对联传统源远流长,一幅写春联的需要极高的文学素养,不仅要求平仄齐整、意境对称,还要表达辟邪除灾、迎祥纳福的美好愿望。但是对于现代人来说,由于对传统文学的生疏和缺乏对对联的练习,对对联变得不容易了。
但是人工智能技术普及的今天,攻克对联难关早就有人来尝试进行了。其中最为著名,最富有文学气息的当属微软亚洲研究院的对联系统,其由微软亚洲研究院副院长周明负责开发,并能够利用本交互方式可以随意修改下联和横批。如下图所示,就“千江有水千江月”一对就可对出“万里无云万里天”。

地址:http://duilian.msra.cn/default.htm
不过,在新奇以及个性化方面不如最近新崛起的百度春联系统,百度开发的对联系统有刷脸出对联以及藏头对联等系统。如下图所示,以人工智能为题眼,AI给出的一幅对联。

手机打开哟:https://aichunlian.cctv.com/?from=singlemessage&isappinstalled=0
不仅能刷脸生成对联,还可以预测合成你20岁年纪模样。雷锋网用李飞飞博士的一张照片试了一下,可以在下方滚动区域清晰的看到每一步的文字。结果显示预测年龄为32岁,AI给颜值打80分。另外,生成的李博士20岁的照片颇为青春(* ̄︶ ̄)。
当然,还有去年非常火的个人版AI对联,设计者是本科毕业于黑龙江大学计算机专业,硕士毕业于英国莱斯特大学读计算机硕士的王斌。从测试结果(如下图)来看,对于一般的对联效果也是杠杠滴~
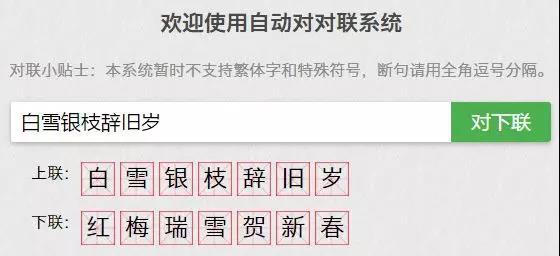
对联地址:https://ai.binwang.me/couplet/
雷锋网介绍,这个AI的训练,是基于深度学习seq2seq模型,用到了TensorFlow和Python 3.6,代码已经开源,你可以自行打开下面的GitHub地址下载开源代码尝试训练。另外,训练它所用的数据集来自一位名为冯重朴_梨味斋散叶的博主的新浪博客,总共包含超过70万副对联。
开源代码:
https://github.com/wb14123/seq2seq-couplet
训练数据集:https://github.com/wb14123/couplet-dataset
所以想自己写春联的,但又憋不出大招的小伙伴,可以使用上述任一AI系统打造出属于你自己的对联。
AI对联背后的技术
关于AI对联所采用的技术,微软周明在博客中曾经写过这样一段话:“我设计了一个简单的模型,把对联的生成过程看作是一个翻译的过程。给定一个上联,根据字的对应和词的对应,生成很多选字和候选词,得到一个从左到右相互关联的词图,然后根据一个动态规划算法,求一个最好的下联出来。
从上述文字我们可以知道,AI对联采用的是一系列机器翻译算法。和不同语言之间的翻译不同的是,给出上联,AI对出下联是同种语言之间的翻译。
这也就是说对联系统的水平直接依赖于机器翻译系统的发展历程。
机器翻译的最初的源头可以追溯到1949年,那时的技术主流都是基于规则的机器翻译, 最常见的做法就是直接根据词典逐字翻译,但是这种翻译方法效果确实不太好。“规则派”败北之后,日本京都大学的长尾真教授提出了基于实例的机器翻译,即只要存上足够多的例句,即使遇到不完全匹配的句子,也可以比对例句,只要替换不一样的词的翻译就可以。但这种方式并没有掀起多大的风浪。
1993年发布的《机器翻译的数学理论》论文中提出了由五种以词为单位的统计模型,其思路主要是把翻译当成机率问题,这种翻译方式虽然在当时风靡一时,但真正掀起革命的还是2014年深度学习的兴起。
2016年谷歌正式宣布将所有统计机器翻译下架,神经网络机器翻译上位,成为现代机器翻译的绝对主流。具体来说,目前市面上的AI对联基本上都是基于attention机制的seq2seq模型的序列生成任务训练而成。seq2seq模型又叫Encoder-Decoder。
关于此模型AI科技评论之前曾经写过一篇文章详细介绍,尚未理解的读者请戳此《完全图解RNN、RNN变体、Seq2Seq、Attention机制》阅读。
现在我们也把关键部分摘要如下:Encoder-Decoder结构先将输入数据编码成一个上下文向量c:
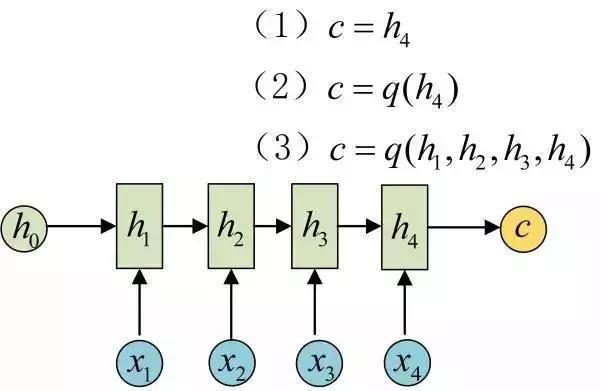
得到c有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。
拿到c之后,就用另一个网络对其进行解码,这部分网络结构被称为Decoder。具体做法就是将c当做之前的初始状态h0输入到Decoder中:
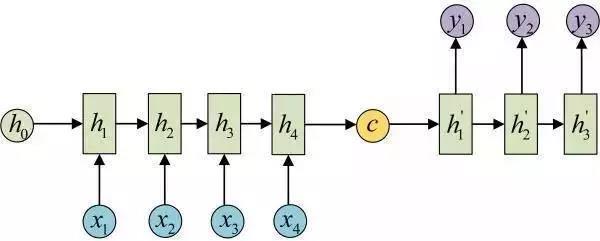
还有一种做法是将c当做每一步的输入:
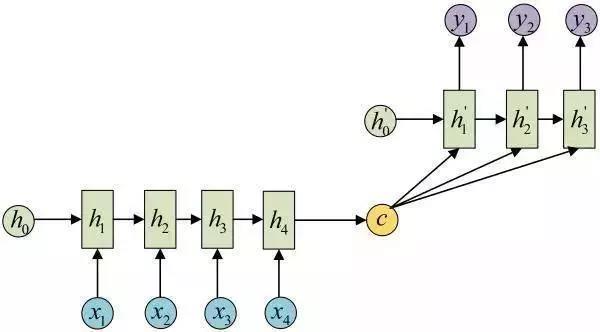
由于这种Encoder-Decoder结构不限制输入和输出的序列长度,因此应用的范围非常广泛。
Attention机制
在Encoder-Decoder结构中,Encoder把所有的输入序列都编码成一个统一的语义特征c再解码,因此,c中必须包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。如机器翻译问题,当要翻译的句子较长时,一个c可能存不下那么多信息,就会造成翻译精度的下降。
Attention机制通过在每个时间输入不同的c来解决这个问题,下图是带有Attention机制的Decoder:
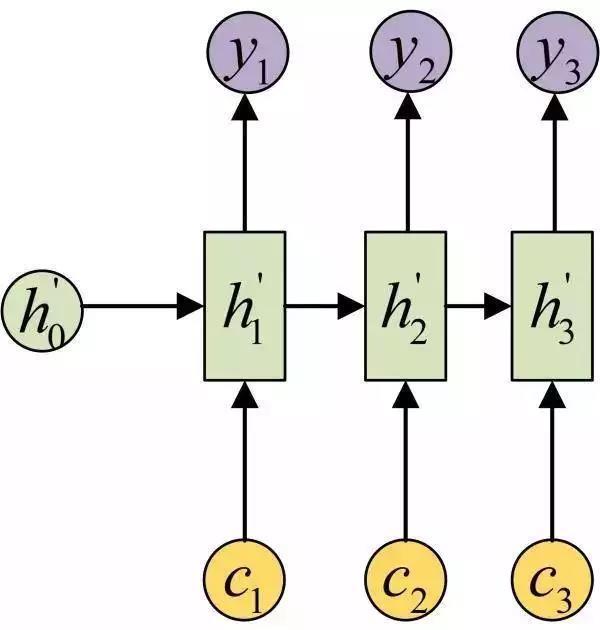
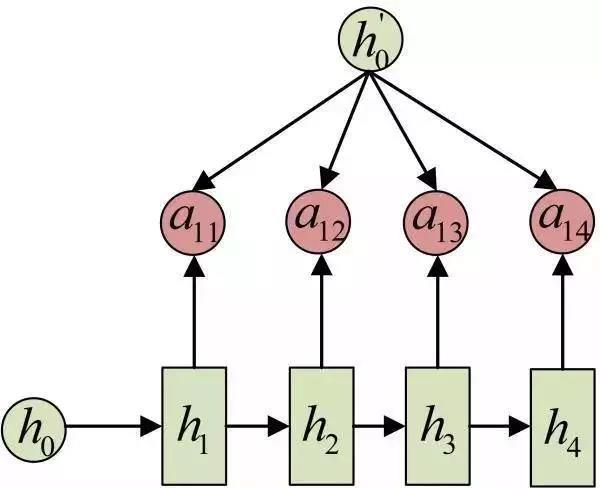
每一个c会自动去选取与当前所要输出的y最合适的上下文信息。具体来说,我们用aij衡量Encoder中第j阶段的hj和解码时第i阶段的相关性,最终Decoder中第i阶段的输入的上下文信息 ci就来自于所有 hj 对 aij 的加权和。以机器翻译为例(将中文翻译成英文):
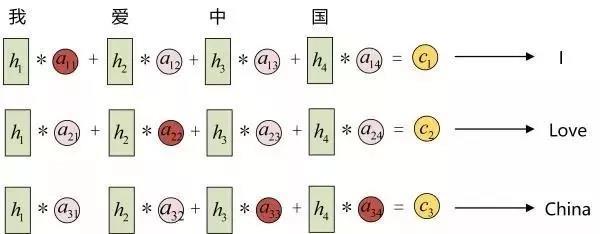
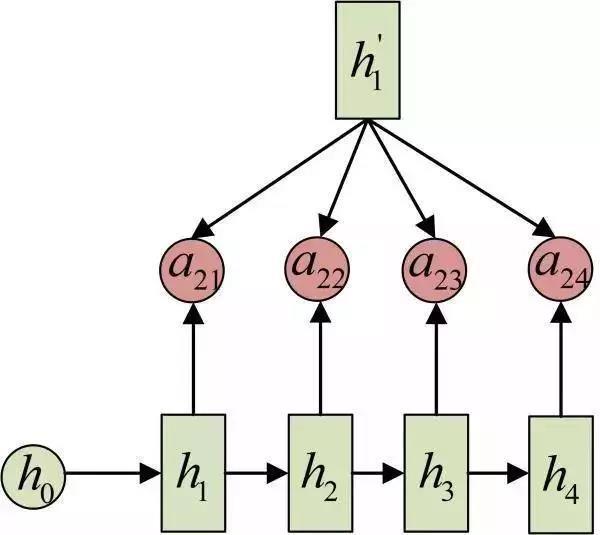
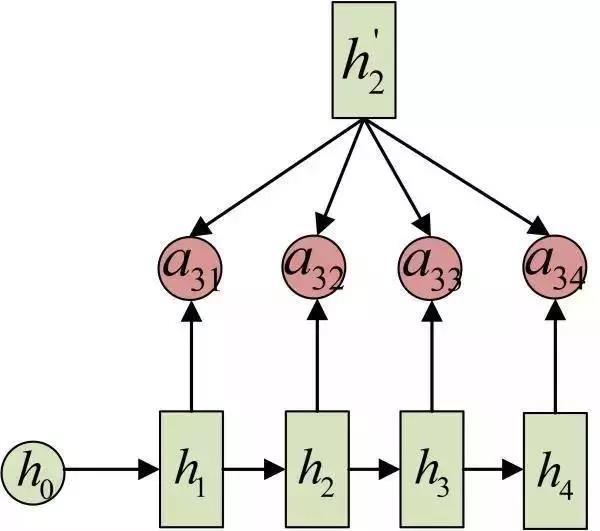
输入的序列是“我爱中国”,因此,Encoder中的h1、h2、h3、h4就可以分别看做是“我”、“爱”、“中”、“国”所代表的信息。在翻译成英语时,第一个上下文c1应该和“我”这个字最相关,因此对应的a11就比较大,而相应的 a12、a13、a14就比较小。c2应该和“爱”最相关,因此对应的a22就比较大。最后的c3和h3、h4最相关,因此a33、a34的值就比较大。
至此,关于Attention模型,我们就只剩最后一个问题了,那就是:这些权重aij是怎么来的?
事实上,aij同样是从模型中学出的,它实际和Decoder的第i-1阶段的隐状态、Encoder第j个阶段的隐状态有关。
同样还是拿上面的机器翻译举例,a1j的计算(此时箭头就表示对h'和 hj 同时做变换):
a2j 的计算:
a3j的计算:
以上就是带有Attention的Encoder-Decoder模型计算的全过程。
关于解码器和编码器
解码器和编码器所用的网络结构,在深度学习时代大多使用卷积网络(CNN)和循环网络(RNN),然而Google 提出了一种新的架构 Transformer也可以作为解码器和编码器。
注:Transformer最初由论文《Attention is All You Need》提出,渐渐有取代RNN成为NLP中主流模型的趋势,现在更是谷歌云TPU推荐的参考模型,包括谷歌给自己TPU打广告的Bert就是Transformer模型。总的来说,在NLP任务上其性能比前两个神经网络的效果要好。
这彻底颠覆了过去的理念,没用到 CNN 和 RNN,用更少的计算资源,取得了比过去的结构更好的结果。
Transformer引入有以下几个特点:提出用注意力机制来直接学习源语言内部关系和目标语言内部关系,1.抛弃之前用 RNN 来学习;2.对存在多种不同关系的假设,而提出多头 (Multi-head) 注意力机制,有点类似于 CNN 中多通道的概念;3..对词语的位置,用了不同频率的 sin 和 cos 函数进行编码。
机器翻译任重而道远
从对联的角度来看,当前的机器翻译还有很大的改进方向,例如前段时间有句很火的上联“莫言路遥余秋雨”,我们用微软对联系统输入之后,就没有答案。出现这种问题的原因在于算法和数据集。

然而我们把这个上联输入王斌版的对联系统,就会得到“看云山远处春风”的下联。虽说给出了下联,但是意境和上联相比却相差甚远:“莫言路遥余秋雨”的字面意思是近现代三位文人,意境是“不必言道路漫长空余寂寥秋雨”,AI给出的下联不仅在意境上无法呼应,字面意思也对应不上。
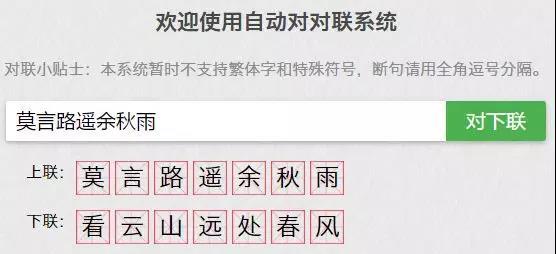
管中窥豹,仅此一例便能看出当前的机器翻译存在一些问题,正如AI科技评论从百度处获悉:“当前主要都是采用端到端序列生成的模型来自动写对联和写诗,对于一般用户来说生成的春联或者诗歌读起来也能朗朗上口,感觉也不错。
从专业角度来说其实还有很大的改进空间,例如现有的模型都是基于语料学习生成的,而采集的春联库通常包含的词汇是有限的,生成的春联有一定的同质性,内容新意上有待继续提升。其次是机器有时候会生成一些不符合常理的内容,对生成内容的理解也值得继续深挖。”
宏观到整个机器翻译层面,不同语言之间的机器翻译还存有很多技术难点亟待攻克,比如语序混乱、词义不准确等。
当前的算法和算力的发展确实能够解决一些特定的困难,但是机器翻译的研究应在以下三个方面有所突破:大语境,而不再是孤立句子地处理;基于理解而不再是停留在句法分析的层面;高度专业化和专门化。
参考文献:
https://www.jianshu.com/p/7e66bec3123b
http://www.citnews.com.cn/e/wap/show.php?classid=9&id=101568

|