老差友应该都知道互联网档案馆(下称 archive.org ),咱介绍好几次了。
还不知道的兄弟自己找找原因,是不是不够帅,没早关注帅逼公众号:差评。

archive.org 由 Brewster Kahle 创办,是一个非营利性的数字图书馆。
从 1996 年起,它每隔一会就会抓取各种各样的网页、视频、图片等资料,保存在 “ 图书馆 ” 。
目前图书馆里存了 8660 亿个网页,1200 万个视频,490 万张图片和 110 万个软件程序。
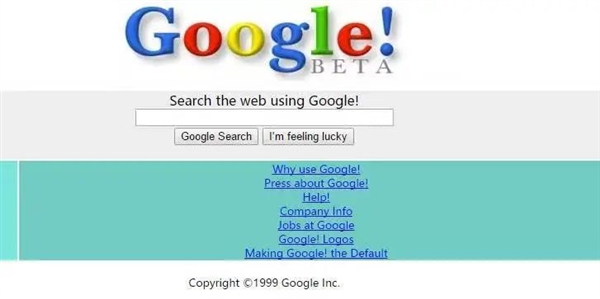
点进网站,从 MJ 演唱会视频,到 1999 年测试版的 Google 搜索页面,再到你多年前送给凤姐的表白,都会重新进入你的世界。
不过,今天故事的主角不是这位,而是另一个档案馆 archive.today (今日档案 )。
archive.today 于 2012 年创办。从名字和功能上看,它类似于archive.org ,可以备份网页。
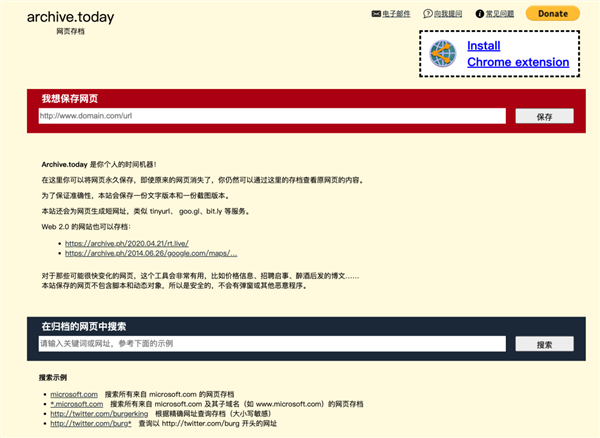
但它俩之间还是有个很大区别——
archive.org 类似于搜索引擎,绝大多数资料都是爬虫自动抓取的。所以一直以来他们都遵守 robot.txt 。
robot.txt 是互联网里通行的一个君子协议。通过它,网站可以告诉搜索引擎,哪些东西它不能抓。百度里搜不到微信文章和淘宝商品,就是因为 robot.txt 。
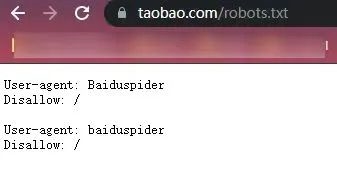
但 archive.today 不遵守这个协议,即便网站不让它存,它也会霸王硬上弓。
不过,这也不能说 archive.today 缺德。
因为它并非自动抓取别人的网站,只有用户上传某个网页时,它才会抓取。
存档 ing..... ▼

目前,archive.today 已经存储了 5 亿个网页。虽然远不及 archive.org ,但这种大家主动寻求备份的网页,相对来说,它的意义和价值会更大点。就像三年前,有位吴彦祖备份了差评的官网,明显是肯定了咱们,咳咳。
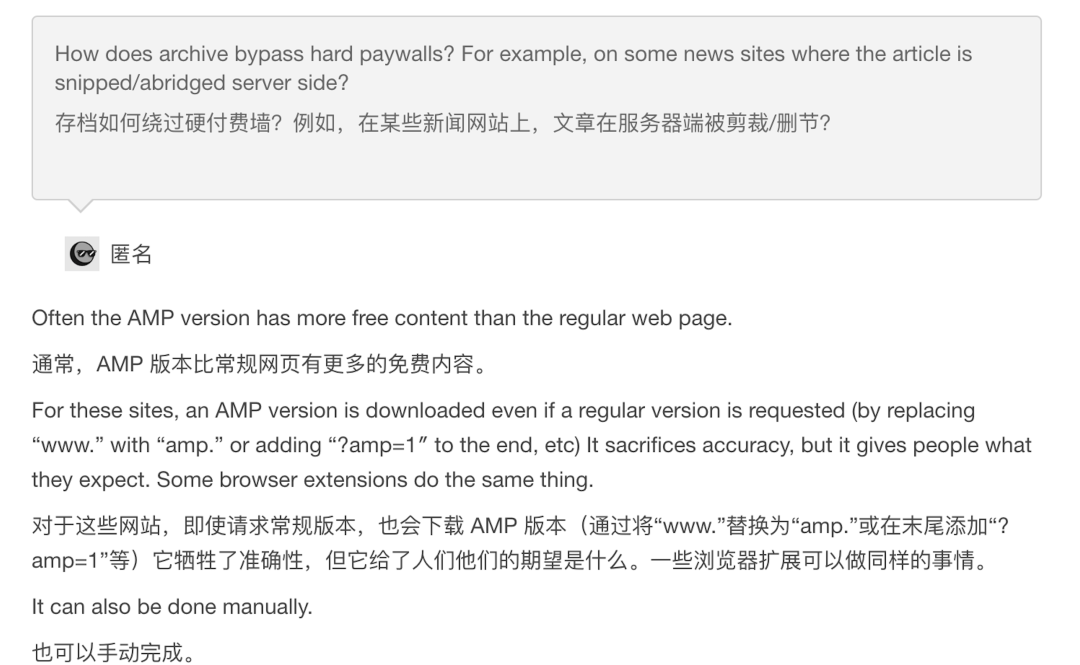
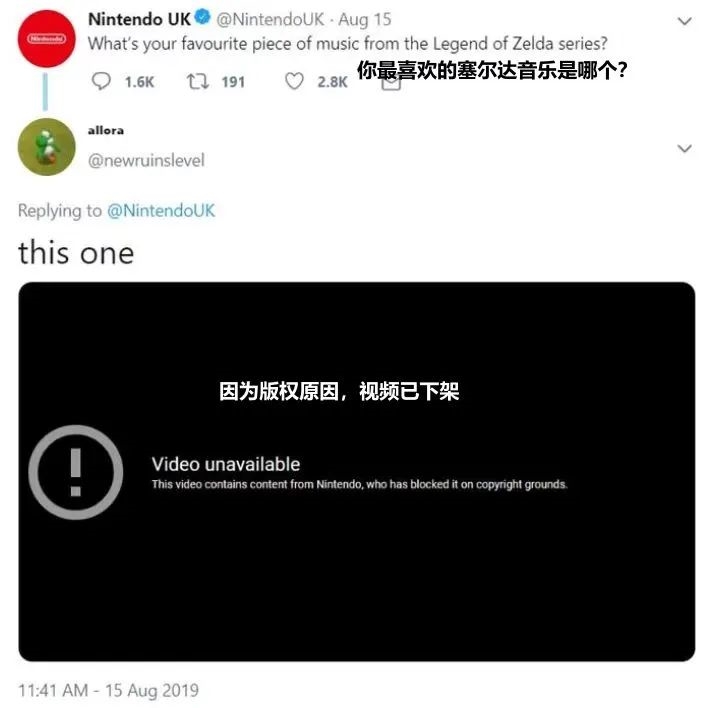
除了可以备份网页,因为技术上一些细节,人们发现 archive.today 有另外一个妙用:翻越付费墙。
对于那些订阅费动辄几百美刀的西方媒体,很多第三方世界国家的读者不光无力支付,甚至压根没有匹配的支付方式。
但自从这个功能被发现后, archive.today 成为了大家心照不宣的 “ 白嫖 ” 工具。只要有好心人存档了付费文章和有版权的学术论文,后来的读者都可以看到。
还有不少人基于这个网站做了一些小工具,让白嫖变得更简单。

编辑部偶尔也用过它,有一些东西在这上面确实比较好找。
虽然 archive.today 管理员曾说过,翻阅付费墙不是网站本意,只是技术问题上产生的一些 “ 意外 ” 。但想到他愿意冒着被诉讼风险默许这个情况存在,甚至教读者一些白嫖技巧。。。
差评君更愿意相信,他就是一个知识自由的支持者。
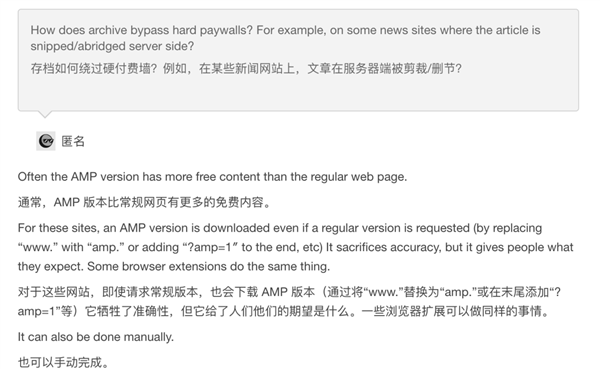
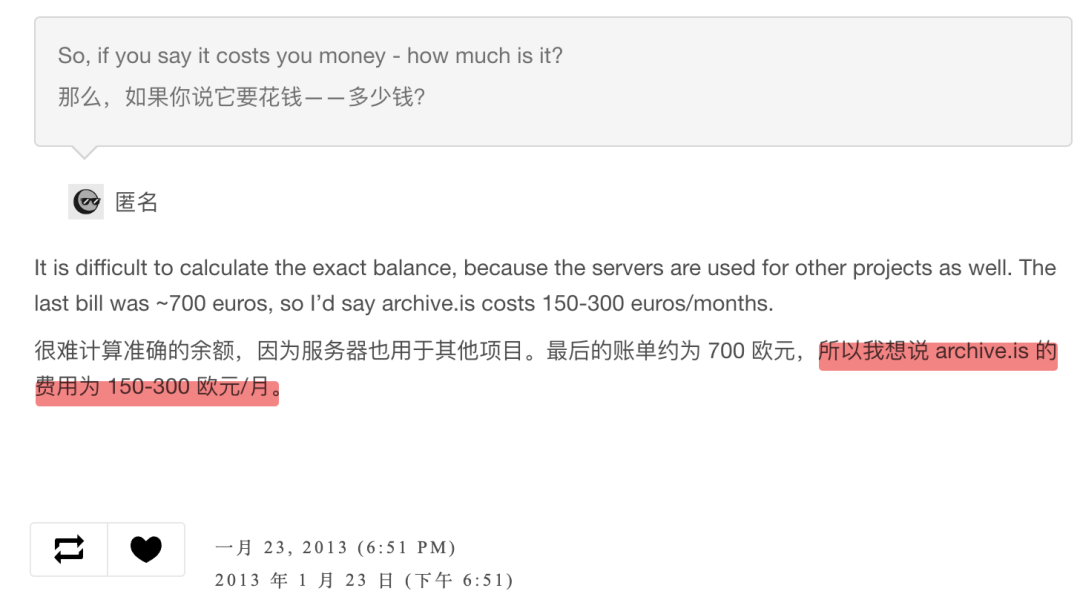
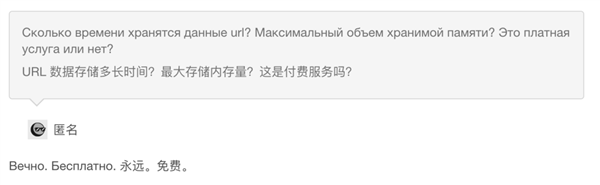
根据网站里问答纪录,2013 年的时候,存储这些档案每月要在服务器上花 300 欧元。
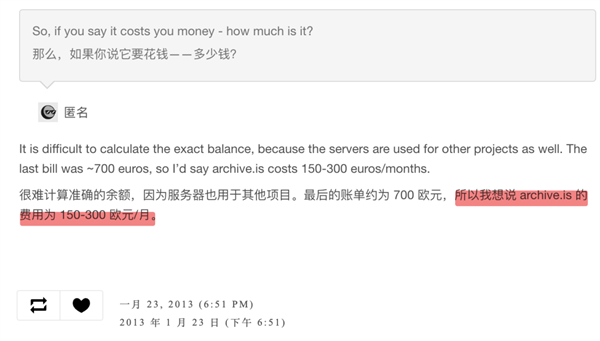
2014 年,随着网页越来越多,服务器成本升到了 2000 美元 / 月。2016 年,这个数字涨到了 4000 美元。

那问题来了,这些服务器的钱谁出呢?我们知道,archive.org 的背后是一家组织,总部在旧金山。它的年度预算有 1000 万美元,这些钱来自于它的合作赞助商和基金会。
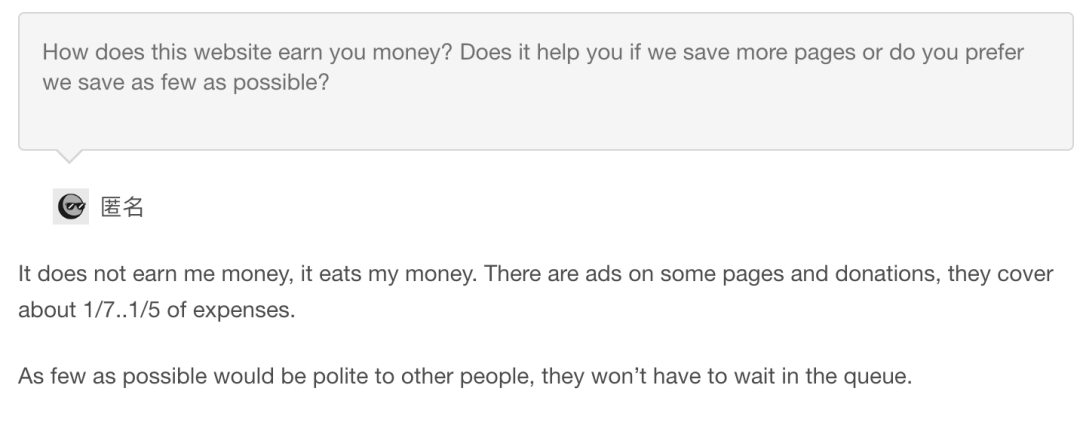
但 archive.today 管理员说,这个网站全靠自己。尽管网页在移动端开始投放广告,并且管理员也开放了捐赠通道,但这些只够 14% ~ 20% 的成本。
也就是说这个网站的管理员,每天在面临版权诉讼的风险下,既要维护网站日常运营,还有隔三差五回答网友各种问题,最后每个月还得掏出几千美金的服务器租金,只为维持这么一个免费网站?并一路坚持了十多年?这个赛博菩萨到底是谁啊?
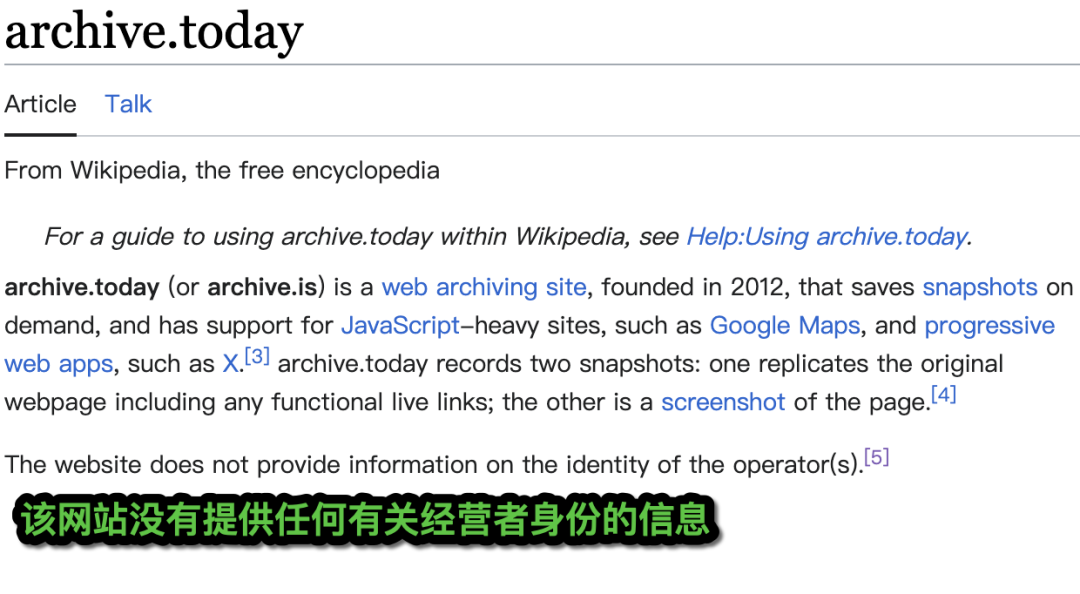
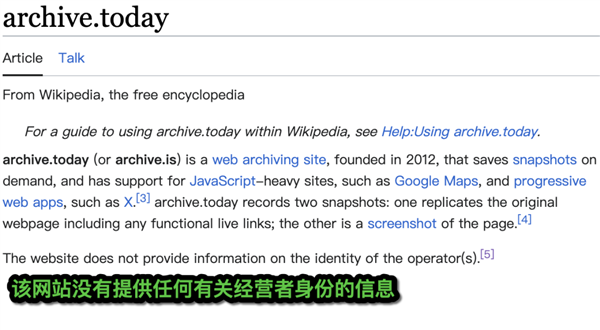
报以好奇和敬意差评君去网上搜了一下,但发现 archive.today 的背后,是一个迷。维基百科上关于经营者的身份,只写了一句话:
事实上,没人知道他的真实身份。半年前一位悉尼的工程师 Jani 花了很大精力,想看看 archive.today 幕后神秘人到底是谁。
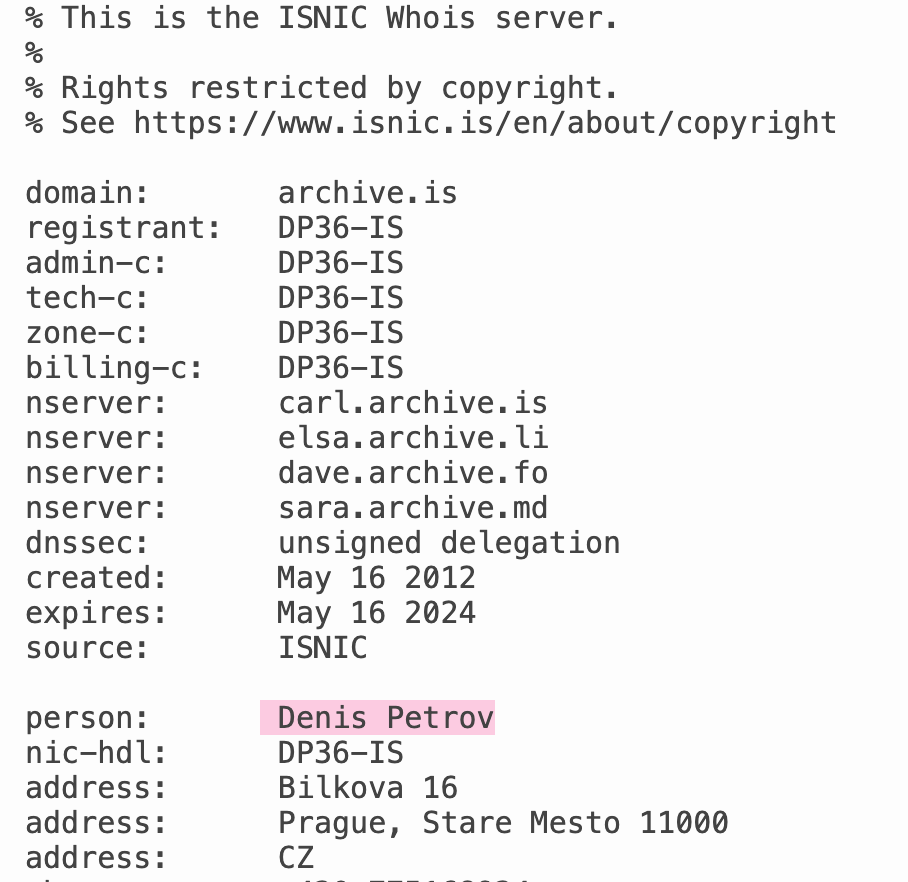
首先,网站能追溯到的第一个历史纪录是在 2012 年 5 月 16 日,网站一开始的域名叫 archive.is。由一个来自捷克布拉格,名叫 “ Denis Petrov ” 的人注册。
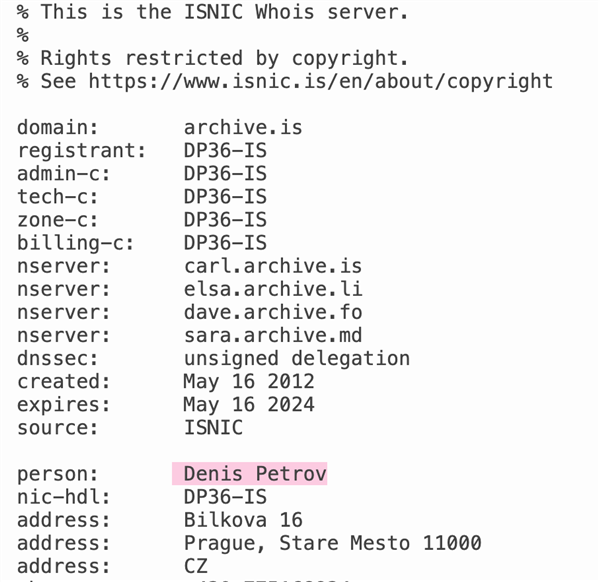
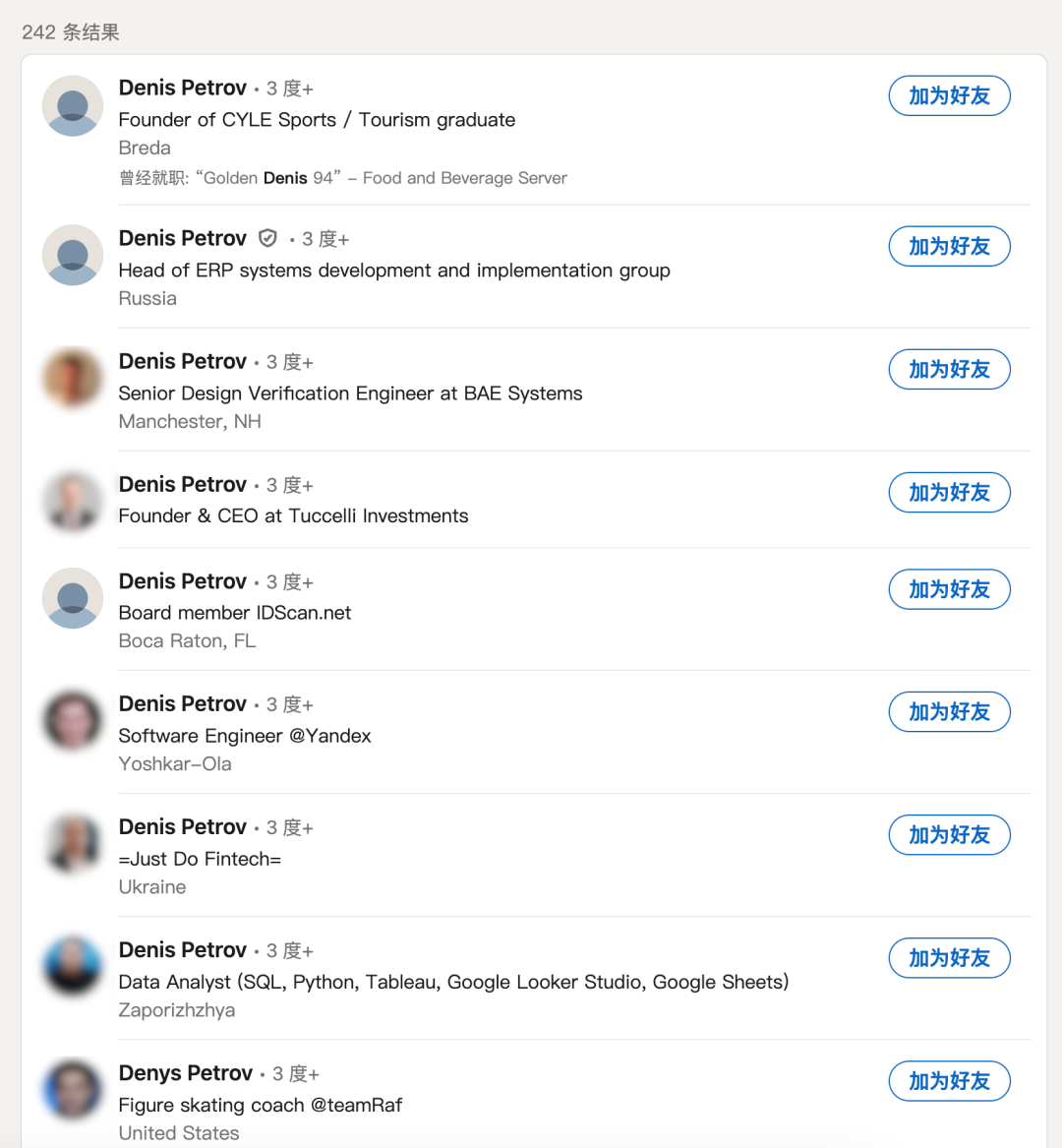
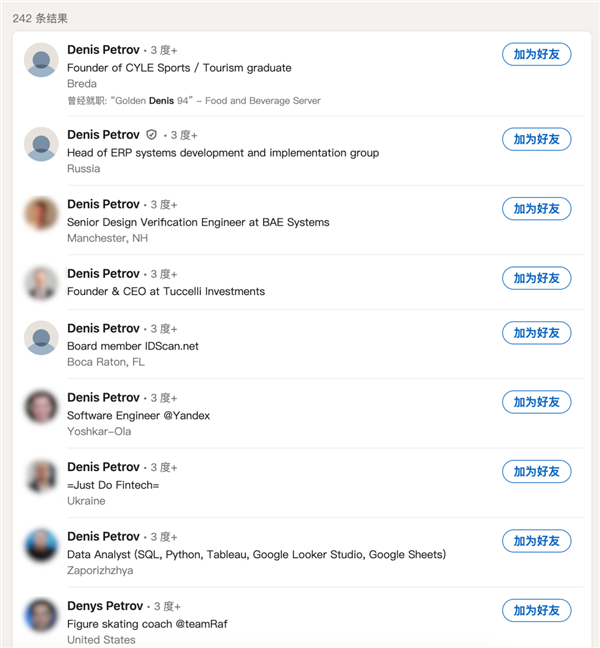
Denis Petrov ,是第一个线索。但随着调查, Jani 察觉 Denis Petrov 可能是假名。一来这是很常见俄罗斯名字,光是在领英里就有 242 个同名好哥们。
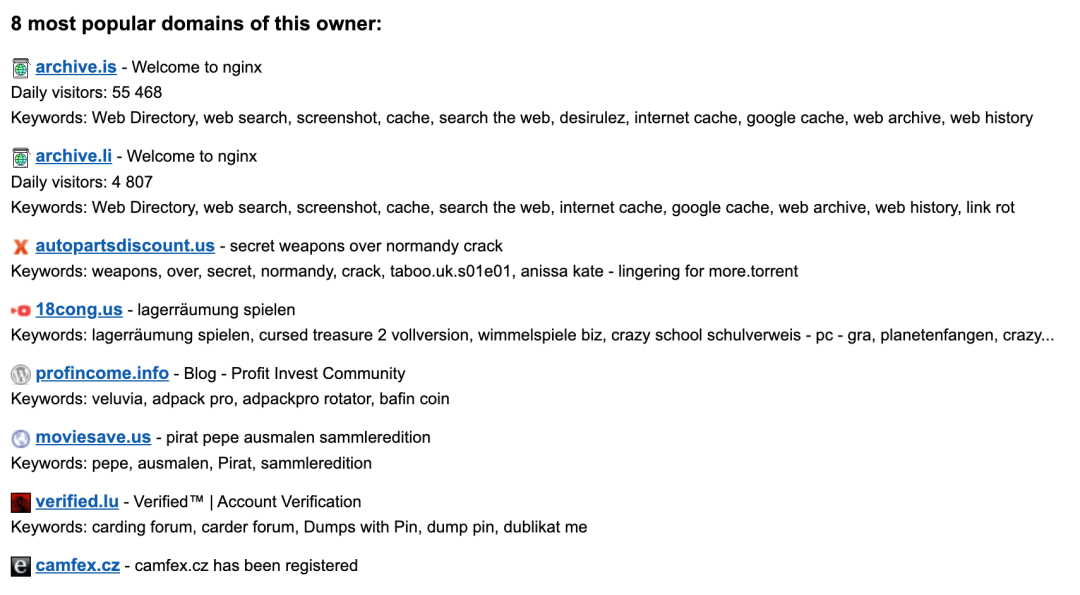
二来 Jani 发现同样的名字和联系方式还注册了一堆乱七八糟的域名。
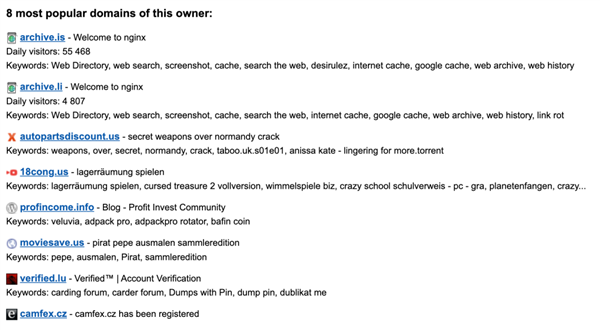
后来 Jani 还验证了很多带有这个名字的网站,如 denispetrov.com、denis.biz 、petrov.net。但大部分网站都已经停运了,唯一能打开的那个,只是一位纽约程序员的博客,早在 2011 年就已停更了。Denis Petrov 这个线索似乎断了。。。
和 Jani 一样,这些年也有其他网友探索过这位神秘人,但大多数人都停在了 “ Denis Petrov ” 的阶段。
倒是 2020 年,有另一个网友找到了神秘人的重要线索。他发现 archive.today 里所有领英网的备份,都基于同一个登录账户。这里我解释一下,诸如领英、 Instagram 这类应用,都要求登录账号后才能浏览详情。
我猜测神秘人是用了自己账号 cookie ,来抓取领英的网页内容。
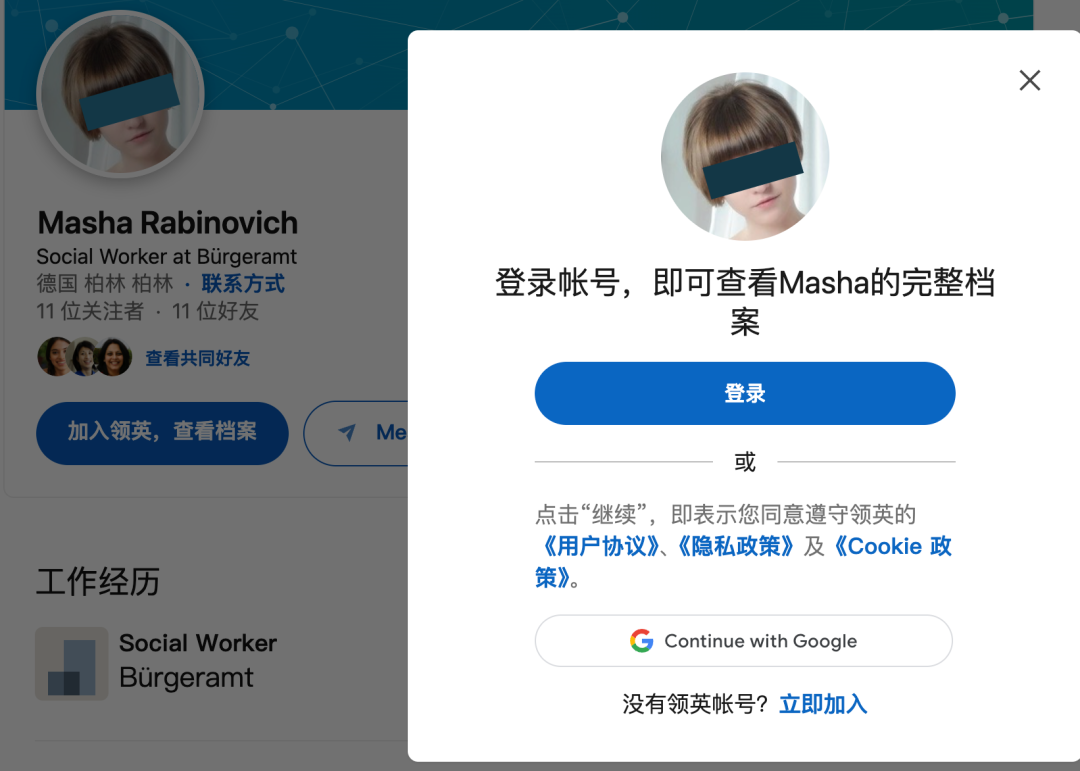
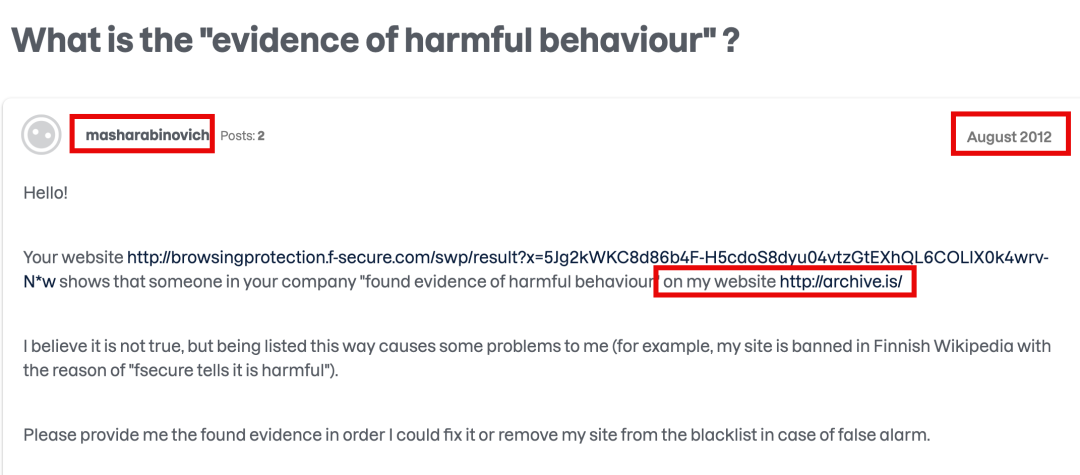
顺着线索,他找到了一个名为 Masha Rabinovich 的领英账号。账号显示,她有德国柏林某个大学的学士学位。
如果这个头像确实是本人,那说起来你可能不信,这个神秘人居然是一个留着波波头,有点娃娃脸的女生。手动码一下另外这个头像应该被删了,登录后就不可见 ▼
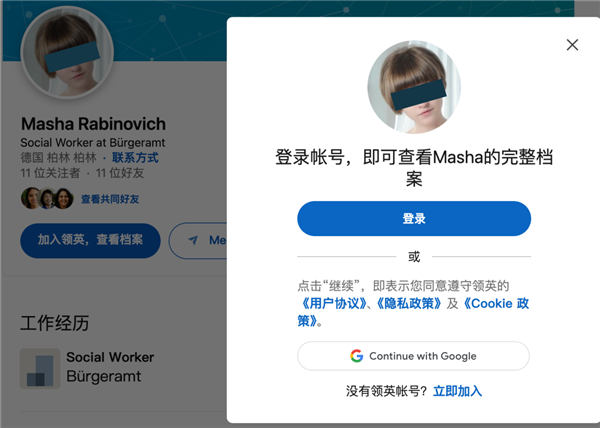
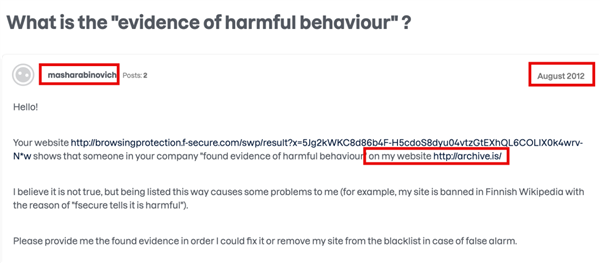
有人把 Masha Rabinovich 放进谷歌搜索,发现了一个 2012 年帖子,基本实锤 Masha Rabinovich 就是那个神秘人。当时一位昵称为 masharabinovich 用户发帖子,吐槽自己网站 archive.today 被恶意举报,进了黑名单。
既然名字 “ 确认 ” 了,接下来就是网友们发挥福尔摩斯天赋的时候了。
他们发现 Masha Rabinovich 曾多次参与了维基词条的编辑,最多的就是 “ 俄罗斯护照 ” ;名字中的 “ Masha ” ( Маша )是玛丽亚的常见俄语说法, Rabinovich 是德国犹太人的姓氏;
另外 archive.today 用的分析引擎是俄国的,回答问题时会使用一些大写词汇,可能有德国背景。
基于这些信息,网友推断出,神秘人大概是一个曾在德国留学的俄罗斯人,且学识渊博,英语流利。至于“ Masha Rabinovich ”,还不一定是其真名。也许和 Denis Petrov 一样,只是神秘人在网络世界的马甲之一。
虽然大家仍无法确定神秘人真实身份,但差评君觉得点到为止,他隐藏起来一定有自己的原因。相比起来,我认为神秘人的个性更值得一提。
在 archive.today 的网站上,有一个基于 Tumblr 问答服务的页面。通过这些 Q&A ,我推断神秘人是一个偏执且不喜欢被吹捧的技术极客。
首先就是我们前面说的,不遵守 robot.txt 。
其实这是个非常激进的行为,很容易被以版权法提起诉讼,或者在道德上落下风。
像 archive.org 后来也推出了手动备份的功能,但用户上传网页后,它还会检查一遍 robot.txt ,如果网站不同意被抓取, archive.org 还是会删除的。
但 archive.today 可不管这些。
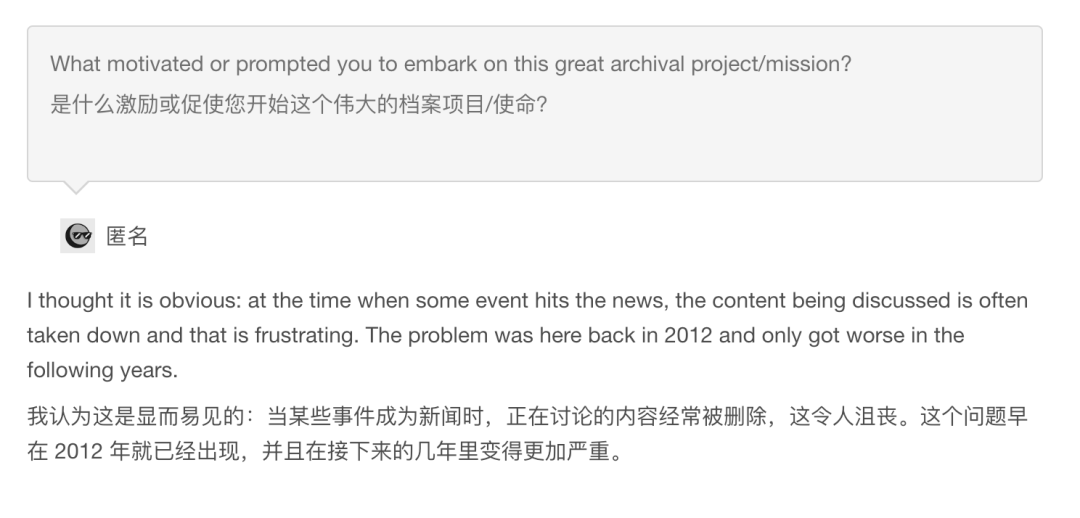
我觉得这么做,是因为他创建网站的初衷就是尊重历史,保存历史。
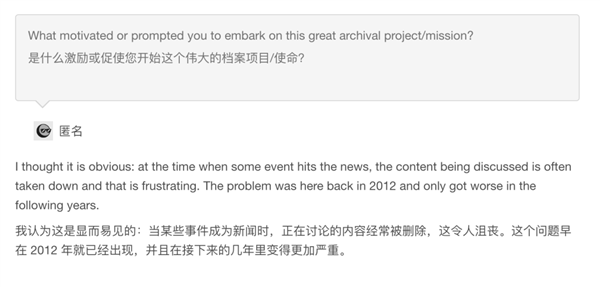
他也说过,网站即便存档了假新闻,也不会删除。
因为 archive.today 从来不是权威的参考来源,而是历史的见证。
它只是在告诉大家,在某个时刻,互联网上某一处存在过这样的页面。这一点差评君也认可,历史不是纪录大事记就够了,它是由无数细节拼凑起来才够完整。
虽然 archive.today 看似有点极端,但也不是所有网页都一视同仁。如果存档确认为恐怖分子的宣传网页、儿童色情等,收到举报后他也会删除。
另外神秘人很低调,从不希望自己被抬得很高。
当网友把他和 archive.org 放在一起夸奖时,他都会否定,说自己没有想保存整个互联网的目标,目前只有 archive.org 的百分之一,且运作方式不同。
差评君觉得,这是每一个老板都要学习的不画大饼精神。他知道自己一个人 / 团队的能力有限,做不到那么宏大的目标,一开始就没设想过这么多。
但 12 年了,网站帮大家存档了五亿多个网页,遇到了无数难题,并依旧坚持免费。
我觉得他和 archive.org 一样,都是令人尊敬的。
不过最近的情况,让差评君觉得网站的生存环境不容乐观。
因为神秘人回答网友问题的频率明显变低了,从两年前月均回答 40 个问题,到现在隔了好几个月才回答 2 个问题。
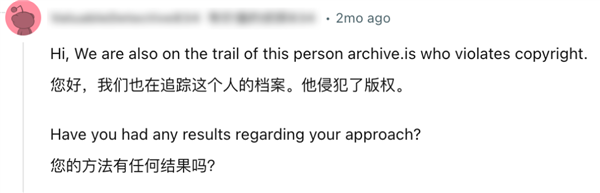
他也曾说网站经常被 DDOS ,时不时瘫痪。在互联网各个角落也有 “ 版权仇家 ” 在搜寻他的真实信息。至于诉讼,那也是迟早的事情。
结合历史来看,这种情况其实是必然的。
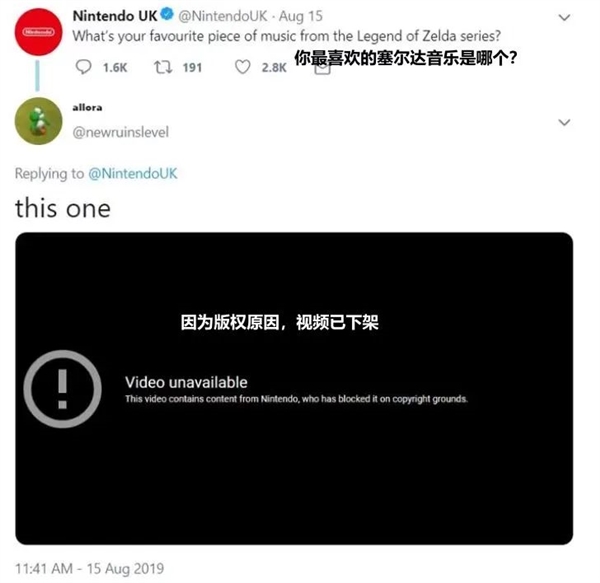
所有支持知识自由的网站,从archive.org 到 Sci-hub ,他们都遭遇过版权法的铁拳或者域名的封锁。
互联网档案馆因为把 140 万实体书扫描出来,不限量租借给读者,被四家出版商联合起诉,还有六千名作家签了请愿书支持这场诉讼。

Sci-hub 因为把 8000 多万学术论文爬取下来,免费分享给所有学者,在多个国家被出版巨头起诉。创始人 Alexandra Elbakyan 为了躲避各国引渡风险,在世界各地躲藏。

我知道,有很多人都抵制他们这种行为,认为盗版就是犯罪,不是解决问题的方式。
但世界不是非黑即白, “ 盗版 ” 就一定不被提倡吗?
这个问题几十年来一直争论不休。
90 年代,互联网上各种盗版电影和音乐横飞、破解和盗版软件横行。明明是赤裸裸的侵权,但却没有明确的法律能治一波乱象。
在这样的背景下,《 数字千年法案 》登场了。它以刑事犯罪立法的形式,希望在网络这块无主之地上,重振版权保护的权威。

毫无疑问,它保护了无数原创者的权利,让人们获得了相应的回报,也让他们的心血没有被盗版商肆意践踏。
可《 数字千年法案 》在保护版权的同时,似乎也催产了一些版权流氓到处碰瓷,让很大一批人也难以接触到优秀的作品。如何做到版权和知识自由兼顾,很难很难。
“ 科学和教育资源,就不应该有所谓的知识产权和资本运作的存在 ” 这是 Sci-hub 传达的理念之一。
从 archive.org 到 Sci-hub 再到 archive.today ,他们把无法翻越的信息壁垒,难以打破的知识桎梏,都变成一个简单的回车键,让我们看到了世界的另外一种可能。
不管怎么说——
Brewster Kahle 、 Alexandra Elbakyan 、神秘人以及所有那些不追求利益去捍卫知识自由的人,他们都值得我们的尊重和敬佩。
撰文:刺猬 编辑:莽山烙铁头 面线 封面:焕妍图片、
资料来源:
blog.archive.today
archive.today: On the trail of the mysterious guerrilla archivist of the Internet
Wikipedia:archive.today
Vice:Dear GamerGate: Please Stop Stealing Our Shit
https://website.informer.com/
|