正文内容 评论(0)

Pentium 4的设计理念区别于PentiumIII和Athlon XP的一个最主要的区别就是其超长的流水线设计,Intel称为NetBurst架构。其根本出发点就是通过提升核心时钟频率来提高处理器的性能,为此将流水线长度大大增加。什么是流水线呢?我们可以将其与自动化生产流水线做类比,比如彩电流水线。它是把每一步需要完成的任务加以分解,称为级。所有的CPU运算操作都是由这些级组成的。设计流水线,也就是分解设计这些级,可以设计的短一些比如20级,也可以长一些比如30级。30级流水线和20级相比就是任务分解的更细了,但最终运算结果两者都是一样的。显而易见,30级流水线每级的任务要简单一些,所需的晶体管或门电路也就要少,每级完成任务的用时也相应降低。对CPU设计来说,流水线中每级的速度越快,CPU的频率上限就越高,这就是Pentium 4可以轻易提升频率的原因。
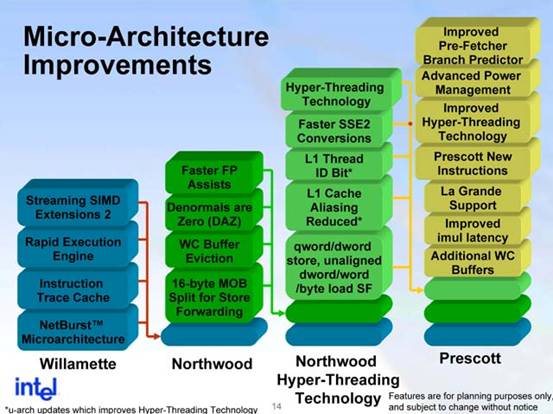
所以我们看到Pentium III的流水线为10级,它的频率没有超过1.5GHz,Pentium 4中Northwood核心的流水线为20级,它可以达到3 GHz以上的频率。于是在Prescott身上,Intel更上一层楼,采用了增强NetBurst架构,使用超长流水线设计,将流水线一举增加到31级,更有人认为Intel实际上是增加到了35-36级。这样预计Prescott的频率可以达到5GHz以上。
凡事有利也有弊,超长的流水线和正常的流水线相比,一个大弊端就是:很难保证流水线中所有的级都是满负荷工作的,也就是说超长的流水线的工作效率要低下一些,这也是最初Pentium 4不如同频PentiumIII的主要原因之一。同Northwood核心相比,Prescott的流水线长度又增加了50%,必然进一步造成效率的损失,会消耗掉其它方面改进得来的提升。所以改进的超长流水线,只是为了将来 Prescott频率的提升做准备,我们就把它理解为Intel对“一切为了明天”的具体阐述吧。
不仅如此,超长流水线还会带来其他一系列问题。当核心频率越高时,越容易出现缓存没有数据供给处理器处理的情况,这无疑是以浪费核心时钟周期为代价的。而且,目前系统架构中的内存子系统速度与处理器的速度相比是非常慢的,基于NetBurst架构处理器中的ALU算术单元更是以处理器时钟的两倍频率运行,因此处理器需要浪费很多时间来等新数据的到来。
更麻烦的是超长流水线在出现分支预测错误时会造成更多的损失。所谓分支预测,我们知道普通程序运算时的程序指令通常都包含各类型的条件选择和分支语句,通过具体的验证条件决定程序执行路线。但CPU的执行单元有些不同,它为了节省在验证语句处消耗的等待时间,必须通过一项特殊的预测机制,估计程序可能会选择的线路直接执行,然后在后面进行验证。如果预测正确当然万事大吉继续往下执行,但如果发现之前的预测错误,那么就必须返回原地重新开始,之前的指令就会被作废。因此,流水线越长,出现分支预测错误的机会就越多,如果预测错误,很多在管线内的指令会被清掉,重新填满流水线的时间也就越多。毫无疑问这将花费更多的时间,整体性能也会严重下降。
到此,我们好像看到了这样一个奇怪的循环:一方面超长流水线会带来种种弊端,降低CPU工作效能,另一方面Intel却在拼命的增长流水线的长度,在最新的Prescontt中将流水线长度又增加了50%。那么Intel是何苦呢?其实想想也不难理解,超长流水线固然会带来效率低下等弊端,但它最大的好处是可以简单、迅速的提升CPU频率,而Intel认为高频带来的性能提升不仅完全可以弥补超长流水线带来的弊端,还可以大大提升CPU的总体性能,后劲更大。Intel的这种设计思路已经在之前Pentium 4体系的发展中得到了验证,并且到目前为止这种做法被证明是成功的(不仅仅是技术更是商业上),所以Intel在Prescontt身上故技重施就一点不奇怪了。更何况Intel对于分支预测也进行了种种改进,进一步降低超长流水线对性能的消耗。
从Pentium 4开始,Intel就开发了一套基于NetBurst架构很有成效地分支预测算法,到Prescott它的分支预测又作了进一步的改进。一方面增大分支目标缓存(简称BTB)来提高命中率,另一方面进一步改进了分支预测算法,最后是依靠更大的指令追踪缓存来减少分支预测带来的损失。
在NetBurst架构中,分支目标缓存主要是用来存放分支预测单元的目标信息,同时还承担着指令编译、二级缓存资源分配等处理任务。这次在Prescott的16KB一级缓存中就分配了4KB缓存来进行分支预测。而CPU的分支预测缓存越大,储存的数据量就越大,提供的信息也就越多,分值预测的准确率也就越高。和Northwood核心相比,Prescott的分支目标缓存仍是2组4路设计,但其存储字长比Northwood的高了一倍,达到了64位,大大提高了分支预测的准确度。
在分支预测算法方面,先前的Northwood核心采用后分支预测,即不是所有的向后分支都需要被执行,只要结果不出现错误,预测就不必执行。Prescott核心改进了分支预测统计算法,借判断分支目标和实际分支指令之间的差距,来决定是否要实现分支操作。由此提高了静态分支预测能力。对动态分支预测Prescott也同样进行了改进。此外还有一种间接分支预测,首先被应用到Pentium M处理器中,并已经证明是相当高效的,这次也被移植到了Prescott中。
经过上述努力,和Northwood相比,Prescott对分支预测进行的改进让错误预测减少了12%,这将会大大降低因为重新充满管线所带来的延迟。但减少固然是减少了,并不意味着分支预测错误不会再出现,为了在出错后,尽量减少损失Intel在Prescott上更是增大了指令追踪缓存。
对于普通处理器,当分支预测出错后,必须将整条流线清空,然后从错误处重新开始执行,这对于Pentium 4这种超长流水线的CPU简直是不可想象的。指令追踪缓存就是在这种情况下产生的。它存放的都是CPU已经执行过了的指令,当分支预测出错时,可以根据这些存放的已经执行过了的指令尽快回到出错前的断点。在指令存放方式上采用的是先进先出的方式,指令追踪缓存存放若干条已经执行过的指令,当指令条数超过存储空间后,就将最先进入指令追踪缓存的指令清除。当分支预测出错时,执行单元将直接回溯到出错处开始执行,从而大大避免了将整条流水线清空的几率。具体量化Prescott的改进就是:Northwood核心可以对2048个地址进行追踪,而Prescott可以对4096个地址进行追踪。
本文收录在
#快讯
- 热门文章
- 换一波

- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...