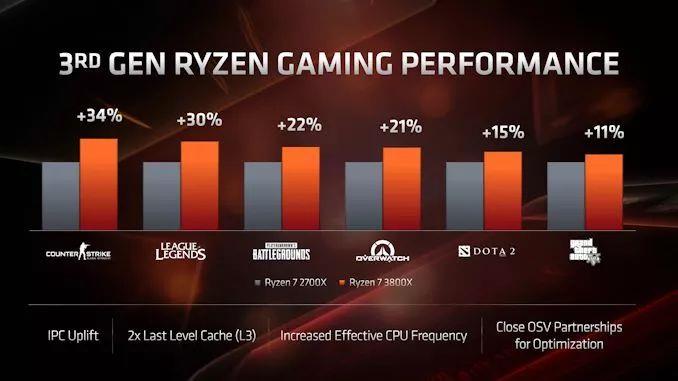
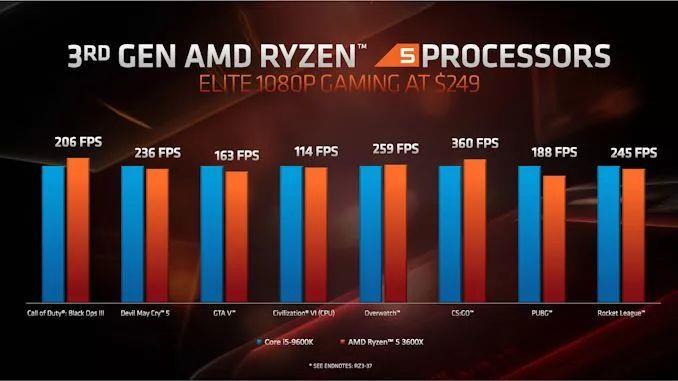
ЬИЕНгЮЯЗЃЌAMDдкетЗНУцЯрЕБРжЙлЁЃ дк1080pЪБЃЌНЋRyzen 7 2700XгыRyzen 7 3800XНјааБШНЯЃЌAMDЯЃЭћжЁЫйТЪУПвЛДњЖМФмга11%~34%ЕФдіГЄЁЃ
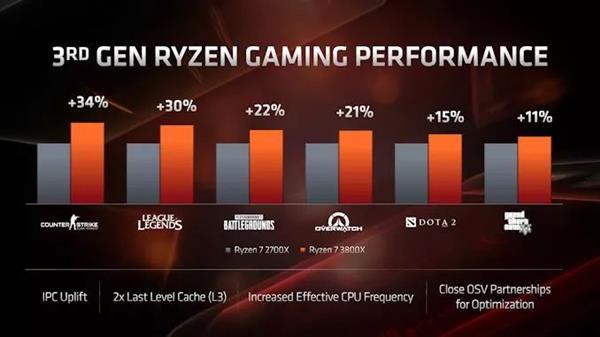
дкБШНЯAMDКЭгЂЬиЖћДІРэЦїЪБЃЌAMDМсГжЖдШШУХгЮЯЗНјаа1080pВтЪдЃЌдйДЮБШНЯКЫаФЪ§СПКЭМлИёРрЫЦЕФДІРэЦїЁЃдкМИКѕЫљгаЕФБШНЯжаЃЌAMDЕФВњЦЗКЭгЂЬиЖћЕФВњЦЗЖМВЛЯрЩЯЯТЃЌAMDгаЕФИпаЉЃЌгаЕФЕЭаЉЃЌЛђЦНЗжЧяЩЋЁЃвдЯТвд250УРдЊВњЦЗЮЊР§НјааБШНЯЃК
ДЫЪБЃЌгЮЯЗадФмжМдкеЙЪОЦЕТЪКЭIPCЕФИФНјЃЌЖјВЛЪЧеЙЪОPCIe 4.0ДјРДЕФКУДІЁЃдкЦЕТЪЗНУцЃЌAMDБэЪОЃЌОЁЙм7nmаОЦЌГпДчЫѕаЁЧвЭЈТЗЕчзшТЪНЯИпЃЌЕЋгыGlobalFoundriesЕФ14nmКЭ12nmЯрБШЃЌЫќУЧФмЙЛДгЬЈЛ§Еч7nmЙЄвежаЛёЕУИќИпЕФЦЕТЪЁЃ

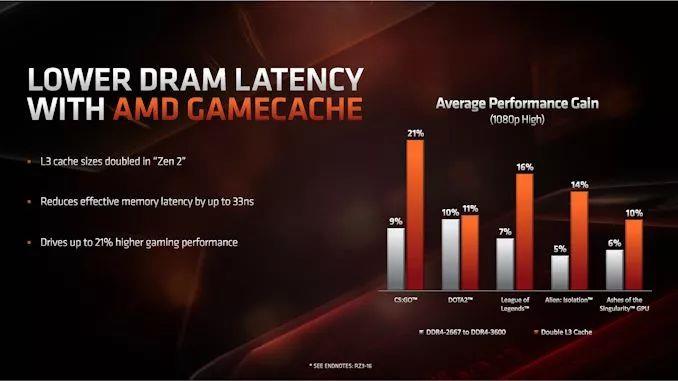
AMDЛЙЦРТлСЫаТЕФL3ЛКДцЩшМЦЃЌвђЮЊЫќДг2MB/КЫаФБфГЩСЫ4MB/КЫаФЁЃОнAMDГЦЃЌL3ЛКДцЗСЫвЛБЖЃЌЪЙгУЖРСЂGPUНјаагЮЯЗЪБЃЌ1080pЕФадФмЬсЩ§СЫ11ЃЅ~21ЃЅЁЃ
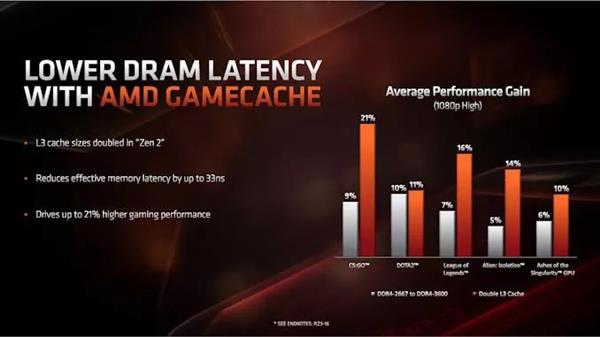
Zen 2жагавЛаЉаТжИСюПЩвдАяжњбщжЄетаЉЪ§зжЁЃ
WindowsгХЛЏ
ЖдгкЪЙгУWindowsЕФЗЧгЂЬиЖћДІРэЦїЖјбдЃЌвЛИіСюШЫЭЗЬлЕФЙиМќЮЪЬтЪЧВйзїЯЕЭГжаЕФгХЛЏКЭЕїЖШГЬађАВХХЁЃЮвУЧдкЙ§ШЅвбОПДЕНWindowsЖдЗЧгЂЬиЖћЮЂМмЙЙВМОжЪЧЖрУДЕиВЛгбКУЃЌР§ШчAMDвдЧАдкBulldozerжаЕФФЃПщЩшМЦЁЂИпЭЈдкSnapdraonЩЯЪЙгУЕФЛьКЯCPUВпТдЃЌвдМАзюНќдкThreadripperЩЯНјааЕФЖраОЦЌАВХХЃЌвдБуНЋВЛЭЌЕФФкДцбгГйгђв§ШыЯћЗбМЖМЦЫуЁЃ
ЯдШЛЃЌAMDгыЮЂШэгаУмЧаЕФЙиЯЕЃЌЕБЩцМАЕНЪЖБ№ДІРэЦїЕФЗЧГЃЙцКЫаФЭиЦЫЪБЃЌетСНМвЙЋЫОжТСІгкШЗБЃЯпГЬКЭФкДцЗжХфЃЌУЛгаГЬађЧ§ЖЏЕФЗНЯђЃЌЪдЭМзюДѓЯоЖШЕиРћгУЯЕЭГЁЃЫцзХ5дТ10ШеWindowsЕФИќаТЃЌвЛаЉЖюЭтЕФЙІФмвбОЕНЮЛЃЌвдГфЗжРћгУМДНЋЕНРДЕФZen 2ЮЂМмЙЙКЭRyzen 3000аОЦЌВМОжЁЃ

гХЛЏгаСНЗНУцЃЌетСНЗНУцЖМКмШнвзНтЪЭЁЃ
ЯпГЬЗжзщ
ЕквЛИіЪЧЯпГЬЗжХфЁЃЕБДІРэЦїОпгаВЛЭЌЕФCPUКЫаФ“зщ”ЪБЃЌЗжХфЯпГЬЕФЗНЪНвВОЭВЛЭЌЃЌЫљгаетаЉЗНЗЈЖМгаИїздЕФгХШБЕуЁЃЯпГЬЗжХфЕФСНИіМЋЖЫЙщНсЮЊЯпГЬЗжзщКЭЯпГЬРЉеЙЁЃ

ЯпГЬЗжзщЪЧЕБаТЯпГЬЩњГЩЪБЃЌЫќУЧНЋБЛжБНгЗжХфЕНвбОгЕгаЯпГЬЕФФкКЫХдБпЕФФкКЫЩЯЁЃетЪЙЯпГЬНєУмНсКЯдквЛЦ№ЃЌгУгкЯпГЬЕНЯпГЬЕФЭЈаХЃЌЕЋЪЧЫќПЩвдДДНЈИпЙІТЪУмЖШЕФЧјгђЃЌЬиБ№ЪЧЕБДІРэЦїЩЯгаЖрИіФкКЫЕЋжЛгаМИИіДІгкЛюЖЏзДЬЌЕФЪБКђЁЃ
ЯпГЬРЉеЙЪЧжИФкКЫБЫДЫЗХжУЕУОЁПЩФмдЖЁЃетвтЮЖзХЕкЖўИіЯпГЬОЁПЩФмдЖЕидкВЛЭЌЕФchipletЛђВЛЭЌЕФКЫаФИДКЯЬхЃЈCCXЃЉЩЯВњЩњЁЃетдЪаэCPUЭЈЙ§УЛгаИпЙІТЪУмЖШЕФЧјгђРДБЃГжИпадФмЃЌЭЈГЃдкЖрИіЯпГЬЩЯЬсЙЉзюМбЕФturboадФмЁЃ
ЯпГЬРЉеЙЕФЮЃЯедкгкЃЌЕБвЛИіГЬађЩњГЩСНИіЯпГЬЃЌЖјетСНИіЯпГЬзюжеЮЛгкCPUЕФВЛЭЌЮЛжУЕФЪБКђЁЃдкThreadrapperжаЃЌетЩѕжСПЩФмвтЮЖзХЕкЖўИіЯпГЬЮЛгкCPUЕФвЛИіОпгаНЯГЄФкДцбгГйЕФВПЗжЃЌДгЖјЕМжТСНИіЯпГЬжЎМфЕФЧБдкадФмВЛЦНКтЃЌМДБуетаЉЯпГЬЫљдкЕФФкКЫДІгкНЯИпЕФturboЦЕТЪЁЃ
гЩгкЯжДњШэМўЃЈЬиБ№ЪЧЪгЦЕгЮЯЗЃЉе§дкВњЩњЖрЯпГЬЖјВЛЪЧвРРЕЕЅИіЯпГЬЃЌВЂЧветаЉЯпГЬашвЊЯрЛЅЭЈаХЃЌAMDе§дкДгЛьКЯЯпГЬРЉеЙММЪѕзЊЯђЯпГЬЗжзщММЪѕЁЃетвтЮЖзХдкЗУЮЪСэвЛИіCCXжЎЧАЃЌвЛИіCCXНЋБЛЯпГЬЬюТњЁЃAMDШЯЮЊЃЌОЁЙмвЛИіchipletжаОпгаИпЙІТЪУмЖШЕФЧБСІЃЌЖјСэвЛИіПЩФмДІгкЗЧЛюЖЏзДЬЌЃЌЕЋЖдгкећЬхадФмЖјбдЃЌетШдШЛЪЧжЕЕУЕФЁЃ
ЖдгкMatisseЖјбдЃЌетгІИУПЩвдЮЊгаЯоЕФЯпГЬГЁОАЬсЙЉвЛИіКмКУЕФИФНјЁЃПДПДетЖдМДНЋЕНРДЕФEPYC Rome CPUЛђЮДРДЕФThreadripperЩшМЦгаЖрДѓгАЯьНЋЛсКмгаШЄЁЃAMDдкЦфНтЪЭжаЬсЙЉЕФЕЅвЛЛљзМЪЧ1080p LowЕФЁЖЛ№М§СЊУЫЁЗЃЌБЈИцГЦжЁЫйТЪдіМгСЫ15ЃЅЁЃ
ЪБжгЬсЩ§
ЖдгкЪьЯЄSkylakeЮЂМмЙЙЕФгУЛЇРДЫЕЃЌФуПЩФмЛЙМЧЕУгЂЬиЖћЭЦГіСЫвЛЯюУћЮЊSpeed ShiftЕФаТЙІФмЃЌЪЙДІРэЦїФмЙЛИќздгЩЕидкВЛЭЌPзДЬЌжЎМфНјааЕїећЃЌвдМАЗЧГЃПьЫйЕиДгПеЯаЕїећЕНИКди——SkylakeЕФЕквЛИіАцБОДг100КСУыЕН40КСУыЃЌШЛКѓKaby LakeЯТНЕЕН15КСУыЁЃЫќЭЈЙ§НЋPзДЬЌПижЦДгВйзїЯЕЭГЗЕЛиИјДІРэЦїРДЪЕЯжетвЛЕуЃЌДІРэЦїИљОнжИСюЭЬЭТСПКЭЧыЧѓзіГіЗДгІЁЃдкZen 2жаЃЌAMDЯждкЪЕЯжСЫЯрЭЌЕФЙІФмЁЃ

ЯрБШгкгЂЬиЖћЃЌAMDдкЦЕТЪЕїећЗНУцвбООпгазуЙЛЕФСЃЖШЃЌдЪаэ25MHzЖјВЛЪЧ100MHzЕФВювьЃЌЕЋЪЧЃЌЕБЩцМАЗЧГЃЭЛЗЂЧ§ЖЏЕФЙЄзїИКдиЃЈburst-driven workloadЃЉЪБЃЌФмЙЛЪЕЯжИќПьЕФramp-to-loadЦЕТЪЬјБфНЋИјAMDДјРДАяжњЃЌР§ШчWebXPRTЃЈгЂЬиЖћзюЯВЛЖетжжбнЪОЃЉЁЃИљОнAMDЕФЫЕЗЈЃЌЪЙгУZen 2ЪЕЯжетвЛЙІФмЕФЗНЪННЋашвЊBIOSИќаТвдМАWindows 5дТ10ШеЕФИќаТЃЌЕЋЪЧЫќНЋАбZenЕФЦЕТЪЬсЩ§ЪБМфДг30КСУыНЕЕЭЕНZen 2ЕФ1~2КСУыЁЃжЕЕУзЂвтЕФЪЧЃЌетБШгЂЬиЖћИјГіЕФЪ§зжвЊПьЕУЖрЁЃ
AMDЪЕЯжЕФММЪѕУћГЦЩцМАCPPC2ЃЌМДCollaborative Power Performance Control 2ЃЌAMDЕФжИБъБэУїетЛсдіМгЭЛЗЂЙЄзїИКдиКЭгІгУГЬађИКдиЁЃAMDБэЪОЃЌЪЙгУPCMark10ЕФгІгУГЬађЦєЖЏзгВтЪдЃЌгІгУГЬађЕФЦєЖЏЪБМфадФмЬсЩ§СЫ6ЃЅЁЃ
діЧПСЫZen 2ЕФАВШЋад
Zen 2ЕФСэвЛИіЗНУцЪЧAMDгУРДЬсИпЯжДњДІРэЦїАВШЋадвЊЧѓЕФЗНЗЈЁЃе§ШчвбОБЈЕРЙ§ЕФЃЌзюНќвЛЯЕСаЕФВрЭЈЕРЙЅЛїВЂУЛгагАЯьAMDДІРэЦїЃЌетжївЊЪЧвђЮЊAMDЙмРэЦфTLBЛКГхЧјЕФЗНЪНЃЌетаЉЛКГхЧјдкДѓВПЗжГЩЮЊЮЪЬтжЎЧАзмЪЧашвЊЖюЭтЕФАВШЋМьВщЁЃОЁЙмШчДЫЃЌЖдгкAMDвзЪмЙЅЛїЕФЮЪЬтЃЌЫќвбОЮЊетаЉЮЪЬтЪЕЯжСЫвЛИіЭъШЋЛљгкгВМўЕФАВШЋЦНЬЈЁЃ

етРяЕФБфЛЏРДздSpeculative Store BypassЃЌГЦЮЊSpectre v4ЃЌAMDЯждкгаЖюЭтЕФгВМўгыВйзїЯЕЭГЛђащФтФкДцЙмРэЦїЃЈШчhypervisorЃЉаЭЌЙЄзїЃЌвдБуНјааПижЦЁЃAMDдЄМЦетаЉИќаТВЛЛсДјРДШЮКЮадФмБфЛЏЁЃжюШчForeshadowКЭZombieloadЕШаТЮЪЬтВЛЛсгАЯьAMDДІРэЦїЁЃ
аТжИСю
ЛКДцКЭФкДцДјПэQoSПижЦ
гыДѓЖрЪ§аТЕФx86ЮЂМмЙЙвЛбљЃЌДцдкЭЈЙ§аТжИСюЬсИпадФмЕФЖЏСІЃЌЕЋвВЛсГЂЪддкжЇГжФФаЉжИСюЗНУцЪЕЯжВЛЭЌЙЉгІЩЬжЎМфЕФЖдЕШЁЃЖдгкZen 2ЃЌЫфШЛAMDУЛгаЯёгЂЬиЖћФЧбљгКЯвЛаЉИќЙХЙжЕФжИСюМЏЃЌЕЋЫќдкШ§ИіВЛЭЌЕФСьгђдіМгСЫаТЕФжИСюЁЃ

ЕквЛИіЪЧCLWBЃЌвдЧАвбОдкгЂЬиЖћДІРэЦїЩЯПДЕНЙ§ЫќгыЗЧвзЪЇадФкДцгаЙиЁЃ ДЫжИСюдЪаэГЬађНЋЪ§ОнЭЦЛиЕНЗЧвзЪЇадФкДцжаЃЌвдЗРЯЕЭГЪеЕНЭЃЛњУќСюдьГЩЪ§ОнЖЊЪЇЁЃОЁЙмAMDУЛгаУїШЗЫЕУїЃЌЕЋЛЙгаЦфЫћгыБЃЛЄЪ§ОнЕНЗЧвзЪЇадФкДцЯЕЭГЯрЙиЕФжИСюЁЃетПЩФмБэУїAMDе§дкбАЧѓдкЮДРДЕФЩшМЦжаИќКУЕижЇГжЗЧвзЪЇадФкДцЕФгВМўКЭНсЙЙЃЌЬиБ№ЪЧдкEPYCДІРэЦїжаЁЃ
ЕкЖўИіЛКДцжИСюWBNOINVDЪЧвЛИіНіЯоAMDЕФУќСюЃЌЕЋЫќЛљгкЦфЫћРрЫЦЕФУќСюЃЌШчWBINVDЁЃ ДЫУќСюгУгкдЄВтНЋРДПЩФмашвЊЛКДцЕФЬиЖЈВПЗжЃЌВЂЧхГ§ЫќУЧЃЌвдБуМгЫйНЋРДЕФМЦЫуЁЃШчЙћЫљашЕФЛКДцааЮДзМБИОЭаїЃЌдђЛсдкЫљашВйзїжЎЧАДІРэЫЂаТУќСюЃЌДгЖјдіМгбгГй——ЕБбгГйЙиМќаЭжИСюШдбиСїЫЎЯпжаДЋЕнЪБЬсЧАдЫааЛКДцааЫЂаТЃЌгажњгкМгЫйЦфзюжежДааЁЃ
дкQoSЯТЙщЕЕЕФзюКѓвЛзщжИСюЪЕМЪЩЯгыШчКЮЗжХфЛКДцКЭФкДцгХЯШМЖгаЙиЁЃ
ЕБеыЖдВЛЭЌПЭЛЇНЋдЦCPUВ№ЗжЮЊВЛЭЌЕФШнЦїЃЈcontainerЃЉЛђащФтЛњЃЈVMЃЉЪБЃЌадФмМЖБ№ВЂВЛзмЪЧвЛжТЕФЃЌвђЮЊадФмПЩФмЛсИљОнСэвЛИіащФтЛњдкЯЕЭГЩЯжДааЕФВйзїЖјЪмЕНЯожЦЁЃетОЭЪЧЫљЮНЕФ“радгСкОг”ЮЪЬтЃКШчЙћЦфЫћШЫе§дкеМгУЫљгаКЫаФЕНФкДцЕФДјПэЃЈМДL3ЛКДцЃЉЃЌФЧУДЯЕЭГЩЯЕФСэвЛИіVMОЭКмФбЗУЮЪЫќЫљашЕФФкШнЁЃгЩгкетИірадгЕФСкОгЃЌЦфЫћVMдкДІРэЦфЙЄзїИКдиЪБЕФбгГйНЋЪЧИпЖШПЩБфЕФЁЃЛђепЃЌШчЙћвЛИіШЮЮёЙиМќаЭVMдкЯЕЭГЩЯЃЌЖјСэвЛИіVMвЛжБдкЧыЧѓзЪдДЃЌФЧУДШЮЮёЙиМќаЭVMПЩФмЛсДэЙ§ЫќЕФФПБъЃЌвђЮЊЫќУЛгаЗУЮЪЫљашЕФЫљгазЪдДЁЃ
Г§СЫШЗБЃЕЅИігУЛЇПЩвдЭъШЋЗУЮЪгВМўжЎЭтЃЌДІРэрадгЕФСкОгКмРЇФбЁЃДѓЖрЪ§дЦЬсЙЉЩЬКЭВйзїЩѕжСВЛЛсИцЫпФуЪЧЗёгаСкОгЃЌдкЪЕЪБVMЧЈвЦЕФЧщПіЯТЃЌетаЉСкОгПЩФмЛсЗЧГЃЦЕЗБЕиИќИФЃЌвђДЫВЛФмБЃжЄдкШЮКЮЪБКђЖМгаГжајЕФадФмЁЃетОЭашвЊвЛзщзЈгУЕФQoSЃЈЗўЮёжЪСПЃЉжИСюЁЃ
гыгЂЬиЖћЕФЪЕЯжвЛбљЃЌЕБвЛЯЕСаащФтЛњЗжХфЕНащФтЛњЙмРэГЬађжЎЩЯЕФЯЕЭГЩЯЪБЃЌащФтЛњЙмРэГЬађПЩвдПижЦУПИіащФтЛњгаЖрЩйФкДцДјПэКЭЛКДцЁЃШчЙћШЮЮёЙиМќаЭ8КЫащФтЛњашвЊЗУЮЪ64MBЕФL3КЭжСЩй30GB/sЕФФкДцДјПэЃЌдђащФтЛњМрПиГЬађПЩвдПижЦгХЯШМЖащФтЛњЪМжегаШЈЗУЮЪИУЪ§СПЃЌВЂНЋЦфДгЦфЫћащФтЛњЕФГижаЭъШЋЩОГ§ЃЌЛђепдкШЮЮёЙиМќаЭащФтЛњЭЛШЛНјШыЭъШЋЗУЮЪЪБжЧФмЕиЯожЦЦфвЊЧѓЁЃ
гЂЬиЖћжЛдкЦфXeonПЩРЉеЙДІРэЦїЩЯЪЕЯжСЫетвЛЙІФмЃЌЕЋAMDНЋЮЊЯћЗбМЖКЭЦѓвЕгУЛЇдкZen 2ДІРэЦїЯЕСажаЪЕЯжетвЛЙІФмЁЃ
ЮвдкетИіЙІФмЩЯгіЕНЕФзюжБНгЕФЮЪЬтЪЧдкЯћЗбМЖЗНУцЁЃЯыЯѓвЛЯТЃЌШчЙћвЛИіЪгЦЕгЮЯЗашвЊЗУЮЪЫљгаЕФЛКДцКЭЫљгаЕФФкДцДјПэЃЌЖјвЛаЉСїУНЬхШэМўШДВЛФмЗУЮЪ——етПЩФмЛсЖдЯЕЭГдьГЩбЯжиЕФЦЦЛЕЁЃAMDНтЪЭЫЕЃЌЫфШЛДгММЪѕЩЯНВЃЌЕЅИіГЬађПЩвдЧыЧѓвЛЖЈМЖБ№ЕФQoSЃЌЕЋЪЧЃЌетаЉЧыЧѓЪЧЗёгааЇКЭКЯЪЪНЋШЁОігкВйзїЯЕЭГЛђащФтЛњМрПиГЬађЁЃЫћУЧНЋДЫЙІФмИќЖрЕиЪгЮЊЗЂЛгащФтЛњМрПиГЬађзїгУЪБЪЙгУЕФвЛжжЦѓвЕЙІФмЃЌЖјВЛЪЧЯћЗбМЖЯЕЭГЩЯЕФТуЛњАВзАЁЃ
CCXГпДч
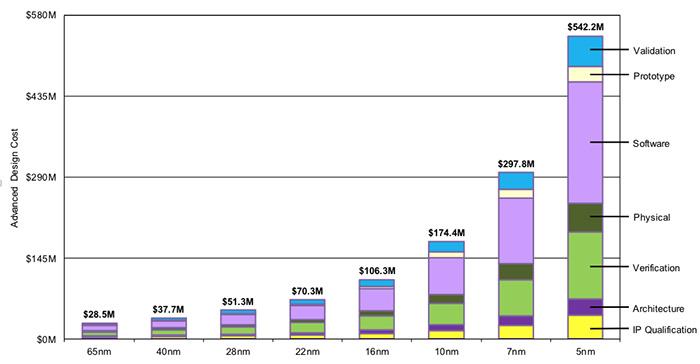
ЯђЯТвЦЖЏНкЕуДѓаЁЛсдкКЫаФФкЭтДјРДаэЖрЬєеНЁЃМДЪЙВЛПМТЧЙІТЪКЭЦЕТЪЃЌНЋНсЙЙЗХШыаОЦЌЃЌШЛКѓНЋаОЦЌМЏГЩЕНЗтзАжаЃЌвдМАЭЈЙ§е§ШЗЕФСЌНгЮЊаОЦЌЕФе§ШЗВПЗжЬсЙЉЕчСІБОЩэвВГЩЮЊвЛжжСЗЯАЁЃAMDШУЮвУЧЩюШыСЫНт7nmШчКЮИФБфЦфВПЗжЩшМЦЃЌвдМАЦфжаЕФЗтзАЬєеНЁЃ

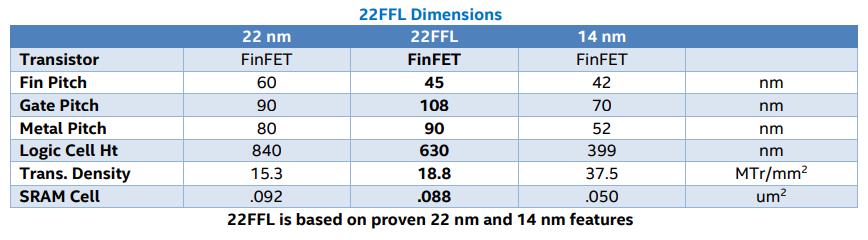
AMDЗХЦњЕФвЛИіЙиМќжИБъгыКЫаФИДКЯЬхЃЈCCXЃЉгаЙиЃК4ИіКЫаФЃЌЯрЙиЕФКЫаФНсЙЙЃЌШЛКѓЪЧL2КЭL3ЛКДцЁЃAMDГЦЃЌдк12 nmКЭZEN+КЫаФЕФЧщПіЯТЃЌЕЅИіКЫаФИДКЯЬхЮЊ60ЦНЗНКСУзЃЌЦфжаКЫаФеМ44ЦНЗНКСУзЃЌ8MBЕФL3еМ16ЦНЗНКСУзЁЃАбЦфжаСНИі60ЦНЗНКСУзЕФИДКЯЬхМгЩЯСНИіДјФкДцПижЦЦїЁЂPCIeЭЈЕРЁЂ4ИіIFСДТЗКЭЦфЫћIOЃЌZen+ ZeppelinТуЦЌзмЙВЪЧ213ЦНЗНКСУзЁЃ
ЖдгкZen 2ЃЌЕЅИіchipletЪЧ74ЦНЗНКСУзЃЌЦфжа31.3ЦНЗНКСУзЪЧКЫаФИДКЯЬхЃЌга16 MBЕФL3ЁЃAMDУЛгаНЋет31.3ИіЪ§зжВ№ЗжЮЊКЫаФКЭL3ЃЌЕЋЪЧШЫУЧПЩвдЯыЯѓL3ПЩФмНгНќетИіЪ§зжЕФ50%ЁЃchipletШчДЫаЁЕФдвђЪЧЫќВЛашвЊФкДцПижЦЦїЃЌЫќжЛгавЛИіIFСДТЗЃЌУЛгаIOЃЌвђЮЊЫљгаЕФЦНЬЈвЊЧѓЖМдкIOаОЦЌЩЯЁЃетЪЙЕУAMDПЩвдЪЙchipletЗЧГЃНєДеЁЃШЛЖјЃЌШчЙћAMDДђЫуМЬајдіМгL3ЛКДцЃЌФЧУДL3ЛКДцПЩФмЛсеМОнаОЦЌЕФДѓВПЗжЁЃ
ЕЋзмЬхЖјбдЃЌAMDвбОБэЪОCCXЃЈКЫаФМгL3ЃЉЕФГпДчМѕЩйСЫ47ЃЅЁЃетЯдЪОСЫОоДѓЕФПЩРЉеЙадЃЌЬиБ№ЪЧЕБ+15%ЕФдЪМжИСюЭЬЭТСПКЭдіМгЕФЦЕТЪПЊЪМЗЂЛгзїгУЪБЁЃУПЦНЗНКСУзЕФадФмНЋЪЧвЛИіЗЧГЃСюШЫаЫЗмЕФжИБъЁЃ
ЗтзА
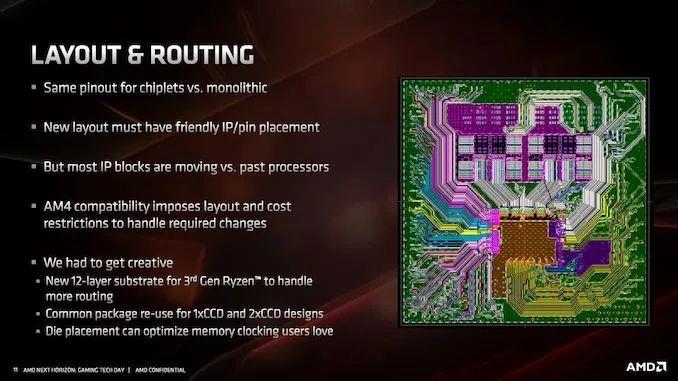
гЩгкMatisseЪЙгУAM4ВхВлЃЌRomeЪЙгУEPYCВхВлЃЌAMDБэЪОЫћУЧБиаыбКБІЗтзАММЪѕЃЌвдБЃГжМцШнадЁЃетаЉЖФзЂжаЕФвЛаЉзюжезмЪЧЮЊСЫГжајЕФжЇГжЖјНјааШЈКтЃЌЕЋAMDЯраХЃЌЮЊСЫМцШнаджЕЕУИЖГіЖюЭтЕФХЌСІЁЃ
AMDЬИЕНЕФгыЗтзАгаЙиЕФЙиМќЮЪЬтжЎвЛЪЧЃЌУПИіТуЦЌШчКЮСЌНгЕНЗтзАЩЯЁЃЮЊСЫЪЕЯжpin-gridеѓСаЬЈЪНЛњДІРэЦїЃЌБиаывдBGAЗНЪННЋаОЦЌЙЬЖЈЕНДІРэЦїЩЯЁЃAMDБэЪОЃЌгЩгкВЩгУСЫ7nmЙЄвеЃЌЭЙЕуМфОрЃЈТуЦЌКЭЗтзАЩЯЕФКИЧђжЎМфЕФОрРыЃЉДг12nmЕФ150ЮЂУзМѕЩйЕН7nmЕФ130ЮЂУзЁЃетЬ§Ц№РДВЂВЛЖрЃЌЕЋAMDБэЪОЃЌЪРНчЩЯжЛгаСНМвГЇЩЬгЕгазуЙЛЕФММЪѕРДзіЕНетвЛЕуЁЃЮЈвЛЕФЬцДњЗНАИЪЧЪЙгУИќДѓЕФаОЦЌРДжЇГжИќДѓЕФЭЙЕуМфОрЃЌзюжеЕМжТаОЦЌжаГіЯжДѓСППеЯаЃЈЛђВЛЭЌЕФЩшМЦЗЖЪНЃЉЁЃ

ЮЊСЫЪЕЯжИќНєУмЕФЭЙЕуМфОрЃЌЦфжавЛжжЗНЗЈЪЧЕїећдкаОЦЌЯТВрДІРэЭЙЕуЕФЗНЪНЁЃЭЈГЃЧщПіЯТЃЌЗтзАЩЯЕФКИСЯЭЙЕуЪЧвЛИіЮоЧІКИСЯЕФЭХЛђЧђЃЌвРППБэУцеХСІКЭЛиСїЕФЮяРэЬиадРДШЗБЃЦфвЛжТЧвЙцдђЁЃШЛЖјЃЌЮЊСЫЪЕЯжИќНєУмЕФЭЙЕуМфОрЃЌAMDБиаызЊЯђЭжљКИСЯЭЙЕуЭиЦЫЁЃ
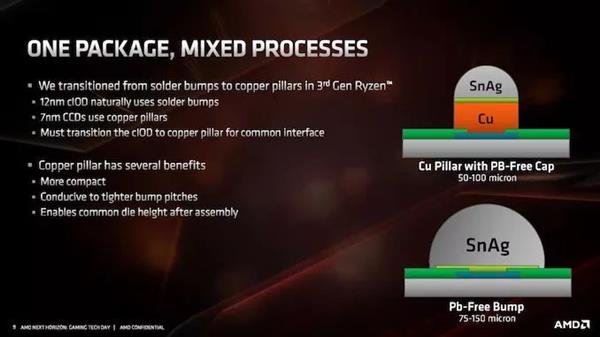
ЮЊСЫЪЕЯжетвЛЬиадЃЌЭБЛЭтбгГСЛ§дкбкФЃФкЃЌвдБуаЮГЩЛиСїКИСЯЫљЪЙгУЕФ“жЇМм”ЁЃгЩгкКИжљЕФжБОЖЃЌЫљашЕФбкФЃНЯЩйЃЌДгЖјВњЩњНЯаЁЕФКИСЯАыОЖЁЃгЩгкЦфдкMatisseФкВПЕФЫЋаОЦЌЩшМЦЃЌAMDЛЙгіЕНСЫСэвЛИіЮЪЬтЃКШчЙћIOаОЦЌЪЙгУБъзМКИСЯЭЙЕубкФЃЃЌВЂЧвchipletЪЙгУЭжљЃЌдђМЏГЩЩЂШШЦїашвЊгавЛЖЈЕФИпЖШвЛжТадЁЃЖдгкНЯаЁЕФЭжљЃЌетвтЮЖзХЙмРэЭжљЕФдіГЄЫЎЦНЁЃ
AMDНтЪЭЫЕЃЌгыНЈдьВЛЭЌИпЖШЕФЩЂШШЦїЯрБШЃЌЪЕМЪЩЯЙмРэетжжСЌНгЪЕЯжИќШнвзЃЌвђЮЊЩЂШШЦїЕФГхбЙЙЄвеВЛЛсВњЩњШчДЫаЁЕФЙЋВюЁЃAMDдЄМЦЃЌЮДРДЫљга7nmЩшМЦЖМНЋВЩгУЭжљЪЕЯжЁЃ
ВМЯп
Г§СЫНЋТуЦЌЗХдкгаЛњГФЕзЩЯжЎЭтЃЌИУГФЕзЛЙБиаыЙмРэТуЦЌгыТуЦЌЭтВПжЎМфЕФСЌНгЁЃЮЊСЫДІРэЖюЭтЕФВМЯпЃЌAMDБиаыНЋЗтзАжаЕФГФЕзВудіМгЕН12ВуЃЈУЛгаЭИТЖдкRomeашвЊЖрЩйВуЃЌвВаэ14ВуЃЉЁЃЖдгкЕЅКЫchipletКЭЫЋКЫchipletДІРэЦїЖјбдЃЌетвВБфЕУгааЉИДдгЃЌЬиБ№ЪЧдкНЋТуЦЌЗХНјЗтзАжЎЧАЖдЦфНјааВтЪдЪБЁЃ
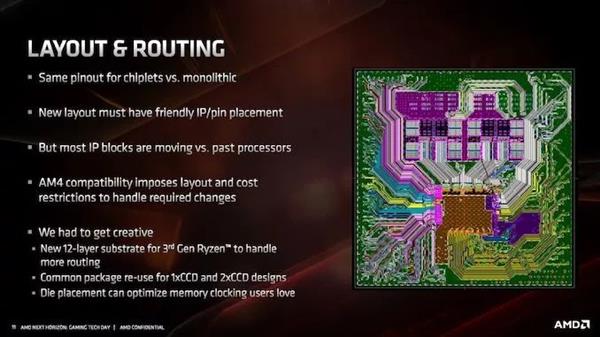
ДгЭМжаЮвУЧПЩвдЧхГўЕиПДЕНДгСНИіchipletЕНIOаОЦЌЕФIFСДТЗЃЌIOаОЦЌвВДІРэФкДцПижЦЦївдМАУВЫЦЕчдДЦНУцЕФШЮЮёЁЃchipletжЎМфУЛгаЗтзАФкСДНгЃКchipletЮоЗЈжБНгЭЈаХЃЌchipletжЎМфЕФЫљгаЭЈаХЖМЪЧЭЈЙ§IOаОЦЌДІРэЕФЁЃ
AMDБэЪОЃЌВЩгУетжжВМОжЃЌЫћУЧЛЙБиаызЂвтДІРэЦїШчКЮЗХжУдкЯЕЭГжаЃЌвдМАРфШДКЭФкДцВМОжЁЃДЫЭтЃЌЕБЩцМАЕНИќПьЕФФкДцжЇГжЛђPCIe 4.0ИќбЯИёЕФШнВюЪБЃЌЫљгаетаЉвВашвЊБЛПМТЧЃЌвдБудкВЛЪмЦфЫћВМЯпИЩШХЕФЧщПіЯТЮЊаХКХДЋЕМЬсЙЉзюМбТЗОЖЁЃ

AMD Zen 2ЮЂМмЙЙИХЪі
ПьЫйЗжЮі
дкAMDЕФММЪѕШеЃЌдкГЁЕФЪЧЭЌЪТМцЪзЯЏМмЙЙЪІMike ClarkЃЌЫћОРњСЫетаЉБфЛЏЁЃMikeЪЧвЛИіКмКУЕФЙЄГЬЪІЃЌОЁЙмзмЪЧШУЮвИаЕНгаШЄЕФЪЧЃЌЬИТлзюаТВњЦЗЩЯЪаЕФЙЄГЬЪІУЧвбОдкЙЋЫОЙЄзїСЫвЛДњЁЂСНДњЛђШ§ДњЃЈЖдгкШЮКЮЙЋЫОЖМЪЧетбљЃЌВЛНіНіЪЧAMDЃЉЁЃMikeЫЕЃЌЫћЛЈСЫвЛЖЮЪБМфРДЛиЯыZen+ЕНZen 2ЕФОпЬхБфЛЏЃЌЖјЫћЕФФдКЃжавбООРњСЫМИДњВњЦЗЕФБфЛЏЁЃ
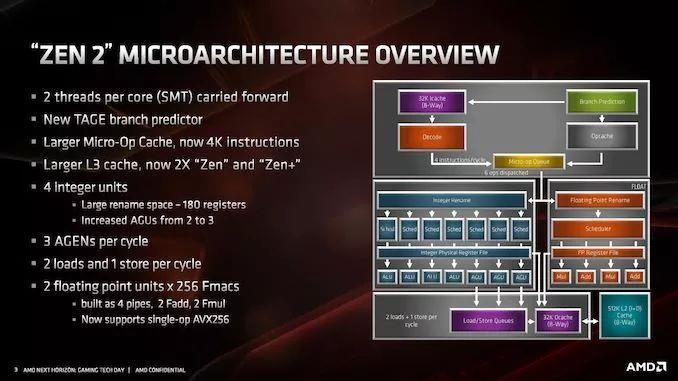
Zen 2ЕФвЛИігаШЄдЊЫиЪЧЮЇШЦЦфвтЭМЁЃзюГѕZen 2НіНіЪЧZen+ЕФЫѕаЁАцЃЌДг12nmЫѕаЁЕН7nmЃЌРрЫЦгкЮвУЧдкБОЪРМЭГѕПДЕНЕФгЂЬиЖћЕФtick-tockФЃаЭЁЃШЛЖјЃЌAMDИљОнФкВПЗжЮіКЭ7nmЕФЪБМфПђМмЃЌОіЖЈЪЙгУZEN 2зїЮЊадФмИќКУЕФЦНЬЈЃЌвдЖржжЗНЪНРћгУ7nmЃЌЖјВЛЪЧНіНідквЛИіаТЕФЙЄвеНкЕуЩЯжиаТЩшМЦЯрЭЌЕФВМОжЁЃзїЮЊЕїећЕФНсЙћЃЌAMDе§дкЭЦЖЏZen 2ЕФIPCБШZen+ЬсЩ§15%ЁЃ
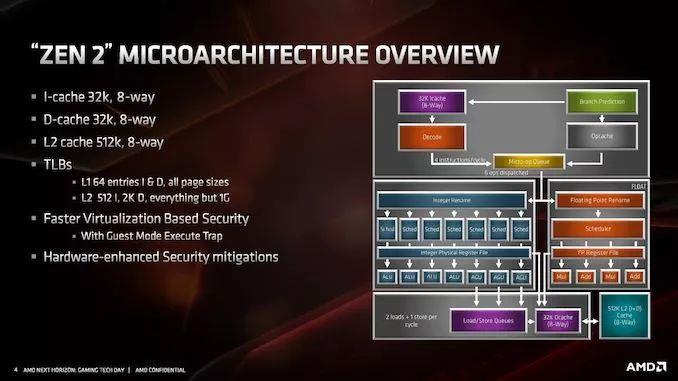
ЕБЬИЕНЮЂМмЙЙЕФШЗЧаБфЛЏЪБЃЌЮвУЧЛљБОЩЯПДЕНЕФШдШЛЪЧРрЫЦгкZenЭтЙлЕФВМОжЙцЛЎЁЃZen 2ЪЧZenЯЕСаЕФвЛдБЃЌдкДІРэx86ЗНУцВЂВЛЪЧЭъШЋЕФжиаТЩшМЦЛђВЛЭЌЕФЗЖР§——гыЦфЫћОпгаМвзхИќаТЕФМмЙЙвЛбљЃЌZen 2ЬсЙЉСЫИќгааЇЕФКЫаФКЭИќЙуЗКЕФКЫаФЃЌдЪаэИќКУЕФжИСюЭЬЭТСПЁЃ

ДгНЯИпЕФВуУцРДПДЃЌКЫаФПДЦ№РДЗЧГЃЯрЫЦЁЃZen 2ЩшМЦЕФССЕуАќРЈВЛЭЌЕФL2ЗжжЇдЄВтЦїЃЌГЦЮЊTAGEдЄВтЦїЃЌmicro-opЛКДцМгБЖЃЌL3ЛКДцМгБЖЃЌећЪ§зЪдДдіМгЃЌМгди/ДцДЂзЪдДдіМгЃЌвдМАЖдЕЅВйзїAVX-256ЃЈЛђAVX2ЃЉЕФжЇГжЁЃAMDБэЪОЃЌЛљгкЦфФмСПИажЊЦЕТЪЦНЬЈЃЌAVX2УЛгаЦЕТЪЫ№ЪЇЁЃ
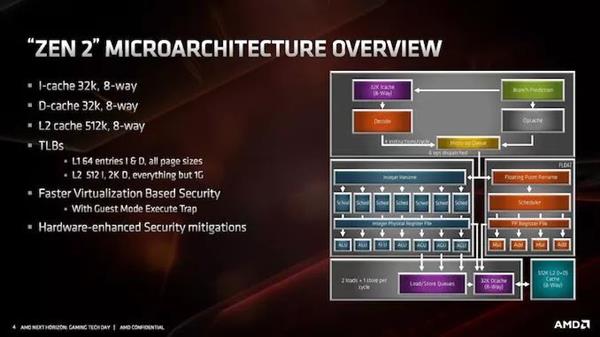
AMDЛЙЖдЛКДцЯЕЭГНјааСЫЕїећЃЌЦфжазюв§ШЫзЂФПЕФЪЧL1жИСюЛКДцЃЌЫќБЛМѕАыЕН32kbЃЌЕЋЙиСЊаддіМгСЫвЛБЖЁЃНјааетжжИќИФЪЧГігкживЊЕФдвђЃЌЮвУЧНЋдкЯТвЛвГжаЖдДЫНјааЬжТлЁЃL1Ъ§ОнЛКДцКЭL2ЛКДцБЃГжВЛБфЃЌЕЋЪЧЪТЮёКѓБИЛКГхЧјЃЈTLBЃЉдіМгСЫжЇГжЁЃAMDЛЙБэЪОЃЌЫќвбОдкАВШЋЗНУцдіМгСЫИќЩюВуДЮЕФащФтЛЏжЇГжЃЌгажњгкЪЕЯжСїЫЎЯпКѓајЕФЙІФмЁЃе§ШчБОЮФЧАУцЬсЕНЕФЃЌЛЙгаАВШЋадЧПЛЏИќаТЁЃ
ЖдгкПьЫйЗжЮіЃЌПЩвдКмШнвзЕиПДГіЃЌдкаэЖрЧщПіЯТЃЌМгБЖmicro-opЛКДцНЋЮЊIPCДјРДЯджјЕФИФНјЃЌЖјАбЫќгыИКди/ДцДЂзЪдДЕФдіМгЯрНсКЯЃЌЛсгажњгкЭЈЙ§ИќЖрЕФжИСюЁЃМгБЖL3ЛКДцгажњгкЬиЖЈЙЄзїИКдиЃЌжЇГжAVX2ЕЅВйзївВЪЧШчДЫЃЌЕЋИФНјЕФЗжжЇдЄВтГЬађвВНЋеЙЪОдЪМадФмЬсЩ§ЁЃзмЖјбджЎЃЌДгжНУцЗжЮіРДПДЃЌAMD 15%ЕФIPCИФНјЫЦКѕЪЧвЛИіЗЧГЃКЯРэЕФЪ§зжЁЃ
дкНгЯТРДЕФМИвГжаЃЌЮвУЧНЋЩюШыЬНЬжЮЂМмЙЙЕФБфЛЏЁЃ
ЬсШЁ/дЄЬсШЁ
ЮвУЧДгДІРэЦїЕФЧАЖЫПЊЪМЃЌдЄШЁЦїЁЃ
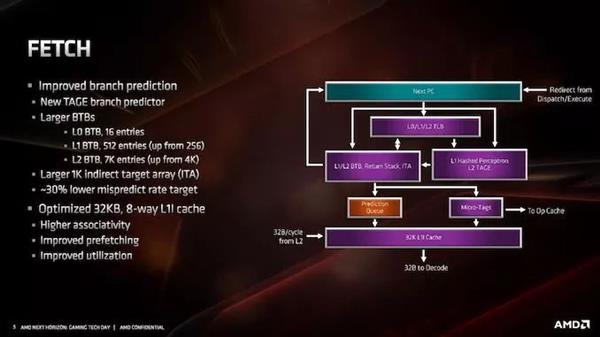
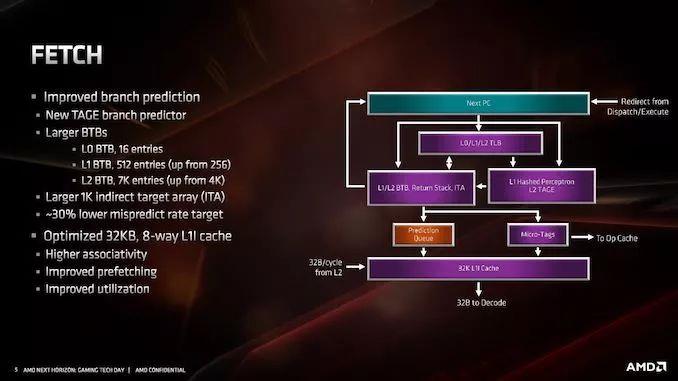
AMDдкетРяаћДЋЕФжївЊИФНјЪЧЪЙгУTAGEдЄВтЦїЃЌОЁЙмЫќжЛгУгкЗЧl1ЬсШЁЁЃетЬ§Ц№РДПЩФмВЂВЛзуЕРЃКAMDШдШЛЪЙгУЙўЯЃИажЊЦїдЄШЁв§ЧцЮЊL1ЬсШЁЃЌетНЋЛсОЁПЩФмЖрЕФЬсШЁЃЌЕЋTAGE L2ЗжжЇдЄВтЦїЪЙгУЖюЭтЕФБъМЧРДЪЕЯжИќГЄЕФЗжжЇРњЪЗЃЌвдЛёЕУИќКУЕФдЄВтТЗОЖЁЃетЖдгкL2дЄШЁМАвдКѓЕФдЄШЁБфЕУИќМгживЊЃЌЙўЯЃИажЊЦїгХЯШгУгкЛљгкЙІТЪЕФL1жаЕФЖЬдЄШЁЁЃ
дкЧАЖЫЃЌЮвУЧЛЙгаИќДѓЕФBTBЃЌвдАяжњИњзйжИСюЗжжЇКЭЛКДцЧыЧѓЁЃL1 BTBЕФДѓаЁдіМгСЫвЛБЖЃЌДг256ИіЬѕФПдіМгЕН512ИіЬѕФПЃЌL2МИКѕдіМгСЫвЛБЖЃЌДг4KдіМгЕН7KЁЃL0 BTBБЃГждк16ИіЬѕФПЃЌЕЋМфНгФПБъеѓСазюЖрПЩДя1KИіЬѕФПЁЃзмЬхЖјбдЃЌAMDЕФетаЉБфЛЏШУЮѓдЄВтТЪНЕЕЭСЫ30ЃЅЃЌДгЖјНкЪЁСЫЕчСІЁЃ
СэвЛИіжївЊБфЛЏЪЧL1жИСюЛКДцЁЃЮвУЧзЂвтЕНЫќЖдгкZen 2РДЫЕИќаЁЃКжЛга32KBЖјЗЧ64KBЃЌЕЋЪЧЙиСЊаддіМгСЫвЛБЖЃЌДг4ТЗдіМгЕН8ТЗЁЃПМТЧЕНИпЫйЛКДцЕФЙЄзїЗНЪНЃЌетСНжжгАЯьзюжеВЛЛсЛЅЯрЕжЯћЃЌЕЋЪЧ32KB L1-IЛКДцгІИУИќНкФмЃЌВЂЧвгаИќИпЕФРћгУТЪЁЃL1-IЛКДцВЂВЛЪЧЙТСЂЕиМѕЩйЕФ——МѕЩйIЛКДцДѓаЁЕФКУДІжЎвЛЪЧдЪаэAMDНЋmicro-opЛКДцЕФДѓаЁдіМгвЛБЖЁЃетСНИіНсЙЙдкКЫаФФкВПБЫДЫЯрСкЃЌвђДЫМДЪЙдк7nmЃЌЮвУЧвВгаПеМфЯожЦЕФЪЕР§ЃЌЕМжТКЫаФФкВПНсЙЙжЎМфЕФШЈКтЁЃAMDБэЪОЃЌетжжНЯаЁЕФL1гыНЯДѓЕФmicro-opЛКДцЕФХфжУЃЌдкИќЖрЕФВтЪдГЁОАжаБэЯжИќКУЁЃ
НтТы
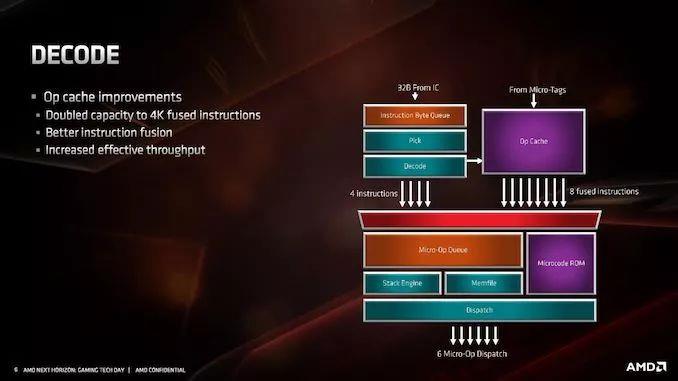
ЖдгкНтТыНзЖЮЃЌетРяЕФжївЊЬсЩ§ЪЧmicro-opЛКДцЁЃЭЈЙ§Аб2KЬѕФПМгБЖЕН4KЬѕФПЃЌЫќНЋБШвдЧААќКЌИќЖрЕФНтТыВйзїЃЌетвтЮЖзХЫќНЋОРњДѓСПЕФжигУЁЃЮЊСЫБугкЪЙгУЃЌAMDЬсИпСЫДгmicro-opЛКДцЕНЛКГхЧјЕФЕїЖШЫйЖШЃЌзюЖр8ЬѕШкКЯжИСюЁЃМйЩшAMDПЩвдОГЃШЦЙ§ЫќЕФНтТыЦїЃЌетгІИУЪЧвЛИіЗЧГЃгааЇЕФЧјПщЁЃ
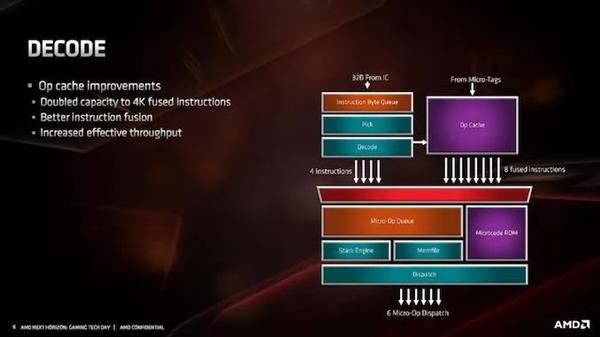
4KЬѕФПИќСюШЫгЁЯѓЩюПЬЕФЪЧЕБЮвУЧНЋЫќгыОКељЖдЪжНјааБШНЯЕФЪБКђЁЃдкгЂЬиЖћЕФSkylakeЯЕСажаЃЌетаЉФкКЫжаЕФmicro-opЛКДцжЛга1.5KЬѕФПЁЃгЂЬиЖћНЋIce LakeЕФЙцФЃдіМгСЫ50ЃЅЃЌДяЕНСЫ2.25KЃЌетИіКЫаФНЋдкНёФъЭэаЉЪБКђНјШывЦЖЏЦНЬЈЃЌУїФъПЩФмНјШыЗўЮёЦїЁЃЯрБШжЎЯТЃЌAMDЕФZen 2КЫаФНЋКИЧДгЯћЗбМЖЕНЦѓвЕЕФЫљгаСьгђЁЃЭЌЪБЃЌЮвУЧвВПЩвдНЋЦфгыArm A77 CPUЕФmicro-opЛКДцНјааБШНЯЃЌИУЛКДцЮЊ1.5KЬѕФПЃЌШЛЖјЃЌЫќЪЧArmЮЊКЫаФЩшМЦЕФЕквЛИіmicro-opЛКДцЁЃ
Zen 2жаЕФНтТыЦїБЃГжВЛБфЃЌЮвУЧШдШЛПЩвдЗУЮЪ4ИіИДдгНтТыЦїЃЈIntelЪЧ1ИіИДдгНтТыЦї+4ИіМђЕЅНтТыЦїЃЉЃЌНтТыжИСюБЛЛКДцЕНmicro-opЛКДцжаЃЌВЂБЛЗжХЩЕНmicro-opЖгСажаЁЃ
AMDЛЙБэЪОЃЌЫќвбОИФНјСЫЦфmicro-opШкКЯЫуЗЈЃЌЕЋУЛгаЯъЯИЫЕУїетНЋШчКЮгАЯьадФмЁЃФПЧАЕФmicro-opШкКЯзЊЛЛвбОЯрЕБКУЃЌЫљвдПДПДAMDдкетРязіСЫЪВУДНЋЛсКмгаШЄЁЃгыZENКЭZEN+ЯрБШЃЌЛљгкЖдAVX2ЕФжЇГжЃЌетвтЮЖзХНтТыЦїВЛашвЊНЋAVX2жИСюЗжНтЮЊСНИіmicro-opЃКAVX2ЯждкЪЧЭЈЙ§СїЫЎЯпЕФЕЅИіmicro-opЁЃ
Г§СЫНтТыЦїжЎЭтЃЌmicro-opЖгСаКЭЕїЖШПЩвддкУПИіжмЦкЯђЕїЖШЦїРЁЫЭ6Иіmicro-opЁЃЕЋЪЧЃЌетгаЕуВЛЦНКтЃЌвђЮЊAMDгаЖРСЂЕФећЪ§КЭИЁЕуЕїЖШЦїЃКећЪ§ЕїЖШЦїУПжмЦкПЩвдНгЪм6Иіmicro-opЃЌЖјИЁЕуЕїЖШЦїжЛФмНгЪм4Иіmicro-opЁЃШЛЖјЃЌЕїЖШПЩвдЭЌЪБЯђСНепЗЂЫЭmicro-opЁЃ
ИЁЕу
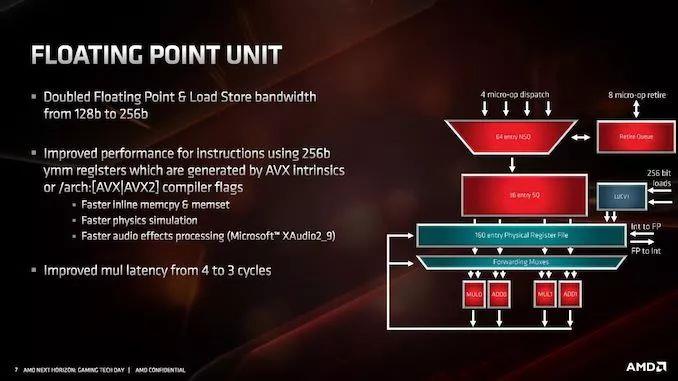
ИЁЕуадФмЕФЙиМќССЕуЪЧЭъШЋжЇГжAVX2ЁЃAMDвбОНЋжДааЕЅдЊЕФПэЖШДг128ЮЛдіМгЕН256ЮЛЃЌдЪаэЕЅжмЦкAVX2МЦЫуЃЌЖјВЛЪЧНЋМЦЫуЗжГЩСНИіжИСюКЭСНИіжмЦкЁЃетЪЧЭЈЙ§ЬсЙЉ256ЮЛИКдиКЭДцДЂРДдіЧПЕФЃЌвђДЫFMAЕЅдЊПЩвдСЌајРЁЫЭЁЃAMDжИГіЃЌгЩгкЦфФмСПИажЊЕїЖШЃЌдкЪЙгУAVX2жИСюЪБУЛгадЄЖЈвхЕФЦЕТЪЯТНЕЃЈЕЋЪЧЦЕТЪПЩФмЛсИљОнЮТЖШКЭЕчбЙвЊЧѓЖјНЕЕЭЃЌЕЋЮоТлЪЙгУКЮжжжИСюЃЌетЖМЪЧздЖЏЕФЃЉЁЃ
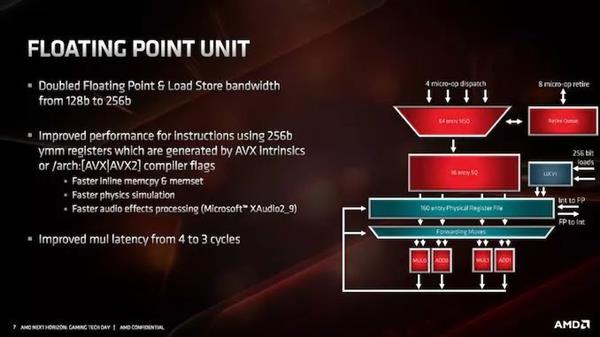
дкИЁЕуЕЅдЊжаЃЌЖгСаУПИіжмЦкзюЖрНгЪмРДздЕїЖШЕЅдЊЕФ4Иіmicro-opЃЌетаЉmicro-opРЁШывЛИіАќКЌ160ИіЬѕФПЕФЮяРэМФДцЦїЮФМўЁЃетНЋвЦЖЏЕН4ИіжДааЕЅдЊЃЌПЩвддкМгдиКЭДцДЂЛњжЦжаЯђетаЉЕЅдЊЬсЙЉ256bЕФЪ§ОнЁЃ
Г§СЫГпДчМгБЖжЎЭтЃЌFMAЛЙНјааСЫЦфЫћЕїећЁЃAMDБэЪОЃЌЫћУЧЬсИпСЫФкДцЗжХфЁЂжиИДЮяРэМЦЫуЃЌвдМАФГаЉвєЦЕДІРэММЪѕЕФдЪМадФмЁЃ
СэвЛИіЙиМќИќаТЪЧНЋFPГЫЗЈбгГйДг4ИіжмЦкМѕЩйЕН3ИіжмЦкЁЃетЪЧЯрЕБЯджјЕФНјВНЁЃAMDБэЪОЃЌЙЋЫОЖдКмЖрЯИНкБЃУмЃЌвђЮЊЙЋЫОЯыдк8дТЕФHot ChipsЩЯеЙЪОЁЃЮвУЧНЋдк7дТ7ШеНјааШЋУцЕФжИСюЗжЮіЁЃ
ећЪ§ЕЅдЊЁЂМгдиКЭДцДЂ
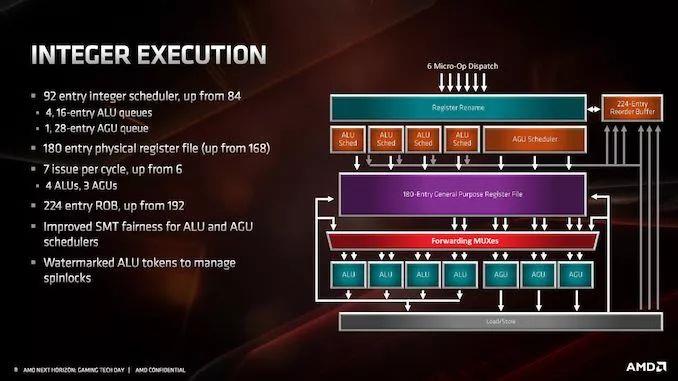
ећЪ§ЕЅдЊЕїЖШЦїУПИіжмЦкзюЖрПЩвдНгЪм6Иіmicro-opЃЌетаЉmicro-opНЋРЁЫЭЕН224ИіЬѕФПЕФжиаТХХађЛКГхЧјЃЈвдЧАЪЧ192ИіЃЉЁЃећЪ§ЕЅдЊдкММЪѕЩЯга7ИіжДааЖЫПкЃЌгЩ4ИіALUЃЈЫуЪѕТпМЕЅдЊЃЉКЭ3ИіAGUЃЈЕижЗЩњГЩЕЅдЊЃЉзщГЩЁЃ
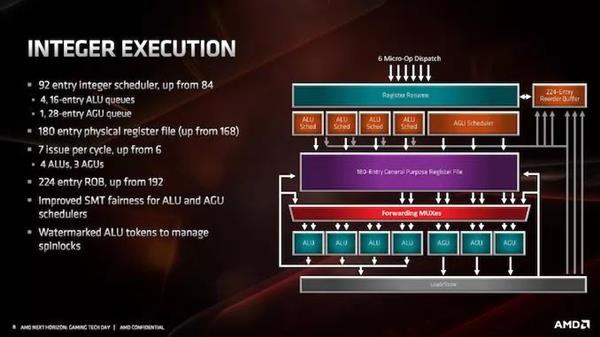
ЕїЖШГЬађгЩ4Иі16ЬѕФПЕФALUЖгСаКЭ1Иі28ЬѕФПЕФAGUЖгСазщГЩЃЌОЁЙмAGUЕЅдЊУПИіжмЦкПЩвдЯђМФДцЦїЮФМўРЁЫЭ3Иіmicro-opЁЃЛљгкAMDЖдЭЈгУШэМўжажИСюЗжВМЕФФЃФтЃЌAGUЖгСаЕФДѓаЁгаЫљдіМгЁЃетаЉЖгСаРЁЫЭ180ИіЬѕФПЕФЭЈгУМФДцЦїЮФМўЃЈдЯШЪЧ168ИіЃЉЃЌЕЋвВИњзйЬиЖЈЕФALUВйзїЃЌвдЗРжЙЧБдкЕФЭЃЛњВйзїЁЃ
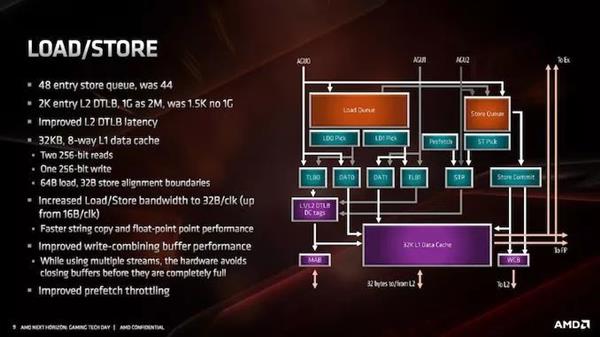
Ш§ИіAGUРЁЫЭЕНМгди/ДцДЂЕЅдЊЃЌМгди/ДцДЂЕЅдЊУПИіжмЦкПЩвджЇГжСНИі256ЮЛЕФЖСШЁКЭвЛИі256ЮЛЕФаДШыЁЃДгЩЯЭМПЩвдПДГіЃЌВЂЗЧЫљгаШ§ИіAGUЖМЯрЭЌЃКAGU2жЛФмЙмРэДцДЂЃЌЖјAGU0КЭAGU1ПЩвдЭЌЪБНјааМгдиКЭДцДЂЁЃ
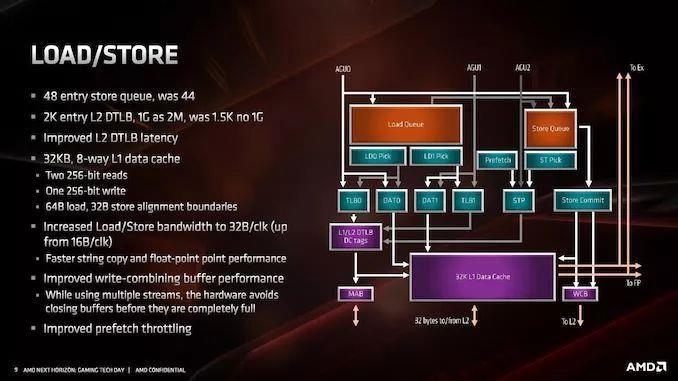
ДцДЂЖгСаДг44ИіЬѕФПдіМгЕН48ИіЬѕФПЃЌЪ§ОнЛКДцЕФTLBвВдіМгСЫЁЃВЛЙ§ЃЌетРяЕФЙиМќжИБъЪЧМгди/ДцДЂДјПэЃЌвђЮЊКЫаФЯждкУПИіЪБжгПЩвджЇГж32ИізжНкЃЌЖјЗЧдРДЕФ16ИізжНкЁЃ
ЛКДцКЭInfinity Fabric
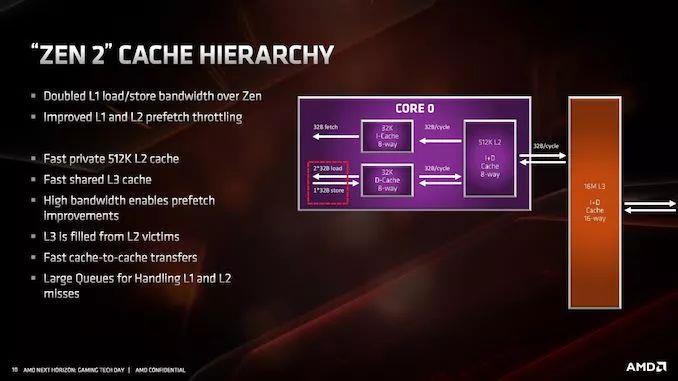
ЛКДцжазюДѓЕФБфЛЏОЭЪЧL1жИСюЛКДцЃЌЫќДг64KBМѕЩйЕНСЫ32KBЃЌЕЋЪЧНсКЯЖШДг4ТЗдіМгЕНСЫ8ТЗЁЃетвЛБфЛЏЪЙAMDФмЙЛНЋmicro-opЛКДцЕФДѓаЁДг2KЬѕФПдіМгЕН4KЬѕФПЃЌAMDШЯЮЊетПЩвдИќКУЕиЦНКтЯжДњЙЄзїИКдиЕФЗЂеЙЁЃ
L1-DЛКДцШдШЛЪЧ8ТЗ32KB ЃЌЖјL2ЛКДцШдЮЊ8ТЗ512KBЁЃL3ЛКДцЪЧЗЧАќШнадЛКДцЃЈL2ЪЧАќШнадЛКДцЃЉЃЌЯждкЫќЕФДѓаЁвбОдіМгСЫвЛБЖЃЌДяЕН16MB/КЫаФИДКЯЬхЃЈдЯШЪЧ8MBЃЉЁЃAMDЙмРэL3ЕФЗНЪНЪЧУПИіCCXЙВЯэвЛИі16MBЕФЧјПщЃЌЖјВЛЪЧдЪаэДгШЮКЮКЫаФЗУЮЪL3ЁЃ
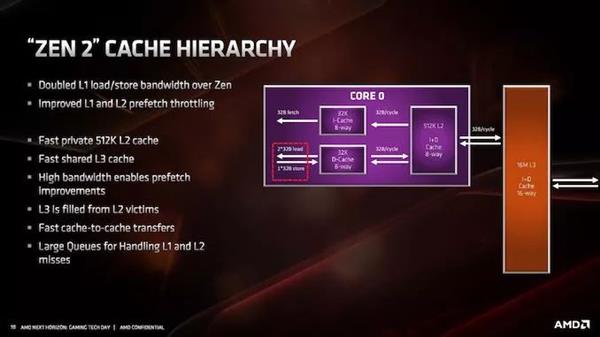
гЩгкL3ЕФДѓаЁдіМгЃЌбгГйТдгадіМгЁЃL1ШдШЛЪЧ4жмЦкЃЌL2ШдШЛЪЧ12жмЦкЃЌЕЋЪЧL3вбОДг35жмЦкдіМгЕНСЫ40жмЦкЃЈетЪЧДѓЛКДцЕФвЛИіЬиадЃЌЫќУЧЕФбгГйЛсЩдЮЂГЄвЛаЉЃЛетЪЧвЛИігаШЄЕФШЈКтЃЉЁЃAMDвбОЩљУїЫќвбОдіМгСЫДІРэL1КЭL2ЖЊЪЇЕФЖгСаЕФДѓаЁЃЌОЁЙмЩаЮДЯъЯИЫЕУїЫќУЧЯждкгаЖрДѓЁЃ
Infinity Fabric
ЫцзХZen 2ЕФЭЦГіЃЌЮвУЧвВзЊЯђСЫЕкЖўДњInfinity FabricЁЃIF2ЕФжївЊИќаТжЎвЛЪЧжЇГжPCIe 4.0ЃЌвђДЫзмЯпПэЖШДг256ЮЛдіМгЕН512ЮЛЁЃ

ОнAMDГЦЃЌIF2ЕФећЬхаЇТЪЬсИпСЫ27ЃЅЃЌЕМжТУПБШЬиЕФЙІКФИќЕЭЁЃЫцзХEPYCжаЕФIFСДТЗдНРДдНЖрЃЌетНЋБфЕУЗЧГЃживЊЃЌвђЮЊЪ§ОнДгchipletДЋЪфЕНIOаОЦЌЁЃ
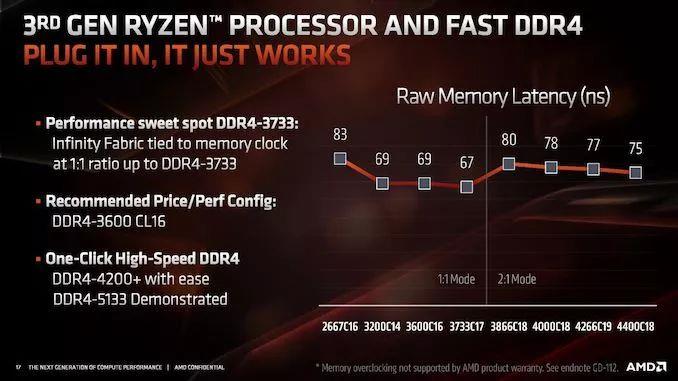
IF2ЕФвЛИіЬиЕуЪЧЪБжгвбОДгDRAMжїЪБжгжаЗжРыГіРДЁЃдкZenКЭZen+жаЃЌIFЦЕТЪгыDRAMЦЕТЪёюКЯЃЌетЕМжТСЫвЛаЉгаШЄЕФГЁОАЃЌдкетаЉГЁОАжаЃЌФкДцПЩвддЫааЕУИќПьЃЌЕЋIFжаЕФЯожЦвтЮЖзХЫќУЧЖМЪмЕНЪБжгЫјВНЬиадЕФЯожЦЁЃЖдгкZen 2ЃЌAMDвбОЮЊIF2в§ШыСЫБШТЪЃЌжЇГж1:1ЕФе§ГЃБШТЪЛђ2:1ЕФБШТЪЃЌПЩвдНЋIF2ЪБжгМѕАыЁЃ
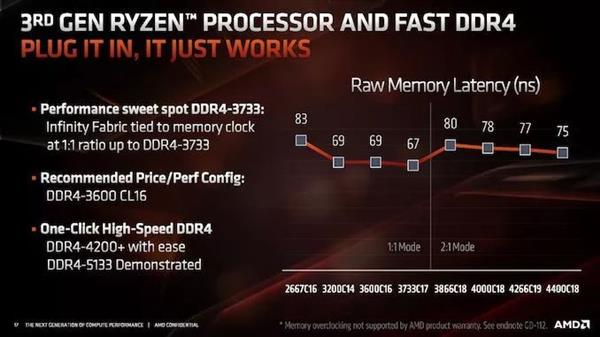
етИіБШТЪгІИУдкDDR4-3600ЛђDDR4-3800ИННќздЖЏЗЂЛгзїгУЃЌЕЋетШЗЪЕвтЮЖзХIF2ЪБжгМѕЩйСЫвЛАыЃЌетЖдДјПэгаГхЛїаЇгІЁЃгІИУзЂвтЕФЪЧЃЌМДЪЙDRAMЦЕТЪКмИпЃЌШчЙћIFЦЕТЪНЯТ§ЃЌдђПЩФмЛсЯожЦДгИУНЯПьФкДцЛёЕУЕФдЪМадФмдівцЁЃAMDНЈвщдкDDR4-3600ИННќБЃГж1:1ЕФБШР§ЃЌЖјЪЧдкИУЫйЖШгХЛЏsub-timingЁЃ
НсТлЃКЦНЬЈЁЂSoCЁЂКЫаФ
ЙЙНЈЯёZen 2етбљЕФКЫаФашвЊЕФВЛНіНіЪЧЙЙНЈКЫаФЁЃКЫаФЁЂSoCЩшМЦКЭЦНЬЈжЎМфЕФЯрЛЅзїгУвЊЧѓВЛЭЌЕФФкВПЭХЖгСЊКЯЦ№РДЃЌДДдьГіЕЅЖРЙЄзїЫљШБЗІЕФаЭЌЫЎЦНЁЃAMDдкchipletЩшМЦКЭZen 2ЗНУцЫљзіЕФЙЄзїБэЯжГіСЫОоДѓЕФЯЃЭћЃЌВЛНіПЩвдРћгУИќаЁЕФЙЄвеНкЕуЃЌЛЙПЩвдЮЊМЦЫуЕФЮДРДПЊБйвЛЬѕЕРТЗЁЃ
ЕБНјШыИќЯШНјЕФЙЄвеНкЕуЪБЃЌжївЊгХЕуЪЧЙІКФИќЕЭЁЃетПЩвдЭЈЙ§вдЯТМИжжЗНЪНРДЪЕЯжЃК дкЯрЭЌЕФадФмЯТНЕЕЭдЫааЕФЙІТЪЃЌЛђепЪЙгУИќЖрЕФЙІТЪдЄЫуРДзіИќЖрЕФЪТЧщЁЃЫцзХЪБМфЕФЭЦвЦЃЌЮвУЧдкКЫаФЩшМЦжаПДЕНСЫетвЛЕуЃКЫцзХИќЖрЕФЙІТЪдЄЫуБЛПЊЦєЃЌвдМАФкКЫжаЕФВЛЭЌЕЅдЊБфЕУИќИпаЇЃЌЖюЭтЕФЙІТЪБЛИќЙуЗКЕигУРДЧ§ЖЏФкКЫЃЌЯЃЭћФмЬсИпдЪМжИСюЫйТЪЁЃетВЛЪЧвЛИіШнвзНтОіЕФЮЪЬтЃЌвђЮЊДцдкаэЖрШЈКтвђЫиЃКZen 2КЫаФжаЕФвЛИіР§згОЭЪЧL1 IЛКДцЕФМѕЩйЪЙЕУAMDЕФmicro-opЛКДцдіМгСЫвЛБЖЃЌAMDЯЃЭћетбљФмЬсИпадФмКЭЙІКФЁЃЖдетаЉЙЄГЬЪІРДЫЕЃЌЪЕЪЉжСЩйдкИпВуДЮЩЯПЩааЕФЗНАИОЭЯёЭцРжИпвЛбљЁЃ
ОЁЙмШчДЫЃЌZen 2ПДЦ№РДКмЯёZenЁЃЫќЪєгкЭЌвЛИіЯЕСаЃЌетвтЮЖзХЫќПДЦ№РДЗЧГЃЯрЫЦЁЃAMDдкетИіЦНЬЈЩЯЫљзіЕФвЛЧаЃЌЦєгУPCIe 4.0ЃЌВЂЪЙЗўЮёЦїДІРэЦїАкЭбРрЫЦNUMAЕФЛЗОГЃЌЖМНЋгажњгкAMDЕФГЄдЖЗЂеЙЁЃAMDСМКУЕФЧАОАШЁОігкЫќПЩвдЧ§ЖЏЕФЗўЮёЦїВПМўЕФЦЕТЪгаЖрИпЃЌЕЋZen 2+ RomeНЋЛсзХСІНтОіZenЕФПЭЛЇЬсГіЕФДѓСПЮЪЬтЁЃ
змжЎЃЌAMDвбОдкZen 2КЭZen+ЕФЛљДЁЩЯЬсИпСЫ15%ЕФКЫаФадФмЁЃЫцзХКЫаФЕФБфЛЏЃЌдкИпВуДЮЩЯПДПЯЖЈЪЧПЩааЕФЁЃ зЈзЂгкадФмЕФгУЛЇЛсЯВЛЖаТЕФ16КЫRyzen 9 3950XЃЌЖјДІРэЦїдк105WЪБПДЦ№РДаЇТЪКмИпЃЌвђДЫПДПДЫќдкЕЭЙІКФЯТЛсЗЂЩњЪВУДЛсКмгаШЄЁЃЮвУЧвВЦкД§дкНгЯТРДЕФМИИідТФкRomeЭЦГіЗЧГЃЧПДѓЕФВњЦЗЃЌЬиБ№ЪЧЯёЫЋБЖFPадФмКЭQoSетбљЕФЬиадЃЌ64КЫЕФдЪМЖрЯпГЬадФмНЋГЩЮЊЪаГЁЕФвЛИігаШЄЕФЦЦЛЕепЃЌЬиБ№ЪЧМлИёгааЇЕФЛАЁЃЮвУЧКмПьОЭЛсФУЕНгВМўЃЌдк7дТ7ШеДІРэЦїЗЂВМЪБеЙЪОЮвУЧЕФЗЂЯжЁЃ
|















































































































































































































































































































![[MD:Title]](/img/20190613/1a77acafa06843b8bafb8a8827982e09.jpg)