正文内容 评论(0)

了解完全新的SIMD和CU的概念,下面再来看看详细的总体架构组成。和传统的多流处理器单元组成SIMD阵列,多个SIMD阵列组成GPU的思路类似,新架构也是由包含数个计算单元的CU阵列搭建而来。虽然下面的讲解只是AMD从宏观高度的一个概览,具体细节单元不可能面面俱到,不过我们依然能从其中得知一二。
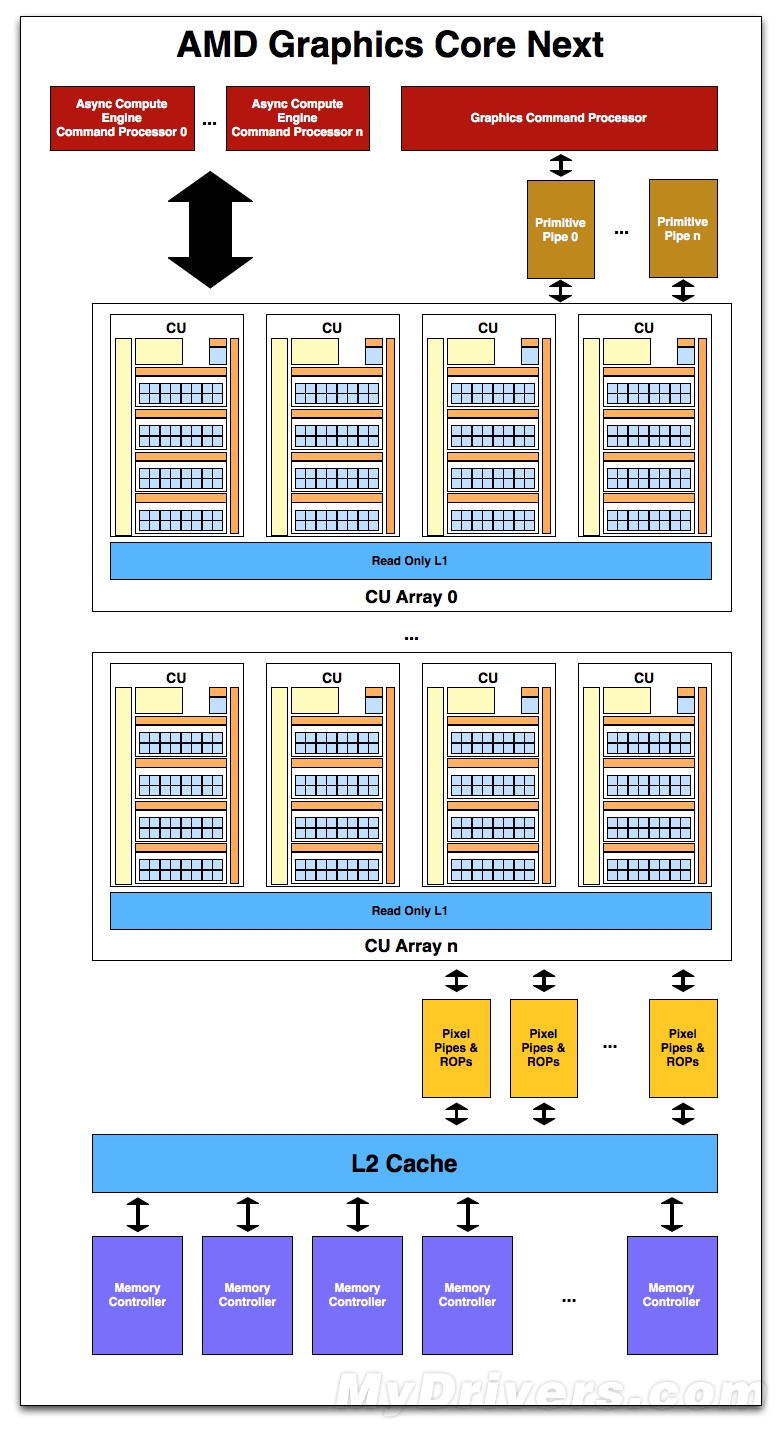
Graphics Core Next全新架构示意图
先从显存和缓存开始说起,我们知道从R600架构时代引入的GDS(Global Data Share)发展至今一直是GPU唯一的临时缓冲单元,虽然RV770加入了LDS(Local Data Share)对GDS进行补充,但是从计算角度来看依然作用不大。新架构改变最明显的一点就是会把L2缓存和显存控制器进行搭配,每个显存控制器可以共享64KB或者128KB的L2缓存(还不太确定),这样以来在并行访问显存的时候可以大大节约宝贵的带宽。
另外,GPU和CPU的同步也可依靠L2缓存提高效率。虽然这种缓存机制很像NVIDIA费米架构的缓存体系,但其中也存在很多差异。新架构的缓存并不与ALU直接连接,而且和GDS和LDS没有任何关系。另外,纹理单元可以直接访问L2缓存。这些与费米架构还是存在本质上的不同的。
与此同时,新架构的异步计算引擎(Asynchronous Compute Engines,ACE)将会充当command Processors的角色用于运算操作,而ACE的主要作用就是接受任务并将其下遣分配给CU处理(主要是分配的过程)。全新架构强化了多任务的并行处理设计,一个GPU中将会看到多个ACE用于多重并发操作,例如资源分配、上下文切换以及任务优先级决策等等。由于AMD目前尚未明确指出各个ACE之间的直接关系以及可以最多并行处理任务的数量,所以我们也不好做出猜测。
不过可以确定的是,有了ACE的直接作用就是新架构拥有了一定程度的乱序执行能力。就像上文我们提到过的一样,虽然严格意义上新架构依然是顺序执行架构,一个完整wavefront中的指令执行顺序不能被打乱,但是ACE可以做到对不同的任务进行优化和排序,划分任务执行的优先级别,进而优化资源。从本质上来说,这与很多CPU(比如Atom、ARM A8等等)处理多任务的方式并没有什么不同。
接着向下说,与目前的Cayman类似,Graphics Command Processor位于新架构的顶层,负责整个GPU组件单元执行任务的调遣(功能与传统架构中的GCP基本相同)。在此之下,Cayman架构的“双核心”将会被传统的“管线”(也就是CU阵列流水线)所代替,主要负责常见的几何和一些固定功能处理,比如曲面细分、几何转换以及纹理贴图等等。
相对于传统GPU的“既定架构”,新架构是完全可扩展的,几何处理能力将会大大增强。经过计算单元处理之后,就是像素管线和ROP单元了(同样可扩展),虽然AMD并未给出详细的设计方案,但我们猜测ROP/L2缓存/显存控制器三者之间会有紧密联系(比如数量关系等等)。此外,AMD还透露了一点新鲜的细节:部分驻存纹理(Partially Resident Textures,RPT)。按照AMD的说法,RPT允许纹理单元的一部分载入到显存之中,以免整个纹理单元都由显存处理造成不必要的性能损失(一部分可能无用)。
遗憾的是,普通用户最关心的附加功能信息到目前一概欠奉,情况很像最初费米架构初露苗头的时候。再加上AMD Fusion开发者峰会本身主要面对开发者,所以更多是展示计算方面的细节而非图形性能,也就不奢求更多了。
本文收录在
#快讯
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...