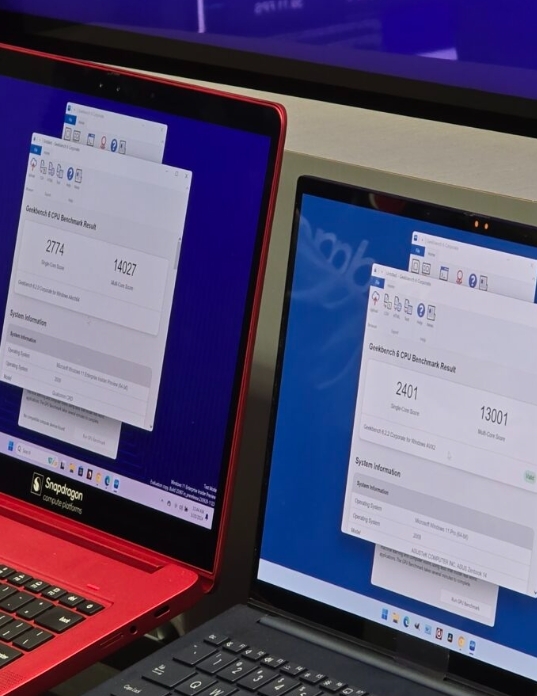
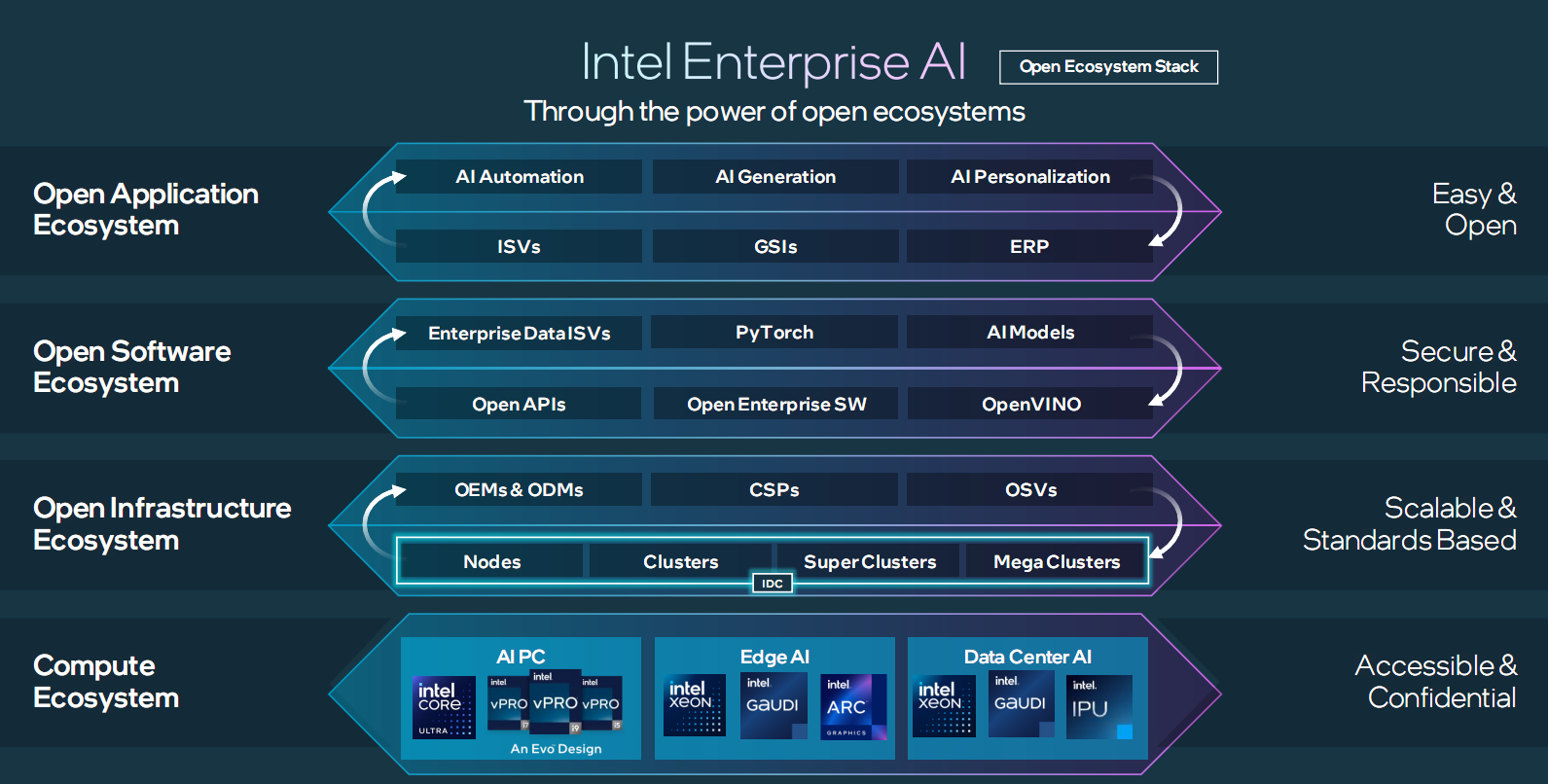
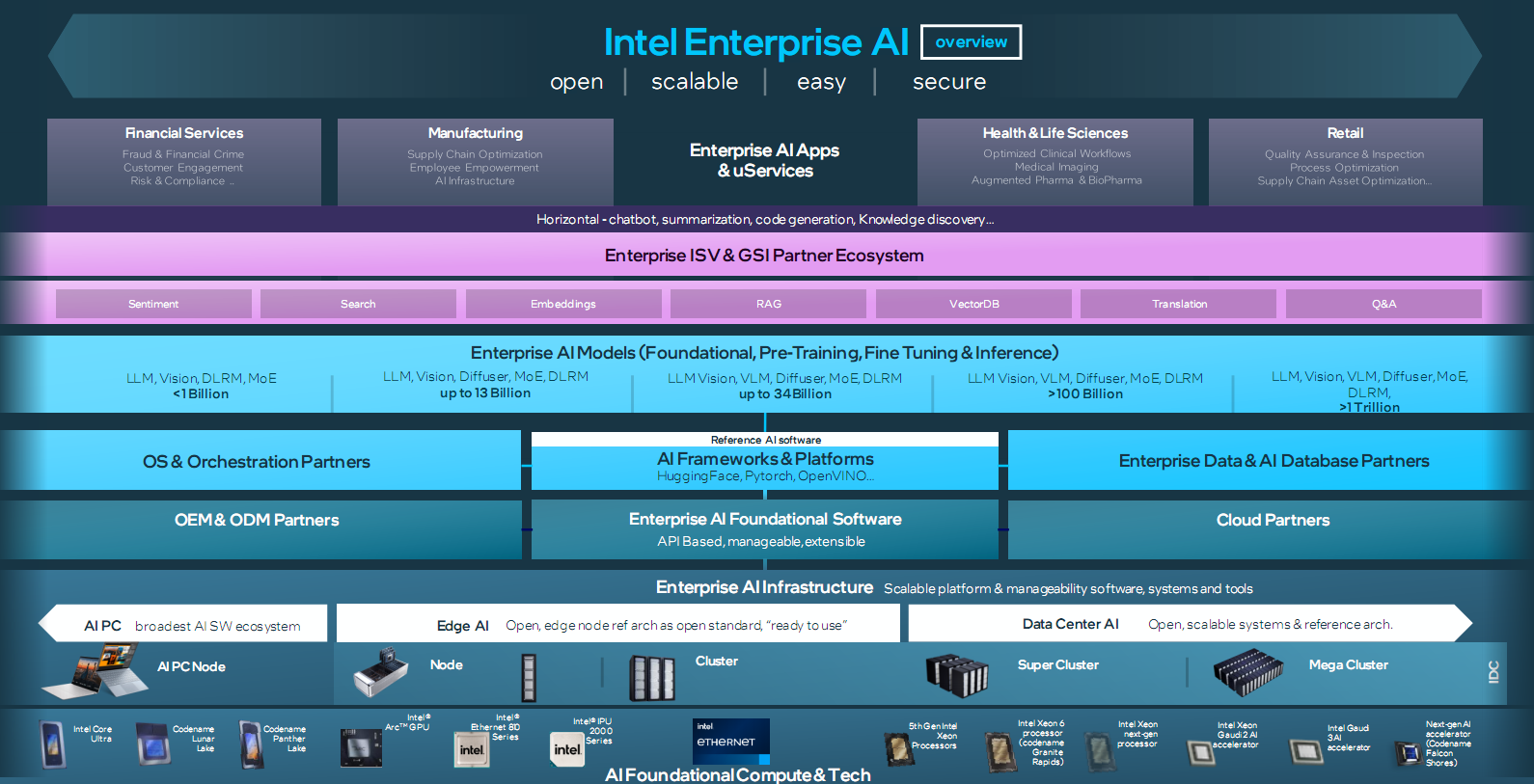
北京时间4月9日晚间,Intel在美国召开了“Intel Vision 2024”大会,介绍了Intel在AI领域取得的成功,并发布了新一代的云端AI芯片Gaudi 3及第六代至强(Xeon)可扩展处理器,进一步拓展了Intel的AI产品路线图。

AI芯片市场的巨大机遇
在生成式AI持续爆发背景之下,市场对于AI芯片的需求正高速增长。根据市场研究机构Gartner最新预测,到2024年AI芯片市场规模将较上一年增长 25.6%,达到671亿美元,预计到2027年,AI芯片市场规模预计将是2023年规模的两倍以上,达到1194亿美元。
Intel也表示,到2030年,半导体市场规模将达1万亿美元,人工智能是主要推动力。创新技术正在以前所未有的速度发展,每家公司都在加速成为AI公司,这一切都需要半导体技术提供支持。从PC到数据中心再到边缘,Intel正在让AI走进千行百业。

在边缘AI市场,Intel已经发布了涵盖Intel酷睿Ultra、Intel酷睿、Intel凌动处理器和Intel锐炫显卡系列产品在内的全新边缘芯片,主要面向零售、工业制造和医疗等关键领域。
Intel边缘AI产品组合内的所有新品将于本季度上市,并将在今年年内获得Intel刚刚发布的Intel Tiber边缘解决方案平台的支持,以简化企业软件和服务的部署,包括生成式AI。
对于去年推出的面向AI PC产品的Intel酷睿Ultra处理器,凭借强大的AI内核,为生产力、安全性和内容创作提供了全新能力,并为企业焕新其PC设备提供了巨大动力。Intel预计将于2024年出货4000万台AI PC,以及超过230种的设计,覆盖轻薄PC和游戏掌机设备。
同时,Intel透露将于2024年推出的下一代Intel酷睿Ultra客户端处理器家族(代号Lunar Lake),将具备超过100 TOPS平台算力,以及在神经网络处理单元(NPU)上带来超过46 TOPS的算力,从而为下一代AI PC提供强大支持。
在面向云端的数据中心市场,Intel在2022年就推出了AI加速芯片Gaudi 2,在去年年底还推出了集成了AI内核的代号为“Emerald Rapids”的面向数据中心的第五代 Xeon处理器。
Intel公司首席执行官帕特·基辛格表示:“创新技术正在以前所未有的速度发展,每家公司都在加速成为AI公司,这一切都需要半导体技术提供支持。从PC到数据中心再到边缘,Intel正在让AI走进千行百业。Intel最新的Gaudi、至强和酷睿平台将提供灵活的、可定制化的解决方案,满足客户和合作伙伴不断变化的需求,把握住未来的巨大机遇。”
Gaudi 3:BF16性能提升4倍,支持1800亿参数大模型
而在云端AI加速芯片市场,Intel早在2019年12月就斥资20亿美元收购Habana Labs(其于2019 年 7 月推出了 Gaudi 1 加速器),虽然当时英伟达在AI芯片市场的体量还很小,但是在AI芯片的技术积累上,英伟达更为深厚。因此,我们可以看到,当2022年Gaudi 2 推出之时,其也只能与英伟达A100进行对标。
为了进一步加强在云端AI加速芯片市场的竞争力,在此次“Intel Vision 2024”大会上,Intel正式推出了全新的Gaudi 3。虽然整体得到了大幅提升,但是依然只能是与英伟达上一代的H100/H200竞争。
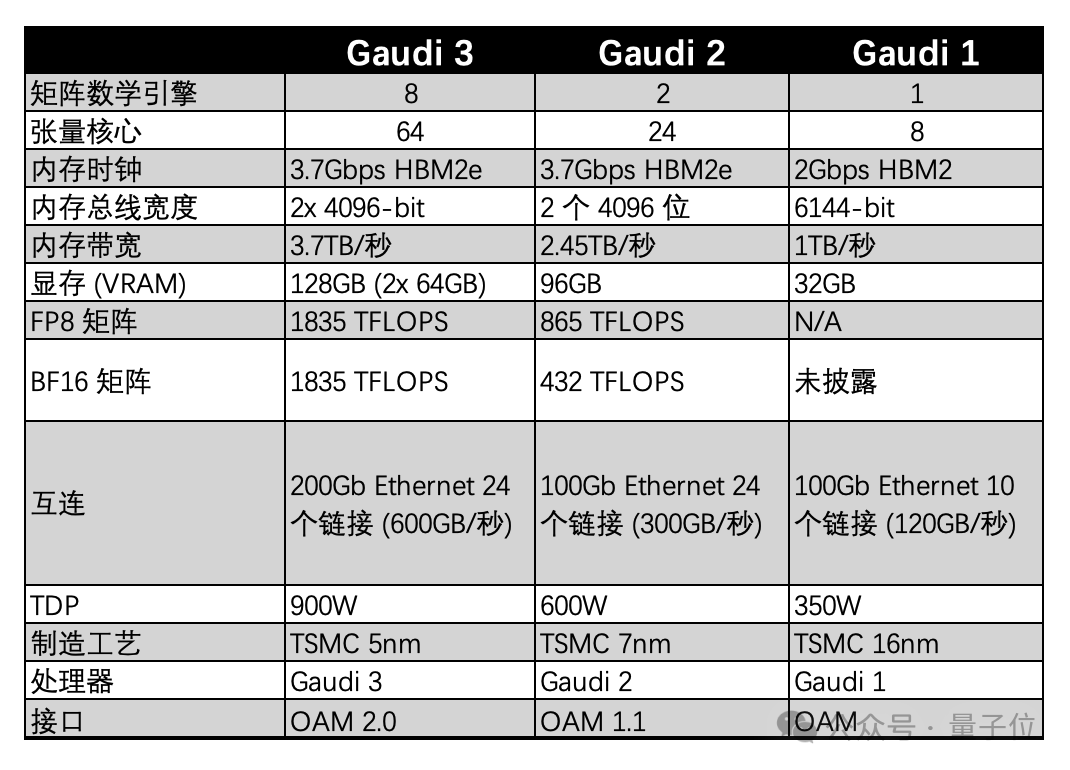
据介绍,Gaudi 3采用的是台积电5nm工艺,在芯片设计上,Gaudi 3转向了具有两个计算集群的Chiplet的设计,而不是Gaudi 2所采用的单个集群的方案。
Gaudi 3 拥有 8 个矩阵数学引擎、64 个张量内核、96MB SRAM(每个Tile 48MB,可提供12.8 TB/s的总带宽) 和 128 GB HBM2e 内存,16 个 PCIe 5.0 通道和 24 个 200GbE 链路 。
在计算核心的周围,则是八个HBM2e内存堆栈,总容量为128 GB,带宽为3.7 TBps。


与上一代的Gaudi 2 相比,Gaudi 3在BF16工作负载方面的性能将是Gaudi 2的四倍,FP8性能也将是Gaudi 2 的两倍,网络性能也是Gaudi 2的两倍(Gaudi 2是24个内置的100 GbE RoCE Nic),HBM容量是Gaudi 2的1.5倍。

另外,Gaudi 3 设备中的张量内核支持与 Gaudi 32 相同的 FP32、TF32、BF16、FP16 和 FP8 数据格式,并且不支持 FP4 精度。相比之下英伟达新的Blackwell GPU 将支持 FP2 精度,而英伟达现有的 Hopper GPU 则不支持。
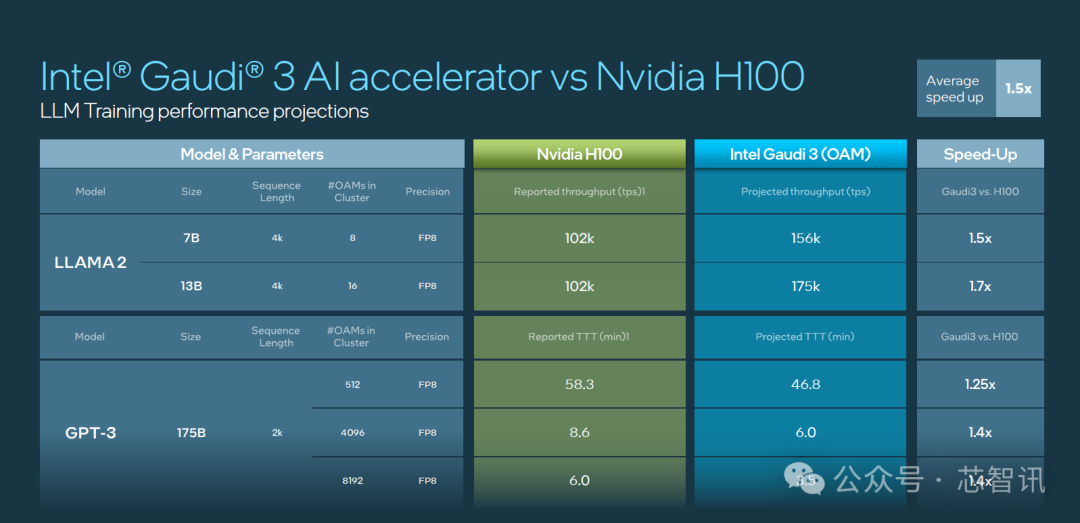
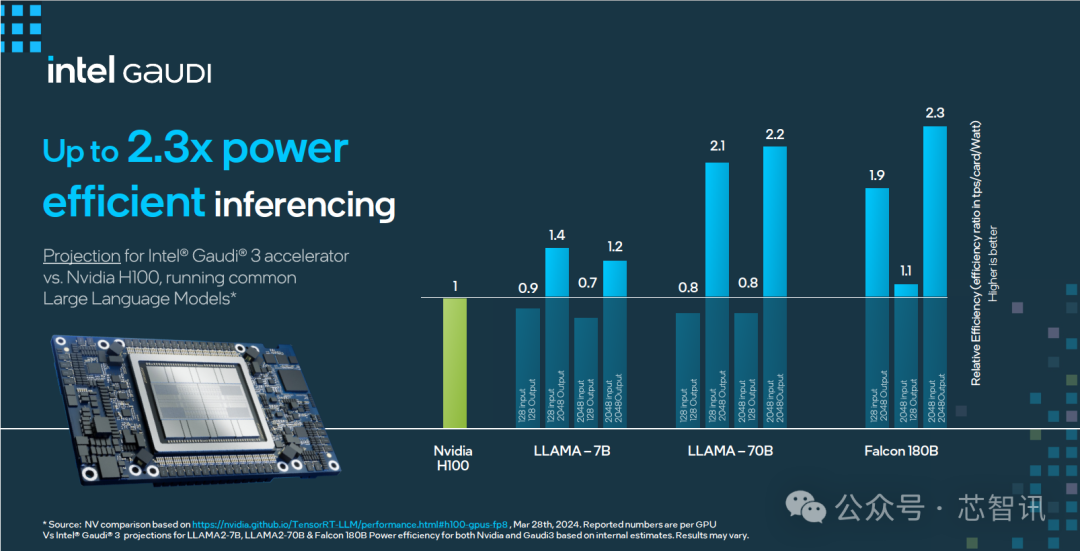
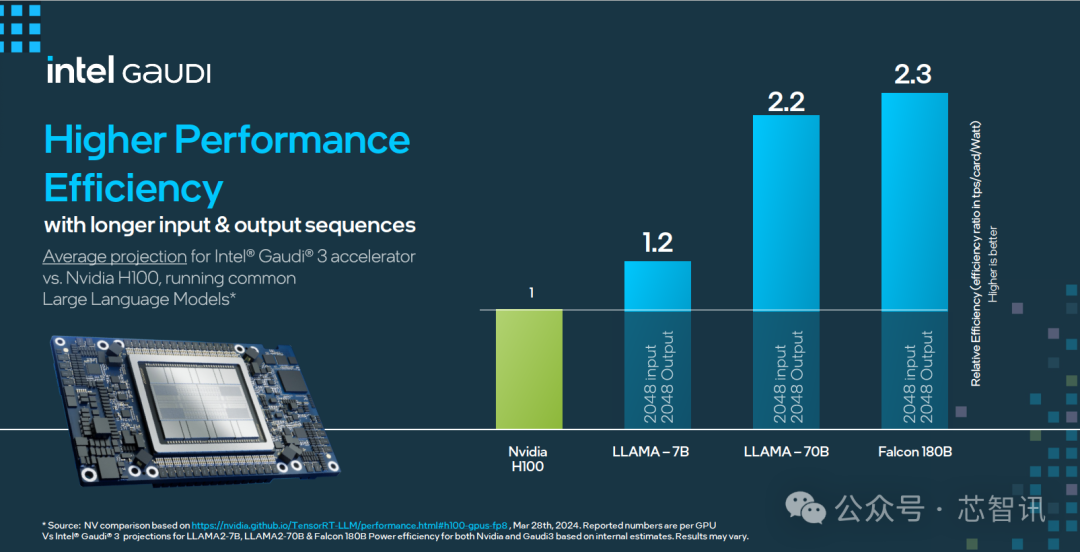
Intel表示,Gaudi 3预计可大幅缩短70亿和130亿参数Llama2模型,以及1750亿参数GPT-3模型的训练时间。此外,在Llama 7B、70B和Falcon 180B大型语言模型(LLM)的推理吞吐量和能效方面也展现了出色性能。
尽管Gaudi 3 与英伟达的Blackwell GPU有着很多相似之处,但Intel旗下Habana首席运营官Eitan Medina强调,这不是GPU。
“GPU传统上是被设计为进行图形渲染,是关于渲染像素的,所以自然而然地,选择实现许多小的执行单元,因为像素就是像素”,他解释道。“图形渲染不需要巨大的矩阵乘法。而Gaudi3 是使用数量较少的非常大的矩阵数学引擎构建的,这些引擎能够更有效地处理 AI 工作负载。”
虽然Gaudi 3是Intel最新一代的AI加速芯片,相比上一代的Gaudi 2带来了很大的提升,但是其仍然难以与英伟达最新的B200或者AMD最新的MI300X系列竞争。
显然,IntelGaudi 3 的主要对标的也是英伟达H100/H200。
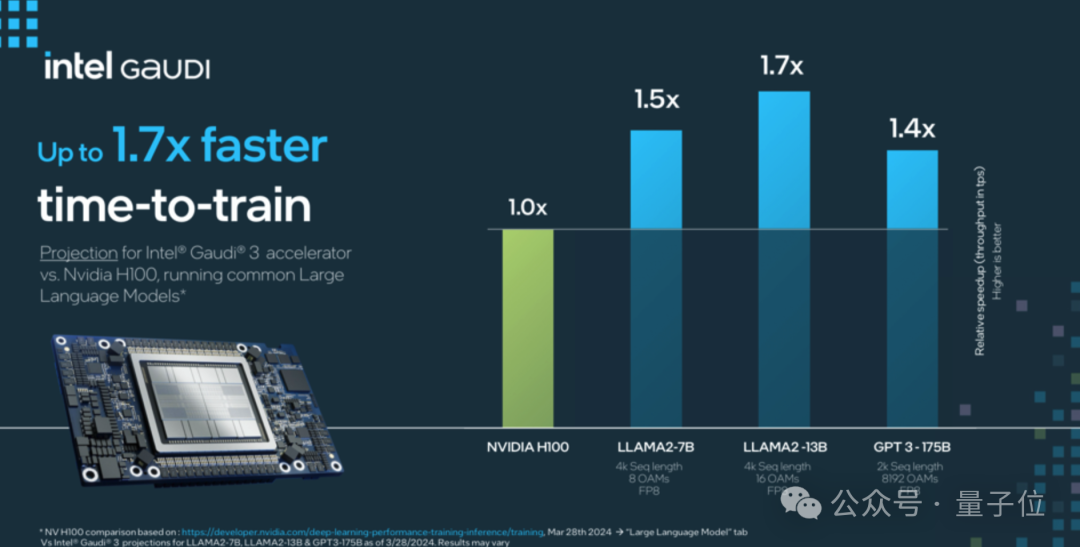
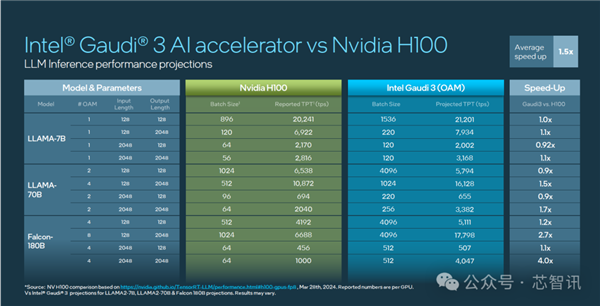
训练性能比英伟达H100快了40%,推理快了50%
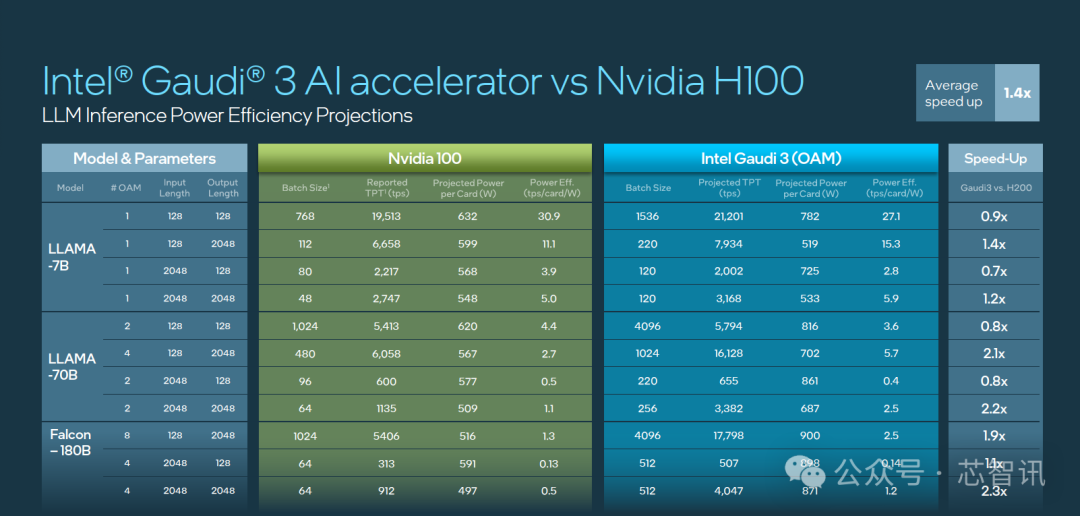
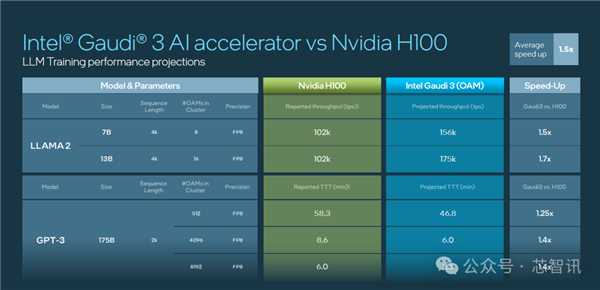
根据Intel官方公布的数据显示,Gaudi 3 在流行的大语言模型(LLM)训练速度方面,比英伟达H100平均快了40%;在流行大模型的推理能效表现上,比如英伟达H100领先50%。

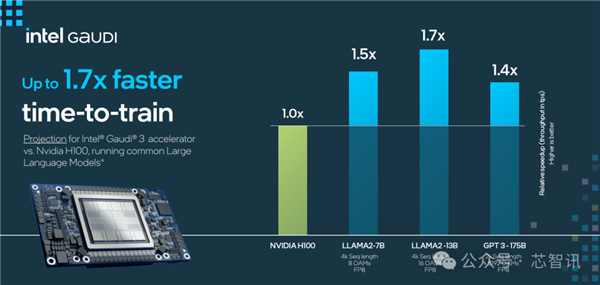
具体来看,Intel Gaudi 3 与英伟达 H100 在相同节点数量下,相关大模型训练时间对比上最高快了1.7倍。
其中,LLAMA2 70 亿参数对比有 1.5 倍于 H100 的优势,LLAMA2 130 亿参数最高有 1.7 倍的优势,GPT 3 1750 亿参数有 1.4 倍优势。
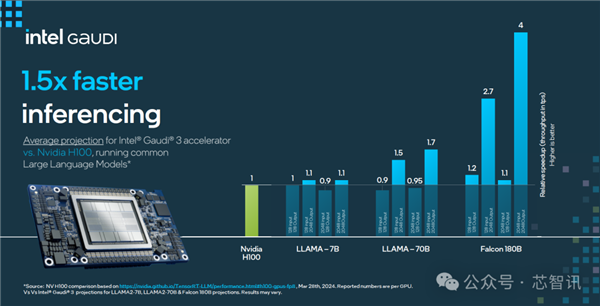
在大模型推理速度表现上,Gaudi 3 相比 H100 平均快了1.5倍,最高快了4倍。
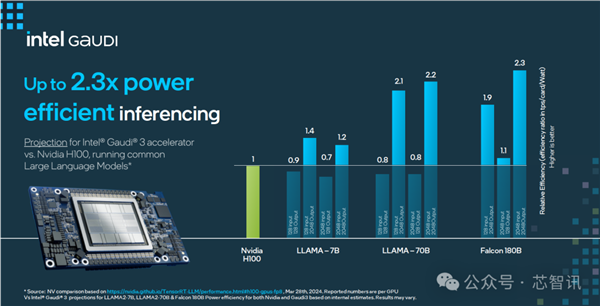
在大模型推理能效表现上,Gaudi 3 相比 H100 最高提升2.3倍。
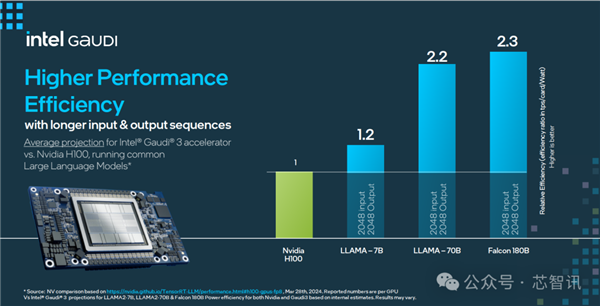
在更高性能的能效表现上,Gaudi 3 相比 H100 最高也提升了2.3倍。
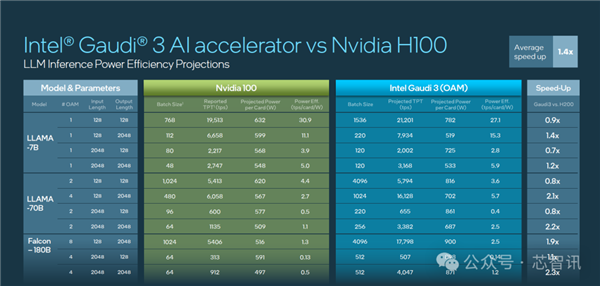
从具体的芯片性能方面来看,Theregister的报道显示,Gaudi 3 的密集的浮点性能为1,835 teraFLOPS ,而英伟达则依靠稀疏性来实现其公布的4 petaFLOPS性能。
考虑到这一点,Gaudi3 仅比 H100 慢了约 144 teraFLOPS,同时提供了更多的HBM内存容量。

在半精度(FP16/BF16)下,Gaudi 3 可以实现相同的1,835 teraFLOPS性能,使其比英伟达H100领先了1.85 倍,比AMD MI300X 领先了 1.4 倍。但是,Gaudi 3不支持稀疏性。
“稀疏性是经过大量研究的东西,但我们并不依赖它。”Medina补充说,Intel“没有立即计划”在 Gaudi 3 上启用稀疏性以进行训练或推理。
由于浮点性能只是 AI 性能对标的一个指标,HBM内存带宽在决定AI性能方面也起着巨大的作用,尤其是对于较大模型来说。
目前英伟达B200和AMD MI300X都配备了192GB HBM3e/HBM3,英伟达上代的H200也配备了141GB HBM3。
显然,Gaudi 3在这方面是相对落后不少的,仅比H100多一些,但还是较旧的HBM2e,这也使得其在HBM内存带宽上仅有3.7 TBps,远低于英伟达H200的4.8 GBps 和 AMD MI300X的 5.3 TBps。

对此,Medina解释称,继续使用HBM2e的决定,是因为风险管理。
“我们的只使用在流片之前已经在芯片中得到验证的IP。在我们流片Gaudi 3 时,还没有经过验证符合我们标准的可用物理层。”
大规模互联
无论是 FP8 还是 FP16/BF16,一个大语言模型在多个AI加速器上运行并不罕见。例如,要在 FP16 上推理一个 1750 亿参数的大模型,至少需要五个 80GB HBM内存的 H100 才能将模型放入其中。
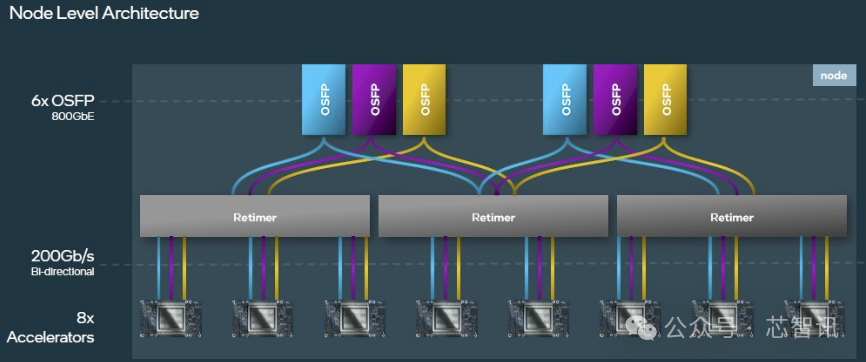
为此,英伟达 和 AMD 分别使用称为 NVLink 和 Infinity Fabric 的专用互连器,它们提供大约 900 GBps 的带宽,将八个或更多AI加速器拼接在一起。相比之下,IntelGaudi3 使用的是常规的旧RDMA融合以太网(ROCe)。

但是,Gaudi 3具有 24 个 200GbE 接口,总带宽为 1.2 TBps。24 条链路中有 3 条专用于节点外通信,剩余 1 TBps 用于服务器内的芯片到芯片通信。
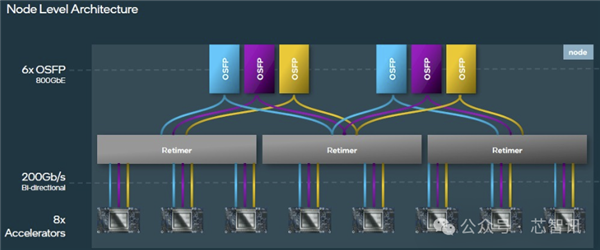
这样做有几个好处。
首先,从理论上讲,Gaudi 3系统应该简单得多,因为它们需要更少的组件。在典型的 英伟达 或 AMD 系统中,每个 GPU 至少有一个用于计算网络的 NIC。
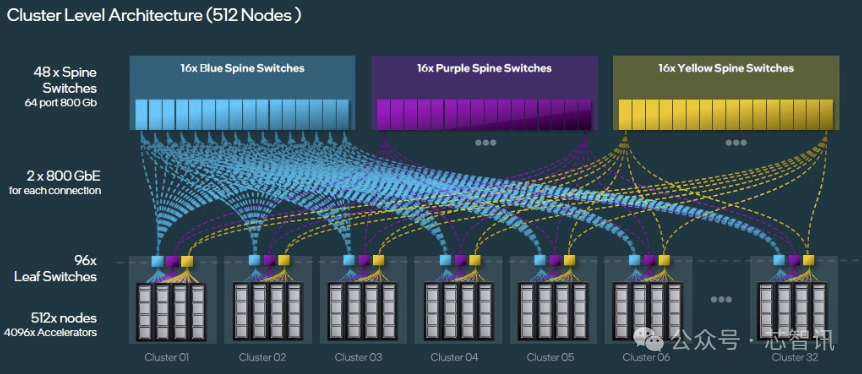
Intel认为,通过将以太网网卡集成到其Gaudi 3 加速器中,使用传统的骨干叶架构扩展以支持 512 甚至 1,024 个节点集群也更容易。
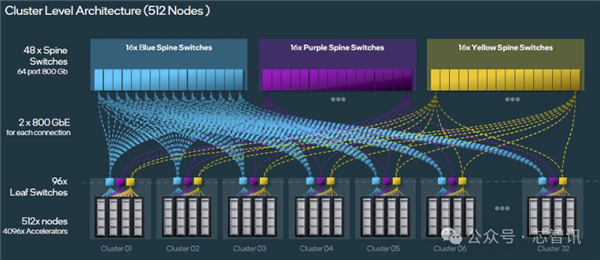
△要获得 512 个服务器节点上的 4,096 个 Gaudi 3 加速器,需要构建 32 个子集群,并将 96 个叶交换机与三组 16 个主干交换机交叉链接,这将为您提供三种不同的路径,通过两层网络将任何 Gaudi 3 链接到任何其他 Gaudi 3。
软件生态
软件生态方面,Intel Gaudi 3 针对生成式 AI 提供端到端全栈 AI 软件解决方案,包括嵌入式软件、软件套件、AI 软件、AI 应用。

Gaudi 3 可以支持基于还支持多模态、大语言模型、增强检索生成核心能力的 3D 生成、文本生成、视频图片生成、内容总结、翻译、问答、分级等常见 AI 功能。
依靠丰富的 AI 软件生态,Gaudi 3 也支持常见的 AI 框架库、使用场景和工具,并对有代表性的模型进行支持。Intel还提供 Gaudi 软件套件,提供对底层硬件的支持。
Gaudi 3提供开放的、基于社区的软件,以及行业标准以太网网络,可以灵活地从单个节点扩展到拥有数千个节点的集群、超级集群和超大集群,支持大规模的推理、微调和训练。
三种形态产品
对于Gaudi 3 硬件,Intel提供了OAM兼容夹层卡(Mezzanine Card)、通用基板(Universal Baseboard)、PCle加速卡三种形态产品。


Gaudi 3 Universal Baseboard有些类似英伟达DGX H100,集成了八个Gaudi 3芯片。



三季度交付
Intel在 Vision 2024 上也公布了 Gaudi 3 生产节点,2024 年一季度将率先推出风冷版样品,二季度推出液冷版样品,并在今年第三、第四季度分别批量交付风冷版和液冷版。
在此基础上,Intel也宣布 Gaudi 3 今年下半年可在Intel Developer Cloud 获得。除了Intel Gaudi 3 加速器之外,Intel还提供了关于其在企业 AI 各个领域的下一代产品和服务的更新。
OEM供应商及行业客户
Gaudi 3 硬件将由戴尔、惠与、联想和超微四家 OEM 厂商提供。

目前,IntelGaudi加速器的行业客户及合作伙伴有NAVER、博世(Bosch)、IBM、Ola/Krutrim、NielsenIQ、Seekr、IFF、CtrlS Group、Bharti Airtel、Landing AI、Roboflow、Infosys,等等。
第六代至强可扩展处理器“Xeon 6”
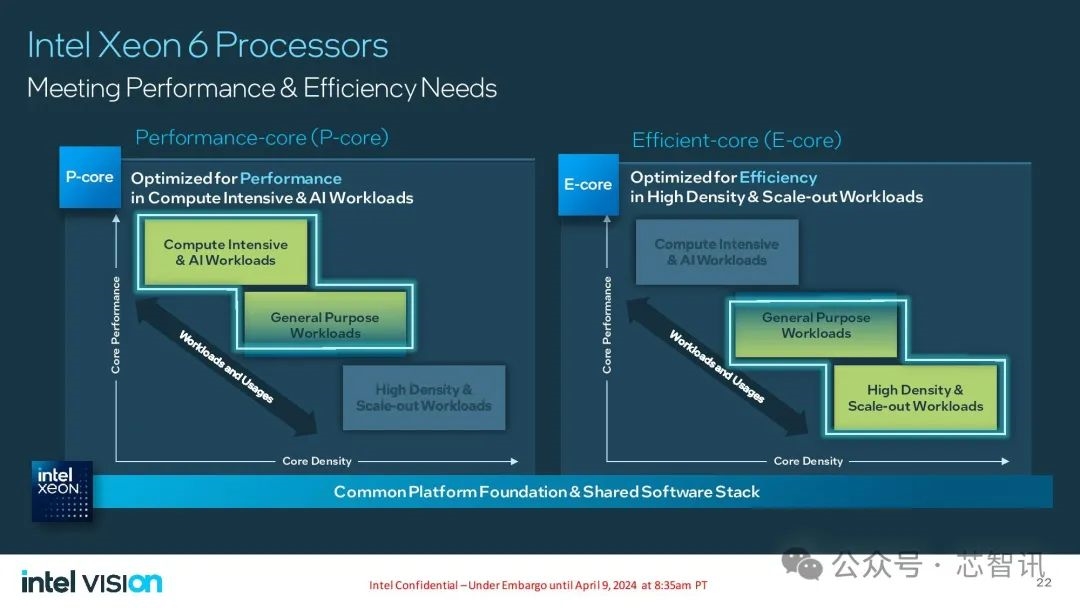
继去年12月Intel正式推出了集成NPU内核的代号为“Emerald Rapids”的第五代至强(Xeon)可扩展处理器之后,Intel此次正式公布了第六代Xeon处理器,Intel将其重新命名为了“Intel Xeon 6”系列。

和之前曝光的信息一样,Intel Xeon 6系列拥有基于性能核(P-core)的 Xeon 6(此前代号为Granite Rapids)和基于能效核(E-core)的 Xeon 6(此前代号为Sierra Forest)两个系列。
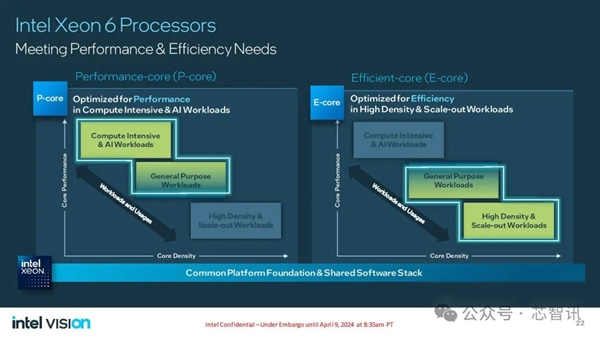
其中,配备能效核的Intel至强6处理器具有144 核和 288 核的两种配置,相比第二代Intel Xeon 处理器,每瓦性能提高了 2.4 倍,并且机架密度提高了 2.7 倍。


对于Intel的客户而言,可以以接近 3 比 1 的比例替换老旧系统,大幅降低能耗,推动实现可持续发展目标。
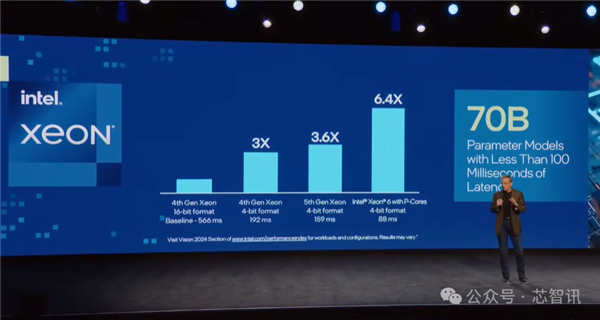
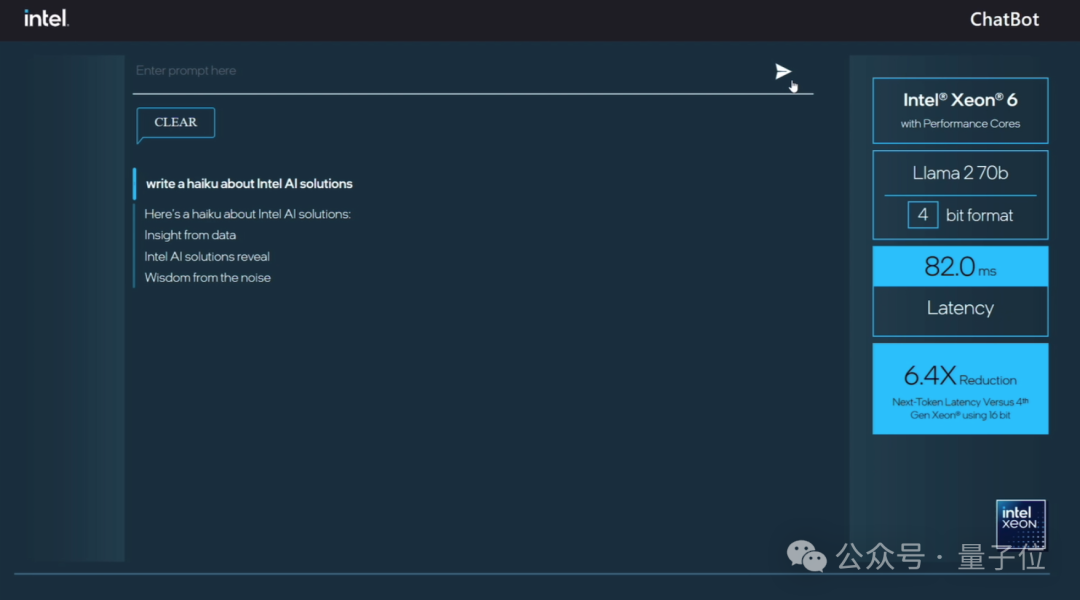
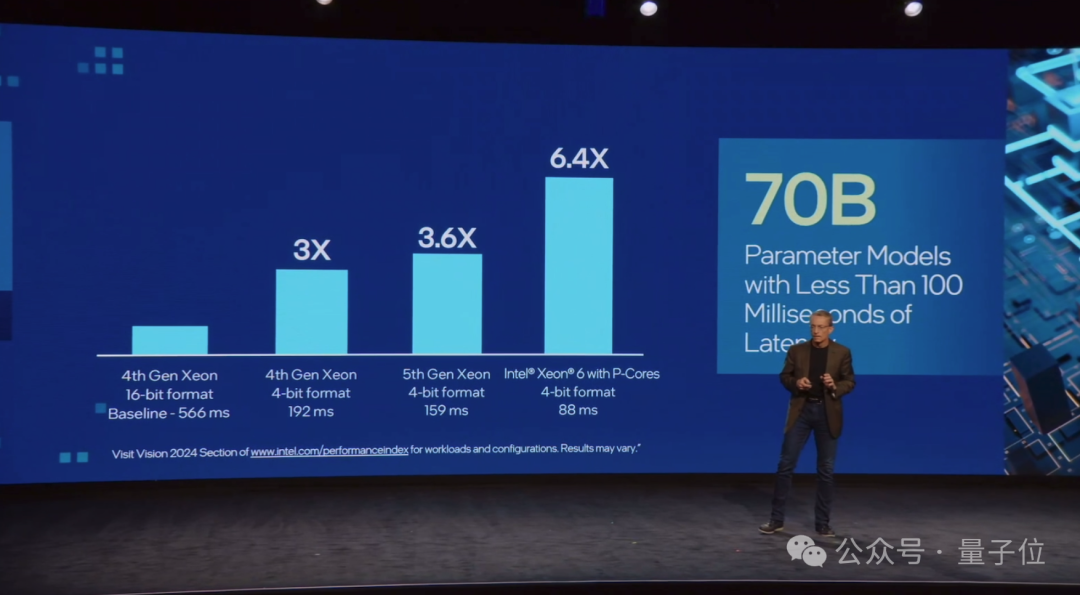
配备性能核的Intel至强6处理器则包含了对MXFP4数据格式的软件支持,与使用FP16的第四代至强处理器相比,可将下一个令牌(token)的延迟时间最多缩短6.5倍,能够运行700亿参数的Llama-2模型。


△IntelCEO基辛格展示Sierra Forest与Granite Rapids晶圆
Intel表示,配备能效核的Intel至强6处理器将于2024年第二季度推出,提供卓越的效率,配备性能核的Intel至强6处理器将紧随其后推出,带来更高的AI性能。
生态系统联合共建开放平台
此外,Intel还宣布联合Anyscale、DataStax、Domino、Hugging Face、KX Systems、MariaDB、MinIO、Qdrant、RedHat、Redis、SAP、SAS、VMware、Yellowbrick、Zilliz等伙伴,共同创建一个开放平台,助力企业推动AI创新。
该计划旨在开发开放的、多供应商的AIGC系统,通过RAG(检索增强生成)技术,提供一流的部署便利性、性能和价值。RAG可使企业在标准云基础设施上运行的大量现存专有数据源得到开放大语言模型(LLM)功能的增强。

初始阶段,Intel将利用至强处理器、Gaudi加速器,推出AIGC流水线的参考实现,发布技术概念框架,并继续加强Intel Tiber开发者云平台基础设施的功能。

另外值得一提的是,通过超以太网联盟(UEC),Intel正在驱动面向AI高速互联技术(AI Fabrics)的开放式以太网网络创新,并推出一系列针对AI优化的以太网解决方案。这些创新旨在革新可大规模纵向(scale-up)和横向(scale-out)扩展的AI高速互联技术,以支持AI模型的训练和推理,这些模型的规模日益庞大,每一代都会增长一个数量级。
Intel的产品组合包括IntelAI网络连接卡(AI NIC)、集成到XPU的AI连接芯粒、基于Gaudi加速器的系统,以及一系列面向Intel代工的AI互联软硬件参考设计。
|