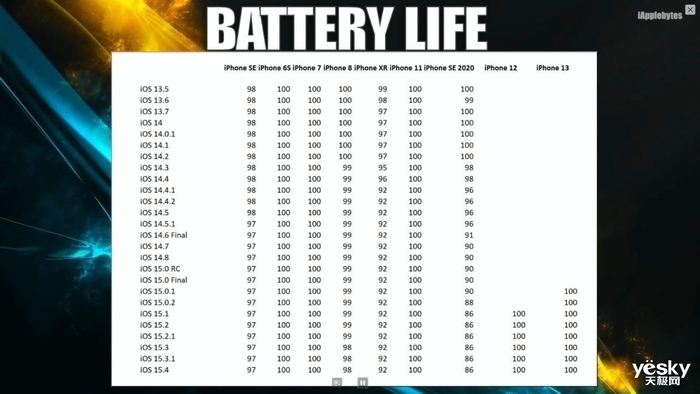
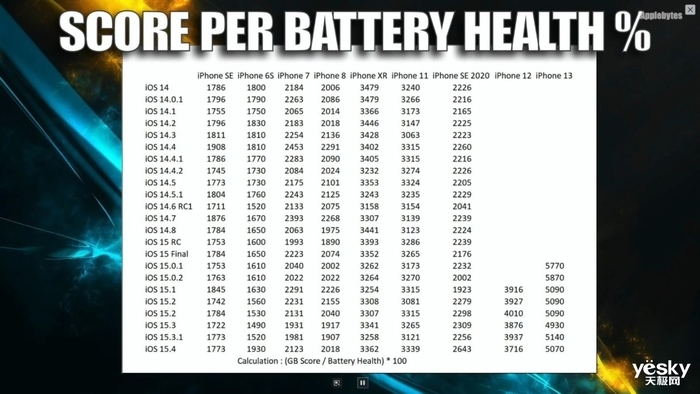
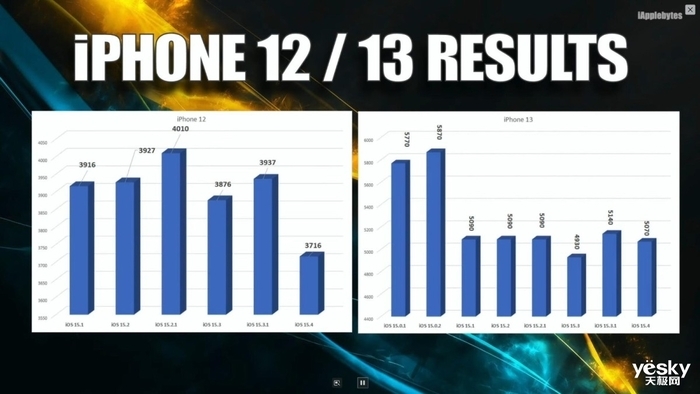
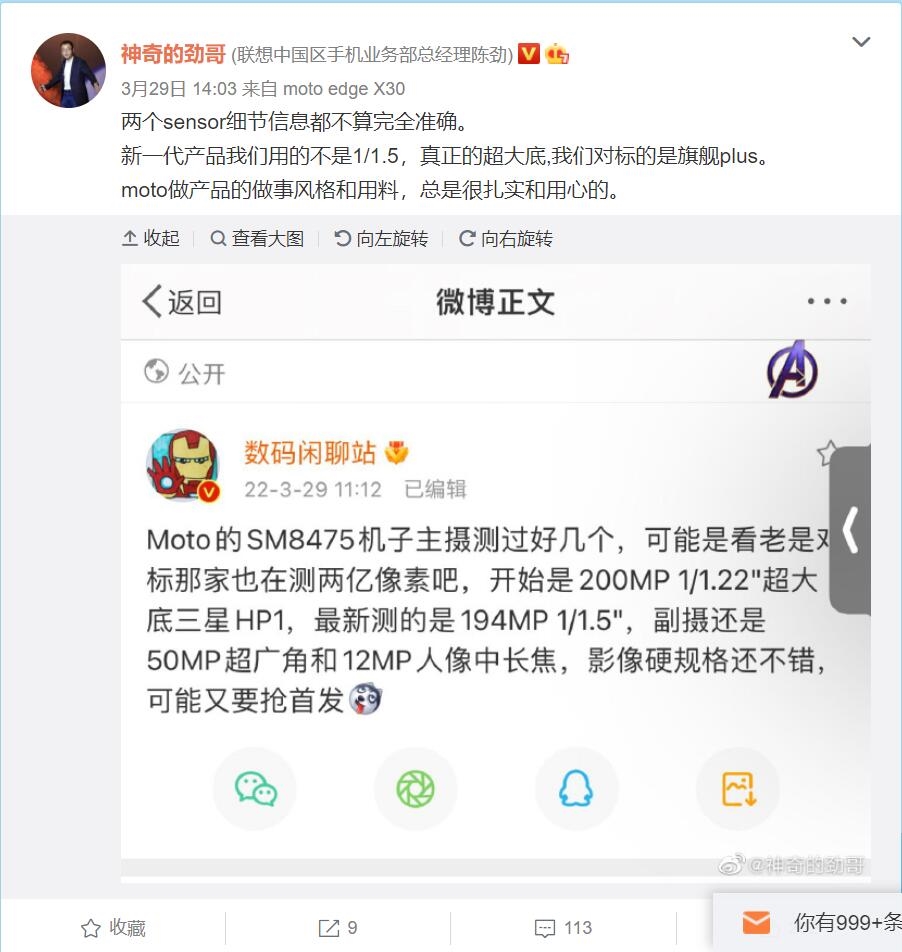
|
3дТ30ШеЭэЃЌIntelжегкЗЂВМСЫдЄШШСМОУЕФArcШёьХЯЕСаЖРСЂЯдПЈЃЌДњКХAlchemist(СЖН№ЪѕЪІ)ЁЃ
IntelЕФЩЯвЛПюИпадФмгЮЯЗЖРСЂЯдПЈЃЌЛЙвЊзЗЫнЕН1998ФъЕФi740ЃЌЕЋЪЧъМЛЈвЛЯжжЎКѓОЭУЛСЫЃЌКѓРДЕФLarrabeeЖРЯдМЦЛЎвВУЛФмПЊЛЈНсЙЙ(Г§СЫбмЩњГіЖЬУќЕФXe PhiМгЫйПЈ)ЁЃ
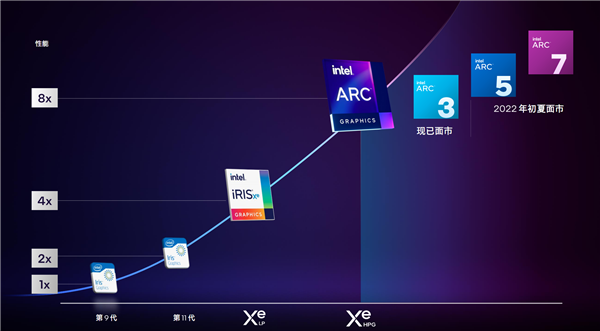
ЯждкЃЌ24ФъЙ§ШЅСЫЃЌIntelжегкЛиЙщгЮЯЗЯдПЈЃЁ

Intel ArcЯдПЈАќРЈ3ЁЂ5ЁЂ7Ш§ДѓЯЕСаЃЌЗжБ№ЖЈЮЛжїСїгЮЯЗЁЂадФмгЮЯЗЁЂЗЂЩегЮЯЗЁЃ
ЪзХњЕЧТНБЪМЧБОвЦЖЏЖЫ(КѓајТНајНјШызРУцЬЈЪНЛњКЭЙЄзїеО)ЃЌЖјЪзЗЂЕФЪЧжїСїЕФ3ЯЕСаЃЌ5ЁЂ7ЯЕСаНЋдкНёФъГѕЯФУцЪРЁЃ
ЦНЬЈДюЕЕжїСІЪЧ12ДњПсюЃH45ЁЂP28ЯЕСаИпадФмДІРэЦїЃЌвВШыЮЇСЫIntel EvoбЯПСШЯжЄЁЃ

ЁОаЭКХ/ЙцИё/адФмЃКзюИпьЕН150WЁП
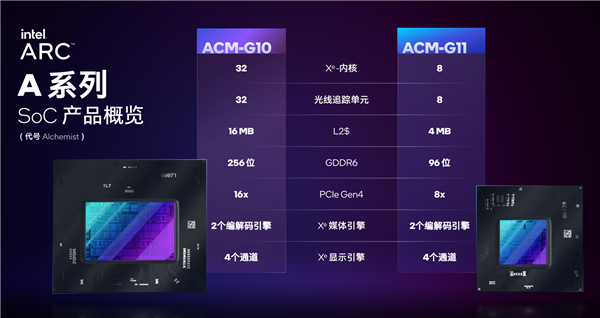



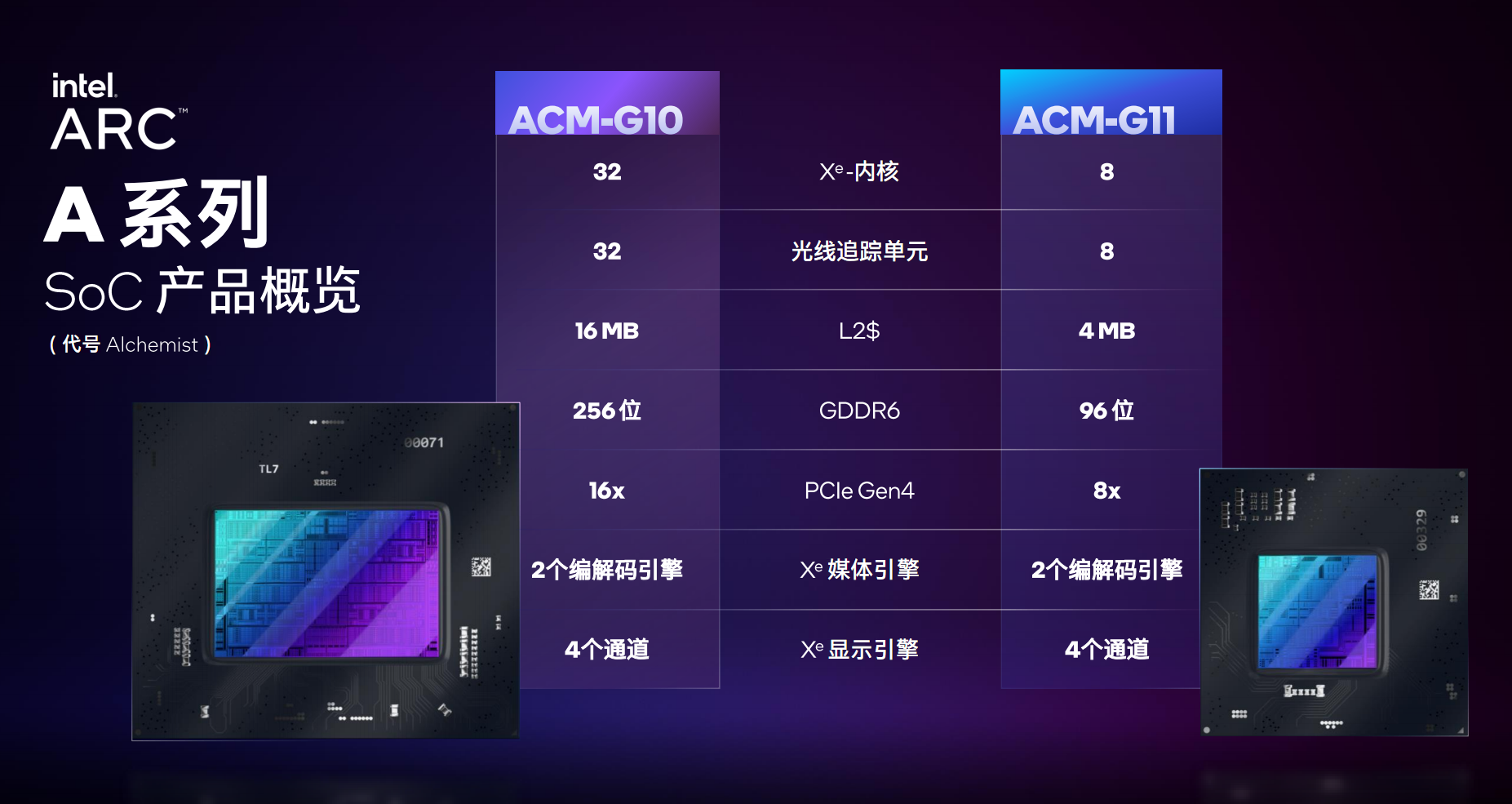
Arc AЯЕСагаДѓаЁСНжжВЛЭЌЕФGPUаОЦЌЃЌЦфжаДѓЕФБрКХ“ACM-G10”ЃЌгЕга32ИіXeКЫаФ(ПЩвдДжТдЕиРэНтЮЊ512жДааЕЅдЊ)ЁЂ32ИіЙтзЗЕЅдЊЁЂ16MBЖўМЖЛКДцЃЌДюХф256-bit GDDR6ЯдДцЃЌжЇГжPCIe 4.0 x16ЁЃ
аЁЕФБрКХ“ACM-G11”ЃЌ8ИіXeКЫаФЃЌ8ИіЙтзЗЕЅдЊЃЌ4MBЖўМЖЛКДцЃЌ96-bit GDDR6ЯдДцЃЌжЇГжPCIe 4.0 x8ЁЃ
ЫќУЧЖМОпБИ2ИіXeУНЬхБрНтТыв§ЧцЁЂ4ИіЯдЪОЭЈЕРЁЃ
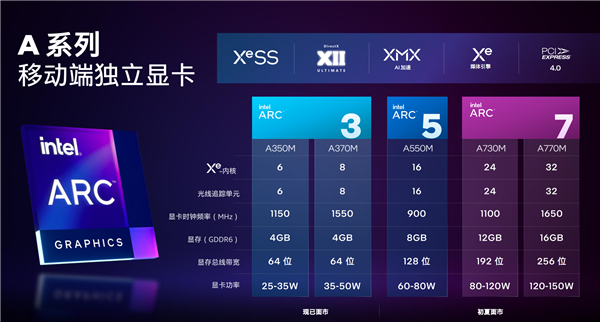
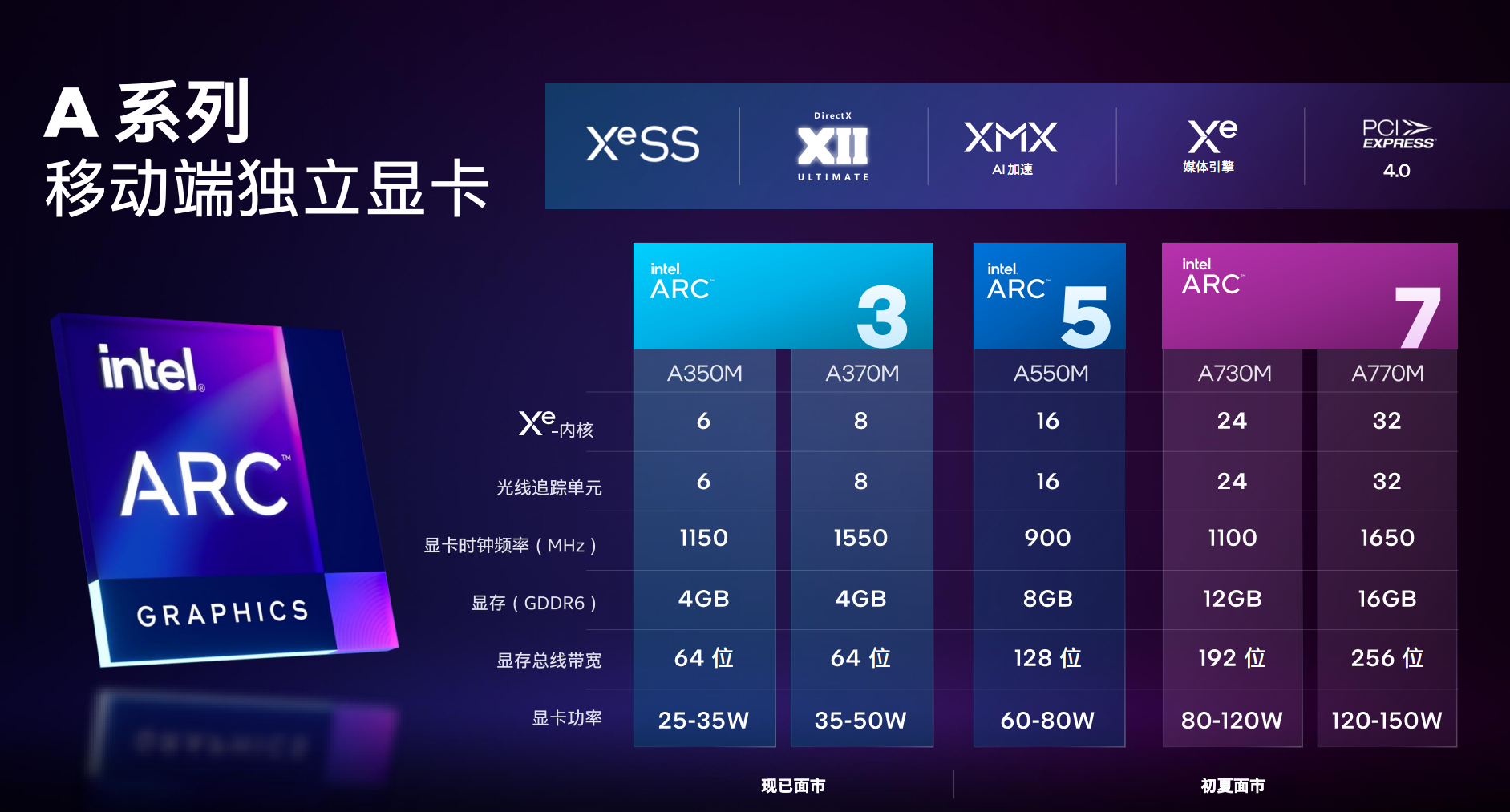
ВњЦЗЗНУцЃЌArc 3ЯЕСаЪзЗЂСНПюаЭКХЃЌИпЖЫЕФArc A370MКЫаФЦЕТЪ1550MHzЃЌ64-bit 4GBЯдДцЃЌЙІКФЗЖЮЇ35-50WЁЃ
Arc A350MОЋМђЕН6ИіXeКЫаФЁЂ6ИіЙтзЗЕЅдЊЃЌКЫаФЦЕТЪНЕжС1150MHzЃЌЯдДцВЛБфЃЌЙІКФЗЖЮЇдђЪЧ25-35WЁЃ
Arc 5ЯЕСаФПЧАНівЛПюаЭКХArc A550MЃЌ16ИіXeКЫаФЁЂ16ИіЙтзЗЕЅдЊЃЌКЫаФЦЕТЪНі900MHzЃЌДюХф128-bit 8GBЯдДцЃЌЙІКФ60-80WЁЃ
Arc 7ЯЕСаНЋгаСНПюаЭКХЃЌТњбЊЕФЪЧArc A770MЃЌ32ИіXeКЫаФ(512жДааЕЅдЊ)ЁЂ32ИіЙтзЗЕЅдЊЃЌКЫаФЦЕТЪИпДя1650MHzЃЌХфБИ256-bit 16GBЯдДцЃЌЙІКФЗЖЮЇИпДя120-150WЁЃ
Arc A730MОЋМђЕН24ИіXeКЫаФЁЂ24ИіЙтзЗЕЅдЊЃЌКЫаФЦЕТЪ1100MHzЃЌЯдДцНЕжС192-bit 12GBЃЌЙІКФ80-120WЁЃ
жЕЕУвЛЬсЕФЪЧЃЌArcЯдПЈЕФКЫаФЦЕТЪВЂВЛЪЧЙЬЖЈЕФЃЌЖјЪЧгавЛИіЖЏЬЌЗЖЮЇЃЌПЩвдИљОнВЛЭЌИКдиздЖЏЕїНкЃЌЙцИёБэжаЕФЦЕТЪжЛЪЧвЛИіЦНОљжЕЁЃ
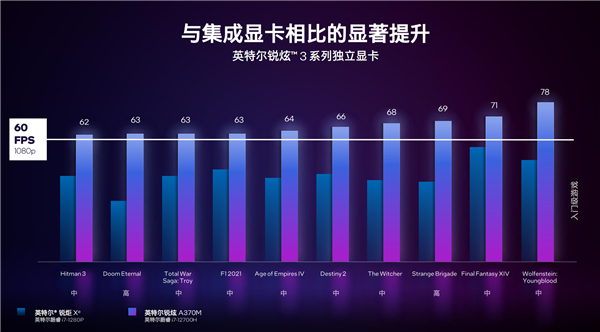
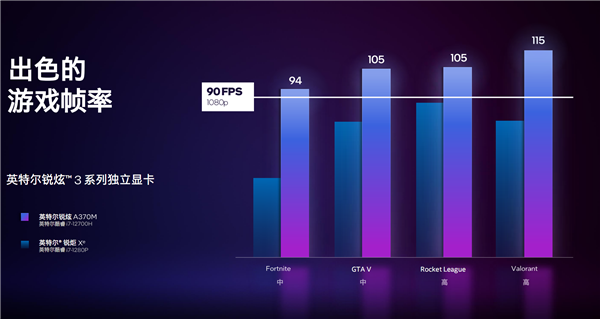
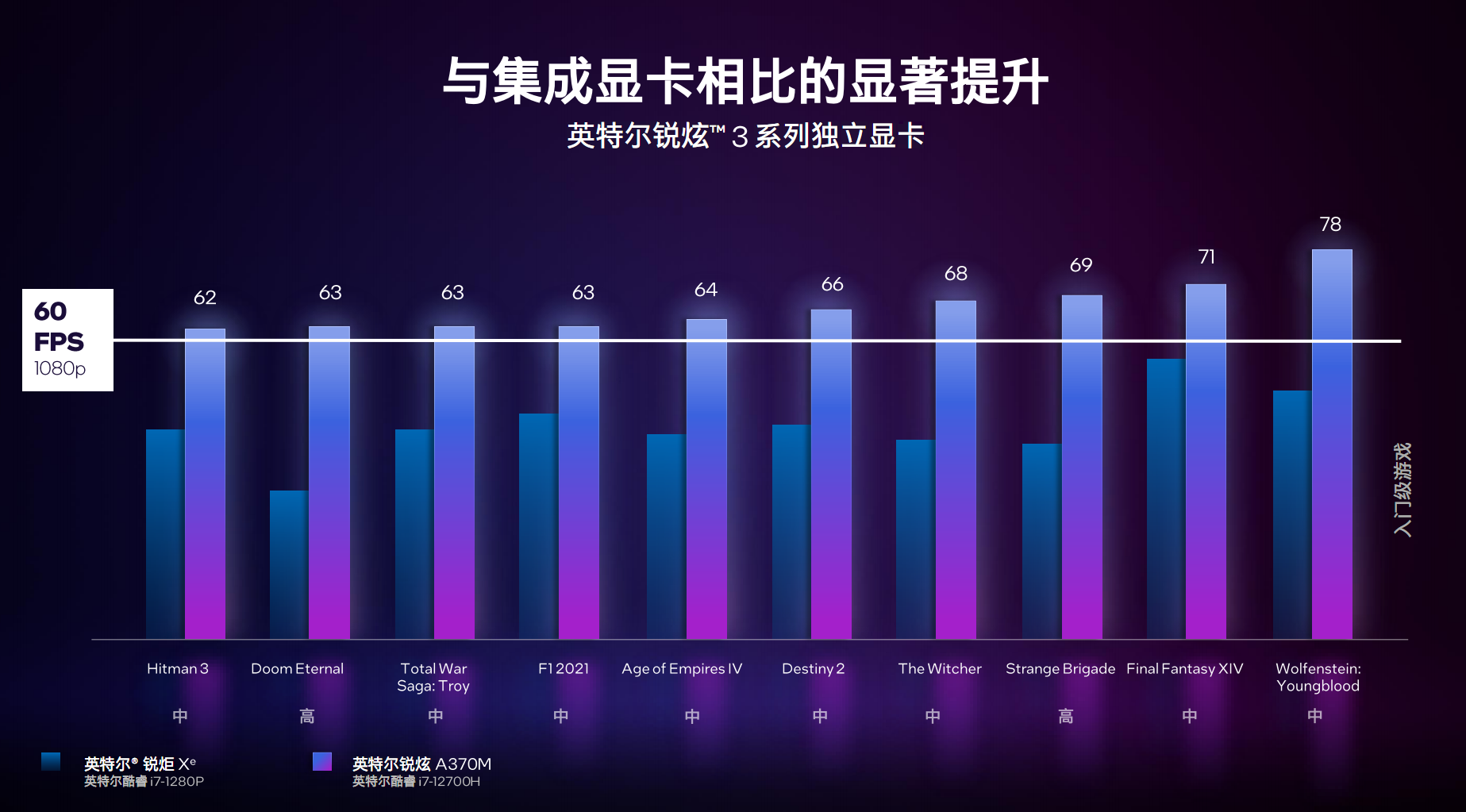
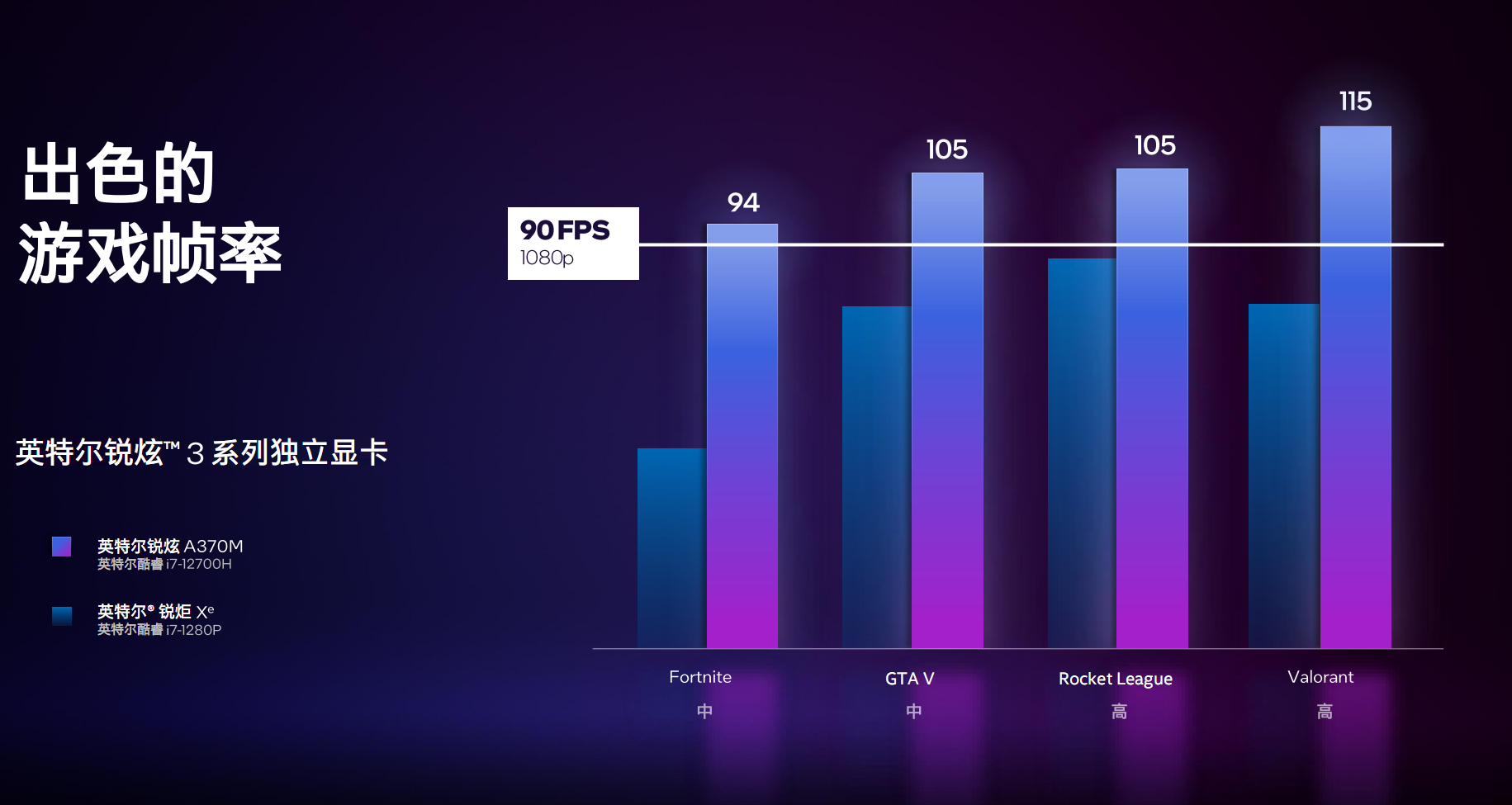
адФмЗНУцЃЌArc A370MЯдПЈДюХфi7-12700HДІРэЦїЃЌ1080pжаЕШЛжЪЯТЃЌДѓВПЗжжїСїгЮЯЗЖМПЩвдЮШЖЈГЌЙ§60FPSЃЌЁЖGTA5ЁЗЁЂЁЖЛ№М§СЊУЫЁЗЕШдђПЩвдГЌЙ§90FPSЁЃ
ЖдБШ12ДњПсюЃi7-1280PжаМЏГЩЕФ96ИіжДааЕЅдЊЁЂ1450MHzЦЕТЪЕФШёОцXeКЫЯдЃЌзлКЯгЮЯЗадФмИпГівЛБЖзѓгвЁЃ
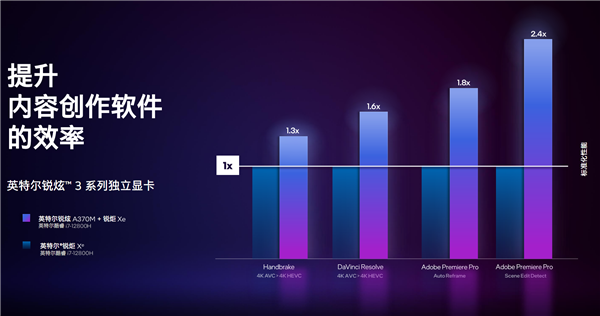
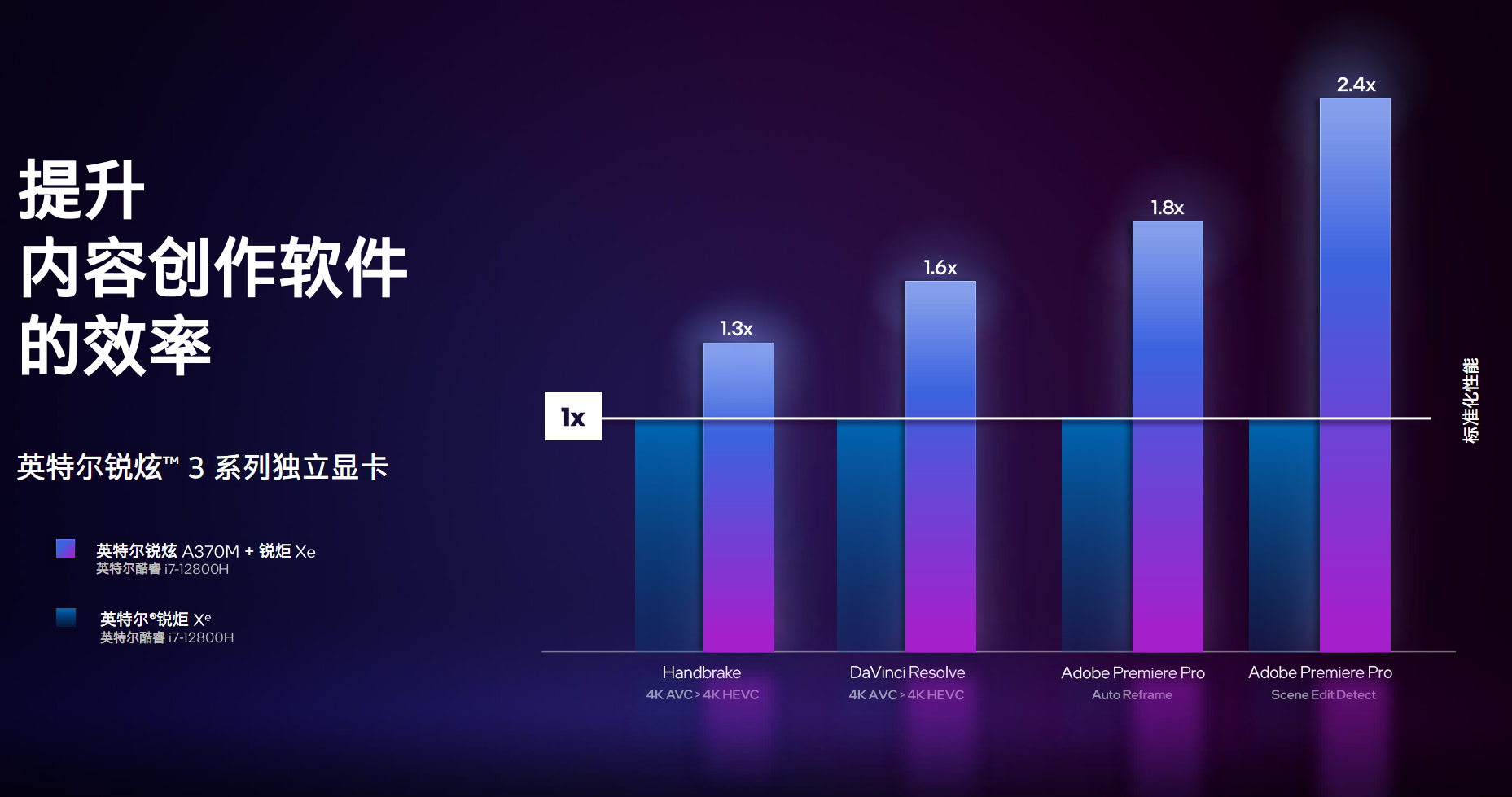
ЖјдкФкШнШэМўжаЃЌЕУвцгкгХЛЏЪЪХфЃЌадФмЬсЩ§ЗљЖШзюЖрПЩвдДяЕН1.4БЖЁЃ

ФПЧАЃЌЛљгкArc A300MЯЕСаЕФБЪМЧБОе§дкТНајЮЪЪРЃЌЦЗХЦАќРЈКъГЁЂЛЊЫЖЁЂДїЖћЁЂКЃЖћЁЂЛнЦеЁЂСЊЯыЁЂЮЂаЧЁЂШ§аЧЁЂРЖЬьЁЂЮХЬЉЕШЕШЃЌIntel NUCУдФуЛњвВЛсМгШыЁЃ
дкЙњФкЪаГЁЃЌArcБЪМЧБОНЋДгЯТИідТПЊЪМЩЯЪаЁЃ
ЁОФкКЫМмЙЙЃКетДЮЭъШЋБфСЫЁП

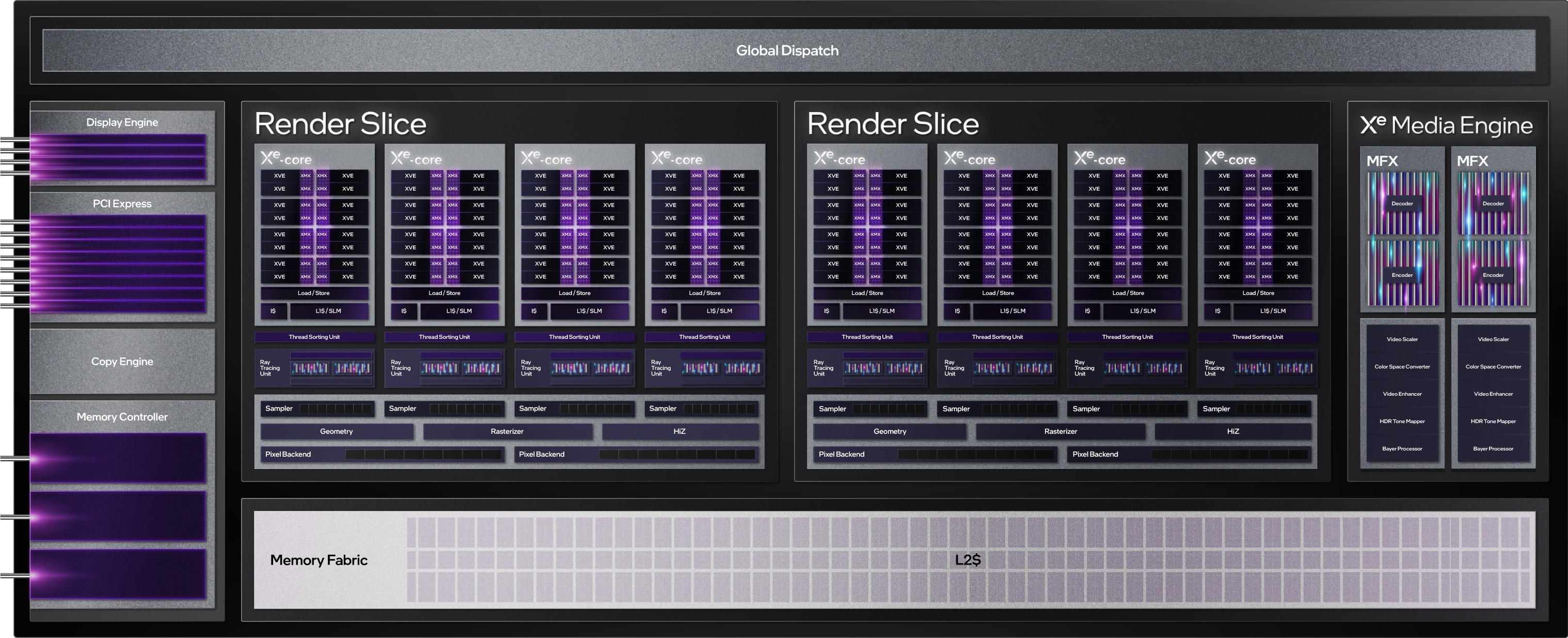
Intel ArcШёьХЯдПЈЛљгкИпадФмЕФXe HPGМмЙЙЃЌЛљБОзщГЩЕЅдЊАќРЈXeФкКЫЁЂXeУНЬхв§ЧцЁЂXeЯдЪОв§ЧцЁЂXeЭМаЮСїЫЎЯпЕШЃЌЮвУЧж№вЛРДПДЁЃ


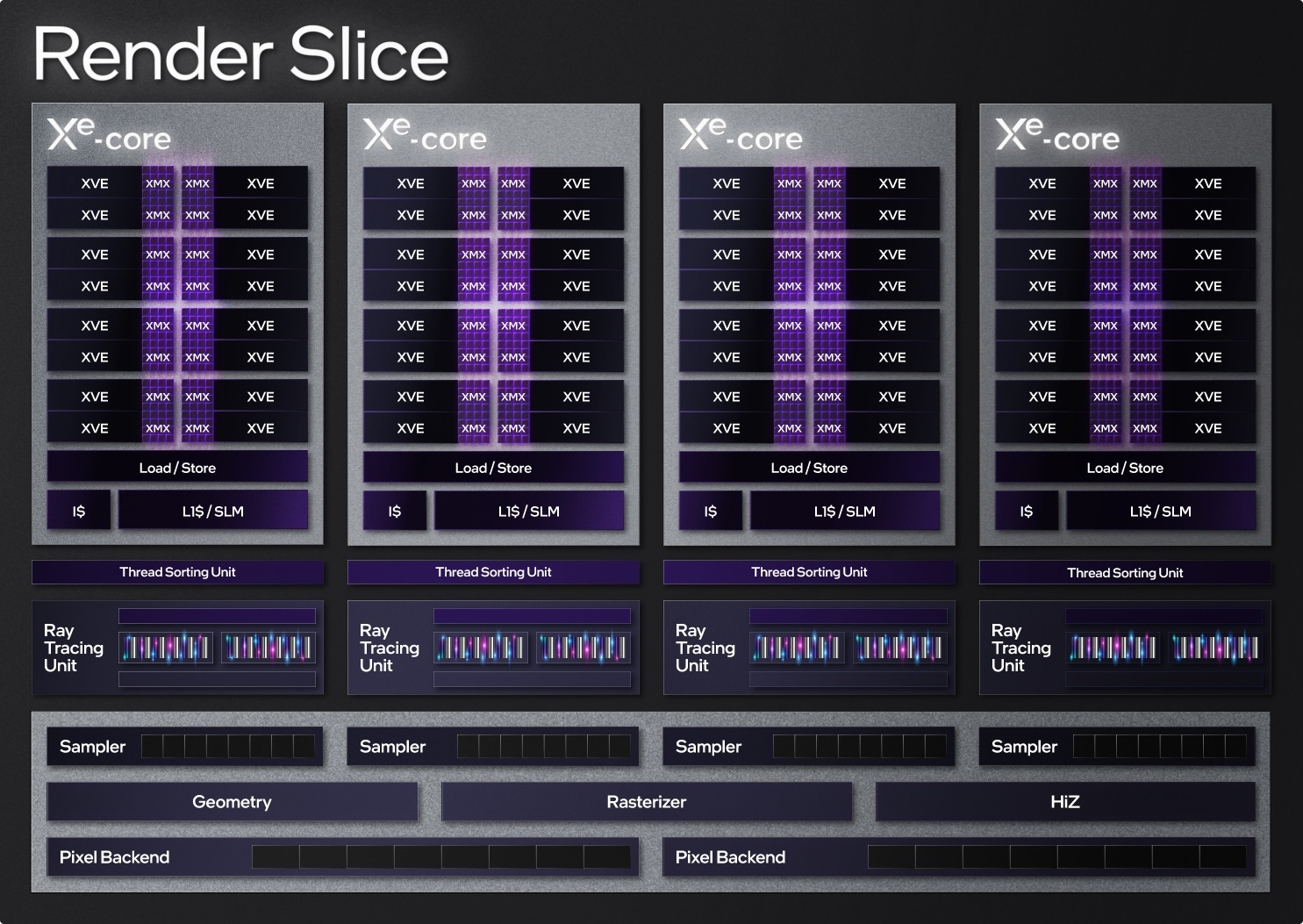
ДѓМвжЊЕРЃЌIntel GPUЖрФъРДЕФЛљБОФЃПщвЛжБЖМЪЧ“жДааЕЅдЊ”(EU)ЃЌXe HPGМмЙЙЩЯБфГЩСЫШЋаТЕФ“XeКЫаФ”(Xe Core)ЁЃ
XeКЫаФжагжАќКЌ16Иі256ЮЛЪИСПв§Чц(XVE)ЁЂ16Иі1024ЮЛОиеѓв§Чц(XMX)ЁЂ192KBЙВЯэЛКДцЁЂдиШыДцДЂЕЅдЊЕШЕШЃЌЦфжаЛКДцПЩвдИљОнЙЄзїИКдиЃЌдквЛМЖЛКДцЁЂЙВЯэБОЕиФкДц(SLM)жЎМфЖЏЬЌЗжХфЁЃ

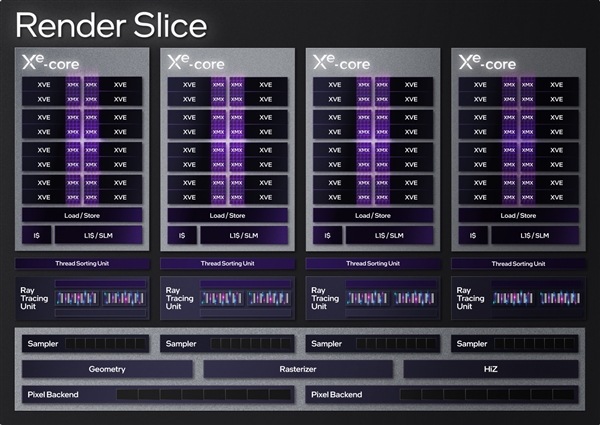
XeКЫаФЕФЩЯвЛВуМЖЪЧфжШОЧаЦЌ(Render Slice)ЃЌУПИіАќКЌ4ИіXeКЫаФЁЂ4ИіЙтзЗЕЅдЊЁЂ4ИіЮЦРэВЩбљЦїЁЂМИКЮЧАЖЫЁЂЙтеЄЧАЖЫЁЂHiZЕЅдЊЁЂ2ИіЯёЫиКѓЖЫЁЃ
фжШОЧаЦЌПЩвдЖрзщНсКЯРЉеЙЃЌArcЯдПЈзюЖрга8ИіЁЃ
ArcЯдПЈЭъећжЇГжDX12 UltimateЁЂVulkanЃЌВЂЧвЭЌЪБжЇГжDXRЙтзЗЁЂVulkanЙтзЗЁЃ

етОЭЪЧArcЯдПЈЭъећЕФФкВПМмЙЙЭМЁЃ

ЪИСПв§ЧцИФНјСЫALUЕЅдЊЃЌЬсЙЉзЈгУЕФFPИЁЕужДааНгПкЃЌЙВЯэЕФINT/EMећЪ§жДааНгПкЃЌУПИіЪБжгжмЦкПЩвджДаа16ИіFP32ВйзїЁЂ32ИіFP16ВйзїЁЂ64ИіINT8ВйзїЁЃ
гЩгкAIЫуЗЈКЫаФМИКѕЭъШЋЮЇШЦОиеѓГЫЗЈЁЂРлМгЫуЗЈЃЌЫљвдXeКЫаФРяМгШыСЫЕЅЖРЕФОиеѓв§ЧцЃЌзЈУХгУгкжДааXMXжИСюЁЃ
ЫќОпБИЖРСЂЕФжДааЖЫПкЃЌУПИіЪБжгжмЦкПЩвджДаа128ИіFP16/BF16ВйзїЁЂ256ИіINT8ВйзїЃЌ512ИіINT4/INT2ВйзїЁЃ
ЁОXeSSЃКЛЏИЏарЮЊЩёЦцЕФГЌЗжБцТЪЫѕЗХЁП
еыЖдОиеѓв§ЧцВЛЭЌжИСюЕФДІРэВйзїЃЌIntelвВзіСЫЯъЯИЕФНтЪЭЃЌЮвУЧРДМђЕЅСЫНтЯТЁЃ


MACзїЮЊЭМаЮфжШОжаЕФЛљБОSIMDЪИСПжИСюЃЌвВЪЧXeЪИСПв§ЧцЕФКЫаФЃЌПЩвджДаа8ДЮВЂааГЫЗЈЃЌШЛКѓжДаа8ДЮВЂааМгЗЈЃЌУПИіЪБжгжмЦкОЭЪЧ16ИіВйзїЁЃ
ЩЯЭМзюзѓВрЫЎЦНЗНЯђЕФЧАХХЁЂКѓХХРЖЩЋЗНПщЃЌОЭДњБэВйзїЪ§ЃЌЩЯЯТЕФЗНПђдђДњБэРлЛ§ЕФдДКЭНсЙћЁЃ
DP4aжИСюЪЧеыЖдВЛашвЊ32ЮЛОЋЖШЕФAIМЦЫуЫљзіЕФгХЛЏЃЌЙЄзїдРэЪЧНЋЫљга32ЮЛЪфШыЗжГЩ8ЮЛПщЃЌШЛКѓЖРСЂжДааЃЌзмЙВ32ДЮВЂааГЫЗЈ(зЯЩЋЗНПщ)ЃЌУПИіЪБжгжмЦкОЭЪЧ64ИіВйзїЃЌЯрБШБъзМSIMD MACЬсИпСЫ4БЖЁЃ
XMXжИСювВЪЧУПИіВйзїЗжГЩ4ИіПщЃЌШЛКѓЖРСЂЯрГЫЁЂРлМгЃЌЙВга64ИіВйзїЃЌУПИіЪБжгжмЦк4ИіНзЖЮОЭЪЧ256ИіВйзїЃЌгЩДЫДјРД16БЖЕФЫуСІЬсЩ§ЁЃ
XMXОиеѓв§ЧцзюжБНгЕФзїгУОЭЪЧжЇГХXeSSГЌВЩбљПЙОтГнММЪѕЃЌРрЫЦNVIDIA DLSSЁЂAMD FSRЃЌПЩвдЭЈЙ§ЕЭЗжБцТЪфжШОЁЂИпЗжБцТЪЫѕЗХЪфГіЃЌЬсЩ§гЮЯЗадФмЃЌВЂЕУЕНРрЫЦЛђГЌдНдЩњЕФЛжЪЁЃ

XeSSвбОЕУЕНСЫЪЎЖрПюгЮЯЗЕФжЇГжЃЌВЛЙ§ФПЧАЛЙВЛПЩгУЃЌЛсдкНёФъГѕЯФе§ЪНУцЪРЁЃ
ЯТБпИаЪмвЛЯТXeSSдкЪЕМЪгЮЯЗжаЕФаЇЙћЃЌзѓВрЪЧ1080pдЩњфжШОЃЌгвВрЪЧ4K XeSSЫѕЗХфжШОЃЌПЩвдУїЯдПДЕНКѓепЕФЛУцжЪСПИпЕУЖрЃЌЯИНквВИќМгЗсИЛЁЂШёРћЁЃ
жСгкадФмЬсЩ§ЗљЖШЃЌIntelднЪБУЛгаИјГіОпЬхЪ§ОнЁЃ





ЁОЖрУНЬхЃКЪзЗЂШЋаТЪгЦЕИёЪНAV1ЁП


XeУНЬхв§ЧцПЩвдЮЊжїСїЪгЦЕШэМўДјРДгВМўМгЫйЃЌНтТыжЇГжИпДя8K60 12-bit HDRЃЌБрТыжЇГжИпДя8K 10-bit HDRЁЃ
ЪгЦЕБрНтТыИёЪНВЛЕЋжЇГжMPEG-4ЁЂVP9ЁЂAVCЁЂH.264ЁЂHEVC(H.265)ЃЌИќЪЧЪзЗЂжЇГжAV1гВМўБрТыЁЂНтТыЁЃ
AV1ЕФБрТыаЇТЪЯрБШH.264ЁЂH.265ЗжБ№ИпГі50ЃЅЁЂ20ЃЅЃЌФмЙЛвдИќаЁЕФЮФМўЁЂИќЩйЕФДјПэДјРДИќИпЕФЛУцжЪСПЃЌЙиМќЪЧПЊЗХЕФЃЌЮоашАцШЈЗбЃЌЪЧПЊЗХУНЬхСЊУЫСІЭЦЕФММЪѕЁЃ

етИіСЊУЫЕФГЩдБЖМЪЧДѓУћЖІЖІЕФОоЭЗЃЌАќРЈбЧТэбЗЁЂЦЛЙћЁЂARMЁЂЫМПЦЁЂFacebookЁЂGoogleЁЂЛЊЮЊЁЂIntelЁЂЮЂШэЁЂMozillaЁЂNetflixЁЂNVIDIAЁЂШ§аЧЁЂЬкбЖЕШЕШЁЃ
AV1ЛЙдкЦ№ВННзЖЮЃЌЕЋЦеМАЫйЖШКмПьЃЌгШЦфЪЧНтТыЗНУцЃЌNVIDIA RTX 30ЯЕСаЁЂAMD RX 6000ЯЕСаЃЌСЊЗЂПЦЬьчс1000ПЊЪМЃЌWindows 10ЯЕЭГКЭВЛЩйЪгЦЕШэМўЁЂЪгЦЕЭјеОЁЂЪгЦЕЩшБИЃЌЖМвбОжЇГжЁЃ
РДЖдБШвЛЯТAV1ЁЂH.264дкгЮЯЗжБВЅжаЕФЛжЪВювьЃЌЗжБцТЪЖМЪЧ1080pЃЌТыТЪЖМЪЧ5MbpsЁЃ




ЁОЯдЪОЃКжЇГжЦНЛЌЭЌВНЁП

XeЯдЪОв§ЧцжЇГжHDMI 2.0bЁЂDisplayPort 1.4aЪфГіБъзМЃЌВЂЧвЮЊЯТвЛДњDisplayPort 2.0 10GзіКУСЫзМБИЁЃ
ЪгЦЕЪфГівВжЇГжМЋИпЕФЗжБцТЪЁЂЫЂаТТЪЃЌзюИпПЩвдЫЋТЗ8K60 HDRЁЂЫФТЗ4K120 HDRЃЌвдМА1080p360ЁЂ1440p360ЁЃ

ЭЌВНММЪѕИќЪЧДјРДСЫШ§жжЃЌзюГЃМћЕФЪЧVESAБъзМЕФAdaptive Sync(ЪЪгІадЭЌВН)ЃЌгыЯдЪОЦїЫЂаТТЪЭЌВНЃЌЯћГ§ЛУцЫКСбЃЌЕБНёЖрЪ§гЮЯЗБОЕФЦСФЛЖМжЇГжИУММЪѕЁЃ
ЦфДЮЪЧSpeed Sync(МгЫйЭЌВН)ЃЌПЩвддкЙиБеV-SyncДЙжБЭЌВНКѓЃЌЮЊЕБЧАжЁЬсЙЉМгЫйЃЌВЛНіПЩвдЯћГ§ЫКСбЃЌЛЙОпБИЕЭбгЪБЁЂЮоЩЯЯоЕФгХЕуЁЃ

зюКѓЪЧаТЕФ“Smooth Sync”(ЦНЛЌЭЌВН)ЃЌЭЈЙ§ЖЖЖЏЙ§ТЫЙІФмЃЌЖдЛУцЫКСбНјааФЃК§ЛЏДІРэЃЌБЃжЄЭЌВНЮоЫКСбЁЂЮоЪЇецЁЃ
ЁОDeep LinkЃКCPU+GPUаЭЌЗЂСІЁП

ДІРэЦїЁЂЯдПЈЖМЪЧздМКМвЕФЃЌздШЛвЊСЊКЯзїеНЃЌетОЭЪЧDeep LinkММЪѕЃЌПЩвдШУПсюЃДІРэЦїЁЂКЫЯдЁЂЖРЯдаЭЌЪЭЗХИїздЕФЧБСІЃЌжївЊгІгУАќРЈШ§ИіЗНУцЁЃ
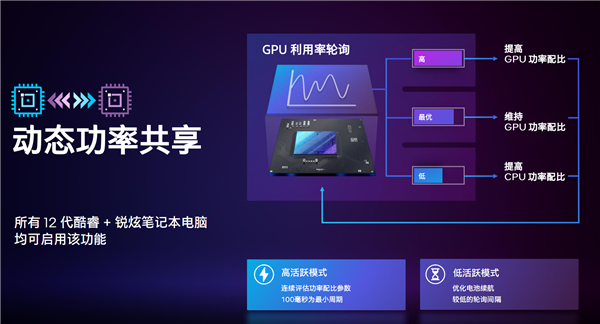
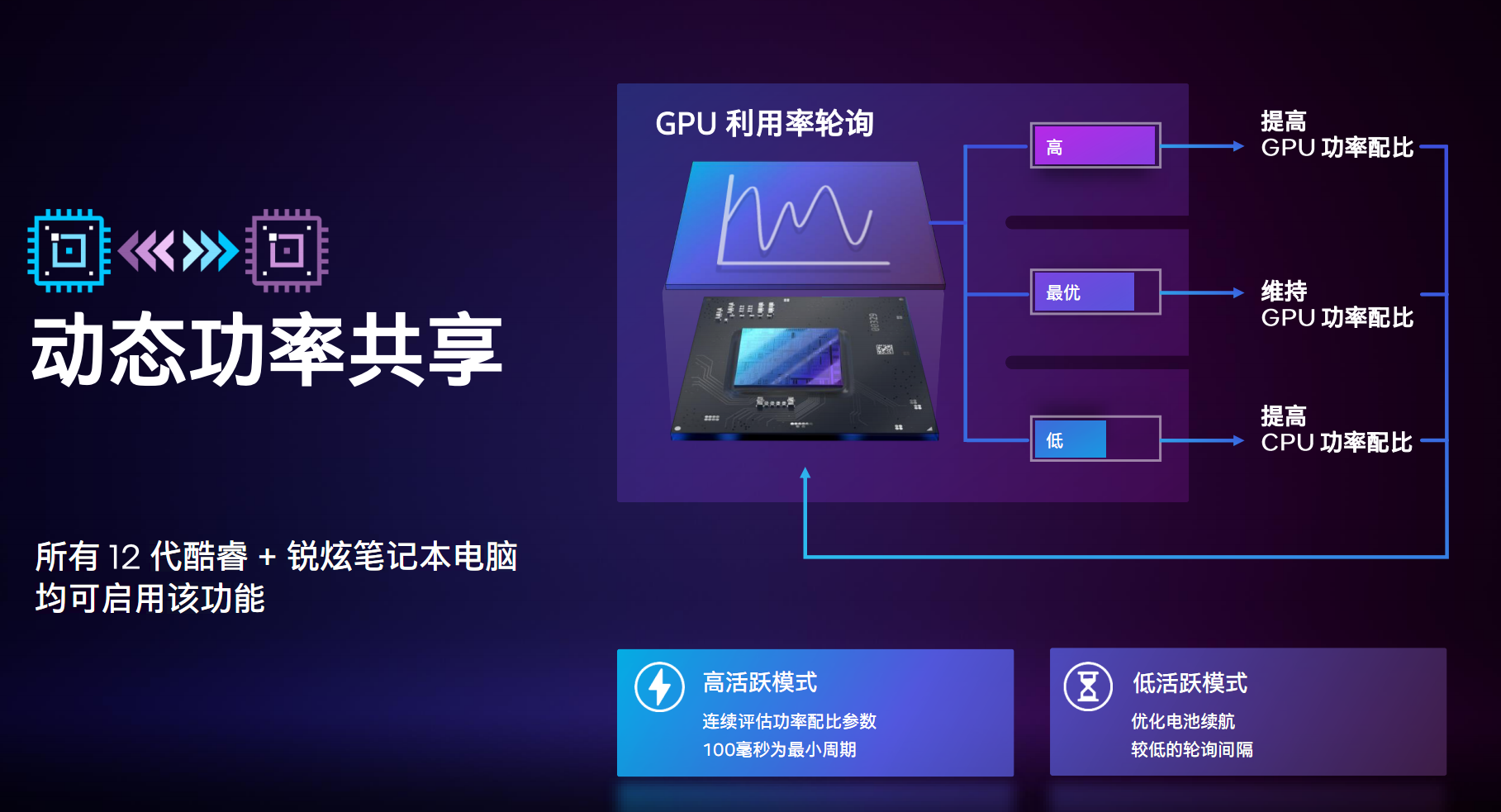
вЛЪЧЖЏЬЌЙІТЪЙВЯэЃЌжЇГж12ДњПсюЃЦНЬЈЃЌдРэКмМђЕЅЃЌОЭЪЧИљОнВЛЭЌЕФИКдиЃЌЖЏЬЌЕїНкCPUЁЂGPUЕФЙІКФХфБШЃЌЭцгЮЯЗОЭЖрИјGPUЁЃ
AMDЦНЬЈгаЯрЭЌЕФММЪѕSmartShiftЃЌNVIDIAвВгаРрЫЦЕФЃЌЕЋздМКУЛгаCPUДІРэЦїЃЌаЇЙћздШЛДѓДђелПлЁЃ
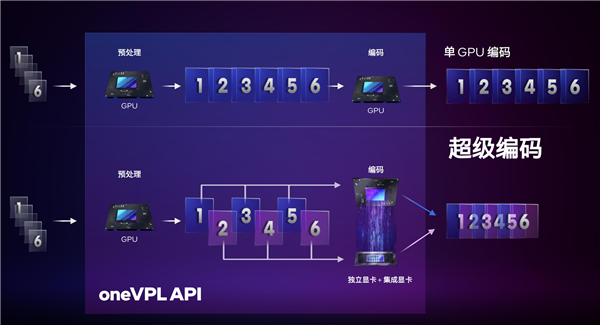
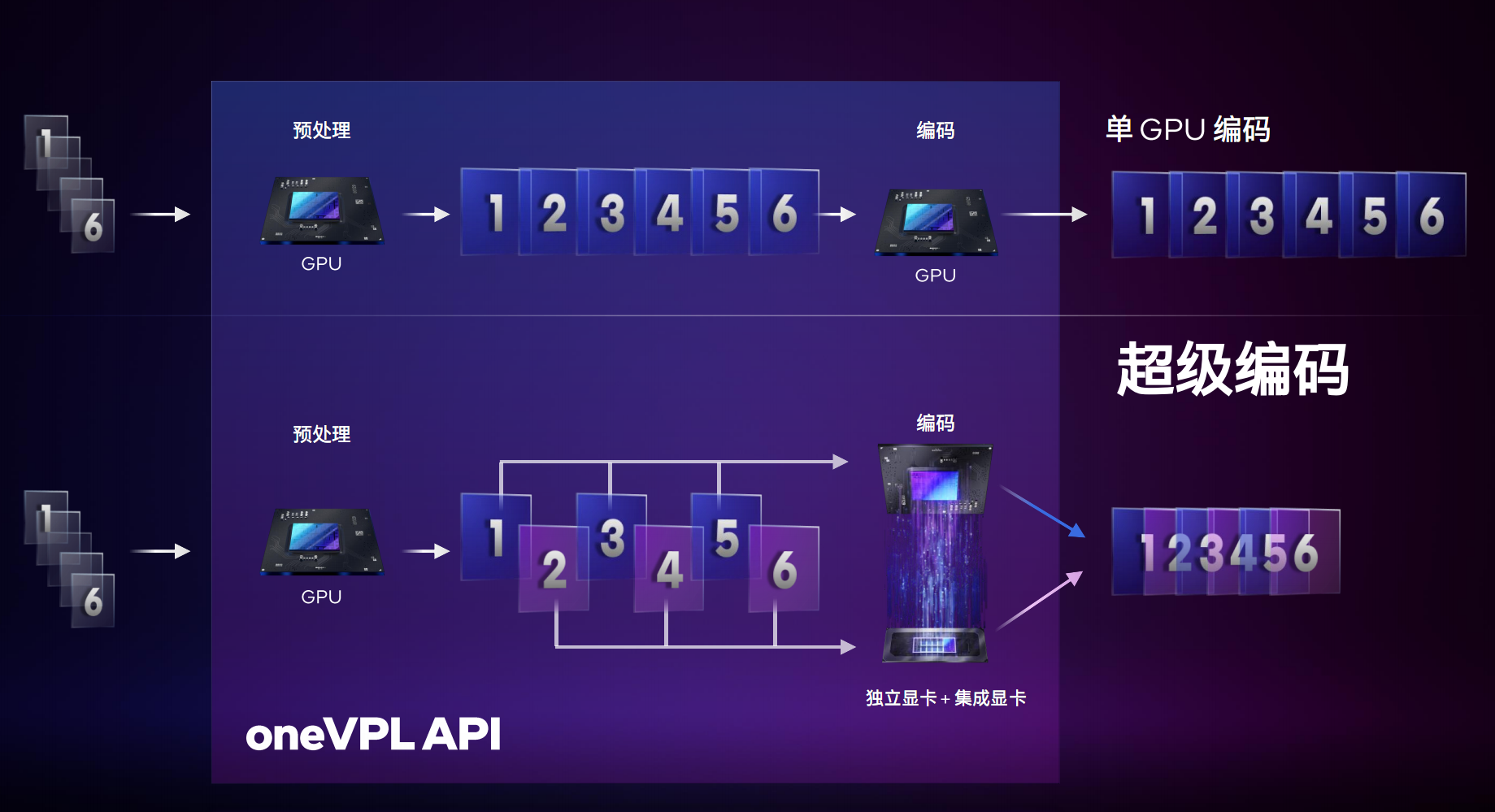
ЖўЪЧГЌМЖБрТыЃЌЭЈЙ§oneVPL APIЃЌПЩвдШУЖРСЂЯдПЈЁЂКЫаОЯдПЈЙВЭЌНјааЪгЦЕБрТыЃЌДІРэВЛЭЌЕФжЁЛУцЃЌдйКЯГЩЁЃ
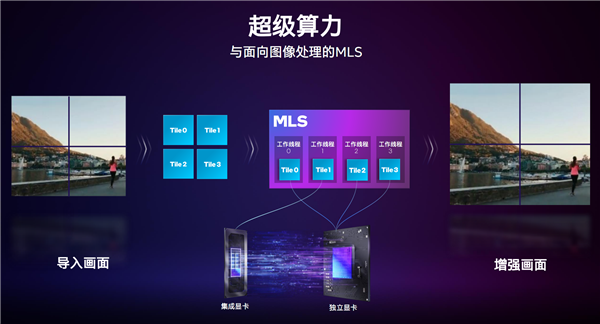
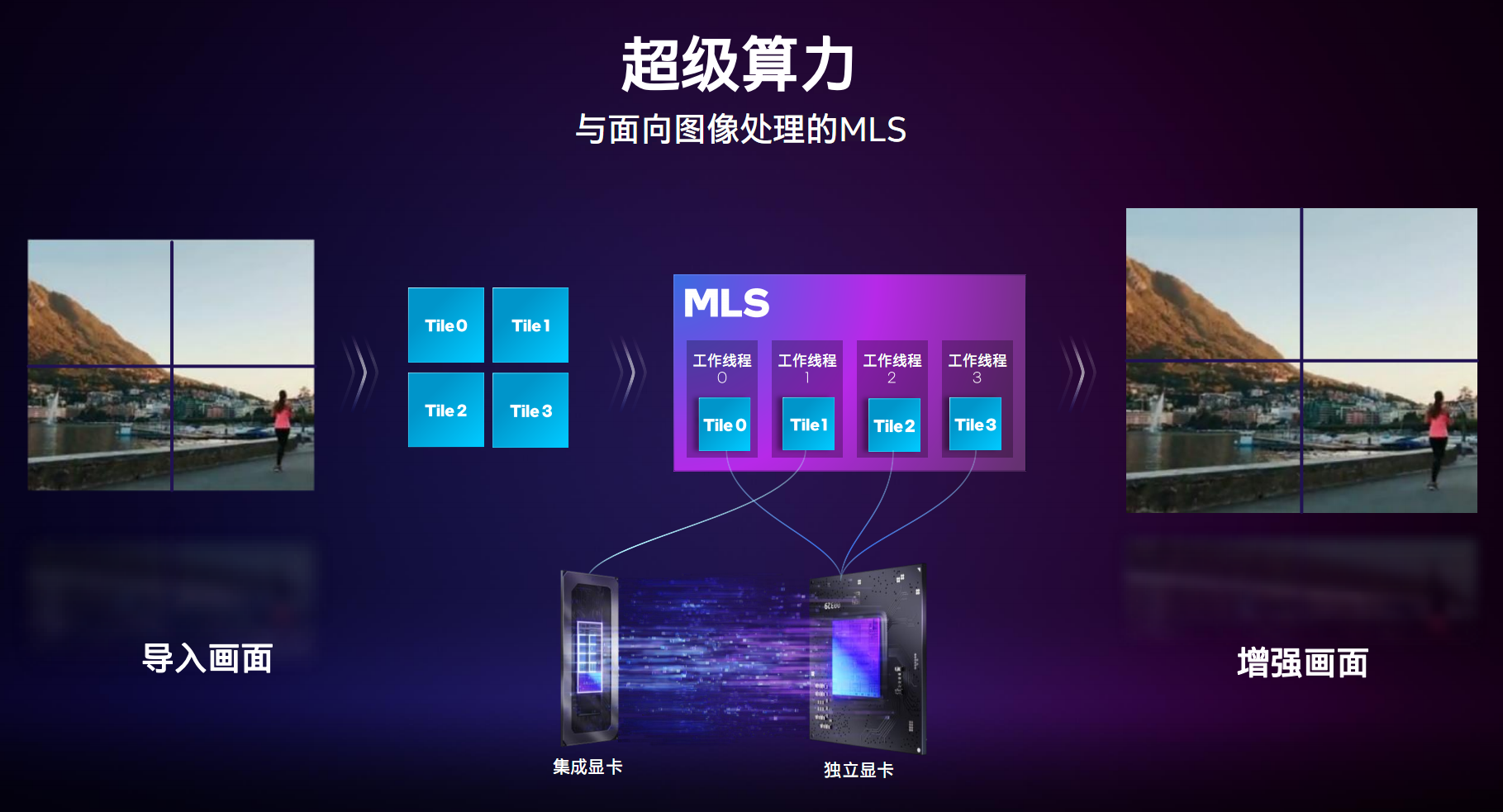
Ш§ЪЧГЌМЖЫуСІЃЌСЊКЯЛљгкЛњЦїбЇЯАЕФMLSПђМмЃЌНсКЯXMXв§ЧцМгЫйЃЌПЩвджЧФмЕиНЋМЦЫуИКдиЗжХфИјЖРСЂЯдПЈЁЂКЫаОЯдПЈИїздЕФМЦЫув§ЧцЃЌБШШчДІРэЪгЦЕЕФЪБКђЃЌНЋЛУцЗжГЩВЛЭЌЧјПщЃЌНЛИјСНжжЯдПЈЃЌДІРэЭъБЯКѓдйКЯГЩЪфГіЁЃ

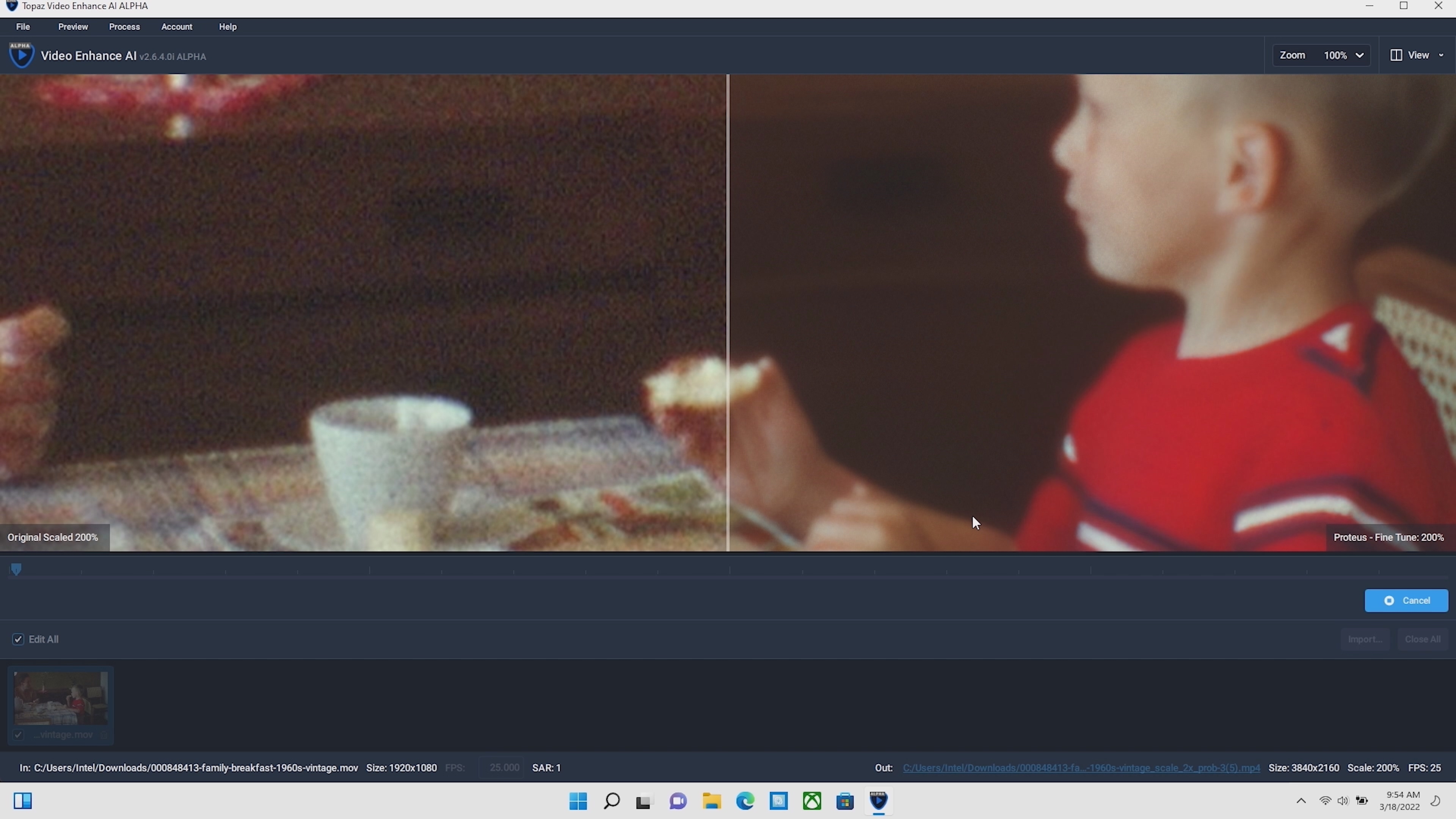
IntelаћГЦЃЌдкФкШнДДзїЩЯЃЌЖЏЬЌЙІТЪЙВЯэЁЂГЌМЖБрТыЁЂГЌМЖЫуСІПЩвдЗжБ№ДјРДзюЖр30ЃЅЁЂ60ЃЅЁЂ24ЃЅЕФадФмЬсЩ§ЁЃ
IntelвВеЙЪОСЫГЌМЖЫуСІЕФгІгУЪЕР§ЃЌНЋЕЭЛжЪЕФЪгЦЕAIДІРэЫѕЗХЕНИпЗжБцТЪЛжЪЁЃ
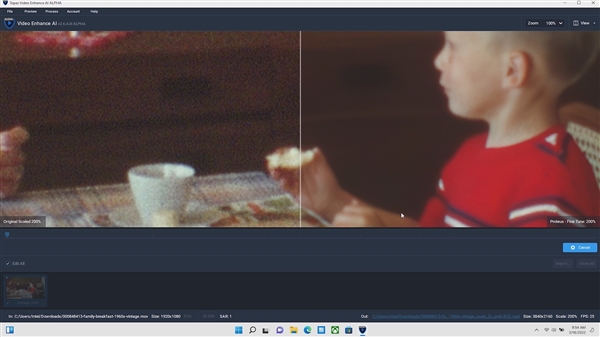
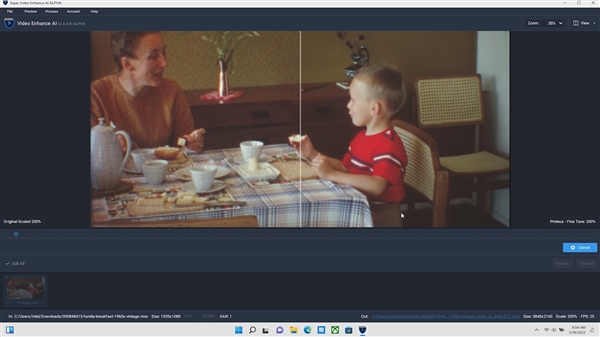





ЁОЧ§ЖЏУцАхЃКЛРШЛвЛаТ МрПигХЛЏЖМдкааЁП

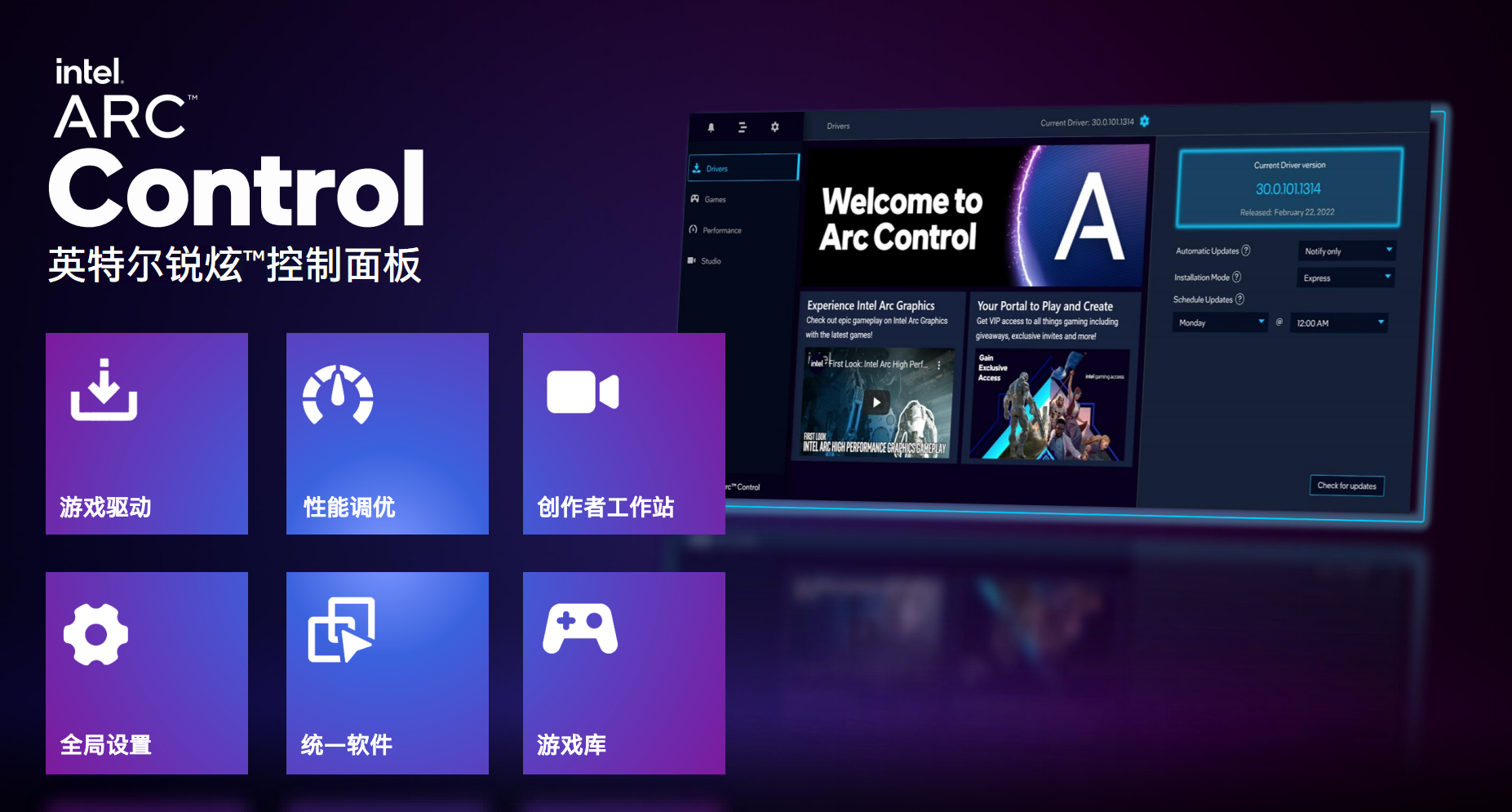
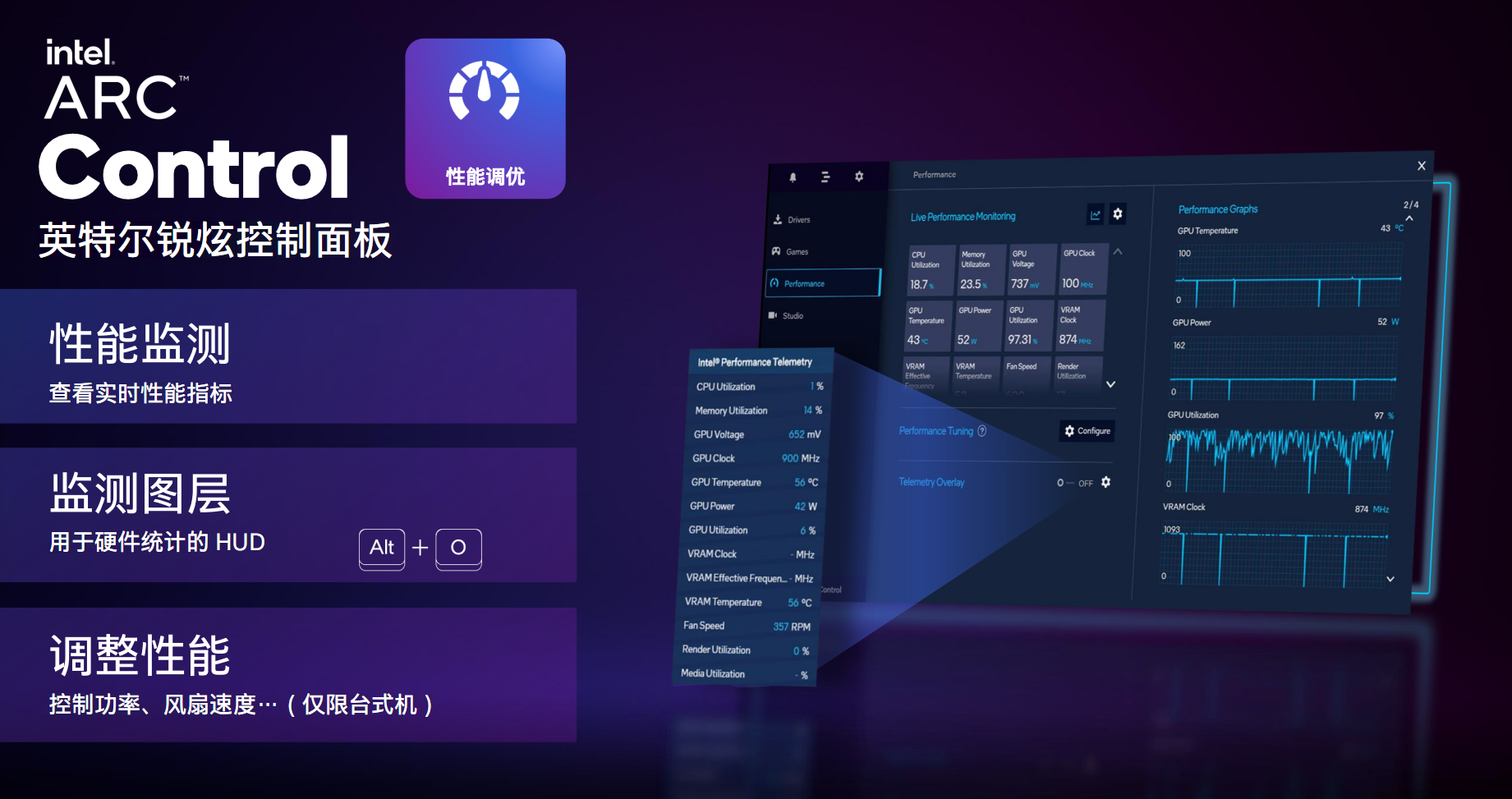
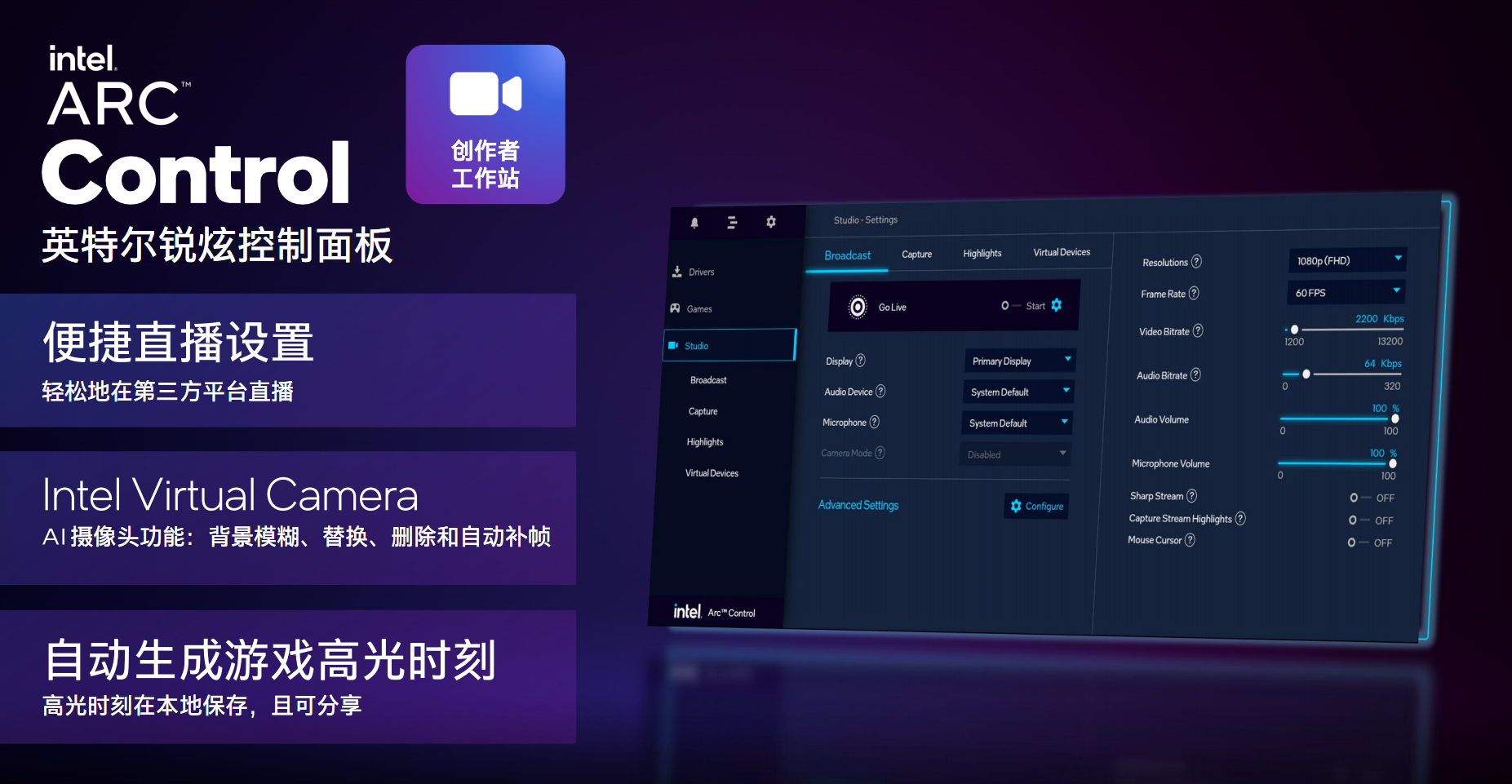
гВМўгаСЫЃЌЧ§ЖЏздШЛвВвЊИњЩЯЃЌArcЯдПЈНЋДюХфШЋаТЕФ“Arc Control”Ч§ЖЏПижЦУцАхЃЌЙІФмИќМгЗсИЛЃЌАќРЈгЮЯЗЧ§ЖЏЁЂадФмЕїгХЁЂШЋОжЩшжУЁЂгЮЯЗПтЁЂДДзїепЙЄзїеОЕШФЃПщЁЃ
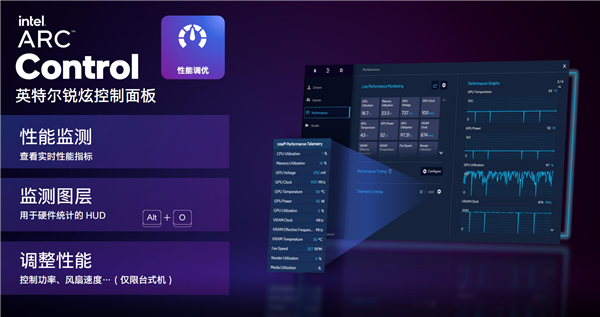
адФмЕїгХВПЗжЃЌПЩвдЪЕЪБМрВтВщПДИїжжгВМўжИБъЃЌЦЕТЪЁЂЕчбЙЁЂеМгУТЪЁЂЮТЖШЁЂЗчЩШзЊЫйЕШЕШЃЌЛЙПЩвдЩшжУМрВтЭПВуЃЌЫцЪБИВИЧВщПДЁЃ
ЮДРДЕФзРУцВњЦЗЃЌЛЙЛсжЇГжЕїНкЙІКФЁЂЗчЩШзЊЫйЕШЃЌВЛжЊЕРЪЧЗёЛсМгШыГЌЦЕ……
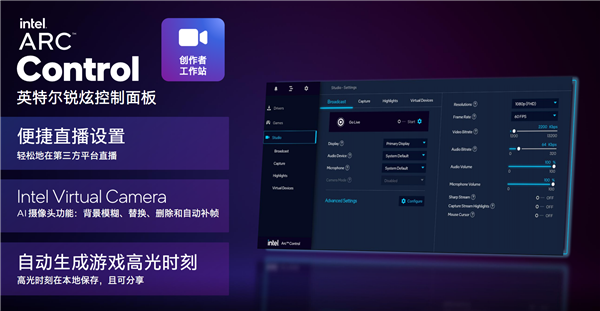
ДДзїепЙЄзїеОВПЗжЃЌПЩвдЗНБуЕиНјаажБВЅЁЂAIЩуЯёЭЗЧПЛЏ(БГОАФЃК§/БГОАЬцЛЛ/ЩОГ§КЭздЖЏВЙжЁЕШ)ЁЂздЖЏЩњГЩгЮЯЗИпЙтЪБПЬЁЃ
ЕШСЫетУДОУЃЌIntelИпадФмЖРСЂЯдПЈжегкРДСЫЃЌФузМБИКУСЫТ№ЃП




|












































































































![[MD:Title]](/img/20220330/3854280e20de4fc3b49a932b70afd0b9.jpg)
![[MD:Title]](/img/20220330/afe3033d93e34aad8590de60e59f7d51.jpg)
![[MD:Title]](/img/20220330/56cd59d9f3fb4a62a1497f581b4ab7d8.jpg)