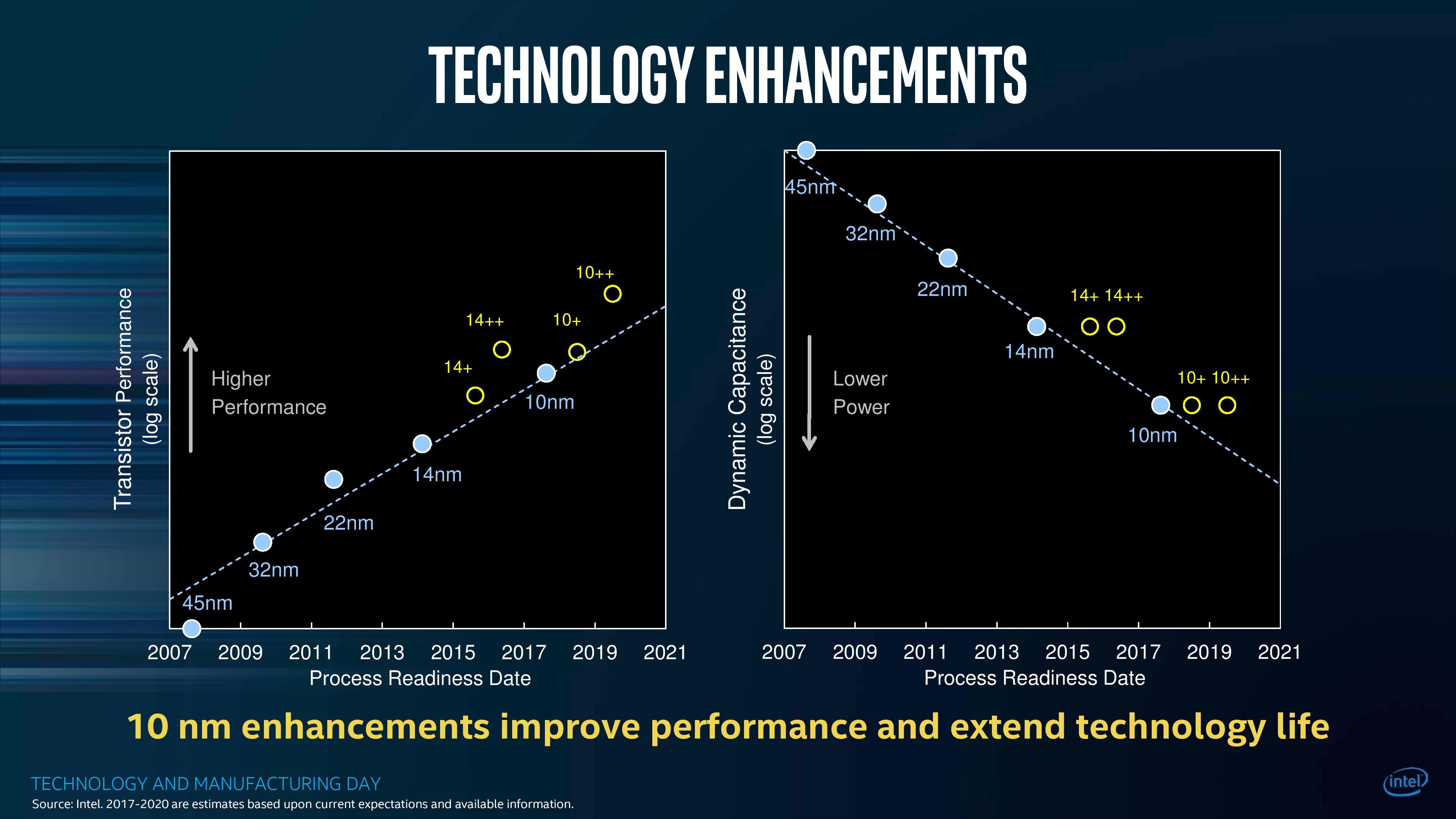
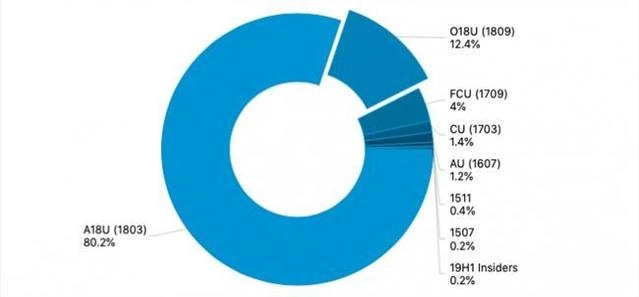
ЖдЧАбиАыЕМЬхИааЫШЄЕФШЫЖМжЊЕРЃЌIntelзюаТЕФжЦдьЙЄвевбОЬјЦБаэОУСЫЁЃ10nmЙЄвеЪзДЮЗЂВМЪЧдк2014ФъЃЌзюГѕЖЈгк2016ФъСПВњЃЌЕЋШДвЛжБбгЦкжСНёЁЃЫфШЛЪзХњЪЙгУ10nmЙЄвеЕФвЦЖЏДІРэЦїдк2017ФъЕзГіЛѕЃЌШДЪЧвд“ЬиЙЉ”БЪМЧБОЕчФдЕФаЮЪНгыЙњФквЛаЉДѓбЇКЯзїЭЦГіЁЃ
IntelЕФ10nmДІРэЦїЪєгкЕк8ДњПсюЃЯЕСаЃЌаЭКХЪЧi3 8121UЁЃИУДІРэЦїЕФARKвГУцЃЈIntelЕФдкЯпЪ§ОнПтЃЉвбОЙЋПЊЃЌЦфКЫаФДњКХЮЊCannon LakeЃЌЪєгк14nm SkylakeКЫаФЕФИФСМАцЃЌгк2018ФъЕкЖўМОЖШе§ЪНЗЂВМЁЃ

i3 8121UЕФTDPЮЊ15WЃЌЫЋКЫЫФЯпГЬЩшМЦЃЌЛљДЁЦЕТЪ2.2GHzЃЌюЃЦЕЦЕТЪ3.2GHzЁЃетБШЭЌЮЊ15WЕФ14nm Kaby LakeДІРэЦїЩѕжСЛЙвЊИќЕЭвЛаЉЁЃзюЮЊаТЦцЕФЪЧЃЌЫфШЛетЪЧвЛПХвЦЖЏДІРэЦїЃЌШДжЇГжЗўЮёЦїКЭИпЖЫзРУцЦНЬЈДІРэЦїВХгаЕФAVX-512жИСюМЏЃЌПЩвдЯёЦѓвЕМЖгВМўвЛбљДІРэЯђСПдЫЫуЁЃ
i3 8121UЕФЦЕТЪВЛНјЗДЭЫЃЌШУШЫУЧЖдIntel 10nmЙЄвеЕФЪЕМЪадФмБэЯжВњЩњСЫЫПЫПвЩТЧЁЃРзЗцЭјДгЭтУНSemiAccurateЕФвЛЦЊбаОПЮФеТжаЛёЯЄЃЌФПЧАЃЈжИi3 8121UЭЦГіЪБЃЉIntelЕФ10nmЙЄвеЛЙДцдкКмЖрЮЪЬтКЭРЇФбЃЌЦфЪевцжЛга10%ЃЌдЖЕЭгкдЄМЦжаЕФ60%ЃЌЦфжаSAQPЁЂCOAGЁЂCobaltКЭЕїгХЕШЛЗНкдЖдЖТфКѓгкМЦЛЎКЭдЄЦкЁЃ
ЦфКѓЕФМИИідТЃЌЗЛМфДЋЮХIntel 10nmЙЄвебЯжиЪмзшЃЌЩѕжСНЋвЊЗХЦњ10nmЕФбаЗЂЙЄзїЃЌвВгаДЋЮХГЦIntelНЋНЕЕЭБъзМвдЪЕЯжетвЛжЦГЬЃЌЕЋЖМБЛIntelвЛвЛБйвЅЁЃКУдкНёФъЕФCESЩЯЃЌIntelеЙЪОСЫ10nmЙЄвеЕФШЋаТSunny CoveМмЙЙIce LakeДІРэЦїЃЌЫуЪЧШУЙизЂаТжЦГЬЕФШЫУЧГдСЫвЛПХЖЈаФЭшЁЃ
ДгВтЪдНсЙћРДПДЃЌСНПюВЛЭЌКЫаФЕФДІРэЦїадФмЯрВюЮоМИЃЌKaby LakeКЫаФЕФi3 8130UдкгыSIMDЯрЙиЕФ462.libquantumКЭ470.lbmВтЪдЯюжаЫЦКѕБШCannon LakeКЫаФЕФi3 8121UИќгагХЪЦЃЌетвВаэгыЖўепФкДцбгГйадФмгаЙиЁЃ
10nmЙЄвеФбдкФФЃП
2017Фъ9дТЃЌIntelдкММЪѕгыжЦдьШеЩЯеЙЪОСЫвЛИі10nm Cannon LakeаОЦЌЕФЭъећ300mmОЇдВЃЌЭтУНTechinsightsВтЕУИУаОЦЌЕФаОЦЌУцЛ§дМЮЊ70.5mm?ЃЌвВОЭЪЧЫЕЃЌi3 8121UЪЧIntelЦљНёЮЊжЙзюаЁЕФЫЋКЫДІРэЦїЃЌЕЋгыЕБЪБЕФSkylakeДІРэЦїЃЈСљДњПсюЃЃЉЯрБШЃЌi3 8121UВЩгУСЫCPUКЭGPUЗжРыЕФЩшМЦЃЌМЏГЩЖШИќЕЭЁЃ

вЕФкКтСПАыЕМЬхЙЄвеКУЛЕЕФГЃгУБъзМжЎвЛЃЌЪЧаОЦЌжаУПЦНЗНКСУзМЏГЩЖШОЇЬхЙмЪ§СПгаЙиЁЃCPUжаВЂВЛЖМЪЧдЫЫуОЇЬхЙмЃЌЛЙгаSRAMЕЅдЊЃЌвдМАвЛаЉБЛЩшМЦГЩЧјгђМфШШЛКГхЧјЕФ“ЫР”ЙшЁЃОЇЬхЙмЕФМЦЪ§вВгаВЛЭЌЕФЗНЗЈЃЌвЛИі2ЪфШыЕФNANDТпМЕЅдЊБШвЛИіИДдгЕФЩЈУшДЅЗЂЦїТпМЕЅдЊвЊаЁЕУЖрЁЃ
IntelНЋЕЅЮЛУцЛ§ЩЯЕФОЇЬхЙмЪ§СПЛЎЗжЮЊ2ЪфШыNANDЕЅдЊКЭЩЈУшДЅЗЂЦїЕЅдЊЃЌЦфжа2ЪфШыNANDЕЅдЊЕФОЇЬхЙмУмЖШЪЧ90.78MTr/mm?ЃЈАйЭђОЇЬхЙмУПЦНЗНКСУзЃЉЃЌЩЈУшДЅЗЂЦїЕЅдЊЕФУмЖШЮЊ115.74 MTr/mm?ЃЌдкЮЊЦфИГгш60/40ЕФШЈжиКѓМЦЫуГі10nmЙЄвеЕФОЇЬхЙмУмЖШЮЊ100.8MTr/mm?ЃЌЪЧ14nmЙЄве37.5MTr/mm?ЕФ2.7БЖЁЃ
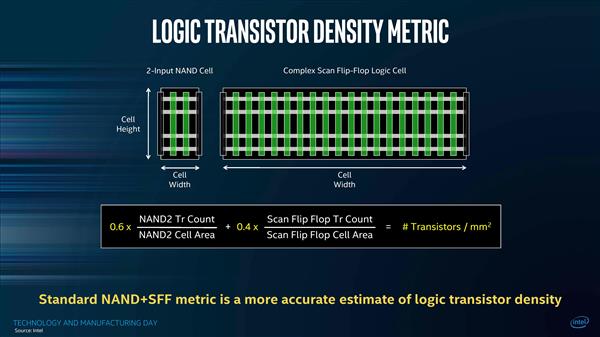
IntelЛЙдкЙњМЪЕчзгЦїМўЛсвщЩЯХћТЖЃЌОпЬхШЁОігкЫљашЕФЙІФмЃЌ10nmЙЄвеЕФТпМПтга10жжРраЭЃЌАќРЈЖЬПтЃЈИпУмЖШПтЃЉЃЌжаИпПтЃЈИпадФмПтЃЉКЭИпПтЃЈГЌИпадФмПтЃЉЕШЁЃПтдНЖЬЃЌЕчТЗЙІКФдНЕЭЃЌОЇЬхЙмУмЖШдНИпЃЌЕЋЗхжЕадФмвВдНЕЭЁЃвђДЫIntelЕФ10nmЙЄвеЦфЪЕгаЖржжВЛЭЌЕФУмЖШЃЌЪЕМЪЩЯжЛгаУмЖШзюИпЕФЖЬПтПЩвдДяЕН100.8MTr/mm?ЁЃ
дкЪЕМЪаОЦЌжЦдьжаЃЌЭЈГЃЛсЛьКЯЪЙгУЖржжПтЃЌНЯЖЬЕФПтЪЪгУгкI/OКЭЗЧКЫаФЧјЕШЖдадФмВЛУєИаЕФВПЮЛвдНкдМГЩБОЃЌНЯИпЕФПтЭЈЙ§НЯЕЭЕФУмЖШКЭНЯИпЕФЧ§ЖЏЕчСїЃЌЭЈГЃЪЙгУдкЖдадФмУєИаЕФКЫаФЧјгђЁЃ
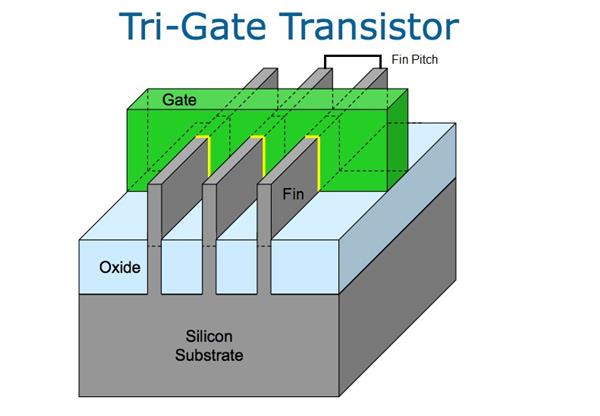
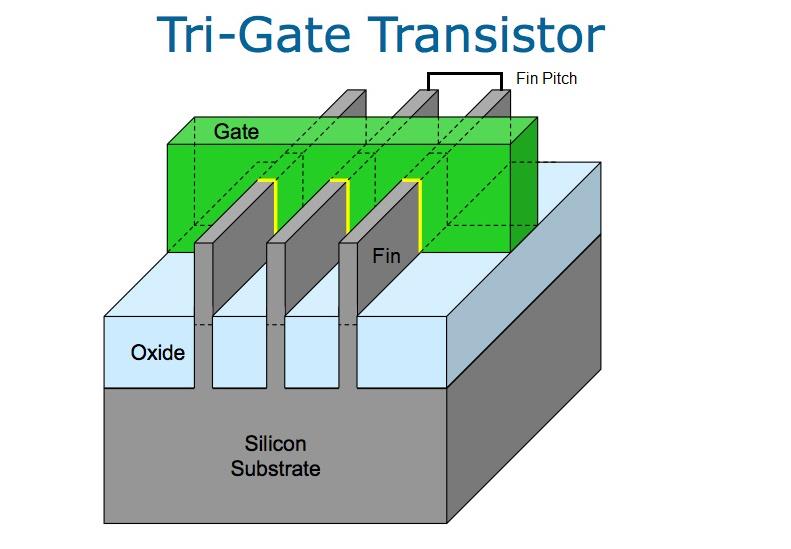
ЮЊСЫИќКУЕФРэНтIntel 10nmЙЄвеЃЌЪзЯШвЊЬжТлFinЃЈїЂЃЉЁЂGateЃЈеЄМЋЃЉЁЂЕЅдЊЛњжЦЃЌвдМАЖЈвхгыОЇЬхЙмКЭFinFETЯрЙиЕФвЛаЉЪѕгяЁЃ
ОЇЬхЙмЕФдДМЋ-ТЉМЋгЩїЂЃЈЛвЩЋЃЉЬсЙЉЃЌИУїЂДЉЙ§еЄМЋЃЈТЬЩЋЃЉВЂЧЖШыбѕЛЏЮяжаЃЌетРяЕФЙиМќжИБъЪЧїЂЕФИпЖШЁЂПэЖШКЭеЄГЄЃЌАыЕМЬхЙЄвеЕФФПБъЪЧЪЙУПвЛИіЖМОЁПЩФмаЁЁЂЕЅдЊадФмОЁПЩФмИпЁЃ
IntelдкЦф22nmЙЄвежаЃЌЪЙгУСЫАќКЌЖрИіїЂЦЌЕФШ§еЄМЋОЇЬхЙмРДдіМгзмЧ§ЖЏЕчСїЃЌвдЛёЕУИќКУЕФадФмЁЃетОЭв§ШыСЫвЛИіаТЕФЖШСПЃК“їЂМфОр”ЃЌМДїЂжЎМфЕФОрРыЁЃШчЙћвЛИіїЂЭЈЙ§СЫЖрИіеЄМЋЃЌеЄМЋжЎМфЕФОрРыГЦЮЊ“еЄМЋОр”ЁЃ
їЂКЭеЄМЋжЎМфНгДЅЕФдНЖрЃЌїЂМфОрдНаЁЃЌаЙТЉОЭдНЕЭЃЌадФмвВОЭдНКУЃЌетПЩвддіМгЧ§ЖЏЕчСїЃЌвВФмПижЦМФЩњЕчШнКЭеЄЕчШнЁЃЦфКѓЕФ14nmЙЄвежаЃЌїЂЕФИпЖШЁЂПэЖШКЭеЄГЄЖМБфЕУИќЖЬЃЌУПИіїЂДЉЙ§ЕФеЄМЋвВИќЖрЃЌвђЖјЛёЕУСЫИќКУЕФадФмЁЃ
ЖјЕНСЫ10nmЙЄвеЃЌIntelвВдкЛ§МЋЩшМЦїЂНсЙЙЃЌїЂМфОрДг42nmЫѕМѕЕН34nmЃЌїЂПэЖШДг8nmЫѕМѕжС7nmвдБмУтМФЩњЕчШнЁЃИФЖЏПДЦ№РДВЂВЛЖрЃЌЕЋдкетИіГпЖШЩЯУПnmЖМЗЧГЃживЊЁЃIntelЛЙЭЈЙ§ЬэМгЙВаЮюбВуРДИФЩЦдДМЋКЭТЉМЋРЉЩЂЧјгђЃЌїЂКЭЙЕВлжЎМфЕФНгДЅЧјгђЃЈеЄМЋЯТЗНЕФЛвЩЋМтЭЗЃЉвВашвЊШУНгДЅЕчзшзюаЁЛЏЁЃдк10nmЙЄвежаЃЌIntelНЋЦфДгЮйНгДЅИФЮЊюмНгДЅЃЌЪЙНгДЅЯпЕчзшНЕЕЭСЫ60ЃЅЃЌжжжжетаЉИФНјЃЌШУММЪѕБфЕУМЋЦфОпгаЬєеНадЁЃ

їЂгыеЄМЋзщКЯЦ№РДОЭЪЧЛљБОЕФЕчТЗЕЅдЊЃЌДг22nmжЦГЬЕФЩЈУшЕчзгЯдЮЂОЕЕФЭМЯёРДПДЃЌЕЅдЊга6ЦЌїЂЕФКЭ2ЦЌїЂЕФЃЈЕБШЛвВгаЦфЫћЙцИёЕФЃЉЃЌеЄМЋГЄЖШВЛОЁЯрЭЌЃЌУПИіЕЅдЊФкЖМгаЛюдОЕФїЂДЋЕнЕчСїКЭЗЧЛюдОЕФїЂзїЮЊМфИєЁЃ
дк10nmЙЄвеЩЯЃЌЪЙгУИпУмЖШПтЕФЕЅдЊзмЙВга8ИіїЂЃЌЦфжа5ИіЪЧЛюЖЏїЂЃЌетаЉЕЅдЊПЩгУгкI/OЕШВЛашвЊКмИпадФмЛђЖдГЩБОУєИаЕФЕчТЗВПЗжЁЃИпадФмПтКЭГЌИпадФмПтдђЗжБ№га10ИіКЭ12ИіїЂЃЌИїздЯрБШЧАепЖрГівЛИіЖюЭтЕФPїЂКЭNїЂЃЌгажњгкЬсЙЉЖюЭтЕФЧ§ЖЏЕчСїЃЌвдЪЪЕБЕФаЇТЪЮўЩќРДЛЛШЁЗхжЕадФмЕФЬсЩ§ЁЃ
дкЕЅдЊжЎМфЃЌЭЈГЃЛсгааэЖрзїЮЊМфИєЮяЕФЮБеЄМЋЁЃдкIntel 14nmЙЄвежаЃЌУПИіЕЅдЊЕФСНЖЫЖМгавЛИіЮБеЄМЋЃЌетвтЮЖзХСНИіЕЅдЊжЎМфЛсгаСНИіЮБеЄМЋЁЃЖјдк10nmЙЄвежаЃЌСНИіЯрСкЕФЕЅдЊПЩвдЙВЯэвЛИіЮБеЄМЋЃЌетНЋДјРДИќДѓЕФУмЖШгХЪЦЃЌIntelБэЪОзюЖрПЩНкдМ20%аОЦЌУцЛ§ЁЃ

ОЇЬхЙмФкВПЃЌеЄМЋЭЈГЃППСНжЇГЄЖШТдЮЂГЌГіЕЅдЊГпДчЕФДЅЕуИјдДМЋКЭТЉМЋМгЕчЃЌетВЛПЩБмУтЕФвЊеМОнЖюЭтЕФЦНУцГпДчЁЃдк10nmЙЄвежаЃЌжСЩйдкФПЧАCannon LakeДІРэЦїЪЙгУЕФАцБОжаЃЌIntelЭЈЙ§вЛжжБЛГЦЮЊ“гадДеЄМЋНгДЅ”ЃЈCOAGЃЉЕФЩшМЦЃЌНЋеЄМЋДЅЕуДЙжБЗХжУдкЕЅдЊЩЯЁЃетвЛЩшМЦЮЊжЦдьЙ§ГЬдіМгСЫКУМИИіВНжшЃЈвЛДЮЪДПЬЁЂвЛДЮГСЛ§КЭвЛДЮХзЙтЃЉЃЌЕЋПЩвдЮЊаОЦЌЬсЙЉДѓдМ10ЃЅЕФУцЛ§ЫѕЗХЁЃ
ЧАЮФвбОбдЕРЃЌЭтУНSemiAccurateЩЯЕФвЛЦЊбаОПЮФеТдјБэЪОЃЌCOAGЪЧвЛжжЗчЯеНЯИпЕФЪЕЪЉЗНАИЃЌЫфШЛIntelвбОАбЫќдьГіРДВЂЧве§ГЃЙЄзїСЫЃЌЕЋЫќВЂВЛЯёдЄЦкЕФФЧбљПЩППЁЃгУгкCannon LakeКЫаФЕФCOAGЫЦКѕжЛФмдЫаадкЕЭадФм&ЕЭЙІТЪЃЌЛђИпадФм&ИпЙІТЪЕФЙЄПіЯТЃЌЯЃЭћЮДРДIntelФмдкаТвЛДњ10nm Ice LakeДІРэЦїе§ЪНЗЂЪлЪБЯъЯИЫЕУїЙигкCOAGЕФИФНјЧщПіЁЃ
ЛиЕНОЇЬхЙмУмЖШЩЯЃЌКтСПОЇЬхЙмУмЖШЕФСэвЛжжЗНЗЈЪЧCPP*MMPЃЌМДНЋеЄМфОрЃЈНгДЅЖрОЇЙшМфОрContact Poly PitchЃЉГЫвдїЂМфОрЃЈзюаЁН№ЪєМфОрЃЉЁЃжжжжетаЉИФНјМгдквЛЦ№ЃЌЪЙIntelЕФCPP*MMPГпДчжЛга54nm*44nmЃЌЯрБШЬЈЛ§ЕчКЭШ§аЧЕФ7nmвВжЛЪЧТдЪфвЛЕуЕуЃЌетвВЪЧIntelвЛжБЧПЕїЧАСНепжЛЪЧЩЬвЕУќУћЕФдвђЁЃ
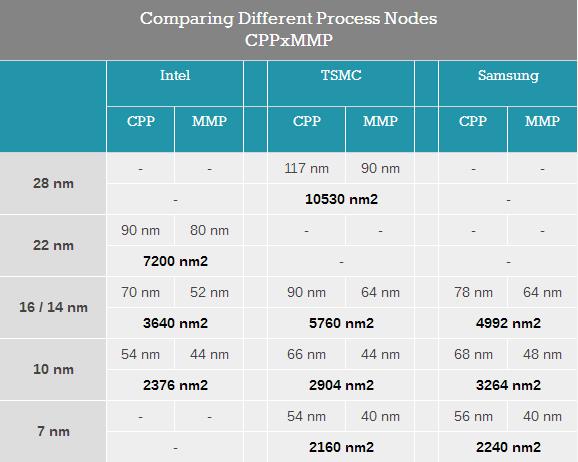
НвПЊМмЙЙжЎУи
ЫфШЛi3 8121UЕФCannon LakeКЫаФШдДІгкNDAжаЃЌЕЋОЙ§ПЦММШІжкЖрЭЌШЪвЛФъвдРДзЮзЮВЛОыЕФбаОПЃЌжегкЛЙЪЧЛљБОНвПЊСЫЦфМмЙЙЕФУцЩДЁЃ
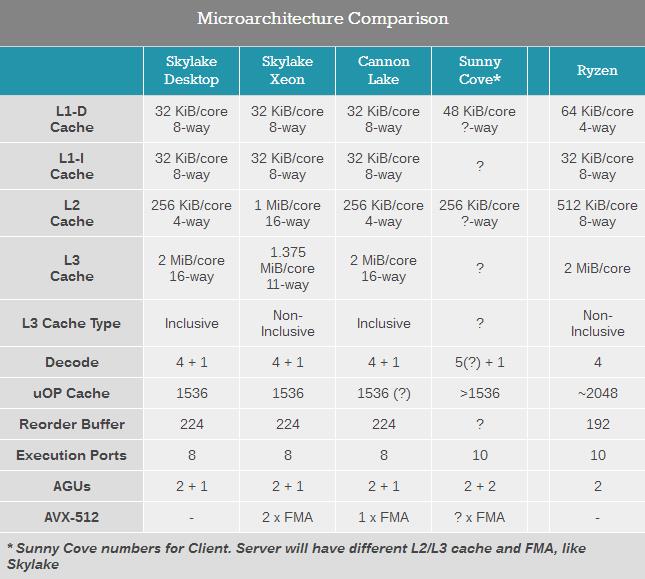
ећЬхЖјбдЃЌCannon LakeКЫаФЕФЩшМЦКмЯёЪЧPCЖЫSkylakeКЫаФгыЗўЮёЦїЖЫSkylake-SPКЫаФЕФЛьКЯЬхЁЃЫфШЛЫќЪЙгУСЫPCЖЫБъзМЕФ4+1НтТыЕЅдЊЁЂ8ИіжДааЕЅдЊвдМАL1+L2+L3ЛКДцНсЙЙЃЌЕЋвВДгЗўЮёЦїЖЫв§ШыСЫвЛИіAVX-512ЕЅдЊЃЌВЂЧвL1Ъ§ОнЛКДцЕФЖСаДЫйЖШЗжБ№ДяЕНСЫУПжмЦк2*512ByteКЭ1*512ByteЁЃ
НјвЛВНРДПДЃЌCannon LakeКЫаФвВЬхЯжСЫвЛаЁВПЗжЕкЖўДњ10nm Sunny CoveМмЙЙЕФЩшМЦЃЌвЛаЉSkylakeКЭSkylake-SPКЫаФЩЯУЛгаЕФжИСюЃЌдкCannon LakeКЭSunny CoveЩЯЖМгаДцдкЁЃ
Г§ДЫжЎЭтЃЌЫфШЛФПЧАВЛЬЋЧхГўCannon LakeКЫаФЕФМмЙЙЧАЖЫЩшМЦБфЛЏЃЌЕЋЛЙЪЧПЩвдПДГіжиХХађЛКГхЧјЕФДѓаЁЪЧгыSkylakeКЫаФЯрЭЌЕФ224ЬѕЮЂжИСюЃЌЖјSunny CoveМмЙЙЕФДѓВПЗжЬиадИФНјЃЈДцДЂДјПэМгБЖЁЂжДааЖЫПкИќЖрвдМАжДааЖЫПкЙІФмИФНјЃЉЖМУЛгаГіЯждкCannon LakeКЫаФЩЯЁЃ
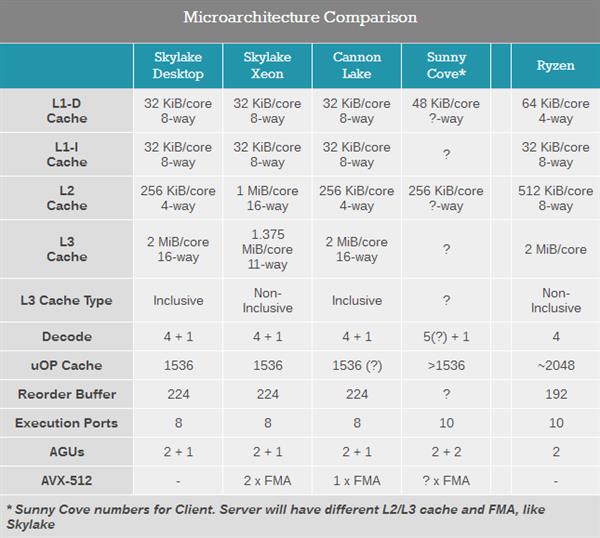
Cannon LakeжЇГжЕФаТжИСюАќРЈIFMAЃЈInteger fusion Multiply AddЃЌећЪ§ШкКЯГЫМгЗЈЃЉЁЂVBMIЃЈVector Byte operation instructionsЃЌЪИСПзжНкВйзїжИСюЃЉЃЌвдМАЛљгкгВМўЕФSHAЃЈSecure Hash AlgorithmЃЌАВШЋЙўЯЃЫуЗЈЃЉЕШЁЃ
ЦфжаЃЌIFMAЪЧ52ЮЛећЪ§ШкКЯГЫЗЈМгЗЈЃЈFMAЃЉЃЌЦфааЮЊгыAVX512ИЁЕуFMAЯрЭЌЃЌбгГйЮЊ4ИіЪБжгжмЦкЃЌУПИіЪБжгжмЦкЕФЭЬЭТСПЮЊ2ЃЈЖдгкxmm/ymm/zmmЮЊ4КЭ1ЃЉЁЃИУжИСюЭЈГЃБЛгУгкИЈжњМгУмЙІФмЃЌЕЋвВвтЮЖзХПЩвджДааШЮвтОЋЖШЕФЫуЪѕдЫЫуЁЃ
VBMIжИСюМЏЬсЙЉСЫVPERMBЁЂVPERMI2BЁЂVPERMT2BКЭVPMULTISHIFTQBЫФЬѕжИСюЃЌдкзжНкЛьЯДЗНАИжаЗЧГЃгагУЁЃ
ЖјгВМўМгЫйSHAдђДПДтЪЧЮЊМгУмЫуЗЈМгЫйЖјЩшМЦЕФЃЌВЛЙ§ВтЪдБэУїЃЌCannon LakeКЫаФгаСЫЫќКѓЫйЖШШдШЛБШGoldmontЃЈЯТДњAtomДІРэЦїЕФКЫаФЃЉКЭAMDЕФZenЖМТ§ЃЌетвтЮЖзХЦ№ТыЛљгкгВМўЕФSHAдкi3 8121UЩЯВЂВЛЪЧЬиБ№гагУЁЃ
Г§СЫдіМгаТжИСюЃЌIntelЭЈГЃЛЙЛсдкаТКЫаФЩЯИФНјЯжгаЕФжИСюЃЌгУгкдіМгЭЬЭТСПЛђМѕЩйбгГйЃЈЛђСНепМцЖјгажЎЃЉЁЃCannon LakeКЫаФЛЙжЇГжVector-AESЬиадЃЌЫќдЪаэAESжИСювЛДЮЪЙгУИќЖрЕФAVX-512ЕЅдЊДгЖјЪЙЭЬЭТСПБЖдіЁЃ
дкCannon LakeКЫаФЩЯЃЌзюДѓЕФБфЛЏЪЧПЩвдгВМўжЇГж64ЮЛећЪ§Г§ЗЈЃЌВЛдйашвЊЗжИюГЩМИЬѕжИСюЃЌ18ИіЪБжгжмЦкФкОЭПЩвдЭъГЩ64bitЕФIDIVЁЃЯрБШжЎЯТЃЌZenжДааЭЌбљЕФдЫЫуашвЊ45ИіЪБжгжмЦкЃЌSkylakeКЫаФдђашвЊ97ЪБжгжмЦкЁЃ
ЖдгкзжЗћДЎЕФПщДцДЂЃЌЫљгаREP STOS*ЯЕСажИСюЖМПЩвдЪЙгУ512bitжДаааДШыЖЫПкЃЌЭЬЭТСПЮЊУПЪБжгжмЦк61bitЃЌЯрБШжЎЯТЃЌSkylake-SPЮЊ43bitЃЌSkylakeЮЊ31bitЃЌZenЮЊ14bitЁЃ
ЖдгкШЋзжећЪ§ЪИСПЃЌAVX512BWУќСюVPERMWЕФЕШД§ЪБМфДг6ИіЪБжгжмЦкМѕаЁЕН4ИіЃЌВЂЧвУПИіЪБжгЕФЭЬЭТСПдіМгвЛБЖЁЃгыЯђСПРрЫЦЃЌЪЙгУVMOVSSКЭVMOVSDУќСювЦЖЏЛђКЯВЂЕЅ/ЫЋОЋЖШБъСПЕФЯђСПЯждкгыЦфЫћMOVУќСюЕФааЮЊЯрЭЌЁЃ
ЖджИСюМЏЕФЦфЫћгавцЕїећАќРЈЪЙZMMЛЎЗжКЭЦНЗНИљИќПьвЛИіЪБжгЃЌВЂНЋвЛаЉGATHERКЏЪ§ЕФЭЬЭТСПДгУПЫФИіЪБжгвЛИідіМгЕНУПШ§ИіЪБжгвЛИіЃЛЛиЙщдђвдОЩx87жИСюЕФаЮЪНГіЯжЃЌЦфжаx87 DIVЁЂSQRTЁЂREP CMPSЁЂLFENCEКЭMFENCEЖМБфТ§вЛСЫИіЪБжгЃЌЦфЫћжИСюдђТ§ЕФИќЖрЃЌФПЕФЪЧШУШЫУЧЦњгУетаЉРЯОЩЕФжИСюЁЃ
Cannon LakeКЫаФЯрЖдВЛзуЕФЕиЗНАќРЈЃКVPCONFLICT*УќСюОпга3ИіЪБжгжмЦкЕФбгГйЃЌЭЬЭТСПЮЊУПЪБжгжмЦквЛЬѕЃЌЫйЖШШдШЛКмТ§ЃЛDWORD ZMMБэЕЅЕФбгГйЮЊ26ИіЪБжгЃЌЭЬЭТСПЮЊУП20ИіЪБжг1ИіЃЛВЛжЇГжSkylake-SPКЫаФЕФЛКДцаааДЛиЙІФмCLWBЃЛВЛжЇГжSGXЃЈШэМўБЃЛЄРЉеЙЃЉЁЃ
ДІРэЦїЙцИёЖдБШ
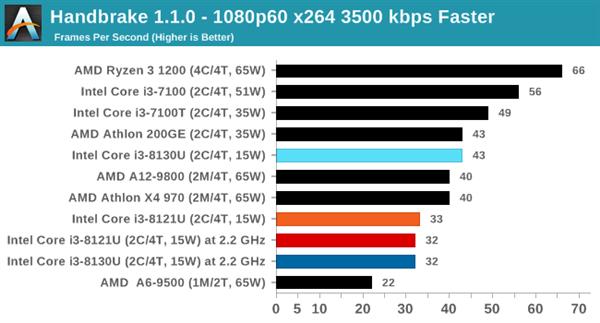
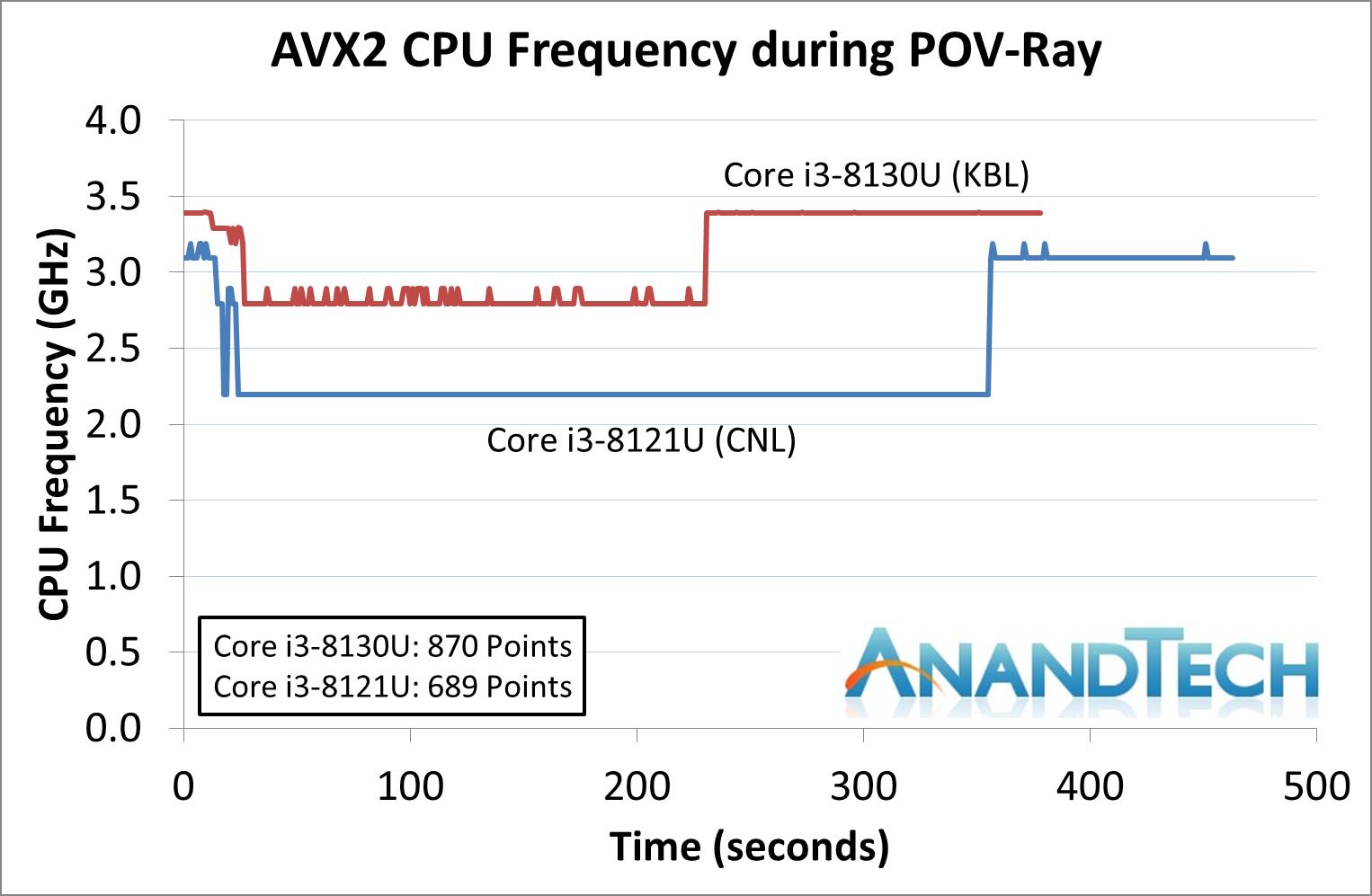
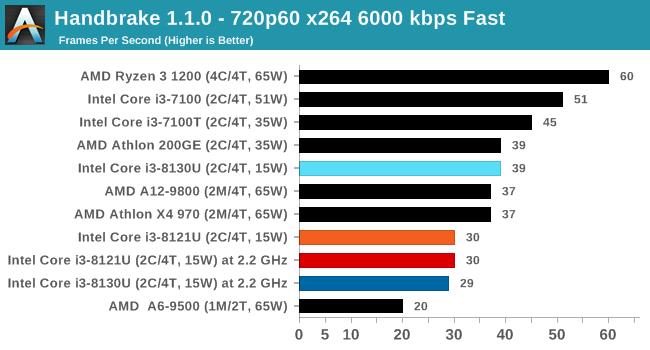
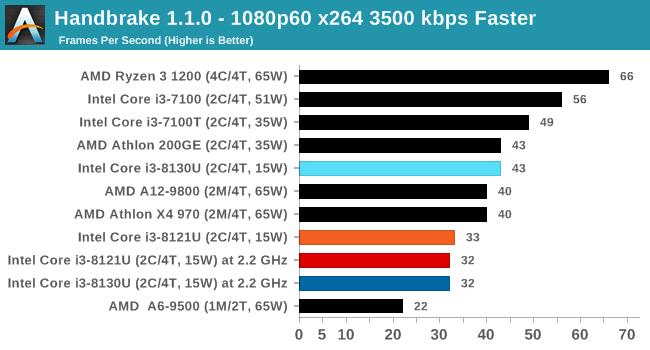
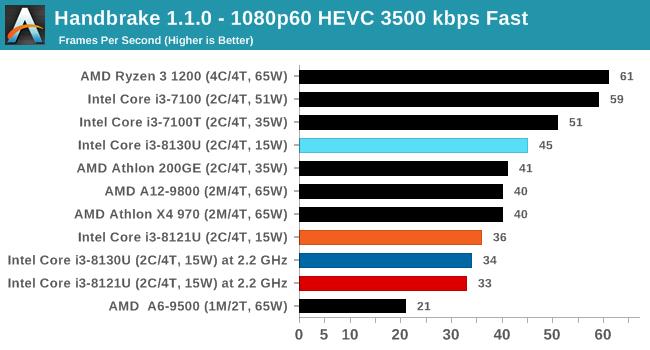
дкi3 8121UЕФВтЪджаЃЌЪЙгУi3 8130UвЦЖЏДІРэЦїзїЮЊЖдБШЃЌетЪЧвЛПюKaby LakeКЫаФЕФЫЋКЫЫФЯпГЬДІРэЦїЃЌЪЙгУ14nmЙЄвежЦдьЃЌTDPЭЌбљЮЊ15WЃЌЛљДЁЦЕТЪгыi3 8121UЯрЭЌЃЌюЃЦЕЦЕТЪдђЗДЖјвЊЩдИпвЛаЉЁЃ
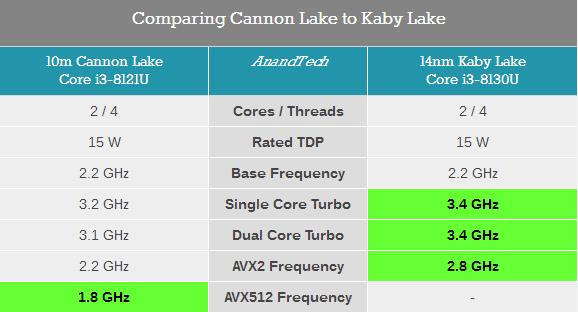
Ждгкетжж15W TDPЕФвЦЖЏДІРэЦїЃЌЛсКмШнвззВЩЯЮТЖШЧНЕМжТНЕЦЕЁЃВтЪджаi3 8121UНЕЦЕЗЧГЃЦЕЗБЃЌдкAVX2гІгУжаИЩДрЪЧдЫаадк2.2GHzЕФЛљзМЦЕТЪзДЬЌЃЌAVX-512гІгУжаЩѕжСЛсНЕЦЕжСЛљзМЯпвдЯТЕФ1.8GHzЁЃ
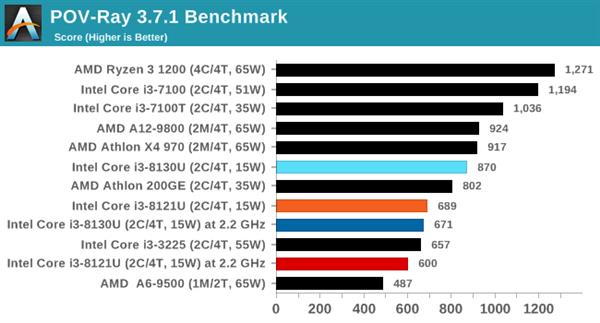
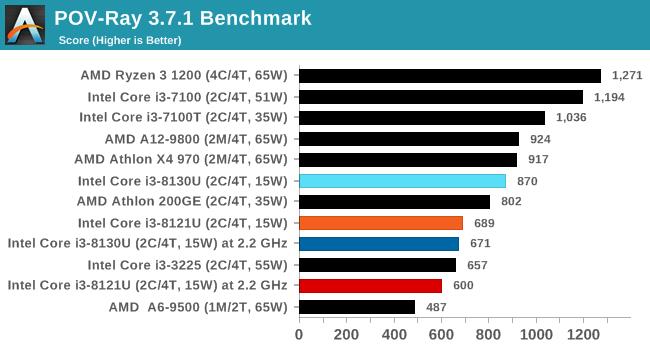
ЯрБШжЎЯТЃЌЪЙгУ14nmГЩЪьЙЄвеЕФi3 8130UдкAVX2гІгУжаШдФмЮЌГж2.8GHzЕФЦЕТЪЃЌБШШчдкPOV-RayВтЪдЯюжаЃЌi3 8130UПЩвдИќПьЕФЭъГЩВтЪдЃЌадФмЯрБШi3 8121UИпГі26ЃЅЁЃ
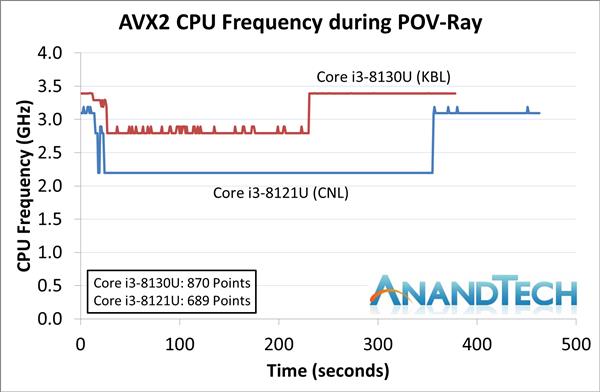
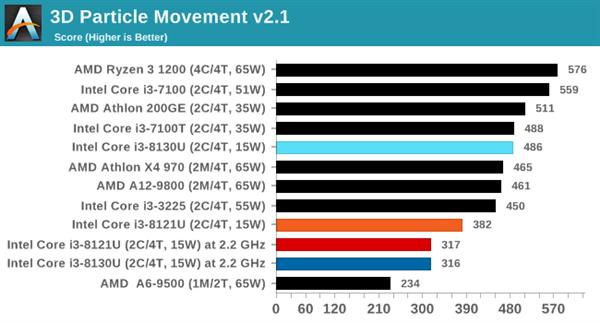
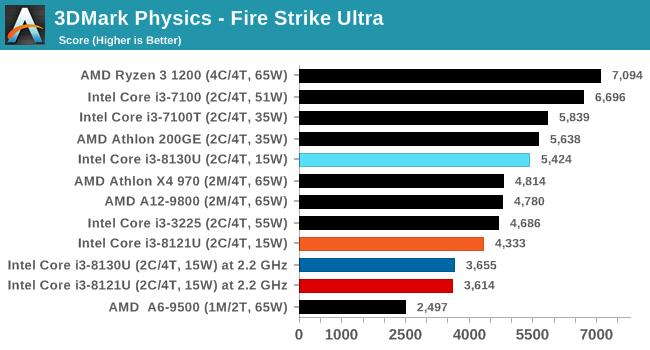
ВЛЙ§ОЁЙмi3 8121UдкдЫааAVX-512гІгУЪБЦЕТЪКмЕЭЃЌЕЋЯШНјЕФжИСюМЏШдШЛДјРДСЫГіЩЋЕФадФмЃЌдк3DPMВтЪджаЃЌПЊЦєAVX-512жИСюМЏЕФi3 8121Uдк1.8GHzЯТГЩМЈЮЊ3846ЗжЃЌ6БЖгк2.8GHzЕЋжЛжЇГжAVX2жИСюМЏЕФi3 8130UЁЃ
ФкДцадФмКЭЙІКФВтЪд
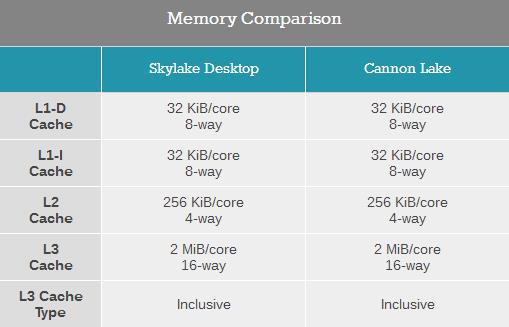
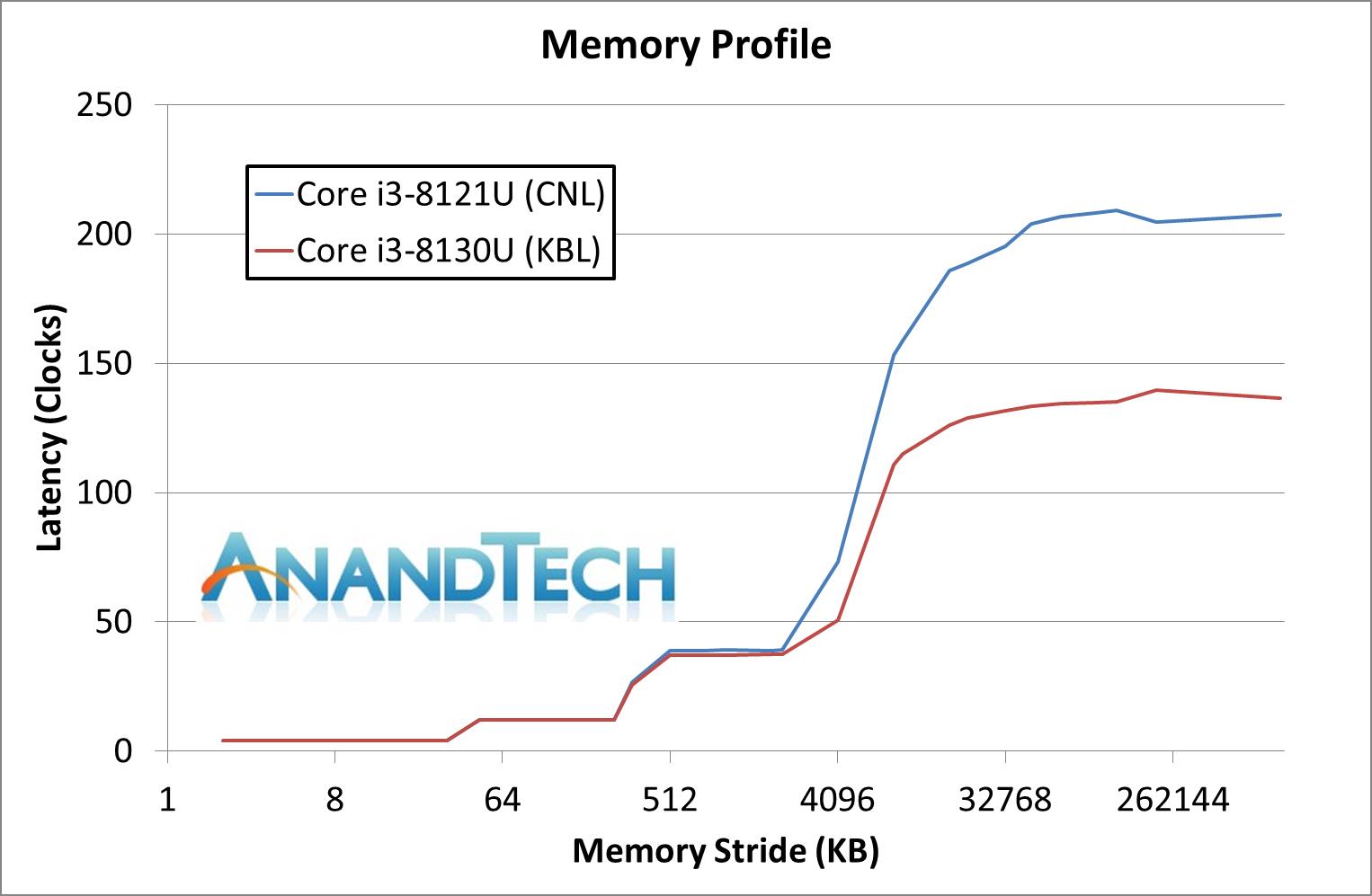
дкЛКДц/ФкДцбгГйВтЪджаЃЌi3 8121UКЭi3 8130UДІРэЦїЖМНћгУСЫюЃЦЕЃЌЦШЪЙЫќУЧвдЯрЭЌЕФ2.2 GHzЦЕТЪдЫааЃЌвдБуНјааЦцХМадКЭжБНгЕФМмЙЙБШНЯЁЃCannon LakeКЫаФЕФЛКДц/ФкДцзгЯЕЭГгыSkylakeКЫаФЯрЭЌЕФЃЌУЛгаШЮКЮЦфЫћИФНјЃЌРэТлЩЯБэЯжГіЕФадФмвВгІИУЛљБОЯрЭЌЁЃ
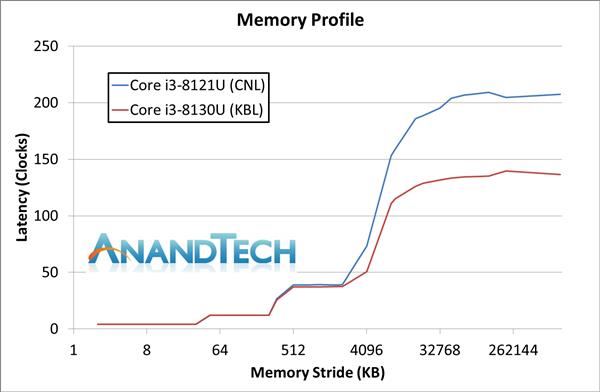
дкетЯюВтЪджаЃЌСНПХДІРэЦїЕФЛКДцЗУЮЪбгГйМИКѕЯрЭЌЃЌЕЋCannon LakeКЫаФЕФi3 8121UЕФФкДцЗУЮЪбгГйвЊИпГіKaby LakeКЫаФЕФi3 8130UЖрДя50%ЃЌвЛЩЯРДОЭе№ОЊСЫЫФзљЃЈЕБШЛетВЛЪЧЩЖКУЪТЃЉЁЃ
ОЁЙмЮЊi3 8121UХфЬзЕФDDR4 2400ФкДцЪБађ17-17-17ЃЌТдЪфгкi3 8130UЕФ16-16-16 -16ЃЌЕЋетвЛЖЊЖЊЪБађВювьдЖВЛзувдгаШчДЫДѓЕФгАЯьЃЌФмЯыЕНЕФЮЈвЛдвђЪЧЃЌCannon LakeКЫаФЗУЮЪФкДцПижЦЦїгаЗЧГЃДѓЕФЖюЭтПЊЯњЃЌетЛђаэОЭЪЧЗтЖТСЫгФСщКЭШлЖЯТЉЖДЕФИБзїгУЁЃ
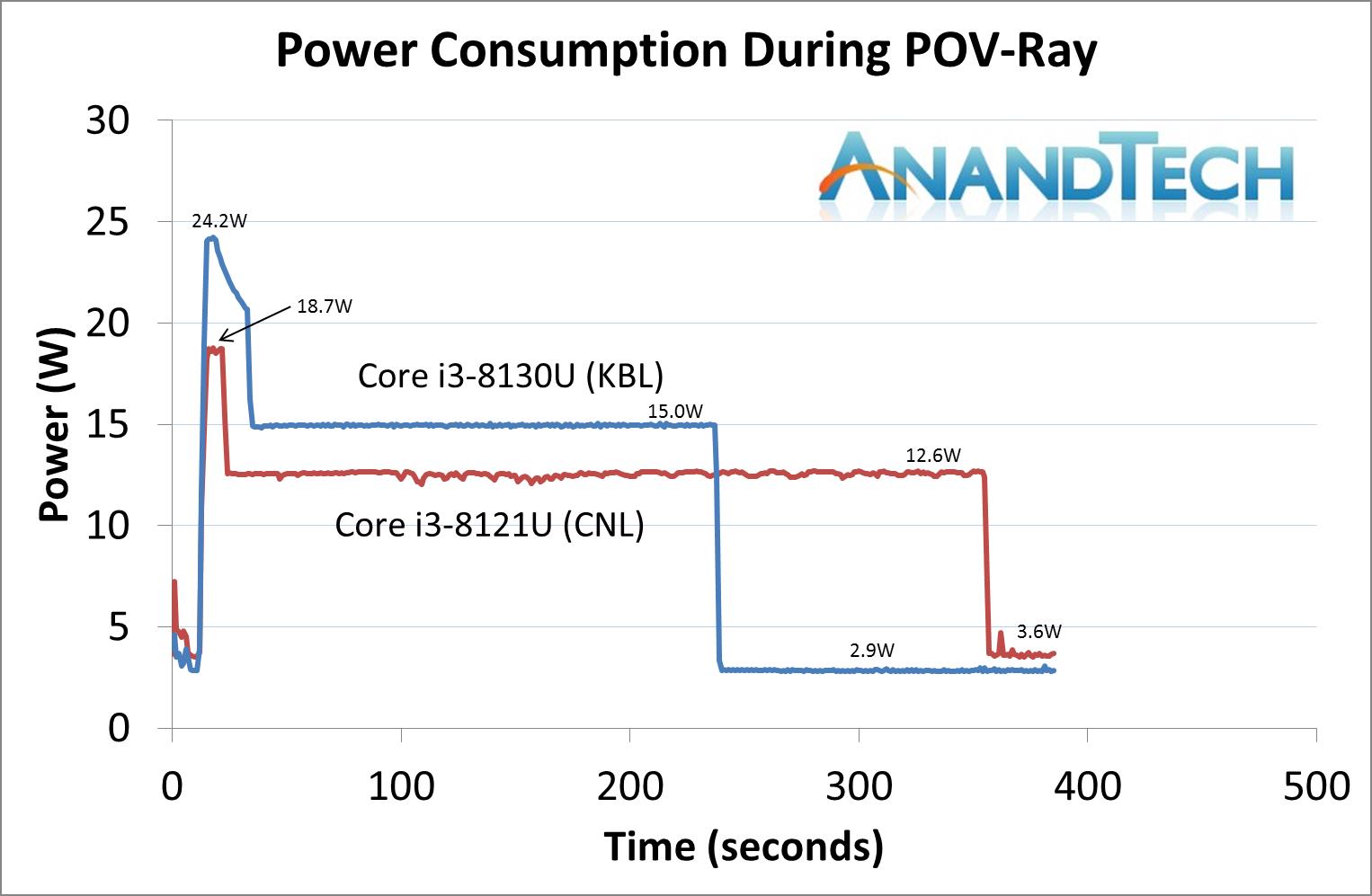
ЖјЙІКФЗНУцБШНЯЦЫЫЗУдРыЃЌЮвУЧжЊЕРЃЌIntelдкДІРэЦїгВМўжаЩшжУСЫСНИіЙиМќЕФЙІКФЯожЦ——PL1КЭPL2ЃЌЧАепПижЦЮШЬЌЙІКФЃЌКѓепПижЦЖЬЪБМфюЃЦЕЙІКФЁЃ
дкДѓЖрЪ§ЧщПіЯТЃЌДІРэЦїЕФЮШЬЌЙІКФКЭTDPЯрЭЌЃЌШчi3 8130UОЭЪЧетбљЃЌДІРэЦїЕФЮШЬЌЙІКФЮЊ15WЃЌШЛЖјЭЌЮЊ15W TDPЕФi3 8121UЕФЮШЬЌЙІКФНіЮЊ12.6WЁЃгЩPL2ПижЦЕФЗхжЕЙІКФвВЪЧЭЌбљЃЌi3 8130UЕФЗхжЕЙІКФПЩвдДяЕН24.2 WЃЌЖјi3 8121UзюИпжЛФмГхЕН18.7WЃЌЧвюЃЦЕЕФГжајЪБМфвВвЊБШi3 8130UЖЬКмЖрЁЃ
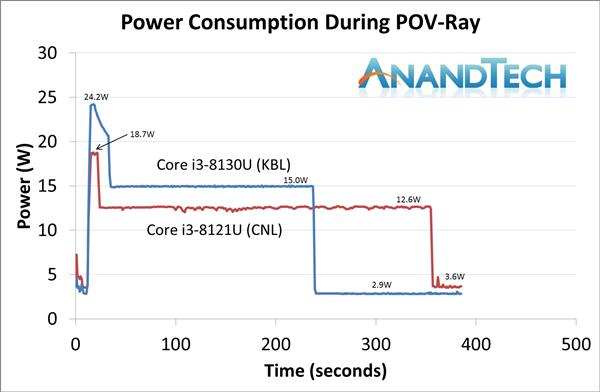
дуаФЕФЪЧЃЌЫфШЛi3 8121UЕФЙІКФЧНИќЕЭЃЌЕЋгЩгкЦфЦЕТЪИќЕЭадФмИќВюЃЌЪЕМЪжДаадЫЫуЫљЯћКФЕФФмСПЗДЖјИќЖрЁЃдкPOV-RayВтЪдЯюжаЃЌKaby LakeКЫаФЕФi3 8130UЕФзмКФФмжЛга768 mWhЃЌЖјCannon LakeКЫаФЕФi3 8121UЕФзмКФФмЮЊ867mWhЃЌзузуИпСЫ12.9%ЁЃ
2.2GHzЭЌЦЕВтЪдЃКSPEC2006
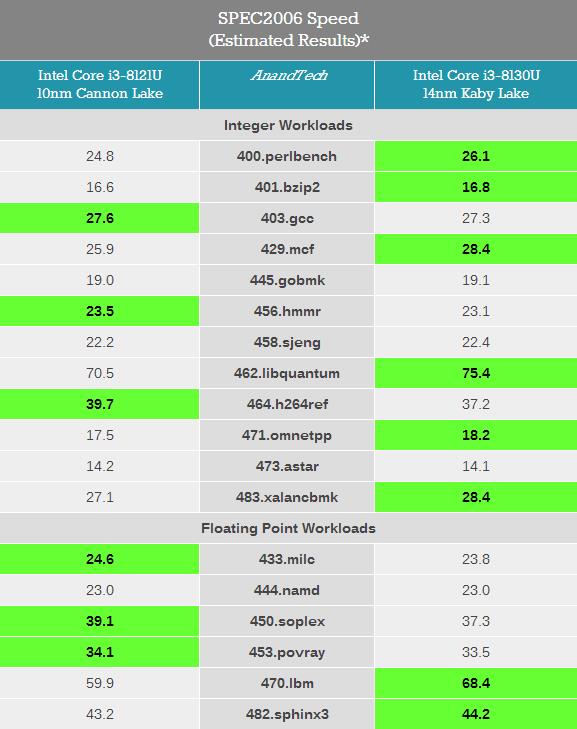
Г§СЫЙІКФЃЌЙигкCannon LakeКЫаФЕФСэвЛИіЮЪЬтдкгкЫќЪЧЗёЪЧвЛИіИпаЇЕФМмЙЙЩшМЦЁЃЮЊСЫНјаажБНгЕФIPCБШНЯЃЌЮвУЧНЋСНПХДІРэЦїЙЬЖЈзЁ2.2 GHzЭЌЦЕТЪЩЯдЫааSPEC2006 ВтЪдЁЃ
SPEC2006ЪЧвЛИіживЊЕФЛљзМВтЪдШэМўЃЌЫќгыЦфЫћВтЪдШэМўЕФЧјБ№дкгкЫљДІРэЕФЪ§ОнМЏИќДѓИќИДдгЁЃзїЮЊЛљзМВтЪдИќгаДњБэадЃЌЫќПЩвдГфЗжеЙЪОМмЙЙЕФИќЖрЯИНкЁЃ
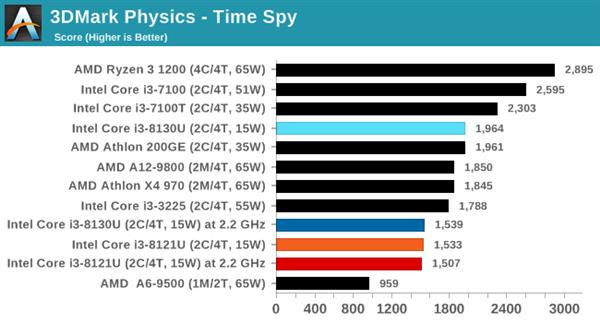
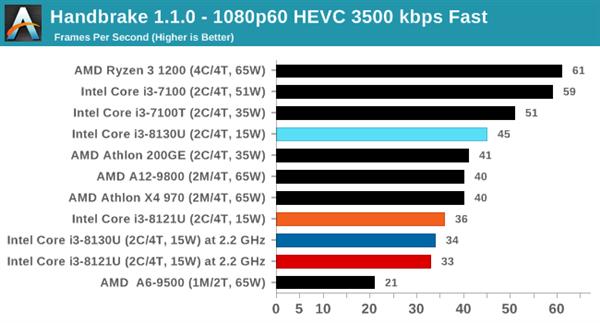
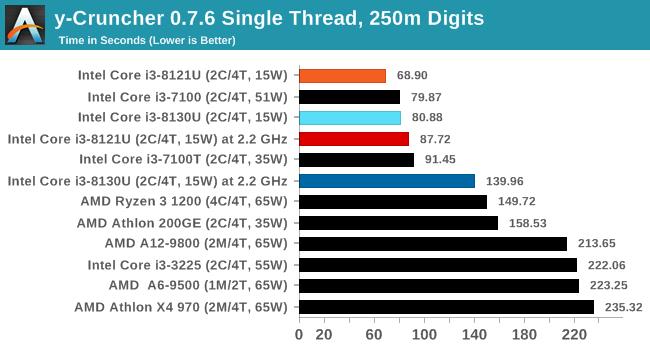
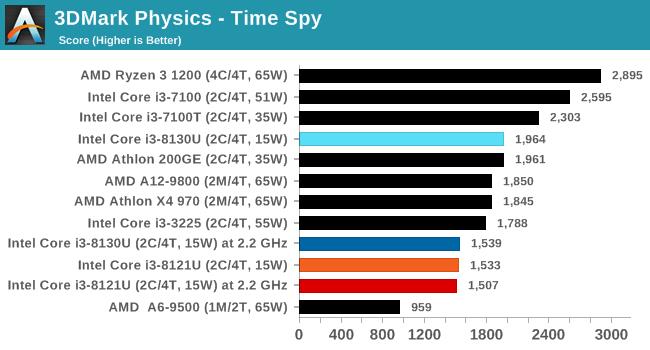
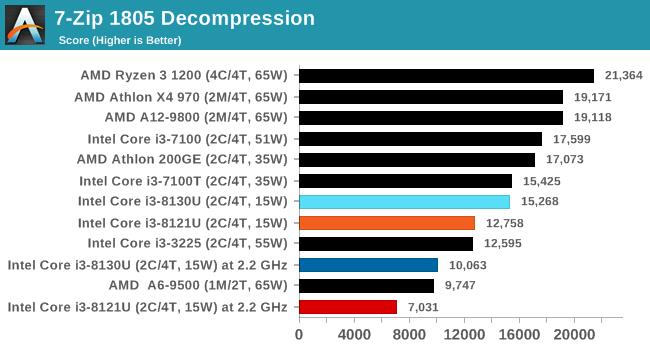
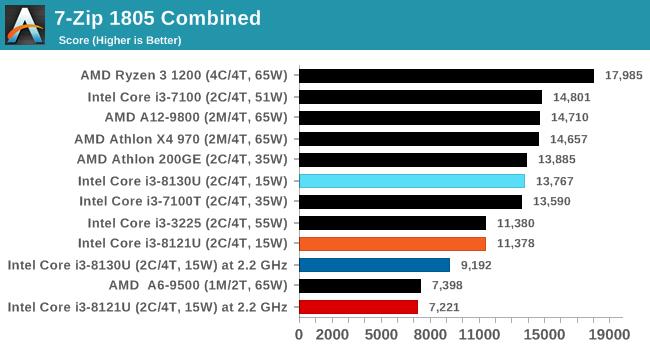
ДгВтЪдНсЙћРДПДЃЌСНПюВЛЭЌКЫаФЕФДІРэЦїадФмЯрВюЮоМИЃЌKaby LakeКЫаФЕФi3 8130UдкгыSIMDЯрЙиЕФ462.libquantumКЭ470.lbmВтЪдЯюжаЫЦКѕБШCannon LakeКЫаФЕФi3 8121UИќгагХЪЦЃЌетвВаэгыЖўепФкДцбгГйадФмгаЙиЁЃ
2.2GHzЭЌЦЕВтЪдЃКЯЕЭГзлКЯадФм
ЯЕЭГВтЪдВПЗжжиЕуЙизЂЪЕМЪгУЛЇЬхбщЃЌНЋАќРЈгІгУМгдиЪБМфЁЂЭМЯёДІРэЁЂМђЕЅПЦбЇЮяРэЁЂЗТецЁЂЩёОЗТецЁЂгХЛЏМЦЫуКЭ3DФЃаЭПЊЗЂЕШВтЪдЯюЁЃ
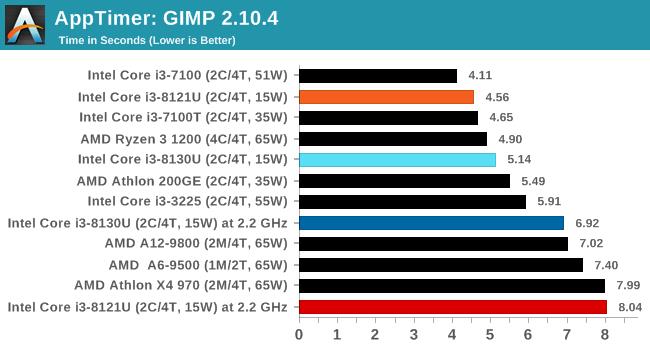
GIMPгІгУМгдиЪБМф
ЯЕЭГЯьгІЫйЖШЪЧзюЙиКѕгУЛЇЬхбщЕФжИБъЃЌвЛИіКмКУЕФВтЪдгУР§ЪЧПДгІгУМгдиашвЊЖрГЄЪБМфЁЃдкетвЛВтЪджаЃЌCannon LakeКЫаФЕФi3 8121UБэЯжЕФЬиБ№КУЁЃ
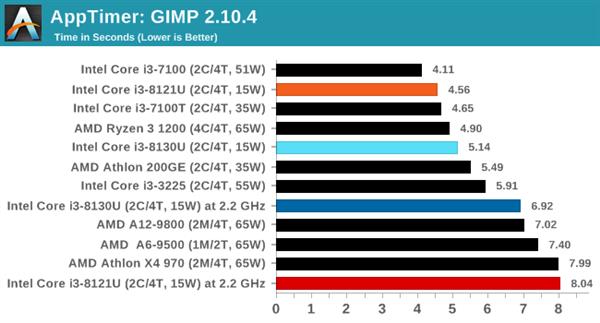
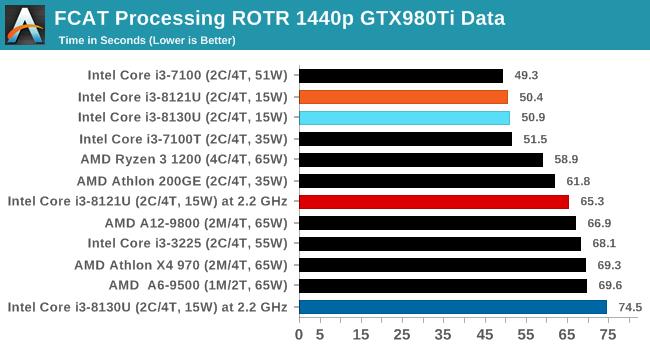
FCATЭМЯёДІРэ
FCATШэМўВЩгУТМжЦЕФЪгЦЕЃЌВЂНЋбеЩЋЪ§ОнДІРэГЩжЁЪБМфЪ§ОнЃЌвдБуЯЕЭГПЩвдЛцжЦПЩЪгЛЏЕФжЁТЪЁЃ
етвЛВтЪдЪЧЕЅЯпГЬЕФЃЌдкЛљзМЦЕТЪЯТЃЌCannon LakeКЫаФЕФi3 8121UгыKaby LakeКЫаФЕФi3 8130UКФЪБВюОрдкАыУыжЎФкЃЌi3 8121UТдЮЂСьЯШЁЃ
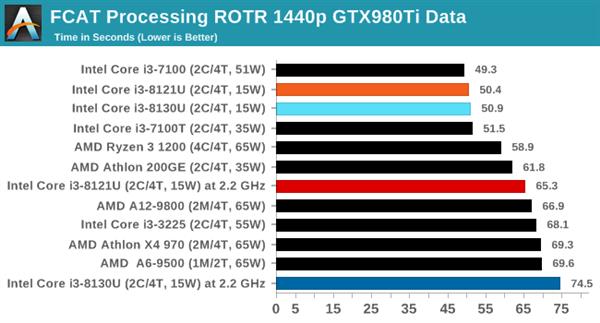
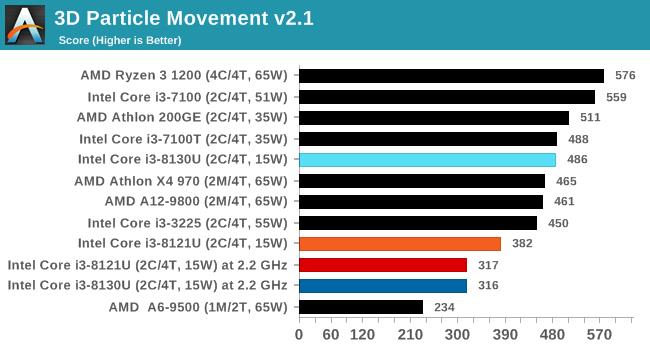
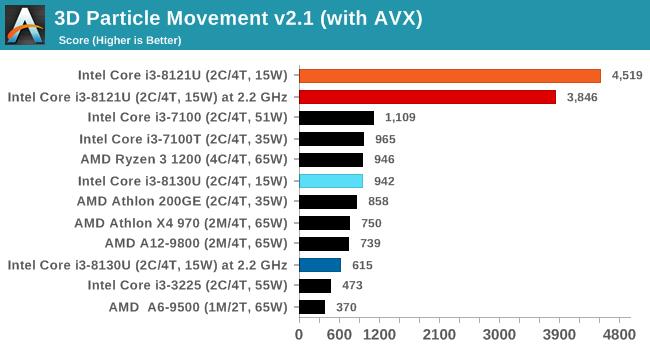
3DPMСЃзгдЫЖЏМЦЫу
3DPMВтЪдЪЧвЛИіЖЈжЦЕФЛљзМВтЪдЃЌжМдкФЃФт3DПеМфжаСљИіЕуЕФВЛЭЌСЃзгдЫЖЏЫуЗЈЁЃЫуЗЈЕФвЛИіЙиМќВПЗжЪЧЪЙгУСЫЯрЖдПьЫйЕФЫцЛњЪ§ЩњГЩЃЌзюжедкДњТыжаЪЕЯжвРРЕСДЁЃдкетвЛВтЪджаЃЌЮвУЧдкСљжжЫуЗЈЩЯдЫаавЛИідзгСЃзгМЏЃЌУПДЮ20УыЃЌднЭЃ10УыЃЌВЂБЈИцСЃзгвЦЖЏЕФзмЫйТЪЃЌвдУПУыЪ§АйЭђДЮдЫЖЏЮЊЕЅЮЛЁЃ
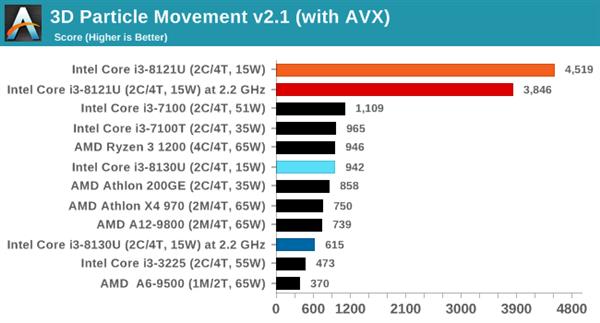
дкВЛЦєЖЏAVXЃЌCannon LakeКЫаФЕФi3 8121UАмИјСЫKaby LakeКЫаФЕФi3 8130UЁЃЕЋИїздЦєЖЏAVXКѓЃЌi3 8121UОЙШЛХмГіСЫ4519ЕФГЌИпЗжЃЌЩѕжСЛїАмСЫ4185ЗжЕФ18КЫCore i9 7980XEДІРэЦїЃЌЗЧГЃЗшПёЁЃ
Dolphin 5.0ФЃФтЦї
Dolphin 5.0ЪЧвЛПюGameCube/WiiжїЛњФЃФтЦїЃЌПЩвддкPCЩЯЭцЕНетаЉРЯПюгЮЯЗжїЛњЕФЖРеМДѓзїЁЃВЛЙ§ЃЌФЃФтетСНЬЈЪЙгУPowerМмЙЙДІРэЦїЕФжїЛњЭЈГЃашвЊвЛПХВЛШѕЕФДІРэЦїВХааЁЃ
дкетвЛВтЪджаЃЌСНПюДІРэЦїЕФЭЌЦЕадФмДѓжТЯрЭЌЁЃ

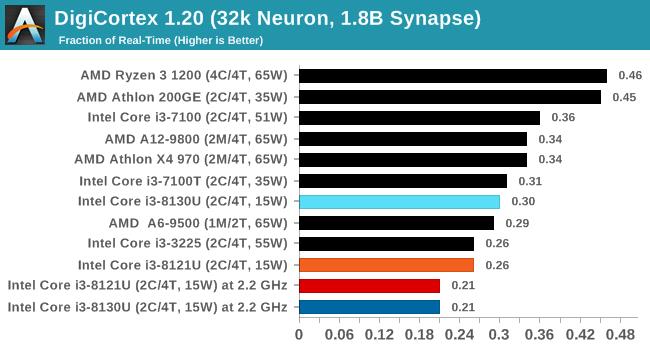
DigiCortexКЃђвђѕДѓФдФЃФт
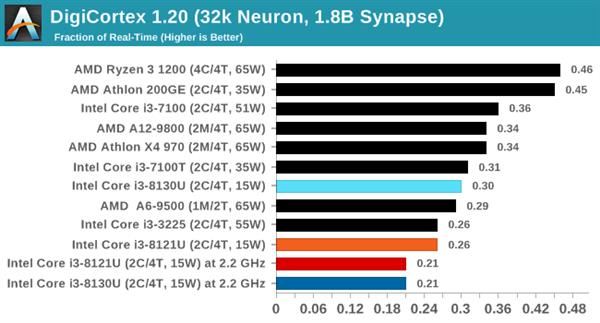
DigiCortexЛљзМВтЪдзюГѕЩшМЦгУгкЩёОдЊКЭЭЛДЅЛюЖЏЕФФЃФтКЭПЩЪгЛЏЃЌИУШэМўОпгаЖржжЛљзМФЃЪНЃЌБОДЮЪЙгУаЁЛљзМВтЪдЃЌФЃФт32000ИіЩёОдЊКЭ18вкИіЭЛДЅЃЌЙцФЃЯрЕБгкКЃђвђѕЕФДѓФдЁЃ
ФЃФтРраЭЗжЮЊ“ЗЧМЄЗЂ”КЭ“МЄЗЂ”СНжжФЃЪНЃЌЧАепЪмФкДцгАЯьИќДѓЃЌКѓепИќвРРЕДПДтЕФДІРэЦїадФмЁЃВтЪджаЪЙгУСЫКѓепЃЌСНПюДІРэЦїЕФЭЌЦЕадФмДѓжТЯрЭЌЁЃ
y-CruncherПЦбЇМЦЫу
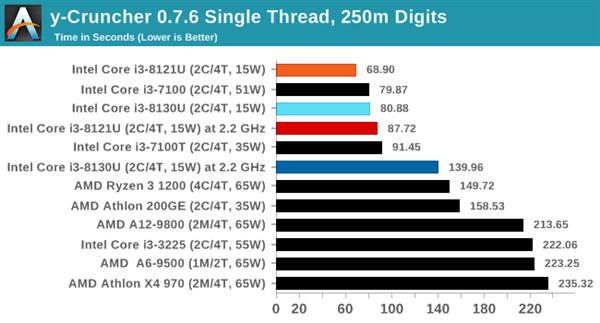
y-CruncherЪЧвЛПюАяжњМЦЫуИїжжЪ§бЇГЃЪ§ЕФЙЄОпЃЌШэМўжЇГжЭЈЙ§ЖўНјжЦЁЂЕЅЯпГЬКЭЖрЯпГЬЕШВЛЭЌгХЛЏЗНЪНдЫааЃЌЩѕжСАќРЈAVX-512гХЛЏЕФЖўНјжЦЮФМўЁЃБОДЮВтЪдЛљгкЕЅЯпГЬКЭЖрЯпГЬЗНЪНЃЌМЦЫу2.5вкЮЛдВжмТЪЁЃ
ВтЪдНсЙћВЛГівтЭтЪЧ Cannon LakeКЫаФЕФi3 8121UЛёЪЄЃЌЕНФПЧАЮЊжЙЃЌЫљгаПЩвдРћгУAVX-512жИСюМЏЕФШэМўЖМЪЧi3 8121UЛёЪЄЁЃ

Agisoft Photoscan 2DЭМЯёзЊ3DФЃаЭ
PhotoScanПЩвдНЋаэЖр2DЭМЯёзЊЛЛЮЊ3DФЃаЭЃЌетЪЧФЃаЭПЊЗЂКЭЙщЕЕжаЕФвЛИіживЊЙЄОпЃЌвРРЕгкаэЖрЕЅЯпГЬКЭЖрЯпГЬЫуЗЈЁЃ
ВтЪдЪЙгУСЫPhotoScan v1.3.3АцБОЃЌЦфжаАќКЌСЫ84 x 1800ЭђЯёЫиЕФДѓЪ§ОнМЏЃЌЭЈЙ§вЛИіЯрЕБПьЫйЕФЫуЗЈБфЬхЃЌзюКѓЖдБШзЊЛЛЙ§ГЬзмЪБМфЁЃ
дкетвЛВтЪджаЃЌСНПюДІРэЦїЕФЭЌЦЕадФмДѓжТЯрЭЌЁЃ

2.2GHzЭЌЦЕВтЪдЃКфжШОадФм
фжШОадФмЭЈГЃЪЧДІРэЦїдкзЈвЕЛЗОГЯТЕФЙиМќжИБъЃЌДг3DфжШОЕНЙтеЄЛЏЃЌКИЧЭјИёЁЂЮЦРэЁЂХізВЁЂОтГнЁЂЮяРэЕШЗНУцЁЃДѓЖрЪ§фжШОЦїЖМжЇГжCPUфжШОЃЌЩйЪ§ПЩвджЇГжGPUЛђFPGAКЭASICЕШзЈгУаОЦЌЁЃЖдгкДѓаЭЙЄзїЪвРДЫЕЃЌCPUШдШЛЪЧЪзбЁЕФгВМўЁЃ
Corona 1.3фжШО
CoronaЪЧ3DS MaxКЭCinema 4DЕШШэМўЕФИпМЖадФмфжШОЦїЃЌЛљзМВтЪдЕФGUIПЩЯдЪОе§дкЙЙНЈЕФГЁОАЃЌВЂНЋфжШОЪБМфЗДРЁИјгУЛЇЁЃ
БОДЮВтЪдЪЙгУСЫжБНгЪфГіНсЙћЕФУќСюааАцБОЃЌЪфГіЕФНсЙћвВВЛЪЧБЈИцЪБМфЃЌЖјЪЧБЈИцСљДЮдЫаажаУПУыЕФЦНОљЙтЯпЪ§ЃЌвђЮЊЕЅЮЛЪБМфФкЕФадФмБШР§ЭЈГЃИќШнвзРэНтЁЃ
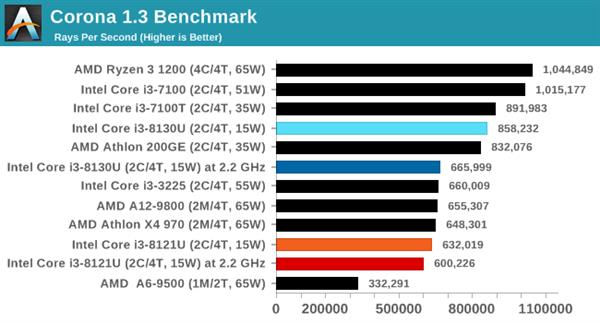
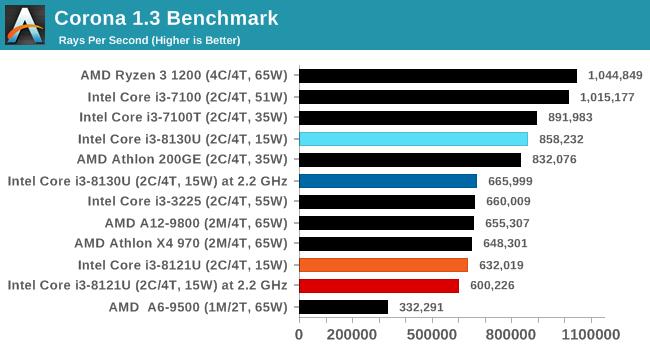
CoronaжЛжЇГжЕНAVX2жИСюМЏЃЌЮоЗЈГфЗжЗЂЛгCannon Lake КЫаФЕФЬиадЁЃдкетвЛВтЪджаЃЌi3 8121UЭЌЦЕадФмТфКѓi3 8130UдМ10%ЁЃ
Blender 3DДДзїШэМў
BlenderЪЧвЛИіПЊдДЕФИпМЖфжШОЙЄОпЃЌжЇГжДѓСППЩХфжУЯюЃЌБЛЪРНчЩЯаэЖржЊУћЕФЖЏЛЙЄзїЪвЫљЪЙгУЁЃИУШэМўЕФПЊЗЂаЁзщзюНќЗЂВМСЫвЛИіЛљзМВтЪдАќЃЌБОДЮВтЪдЭЈЙ§УќСюаадЫааИУЬзМўжаЕФ“bmw27”ГЁОАзгВтЪдЃЌВЂВтСПЭъГЩфжШОЕФЪБМфЁЃ
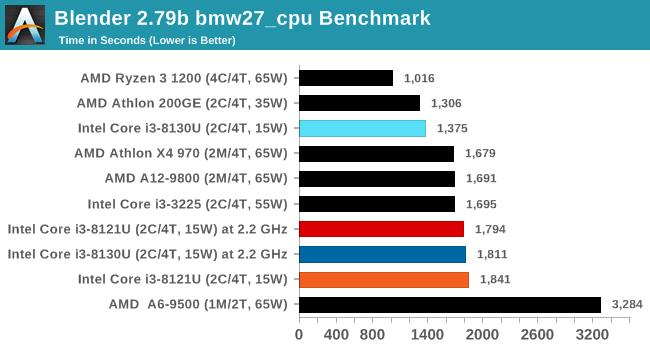
BlenderЭЌбљжЛжЇГжЕНAVX2жИСюМЏЃЌдкетвЛВтЪджаЃЌСНПюДІРэЦїЕФЭЌЦЕадФмДѓжТЯрЭЌЃЌCannon Lake КЫаФЕФi3 8121UгаЮЂШѕгХЪЦЁЃ
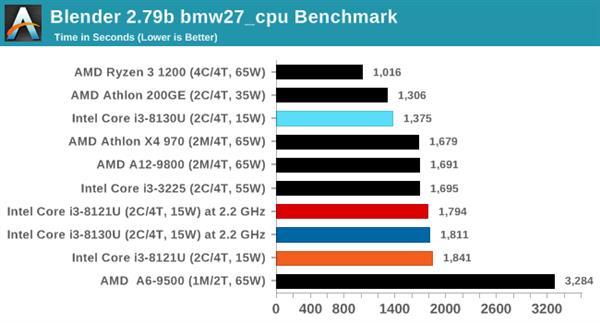
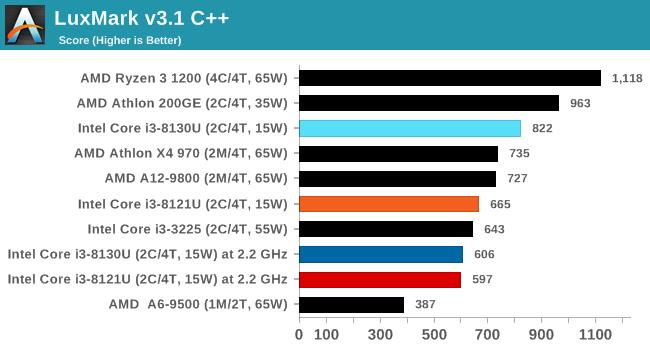
LuxMarkв§Чц
ЪЙгУLuxRenderв§ЧцПЊЗЂЕФЛљзМВтЪдЬсЙЉСЫМИИіВЛЭЌЕФГЁОАКЭAPIЃЌБОДЮВтЪдбЁдёдкC ++КЭOpenCLДњТыТЗОЖЩЯдЫааМђЕЅЕФ“Ball”ГЁОАЃЌвдДжТдфжШОПЊЪМЃЌВЂдкСНЗжжгФкТ§Т§ЬсИпжЪСПЃЌзюжеНсЙћвдУПУыфжШОЕФЙтЯпЪ§еЙЪОЁЃ
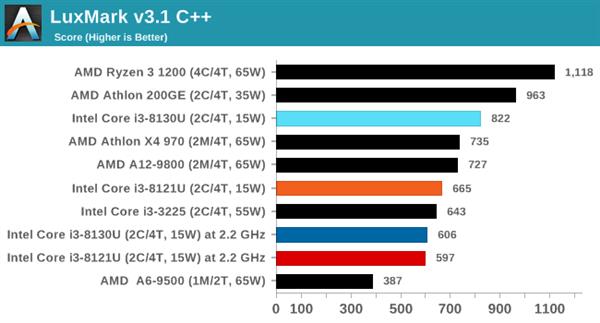
POV-RayЙтЯпзЗзй
Persistence of VisionЙтЯпзЗзйв§ЧцЪЧСэвЛИіжкЫљжмжЊЕФЛљзМВтЪдЙЄОпЃЌдкAMDЗЂВМRyzenДІРэЦїжЎЧАвЛжБФЌФЌЮоЮХЃЌЖјКѓIntelКЭAMDЖМПЊЪМЯђПЊдДЯюФПЕФжївЊЗжжЇЬсНЛДњТыЁЃ
БОДЮВтЪдЪЙгУДгУќСюааЕїгУЫљгаФкКЫЕФФкжУЛљзМЁЃ
2.2GHzЭЌЦЕВтЪдЃКАьЙЋадФм
OfficeВтЪдЬзМўжМдкзЈзЂгкИќЖраавЕБъзМЃЌШчАьЙЄСїГЬКЭЯЕЭГЛсвщЕШЃЌЕЋЪЧЮвУЧвВНЋБрвыЦїадФмРІАѓдкБОНкжаЁЃЖдгкБиаыЖдгВМўНјаазмЬхЦРЙРЕФгУЛЇРДЫЕЃЌетаЉЭЈГЃЪЧзюашвЊПМТЧЕФЛљзМВтЪдЁЃ
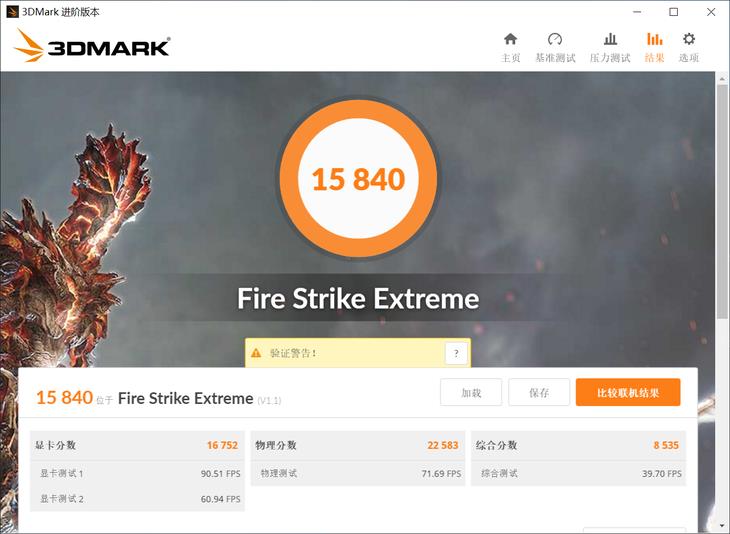
3DMarkЮяРэМЦЫу
гЮЯЗВтЪдШэМў3DMarkЕФУПИіВтЪдГЁОАОљАќРЈвЛИіЮяРэВтЪдзгЯюЁЃАДИДдгГЬЖШХХСаЕФвРДЮЮЊIce StormЁЂCloud GateЁЂSky DiverЁЂFire StrikeКЭTime SpyЁЃ
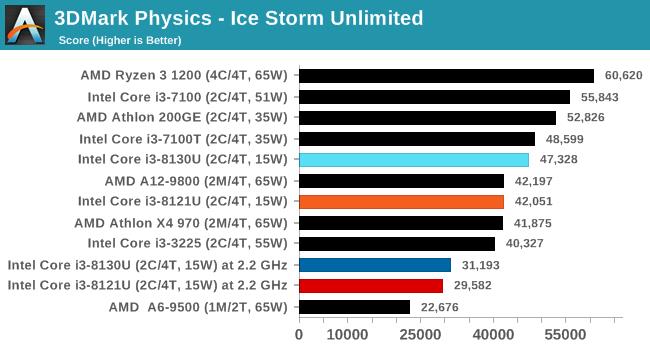
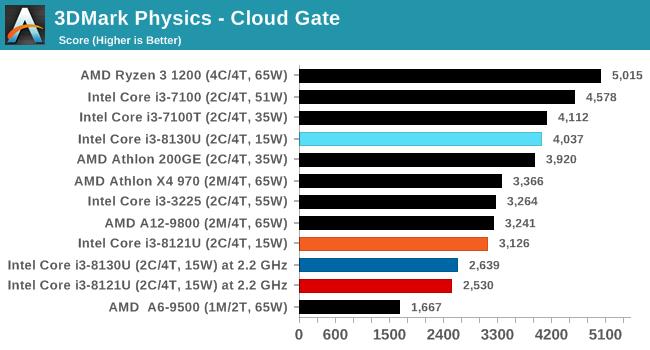
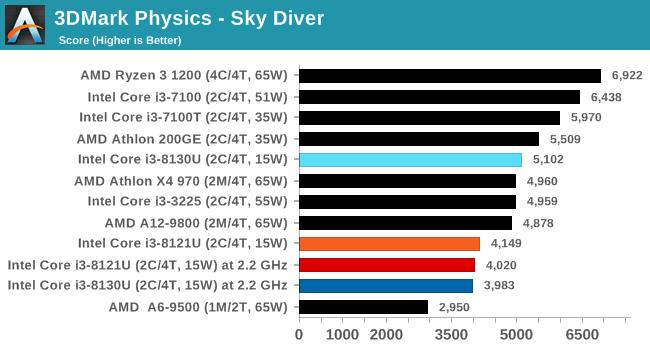
дкЫљгаВтЪдГЁОАжаЃЌСНПюДІРэЦїЕФЭЌЦЕадФмЖМДѓжТЯрЭЌЁЃ
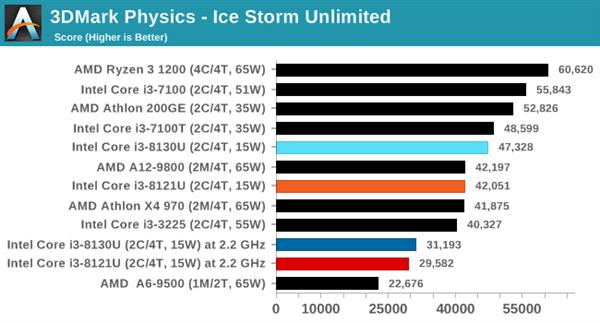
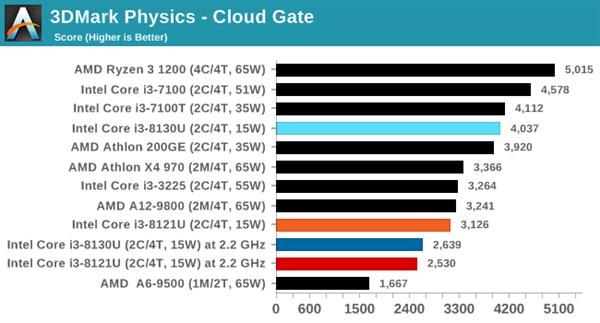
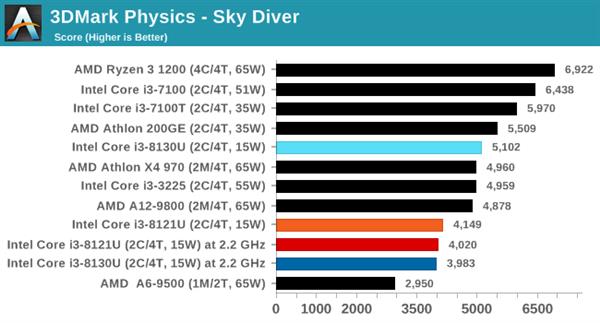
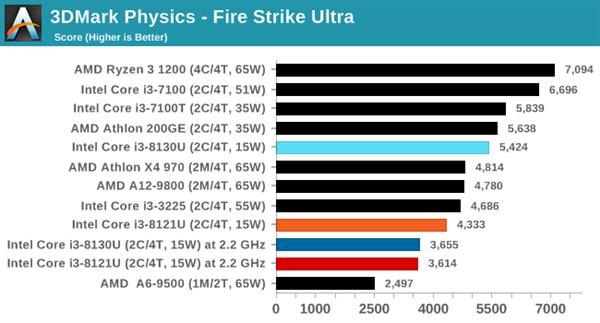
GeekBench 4
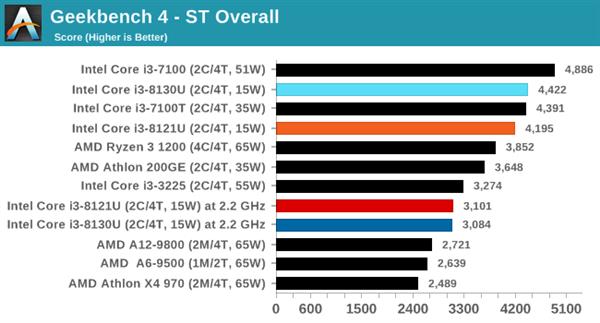
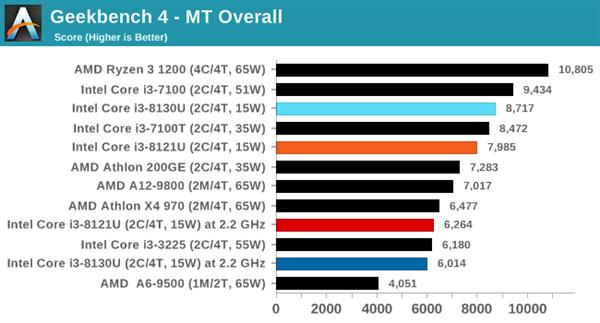
GeekBench 4ЪЧГЃгУЕФПчЦНЬЈВтЪдЙЄОпЃЌжиЕубАЧѓЗхжЕЭЬЭТСПЕФвЛЯЕСаЫуЗЈЃЌАќРЈМгУмЁЂбЙЫѕЁЂПьЫйИЕРявЖБфЛЛЁЂДцДЂЦїВйзїЁЂnЬхЮяРэЁЂОиеѓдЫЫуЁЂжБЗНЭМДІРэКЭHTMLНтЮіЕШЃЌГЃгУгквЦЖЏЩшБИВтЪдЁЃ
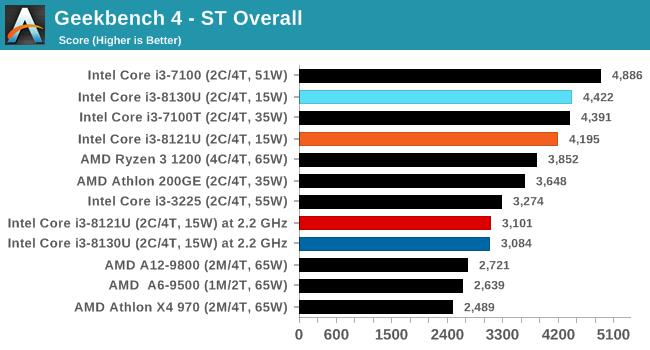
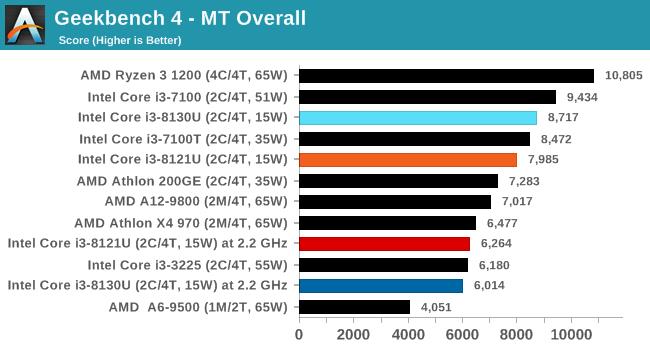
ПМТЧЕНЦфЭЈгУадКЭСїааГЬЖШЃЌБОДЮвВМгШыСЫетПюШэМўЕФЕЅЯпГЬКЭЖрЯпГЬВтЪдЁЃ
2.2GHzЭЌЦЕВтЪдЃКБрТыадФм
ЫцзХСїУНЬхКЭЖЬЪгЦЕФкШнЕФаЫЦ№ЃЌдНРДдНЖрЕФМвЭЅгУЛЇКЭгЮЯЗЭцМвашвЊНЋЪгЦЕЮФМўНјаазЊЛЛЃЌДІРэЦїЕФБрТыКЭзЊТыадФмБфЕУдНРДдНживЊЃЌБОДЮБрТыВтЪдвВжївЊЮЇШЦетаЉживЊЕФГЁОАНјааЁЃ
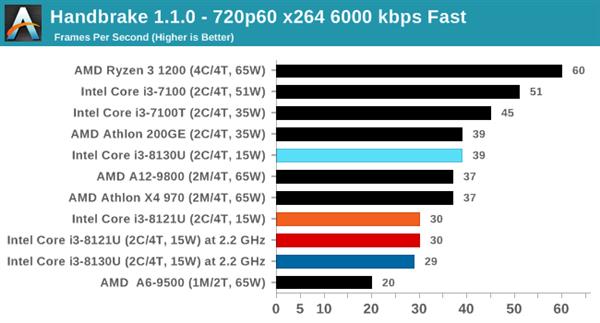
HandbrakeЪгЦЕзЊТы
HandbrakeЪЧвЛжжСїааЕФПЊдДЪгЦЕзЊЛЛШэМўЃЌзюаТЕФАцБОПЩРћгУAVX-512КЭOpenCLРДМгЫйФГаЉРраЭЕФзЊТыКЭЫуЗЈЁЃБОДЮВтЪдЪЙгУЕФCPUзЊТыЁЃ
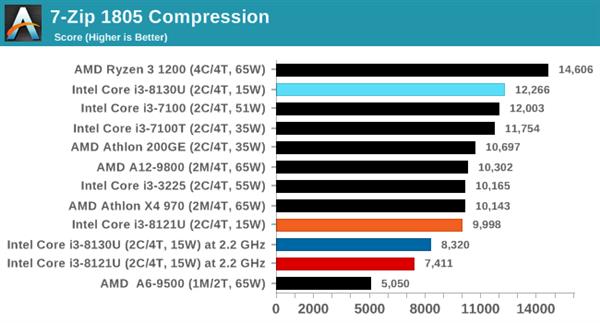
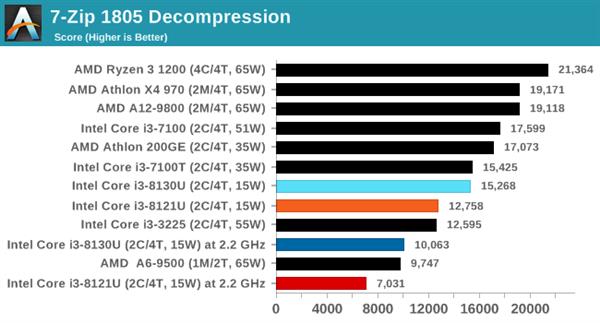
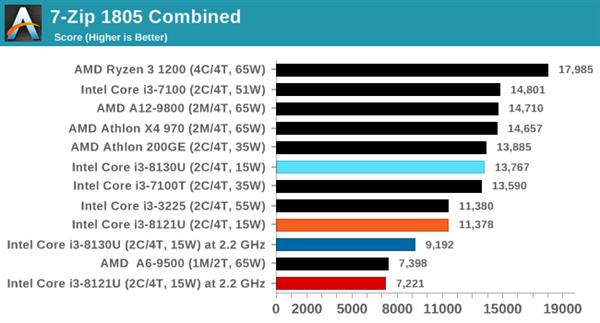
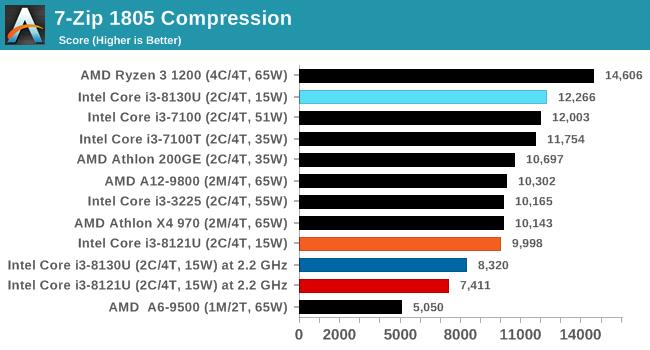
7-ZipбЙЫѕНтбЙ
дкбЙЫѕ/НтбЙгІгУжаЃЌПЊдДЕФ7-ZipЪЧКмЛЖгЕФЙЄОпжЎвЛЁЃБОДЮВТВтЪЧЪЙгУзюаТЕФv18.05АцБОЃЌЫќФкжУгаЛљзМВтЪдЃЌДгУќСюаадЫааЛљзМВтЪдЃЌБЈИцбЙЫѕЁЂНтбЙЫѕКЭзлКЯЕУЗжЁЃ
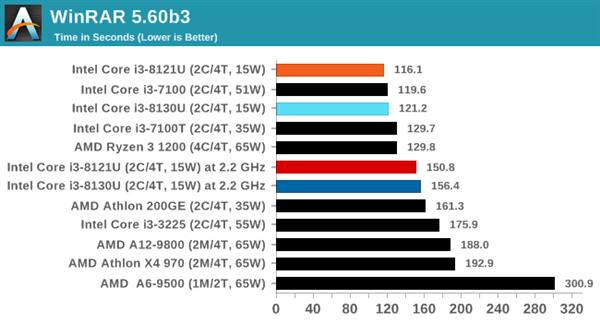
WinRARбЙЫѕНтбЙ
дкДѓЖрЪ§ШЫЕФЯЕЭГжаЭЈГЃЖМгаWinRARЃЌЫќЪЧ20ЖрФъЧАЕФЕквЛХњбЙЫѕНтбЙЙЄОпжЎвЛЁЃЫќУЛгаФкжУЛљзМВтЪдЃЌБОДЮЪЙгУвЛИіАќКЌГЌЙ§30Иі60УыЪгЦЕЮФМўКЭ2000ИіСуЫщаЁЮФМўЕФЮФМўМаЃЌвде§ГЃбЙЫѕТЪдЫаабЙЫѕЁЃ
WinRARЪЧПЩБфЯпГЬЕФЃЌЕЋвВШнвзЪмЕНЛКДцЕФгАЯьЃЌвђДЫВтЪдашдЫааЫќ10ДЮВЂШЁзюКѓЮхДЮЕФЦНОљжЕЃЌЪЙНсЙћПЩвдеЙЪОCPUДПДтЕФдЪММЦЫуадФмЁЃ
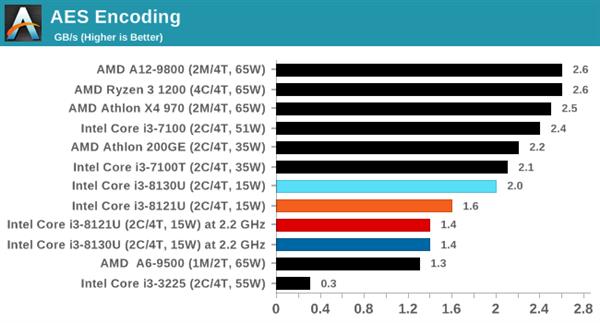
AESМгУм
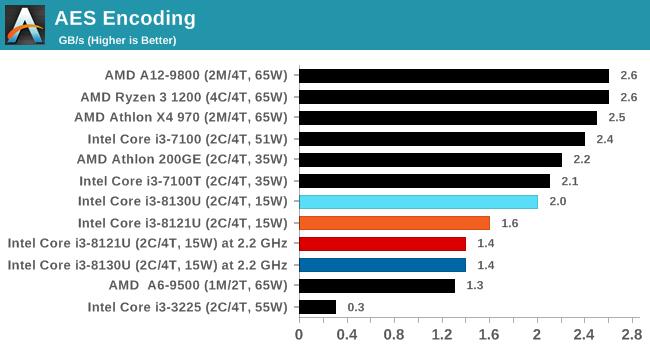
аэЖрвЦЖЏЩшБИФЌШЯЪЙгУЕФЮФМўЯЕЭГЖМЬсЙЉСЫМгУмЙІФмвдБЃЛЄФкШнЃЌPCЩЯЕФWindowsвВгаЃЌЭЈГЃгЩBitLockerЛђЕкШ§ЗНШэМўгІгУЁЃБОДЮЪЙгУвбЭЃВњЕФTrueCryptзїЮЊЦфФкжУЛљзМВтЪдЃЌПЩжБНгдкФкДцжаВтЪдЖржжМгУмЫуЗЈЃЌжЇГжAESжИСюМЏЕЋВЛжЇГжAVX-512ЁЃВтЪдВЩгУЕФЪ§ОнЪЧAESМгУм/НтУмзщКЯЃЌвдУПУыЧЇеззжНкЮЊЕЅЮЛЁЃ
РзЗцЭјзмНс
Intelдк10nmЙЄвеЩЯШЗЪЕНјааСЫКмЖрИФНјЃЌШчЙћУПвЛВНЖМФмЭъУРдЫааЃЌФЧУД10nmгІИУдкШЅФъОЭГЩСЫЁЃПЩЮЪЬтЪЧдкАыЕМЬхЩшМЦжаЃЌгаМИАйИіВЛЭЌЕФЬиадЃЌИФЖЏШЮКЮвЛИіЖМПЩФмЛсЕМжТЦфЫћМИИіЩѕжСМИЪЎИіЬиадБфВюЃЌете§ЪЧIntelдк10nmЙЄвеЗНУцгіЕНЕФзюДѓЮЪЬтЁЃ
ШдМЧЕУ2018ФъЕФCESЩЯЃЌIntelЖд10nmЙЄвеЯрЙиЕФЮЪЬтМъПкВЛбдЃЌДгетъМЛЈвЛЯжЕФCannon LakeКЫаФРДПДЃЌЮЈвЛГЦЕУЩЯССблЕФБэЯжжЛгаAVX-512адФмЃЌКмУїЯдЕквЛДњ10nmЛЙдЖдЖУЛгазМБИКУТѕШыЛЦН№ЪБЖЮЃЌIntelЪЧдкЪдЭМРфДІРэетвЛДњДІРэЦїЃЌвВПЯЖЈВЛЛсе§ЪНЙЋПЊЗЂЪлЫќУЧЁЃ
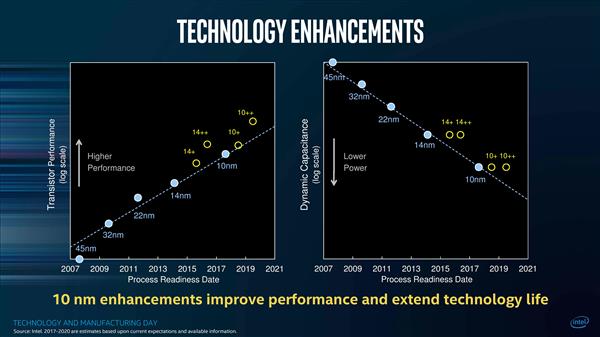
дкIntelИјГіЕФетеХЭМжаЃЌгвВрЯдЪО10nmЙЄвеМАЦфИФаЭПЩвРППНЯЕЭЕФЖЏЬЌЕчШнгЕгаНЯЕЭЕФЙІТЪЃЌШЛЖјЪ§жсЕФзѓВрдђЯдЪО10nmКЭ10nm+ЙЄвеЕФЕЅИіОЇЬхЙмадФмЦфЪЕЛЙвЊЕЭгкЕБЧАЕФ14nm++ЙЄвеЃЌвЊЕНЯТЯТЯТвЛДњЕФ10nm++ЙЄвеВХФмеце§ЪЕЯжШЋУцСьЯШЃЌЖјДгi3 8121UЕФБэЯжРДПДЃЌКмДѓИХТЪЩЯвВвтЮЖзХдкЕкШ§Дњ10nm++ЙЄвеЪЕЪЉжЎЧАЃЌвЕНчКмПЩФмЖМЮоЗЈПДЕНеце§ЭЛЦЦадЕФ10nmДІРэЦїЃЈвЛИЭзгжЇЕНШ§СуСуСуФъСЫ……ЃЉЁЃ
дЄМЦНЋдкНёФъЯТАыФъЮЪЪРЕФIce LakeДІРэЦїЛсЪЙгУЕкЖўДњ10nm+ЙЄвеЃЌЕчЦјадФмНЋЗЧГЃНгНќ14nm++ЙЄвеЃЌЛђаэФЧЪБIntelдк10nmЙЄвеЩЯДђЯьеце§ЕФЕквЛХкАЩЁЃ
|





































































































































































































































































![[MD:Title]](/img/20190130/46957e397cf443698c04903a04ac5ead.jpg)