正文内容 评论(0)

Fusion开发者峰会和全新图形架构
6月15日,阳光明媚的华盛顿贝尔维尤迎来了AMD首次全球开发者大会:AMD Fusion开发者峰会(AMD Fusion Developer Summit,AFDS)。与之类似的技术会议还有NVIDIA的GPU技术峰会(GPU Technology Conference,GTC)以及Intel的信息技术峰会(Intel Developer Forum,IDF)。三天的会议共吸引了700多名来自全球科研机构和IT公司的开发者,显然这是AMD愿意看到的,因为这不仅是和众多开发者交流讨论的一个好机会,更重要的是AMD能从他们那里得到许多反馈和宝贵的建议,当然也就更加有利于日后做出更好的产品。

虽然会议涉及了许多方面,但最主要的还是关于Fusion APU的诸多细节,包括Fusion系统架构路线图,主流级A系列APU LIano的发布,以及下一代Trinity APU芯片笔记本的展示等等。作为会议主题,Fusion系统架构(FSA)勾画了AMD的设计理念:就是融合CPU和GPU处理器核心并将其作为统一的处理引擎,以带来超越此前任何架构的高性能和低功耗,而未来GPU的并行处理性能将被更加重复的利用,CPU和GPU将实现无缝协作运行。很显然,Fusion将成为AMD未来战略的主要目标,尽管它还算还刚刚起步。不过,这并不是本文要说的的重点。
会议中,AMD首席技术官兼图形业务执行副总裁Eric Demers 在一大堆关于APU的讲演之后,终于向大家透露了一些AMD下一代图形架构的细节。虽然产品路线图、发布规划、规格参数、功能特性等等一概欠奉,但是不要失望,关于GPU架构的一些重要信息还是公布了一些。根据AMD的说法,下一步的目标是发展“针对图形、计算双重优化的统一可扩展GPU”,“一套面向吞吐量的大规模多线程计算单元架构”,包括多任务多引擎架构、计算单元架构、多级读写缓存架构,同时具备可读写的一级/二级缓存、乱序资源分配、SRAM和全局内存ECC错误校验数据保护、并行原语设定等等。

由于缺乏开发代号,全新的图形架构目前被称作Graphics Core Next(GCN)。Graphics Core Next是AMD未来GPU架构的基础,包括所有桌面独立显卡以及APU融合的集成显卡。新架构将会以未来市场需求为导向,最大化的发挥GPU的功能,这也是自R600以来,AMD图形架构最大规模的一次变革。在新架构中,传统的图形性能表现和特性发展依然占据很重要的地位,不过GPU的计算能力将会得到前所未有的增强。从某种意义上来讲,后者一致是A卡的一个软肋,再加上近年来NVIDIA不断提倡GPU通用计算的理念,所以新架构的计算能力将成为改革的重点。
当然,AMD也强调了新架构会找到图形和计算性能之间的最佳平衡点,图形和计算架构并不是单独进化,而是隶属于更大的体系Fusion系统架构的一部分,也就意味着今后GPU、CPU会联系得越来越紧密,协同加速。事实上,经过多年的发展,尤其是统一渲染架构出现以后,GPU的用途不再仅仅是图形处理,并行计算能力被不断挖掘,在应付某些高负载并行处理任务的时候更像是一颗广义的CPU。所以以长远的目光来看看,新架构的改变也与AMD倡导的异构计算理念相符。
所以,在未来的发展道路上,AMD的着重点不再是CPU和GPU的单方面发展,而是它们融合之后的协同运作。就近阶段来看,Bulldozer推土机承载了未来的CPU部分,而GPU部分就是我们今天要说Graphics Core Next全新图形架构。不过,欲登高而穷目,勿筑台于浮沙。一切事物的发展都离不开根本,溯本归源,我们先从最基本的说起。
序幕曲:VLIW显卡架构的历史承接上文,在我们走进Graphics Core Next全新架构之前,先来简单回顾一下以往AMD显卡VILW架构的一些要点。
在过去的AMD的统一渲染架构中,基本的运算单元是流处理器单元(Streaming Processor,SPU)。我们知道,除了Cayman(调整为VILW4)核心以外,AMD从R600开始所有的GPU都采用了VLIW5架构(VLIW,超长指令流)。顾名思义,每一个流处理器单元有5个或者4个更基础的数学运算单元(算术逻辑运算器ALU和特殊函数运算器SFU,现在AMD统一称之为Radeon Cores),每一个数学运算单元都能在一个周期并行独立地执行相关指令。数学运算单元与寄存器(Registers)相连,后者主要负责存储输入数据、临时数值和输出数据,并不存放具体的指令,另外还有分支单元(Branch Units)负责指令流的重组和打包,这样就构成了一个完成了流处理器单元。

从设计方面来讲,VILW架构更擅长于并行执行相同的指令,这些相同的指令(线程)往往是被打散之后重新分组的wavefront(类似于NVIDIA的warp)。在AMD以往的实例里,wavefront是64个线程为一组,而指令流就是以wavefront来执行。理想的情况下,在一个wavefront中一组4或5个指令(类似于下图的蓝色指令)在流处理单元中并行完成,这样的执行效率最高达到100%,5个算数单元可以全部负载。但当较少的指令(比如1或2个,类似于下图的其它颜色指令),就会大大影响执行效率,因为此时只有1到2个运算单元负载。就这一点而言,VLIW架构始终难以在执行效率上达到完美,毕竟现实程序中的理想情况并没有那么多。

流处理执行指令情况
在3D图形进行渲染的过程中,VS和PS的主要工作就是进行X、Y、Z、W四个坐标运算和计算除R、G、B、A得出像素颜色。为了一次性处理1个完整的几何转换或像素渲染,GPU的VS和PS从最初就被设计成为同时具备4次运算能力的算数逻辑运算器(ALU)。 而数据的基本单元是Scalar(标量),就是指一个单独的变量,所以GPU的ALU进行一次这种变量操作,被称做1D标量。
与标量对应的是Vector(矢量),一个矢量由N个标量标量组成。所以传统GPU的ALU在一个时钟周期可以同时执行4次标量的并行运算被称做4D Vector(矢量)操作。虽然GPU的ALU指令发射端只有一个,但却可以同时运算4个通道的数据,这就是单指令多数据流(Single Instruction Multiple Data,SIMD)架构。
这种类似的SIMD架构可以追溯到R300(Radeon 9700)时代,而到了DX10统一渲染架构出现的R600(Radeon HD 2900),AMD采用VLIW5架构设计也是在此基础上进行的扩展和革新,因为当时的主要游戏市场依然被DX9占据,而游戏中采用的3D渲染程序也大都利于这种架构执行。但是随着时间的推移,新一代3D游戏和GPGPU(通用计算图形处理器)程序的出现,VILW架构的执行效率就开始出现问题了。
最后,值得一提的是调度问题。在CPU世界中,我们把指令丢给CPU并且安排它在必要的时候进行线程调度操作。但在VLIW的GPU架构里,线程调度是编译器的事儿。编译器对于已知程序的调度做地相当完美,但是对于未知程序的安排就不是很给力了。因为这种调度是静态的,并不能实时改变。再加上VILW架构对编译器的依赖相当之大,如此以来就更加雪上加霜。
那为什么讲AMD全新架构之前要说这些废话?很简单,没有这些我们不可能了解AMD新架构中做了什么,或者说为什么这么做。
新架构:舍弃VILW回归non-VLIW SIMDAMD全新图形架构的革新之路最根本的问题是,以往的VILW对于图形来说非常合适,但是对于计算就略显弱势了。不过从种种迹象来看,GPU的通用计算是AMD未来的一个很重要的发展分支方向,Fusion融合从某一方面来讲并不仅仅是简单地在CPU die里面放置一个不错的GPU,而是充分发挥和利用GPU架构优势完成CPU所不擅长的并行计算任务,GPU的并行处理性能将被更加重复的利用,CPU和GPU将实现无缝协作运行。所以AMD传统GPU的“重图形轻计算”显然不能适合AMD未来的发展方向。
在AMD的全新图形架构里,VILW将会彻底被摒弃,取而代之的是non-VLIW SIMD。从根本上来讲,二者很是相似——都可以并行的处理大量指令,但是执行效率却有天壤之别——VLIW是指令集并行(instruction level parallelism),而non-VLIW SIMD是线程级并行(thread level parallelism)。抛开其它过多不必要的深入研究(限于篇幅以后换个时间再谈),二者架构最大的不同就是关于VILW在通用计算表现不济,而为什么non-VLIW SIMD要加强这方面的讨论。
说到底就是VILW的编译器没有预调度处理机制,在执行过程中不能动态调度,其最大弱点也就在于此。虽然VILW5在图形方面的表现已经相当出色,但计算方面依然不能尽如人意。成也编译器,败也编译器,用这句话来形容VILW最恰当不过。对编译器的过分依赖,也导致了对编译器过高的要求,除了调度问题还包括扩充对编译语言支持之后,即便是通过中间代码进行抽象,编译器也未必能很好的处理和执行。
另外,VLIW的复杂性在某些时候(比如需要对一段程序优化和手动调试的时候)尽显无疑,虽然通常情况下这对图形渲染并不构成问题,但通用计算就不一样了。VILW复杂的天性使得调试和反汇编的每一步都困难重重,而且很难预计性能表现,至于找出和优化相关重要部分的代码就更不用说了。
在讲演中,AMD提供了一段示例代码,展示了VILW和non-VLIW SIMD编译器之间的不同,虽然主要针对开发人员,但是从中不难看出后者的改进之处。

VILW:图形渲染没问题,计算方面就……
去掉VILW之后,AMD又回归了传统的矢量SIMD,但也并非如此简单。以往GPU架构的元素并不会直接原封不动地放到新架构里,既然上文我们已经说过了流处理器单元,下面再来说说它最亲密的代替者SIMD,不过此时的SIMD已经不是彼时的SIMD了。
需要注意的一点就是不要和以往GPU架构中的SIMD混淆(包含大量处理器的阵列),新架构中的SIMD是一个真正的16D 矢量单元(包含16个标量ALU),根据我们之前介绍的概念,全新的SIMD可以在在一个时钟周期可以同时执行16次标量运算。和目前的Cayman一样,AMD的wavefront依然包含64个线程,也就是说一个SIMD需要4个周期循环才能完成一个wavefront。当然,每个SIMD中还会包含一个64KB的寄存器。

另外,类似于以往的流处理器单元,SIMD同样可以进行不同的整数和浮点运算。不过遗憾的是AMD并没有其中的细节方面做任何透露,不过我们还是希望AMD在可能的条件下带来不一样的出色改变。不过有一样能够确认的是64位浮点预算性能大幅提提高,基本上能够达到32位浮点运算的1/2 。虽然这对桌面用户来说并不能造成什么深刻的影响,但是对AMD进入高精度计算是市场是大有裨益的。
SIMD构建的计算单元正如传统的SIMD之于出流处理器单元之上,全新的SIMD之上就是新架构中所谓的计算单元了(Compute Unit,CU)。虽然从某种意义上来讲,计算单元和传统的SIMD相差不多,但前者带来的该改变可谓脱胎换骨,甚至颠覆了AMD以往所有的架构设计。
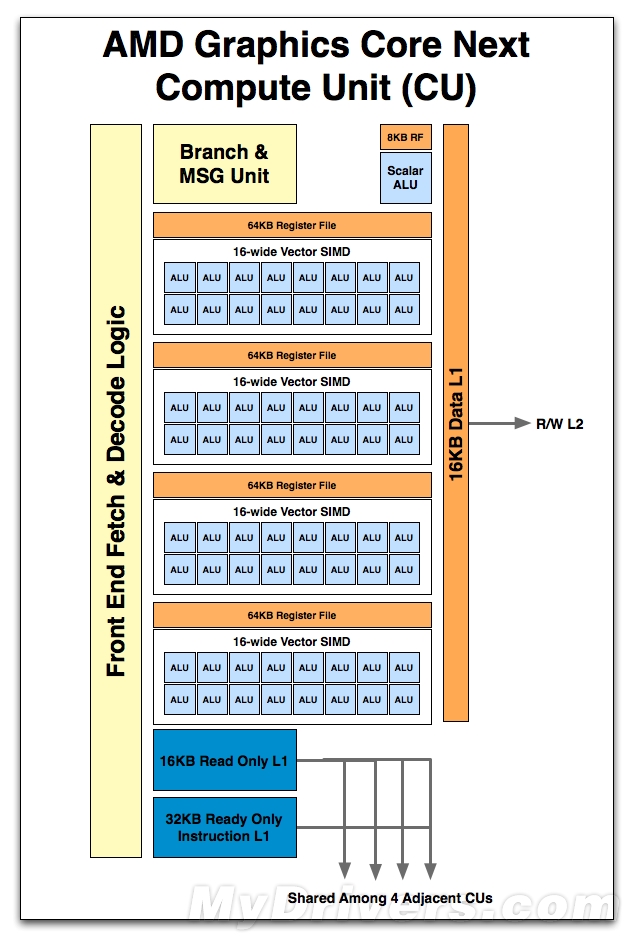
那么计算单元(CU)中都由那些单位构成呢?根据AMD的说法,一个CU中有4个SIMD单元,每个SIMD单元由16个全功能的标量ALU构成。每个CU配备一个硬件分支单元(Branch&MSG Unit),主要负责抽取、编码以及调度wavefront和指令。此外,还有扩充的64KB LDS(Local Data Store)以及16KB数据和纹理L1缓存。也就说新架构中数据和纹理L1缓存进行了合并,因为L1缓存中的纹理单元都是经过压缩过的,纹理L1缓存的压力相比以往减小了。而环绕在显存控制器之外的是可读写的L2缓存,还有可供4个CU共享的16KB只读L1缓存和32KB只读指令L1缓存。
在继续下一步介绍之前,先来看一个问题。我们已经知道了新架构中计算单元的构成以及传统VLIW架构的弱点,现在终于可以解答问什么AMD要放弃VLIW转而采用non-VLIW SIMD了。正如我们开始提到的,VLIW最大的弱点是编译器的静态调度。结果就是代码执行过程中任何相关(至于如何理解可以参看下面的图)性指令的突然出现,调度依然会按事先设定好的路数进行,而VLIW中大部分运算单元就被浪费掉。所以从VLIW到non-VLIW SIMD的第一个改变就很直接,后者的调度工作从编译器完全转移到了硬件——由计算单元来完成。当然,一切的目的就是为了获得更好的执行效率,更好的计算性能。
当然,鱼和熊掌什么时候都不可兼得。这里就有一个明显的折中,硬件动态调度固态很好,但却需要耗费更多的晶体管、占用更大的核心面积。事实上,AMD以往的GPU之所以经历数代都不愿意放弃VLIW架构自然有其中的原因。对于图形渲染来说编译器调度方面并没有太大影响,VLIW甚至在这方面做的相当不错。而且更重要的是可以使用更少的晶体管,有限的核心面积也可以得到更好的利用——填充更多的附加功能单元。说到这儿,是不是很容易让人联想到NVIDIA呢?
那么有了动态调度和和全新的SIMD之后,我们能做以前不能做的呢?在VLIW的理想情况下,如下方第一张图所示,4个wavefront分别各自独立且毫不相关,可以看到新架构和VLIW的执行情况和类似,理论上效率都是100%;不过对于VLIW架构来说,不理想的情况就是遇到相关的指令流,比如下方第二张图的两个绿色wavefront,这样以来前三个wavefront在一个周期执行,最下方的蓝色只能独立执行。而对于新架构来说,则不存在这样的问题。也就是说,采用硬件调度之后,CU和SIMD可以允许选择不同的wavefront乱序执行,wavefront可以来自同一任务,也可以是不同任务。当然,这种“乱序”也不是绝对的,基本的流程还是要遵守的,比如各个wavefront之间的指令必须按顺序执行,不能打乱也不能分割;
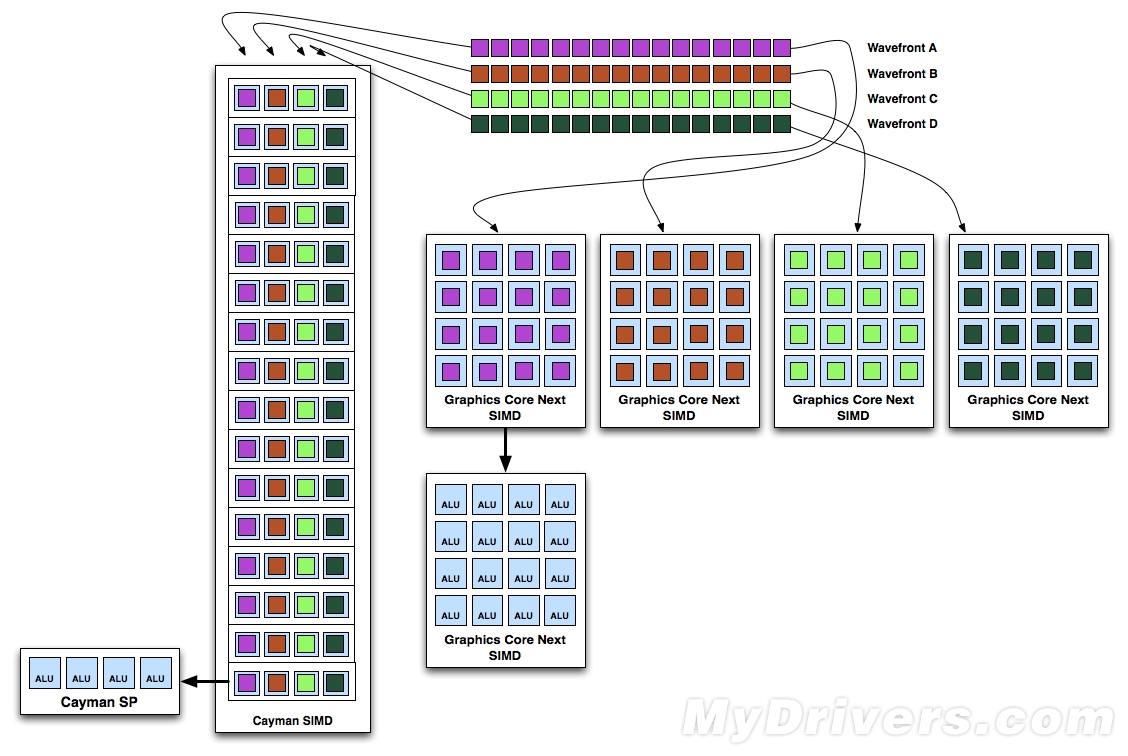
VILW理想方案:所有的WaveFront都不相关

VLIW的不理想状态:一个或两个相关的WaveFront
经过以上的介绍不难看出,以往的VLIW架构在并行任务处理方面处于劣势,并且很依赖编译器和API的支持,扩展到OpenCL也受到很大限制。经过硬件架构的调整,新架构在并行计算方面有了很大提高。其中每个SIMD有10个wavefront可供选择,也就意味着每个CU的wavefront数量依次可以达到40个。这也就是AMD全新架构放弃多年采用的VLIW,转而采用non-VLIW SIMD最为根本的原因。除此之外,带来的其它好处也是不少。首先是编译压力减轻,硬件调度的加入使编译器摆脱了调度任务;其次是程序优化和支持语言扩充更见容易;最后是不用在生成VLIW指令和相关调度信息,新架构最底层的ISA也更加简单。
计算单元组成的GPU了解完全新的SIMD和CU的概念,下面再来看看详细的总体架构组成。和传统的多流处理器单元组成SIMD阵列,多个SIMD阵列组成GPU的思路类似,新架构也是由包含数个计算单元的CU阵列搭建而来。虽然下面的讲解只是AMD从宏观高度的一个概览,具体细节单元不可能面面俱到,不过我们依然能从其中得知一二。
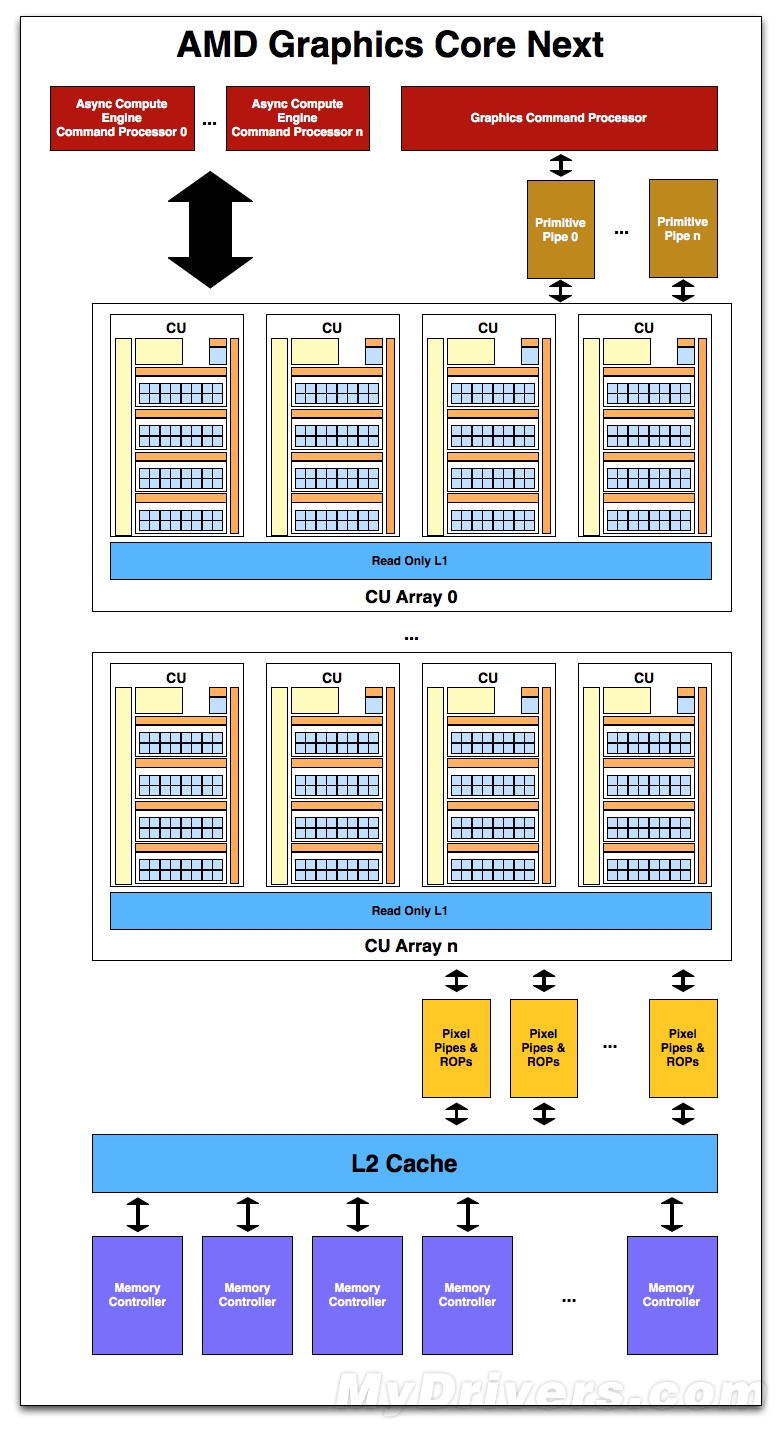
Graphics Core Next全新架构示意图
先从显存和缓存开始说起,我们知道从R600架构时代引入的GDS(Global Data Share)发展至今一直是GPU唯一的临时缓冲单元,虽然RV770加入了LDS(Local Data Share)对GDS进行补充,但是从计算角度来看依然作用不大。新架构改变最明显的一点就是会把L2缓存和显存控制器进行搭配,每个显存控制器可以共享64KB或者128KB的L2缓存(还不太确定),这样以来在并行访问显存的时候可以大大节约宝贵的带宽。
另外,GPU和CPU的同步也可依靠L2缓存提高效率。虽然这种缓存机制很像NVIDIA费米架构的缓存体系,但其中也存在很多差异。新架构的缓存并不与ALU直接连接,而且和GDS和LDS没有任何关系。另外,纹理单元可以直接访问L2缓存。这些与费米架构还是存在本质上的不同的。
与此同时,新架构的异步计算引擎(Asynchronous Compute Engines,ACE)将会充当command Processors的角色用于运算操作,而ACE的主要作用就是接受任务并将其下遣分配给CU处理(主要是分配的过程)。全新架构强化了多任务的并行处理设计,一个GPU中将会看到多个ACE用于多重并发操作,例如资源分配、上下文切换以及任务优先级决策等等。由于AMD目前尚未明确指出各个ACE之间的直接关系以及可以最多并行处理任务的数量,所以我们也不好做出猜测。
不过可以确定的是,有了ACE的直接作用就是新架构拥有了一定程度的乱序执行能力。就像上文我们提到过的一样,虽然严格意义上新架构依然是顺序执行架构,一个完整wavefront中的指令执行顺序不能被打乱,但是ACE可以做到对不同的任务进行优化和排序,划分任务执行的优先级别,进而优化资源。从本质上来说,这与很多CPU(比如Atom、ARM A8等等)处理多任务的方式并没有什么不同。
接着向下说,与目前的Cayman类似,Graphics Command Processor位于新架构的顶层,负责整个GPU组件单元执行任务的调遣(功能与传统架构中的GCP基本相同)。在此之下,Cayman架构的“双核心”将会被传统的“管线”(也就是CU阵列流水线)所代替,主要负责常见的几何和一些固定功能处理,比如曲面细分、几何转换以及纹理贴图等等。
相对于传统GPU的“既定架构”,新架构是完全可扩展的,几何处理能力将会大大增强。经过计算单元处理之后,就是像素管线和ROP单元了(同样可扩展),虽然AMD并未给出详细的设计方案,但我们猜测ROP/L2缓存/显存控制器三者之间会有紧密联系(比如数量关系等等)。此外,AMD还透露了一点新鲜的细节:部分驻存纹理(Partially Resident Textures,RPT)。按照AMD的说法,RPT允许纹理单元的一部分载入到显存之中,以免整个纹理单元都由显存处理造成不必要的性能损失(一部分可能无用)。
遗憾的是,普通用户最关心的附加功能信息到目前一概欠奉,情况很像最初费米架构初露苗头的时候。再加上AMD Fusion开发者峰会本身主要面对开发者,所以更多是展示计算方面的细节而非图形性能,也就不奢求更多了。
不只是新架构还有新特性以上章节我们分别介绍了Graphics Core Next全新图形架构的细节、构成、工作流程以及相对传统的VLIW架构有何优势。根据以往经验,伴随着新架构往往会有一堆全新特性,尤其是革命性架构出现的时候。此次也不例外,Graphics Core Next将会带来一系列新的特性,强化GPU的计算性能提升GPU相对于CPU的地位。

首先,最底层的特性革新就是新架构将会全面支持C/C++和其它高级语言,加入对指针、虚拟函数、异常处理以及递归循环的支持等等。这也就意味着开发过程更加简单,代码也更加容易调试和维护,GPU和CPU将在同一程序下进行编程。虽然从目前来看,给桌面消费者带来的好处不是那么直接,但是未来肯定会有更加功能丰富和实用的程序供GPU加速使用。
由于底层特性特性得以进化,内存子系统也能为之服务。主要变化就是GPU在硬件上支持ISA并且可以访问所有系统内存。语言特性的革新使得开发者编写代码的时候不在区分CPU和GPU,程序(甚至是编译器)可以随时随地的引用系统内存,运行之前二者之间不需要互相拷贝内存。

有意思的是,新架构还增加了统一寻址空间,并且采用x86 64位寻址空间,这也就意味着GPU和CPU将拥有统一的寻址空间,而GPU主要负责本地内存的物理地址转换。事实上,新架构还合并了IOMMU(input/output memory management unit)用于实现这一功能,而之前我们见到的IOMMU主要用于虚拟环境下外围设备的支持。另外,新架构甚至很好地能够处理内存分页错误,当然这些功能还是要依赖于操作系统的支持,或许现在的Win7并不足以发挥新架构的全部特性。
在内存方面新架构还增加了ECC(Error Checking and Correcting)功能,用于补充现有的EDC(Error Detection & Correction),主要用于保证内存传输经过GDDR5高速总线时的数据完整性和准确性,系统内存和显存都能受到ECC的保护,这一点也许和NVIDIA的某些做法一样。
另外,我们还注意到了64位浮点运算。所有采用新架构的GPU都会加入对64位浮点运算的支持,也就是说64位浮点运算也将会作为新架构的一个标准特性纳入其中。而且实际的64位浮点运算性能是可配置的——支持1/2倍速、1/4倍速以及1/6配置。当然,我们更希望AMD能够学习NVIDIA采用低倍速,毕竟目前64位浮点运算对于桌面消费者来说并不是那么重要。
当然,作为一款图形架构,最根本的3D图形自然不会背抛弃,也会随新架构的计算能力异同同进化,而且GPU内仍会有固定功能硬件,未来还会实现FSA、3D的融合,让计算能力为3D图形服务,从而达到AMD Fusion融合之路最根本的目的。
总结:为计算优化的新架构随着架构越来越复杂,传统“半年架构一更新,GPU性能增长一倍”的说法已经不在适用于目前的GPU发展,再加上先进制造工艺的步伐放缓,GPU架构更新的周期被大大延长(1年、2年或者更长),我们现在看到的GPU大多是在原有架构上“缝缝补补”。对于现代GPU来说,一次换代并不仅仅是硬件架构的革新,更多时间的是开发者们对新架构的适应以及对新特性的吸收。从某种意义上来讲,本次AMD Fusion开发者峰会以及Graphics Core Next全新图形架构的提出,就是给开发者们更多的时间去了解新架构带来的好处,从而利用这些优势推动应用软件及相关领域的发展。
正式基于这次机会,我们才有幸比较深入的了解全新架构的种种细节,即便很多方面由于种种原因未能得知,但依然让人对AMD未来的图形架构充满憧憬。就目前的产品发展状况来看,原定于2012年发布的下一代Trinit APU依然会基于已有的VLIW4架构的Cayman核心,也就意味着近短期内不会看到Graphics Core Next全新图形架构。虽然,AMD官方没有明确表态新架构何时能够出现,但我们相信它已经不再遥远了。
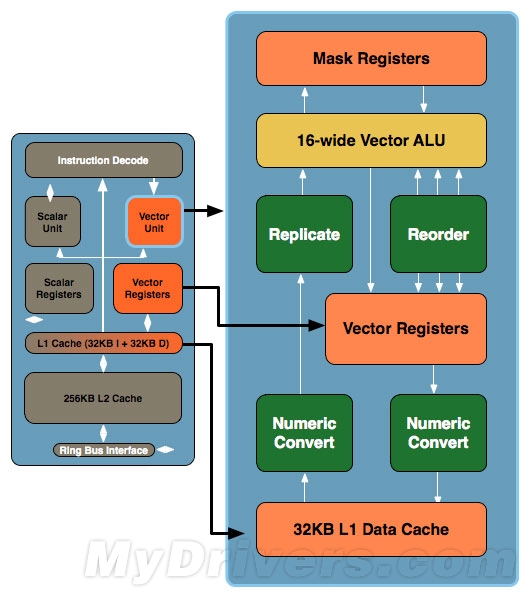
Larrabee架构示意图
从架构设计来看,统一寻址、C++等高级语言的支持、ECC内存纠错等特性以及全新设计的ALU,都让人不由得联想到NVIDIA的费米和Intel的Larrabee架构(特性像费米,运算单元像Larrabee),不得不说Graphics Core Next和费米以及Larrabee在很多方面的革新都有着异曲同工之妙。我们不想说是AMD照搬了NVIDIA和Intel的成功设计经验,至少在新架构正式发布之前我们不想这么说。但是无论如何,优秀的通用计算和并行处理架构、高效的代码执行效率和全新特性,种种偏向计算设计线索都预示着AMD以往坚持数年之久的发展路线将遭到颠覆。
在AMD以往的GPU中,我们看到的是小巧的核心、容易扩充的架构、丰富的特性、精于图形架构,最重要的是这一切都建立在有限数量的晶体管之上(相对于NVIDA来说)。而与之相对的是,NVIDIA苦心数年研发的费米架构虽然在通用计算方面无可匹敌,但浪费了太多的核心面积和晶体管,从而导致图形方面表现的不尽如人意,尤其是在功耗和性能的均衡方面始终难以找到平衡点(至少费米架构第一批GTX 400是这样)。如此看似和图形没有一点关系的浪费值得吗?如今,AMD将这一切优势基础摒弃(事实上这是很难的),转而更趋向于对手的发展方向。我们不仅要问,AMD是怎么了?
而我们要说的是,随着技术的发展,图形和计算的概念已经不再像以往分的那么清楚了,NVIDIA和AMD作为行业的领军者,毫无疑问要比我们看的更远,他们都没有错而是我们错了。进入DX11时代时候,全新API和新特性带来了以往DirectX 版本看不到的东西,尤其是大量的图形特效可以靠GPU的计算能力进行加速,这一切在要求传统图形渲染能力的同事,对GPU的计算能力要求十分苛刻,而未来图形架构的发展势必会顺应这一趋势。由此看来,AMD下定决定进行大规模的架构革新也就不奇怪了。
不过在畅想全新架构带来出色体验的同时,我们不免担忧:Graphics Core Nex能够处理好一切吗?毕竟作为普通消费者的我们,实在是不想看到一个完全偏向于通用计算的GPU。虽然AMD声称会在图形和计算之间找到平衡点,但费米和Larrabee架构的经验和教训告诉我们:一切都不是那么的容易。最重要的是,新架构的颠覆势必会给AMD未来的发展带来前所未有的冲击,一旦出现失败AMD以往数年的精力和心血都会付之东流,这是所有人都不愿意看到的。
当然,面对新鲜事物的出现我们要抱着积极态度,既然如此决定,也说明了AMD已经做好了面对一切困难和挑战的准备。我们希望Graphics Core Next的出现,能够为AMD带来了更加光明的未来。
本文收录在
#快讯
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...