Intel日前举办了Vision 2024年度产业创新大会,亮点不少,号称大幅超越NVIDIA H100的新一代AI加速器Gaudi 3、品牌全新升级的至强6、AI算力猛增的下一代超低功耗处理器Lunar Lake,都吸引了不少目光。
不过对于AI开发者、AI产业尤其是企业AI而言,这次大会上还有一件大事:
Intel联合众多行业巨头,发起了开放企业AI平台,推动企业AI创新应用,同时通过超以太网联盟(UEC)和一系列AI优化以太网解决方案,推进企业AI高速互连网络创新。

如今说到大规模AI部署,很多人脑海中会立刻浮现两个名字:
一个是OpenAI,大模型和算法的一枝独秀;另一个是NVIDIA,硬件算力和生态的典型代表。
但是每每说到NVIDIA,以及CUDA为代表的生态圈,其一贯以来的封闭做法颇为人所诟病,被誉为“硅仙人”的芯片开发大神 Jim Keller就一直对NVIDIA的做法极为不满,斥责CUDA不是护城河而是沼泽,NVLink这种私有互连标准也应该摒弃。
坦白说,NVIDIA AI不仅仅在硬件性能上“遥遥领先”,更大的资本正是耗费十几年时间和无数美元砸出来的CUDA生态,成为其“垄断行业”、获利无数的制胜法宝。
只不过时代在变化,无论企业还是开发者,都不希望被束缚在一个小圈子里,更希望在开放共享的世界里自由前行,这正好给了其他厂商追赶甚至超越NVIDIA的大好机会。
Intel就瞅准这一趋势和需求,联合Anyscale、Articul8、DataStax、Domino、Hugging Face、KX Systems、MariaDB、MinIO、Qdrant、RedHat、Redis、SAP、VMware、Yellowbrick、Zilliz等众多行业伙伴宣布,将联合创建企业AI开放平台,助力企业推动AI创新。

它将为企业AI提供一个从下到上的完整平台,底层基于Intel完整覆盖云、数据中心、边缘、PC各个领域的AI算力硬件,也就是XPU理念。
构筑其上的是标准化和可扩展的基础设施生态、安全可靠的软件生态、开放便捷的应用生态,而且全都是对整个行业开放的。
这一计划凝结了全行业的力量,旨在开发开放的、多供应商的AIGC系统,通过RAG(检索增强生成)技术,提供一流的部署便利性、性能和价值。
对于企业当前正在标准云基础设施上运行的大量专有数据源,RAG可以帮助他们通过开放大语言模型进行功能上的增强,从而加速AIGC在企业中的应用。

在Intel看来,坚持开源开放,并以此撬动开放的AI生态飞速发展,至关重要。
Intel副总裁、Intel中国软件和先进技术事业部总经理李映在接受采访时表示:“传统模式中,几家领导公司组建一个开放联盟,各自有明确分工,更多的是一个选择问题。如今基于AI大模型的变化,开放开源第一次和整个行业的技术创新爆发结合在一起。现在,开放开源和闭源同时出现,不再是选择,而是一个自然演变、发展的过程。”
Intel院士、大数据技术全球首席技术官、大数据分析和人工智能创新院院长戴金权也指出,一个开放的生态,可以让同一生态的创新相互促进,在新的应用场景可以互通。
整个行业都在逐渐意识到,构建一个AIGC应用,并不是只需要一个大模型,一些最先进的系统解决方案,其实更多的是相当于构建一个AI系统来解决问题。

在这个企业AI开放平台中,Intel的一个突出重点就是加快构建开放的AI软件生态,通过构建基础软件为开发者提供便利,帮助大企业简化和深入AI的大规模开发和部署。
李映指出,在开放AI软件生态方面,对于Intel而言,非常重要的一个点是如何通过软件加速企业AI的发展,如何把企业原来的云架构和未来基于大模型、数据的AI架构融合在一起。
软件可以在这个过程中起到非常重要的加速作用,而从整个软件堆栈的角度来讲,Intel正是极少数可以真正在各个层面上通过软件提供优化、提供技术的头部企业之一。
同时,Intel一直在极力推动基于AI的软件创新,最典型的就是oneAPI,下载量已经超过100万次。
第三就是如何帮助开发者提高开发效率,其中很重要的一部分就是Intel开发者云平台。
它不但可以让开发者最早接触到最新的至强、Gaudi AI加速器,还能保证各种开源框架、组件在同一环境中的兼容性,从而提升开发效率、优化用户体验。

另外非常值得一提的是,Intel也在积极为开源社区贡献技术、创新和经验,推进开放标准。
比如,PyTorch已逐渐成为标准的AI框架,Intel一直都是PyTorch非常靠前的重要贡献者,并以高级会员的身份加入了PyTorch基金会。
除了对PyTorch本身进行优化,Intel的一些技术创新都投入到了PyTorch开源框架之中,让更多企业和开发者共享,让整个AI软件框架更加开源、开放。
再比如openEuler、龙蜥这些开源的中国Linux社区,Intel对其的投入都已经和国际同步,甚至在某些领域领先于国际上其他一些Linux的分布和发展。


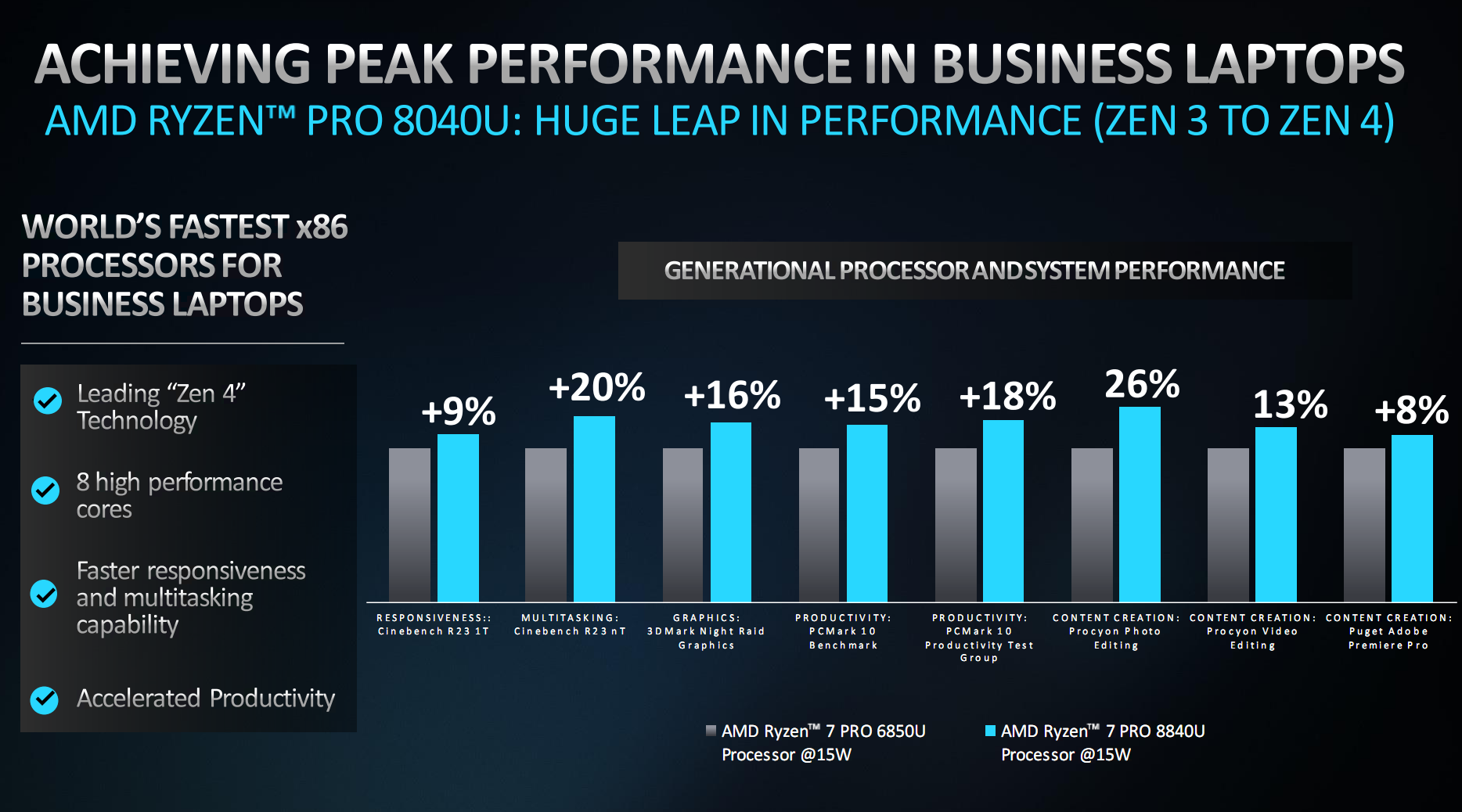
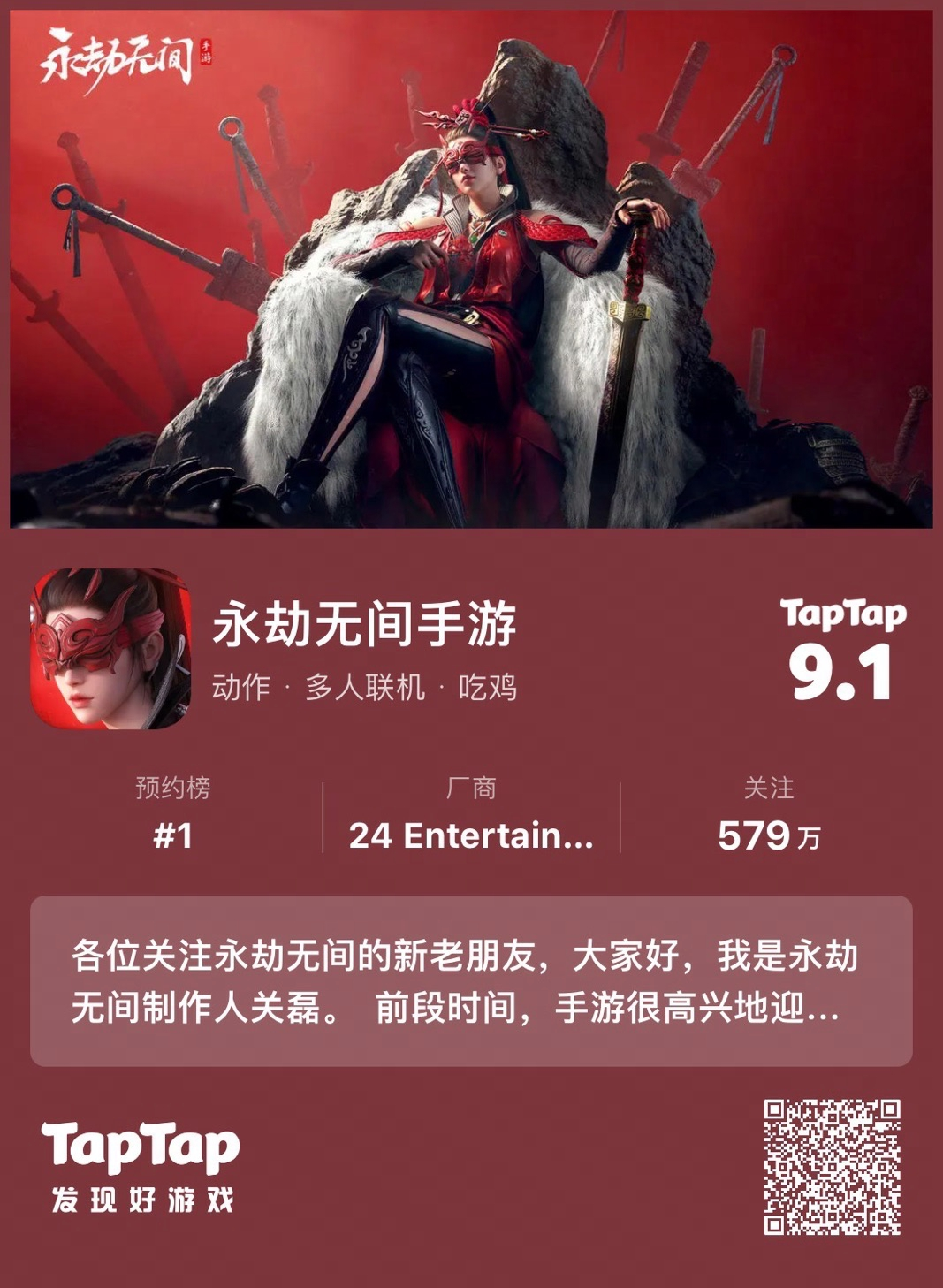
最后再来回顾一下Intel本次揭晓的三大算力产品。
Gaudi 3 AI加速器采用台积电5nm工艺,配备8个矩阵引擎、64个张量核心、96MB SRAM缓存、1024-bit 128GB HBM2E内存(带宽3.7TB/s),还有16个PCIe 5.0通道、24个2000GbE网络、JPEG/VP9/H.264/H.265解码器。
功耗有600/900W两个级别,提供OAM兼容夹层卡、通用基板、PCIe扩展卡三种形态。
Gaudi 3相比上代拥有2倍的FP8 AI算力(1835TFlops)、4倍的BF16 AI算力、2倍的网络带宽、1.5倍的内存带宽。
Intel还声称,它对比NVIDIA H100 LLM推理性能领先50%、训练时间快40-70%,能效领先最多达2.3倍。
另外,得益于强大、便捷的开发工具,开发者最少只需改变3行代码,就能将其他AI应用移植到Gaudi 3之上。

全新的至强6包含两个分支,其中Sierra Forest第二季度发布,堪称至强处理器历史上最大的一次变革,首次采用纯能效核(E核)设计。
它重点针对效率进行优化,适合高密度、可扩展的工作负载,最多288核心288线程。
按照官方说法,相比第二代至强,Sierra Forest可以带来2.4倍的能效提升,机架密度则可以提高2.7倍。
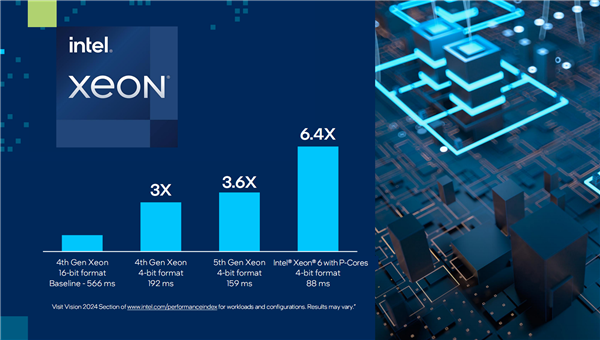
Granite Rapids则是传统的纯性能核(P核)设计,重点针对性能优化,适合计算密集型应用和高强度的AI负载。
它新增了对MXFP4数据格式的软件支持,能够运行700亿参数的Llama 2大模型,对比四代至强能将令牌延迟缩短最多6.5倍。

代号Lunar Lake的下一代超低功耗酷睿Ultra处理器,AI算力将超过100TOPS(100万亿次每秒),是现有一代酷睿Ultra Meteor Lake的足足三倍!
其中,单单是NPU单元就可以提供大约45TOPS的算力,是目前的多达四倍,自己即可满足微软定义下一代AI PC的需求。
可以说,Intel拥有目前最为完善的AI体系,从底层覆盖云端、数据中心端、边缘端、客户端的XPU硬件算力,到上层的网络方案、开发工具,再到广泛的生态合作,如今又组建了开放的企业AI平台,可以说万事俱备,在AI训练与他推理、AIGC领域必定会有一番作为。

|