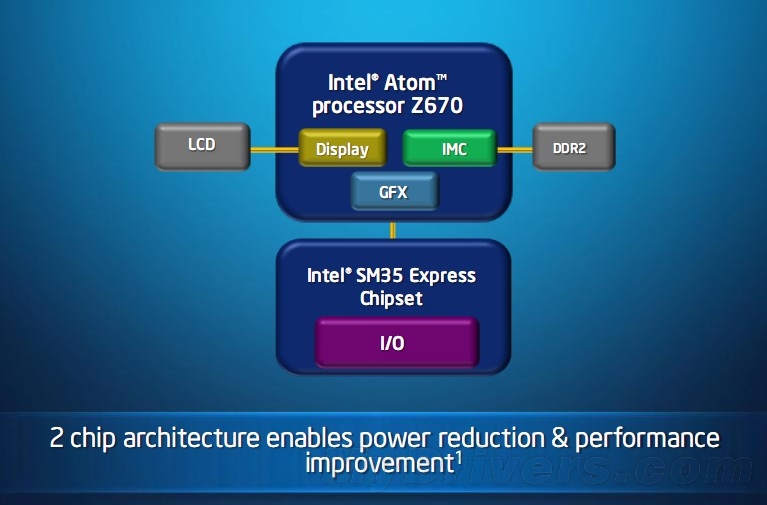
���ƶ�����������AMDһֱ������������������2010�꣬AMD�Ƴ��ĵ������ƶ�ƽ̨������Danube������ƽ̨�ʹ���Nile�ij��ᱡƽ̨��ƾ��CPU+GPU+оƬ��ȫƽ̨Эͬ��ս��������ȡ�����൱�����ijɼ�����Ҳ�ᶨ��AMDѰ�����ƶ��ʼDZ��г�����Ѱ��ͻ�ƣ����������ǶԳ����Ƶľ��ġ�
Fusion APU������
�����֪��˫�ˡ��ĺ��������CPU�������Ƿ��˽�APU��APU��Ӣ��ȫ��Ϊ“Accelerated Processing Unit”����˼�Ǽ��ٴ�����������AMD��Fusion APUȡ��һ�������֣�����������CPU��GPU�϶�Ϊһ����ͬʱִ�д��м���Ͳ��м��㣬Ϊ����Ӧ���ṩ���١�

AMD�����Ƴ���Fusion APU
APU������������еĸ����ʵ����AMD�չ�ATI�ã��ʹ������“Fusion”�ļƻ�����ͼ��CPU��GPU������һ�𡣵�2011�����AMD��APU������CES 2011����ʽ�dz����ࡣ
Fusion APU��������
��GPU��CPU��ͨ������“����”
��ȻӢ�ض������Ƴ��������Կ���Core i5/i3�����������������������Pentium D˫�˴�����һ����Ӣ�ض�����"CPU+GPU"����ƾ�������������оƬ����������������ģ��ļ��ӣ�����һ�ֹ��ɷ���������ԭ���ĵ�оƬ�����������AMD��APU���Dz��ø��Ƚ���ԭ������——��CPU��GPU�ں���ȫ��Ϊһ��ĵ�оƬ�������������ں�֮������ݽ���Ч�ʸ��ߡ�
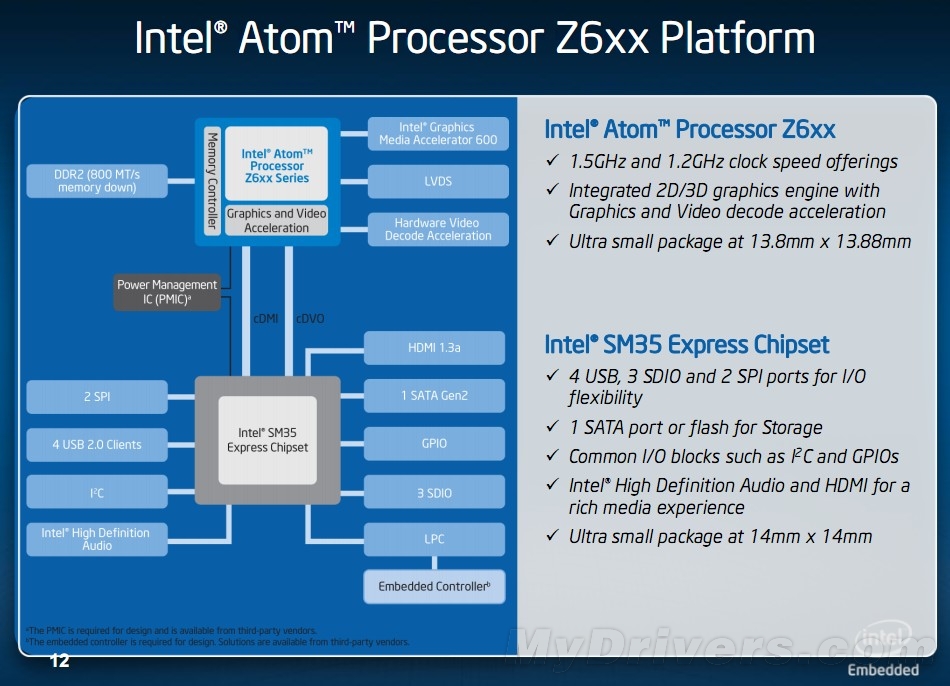
Fusion APU��Ҫ��x86�ܹ���CPU���ģ��������е�Ontario��Zacate APU������������“Bobcat”�ܹ�����DirectX 11 SIMD�������С�UVD������Ƶ���桢�������ߺ�DDR3�ڴ�������ȼ���ģ���װ��һ�������ڹ��ɡ�CPU��GPU��˾��ְ�����Էֱ�ӵ�ж������档CPU��GPUͨ���л����ػ������ӣ�������APU�ڲ��ĸ������֮��ͨ��HyperTransport�������ӳ�һ�����塣CPU��GPU����ֱ�ӷ��ʴ洢����CPU���ڴ�֮�䣬�Լ�GPU���ڴ�֮���ʹ�ý��濪�ؽ������ӣ�����CPU��GPU��ͨ�������ڴ�������ݽ�����APU��һ��Ƶ���������ǿ�����������AMDƽ̨�ϸ�����֮��Ļ���ƿ������Ŀǰ��AMD����ƽ̨�ϣ�ԭ��λ�ڱ���оƬ�����߿��������ڴ���������Ѿ����ɵ�CPU�ڲ��������ڴ���������ڴ�֮��Ĵ�������17GB/s���ң������뼯���Կ�֮��Ĵ������ǽ���ֻ��7GB/s���ң����ѳ�Ϊƿ�����ڡ���Ϊ���ص��ǣ������Կ����ڴ�ͨ��ʱ����Ҫ�Ƶ����Ų��֣�������ͨ����ʱ��AMD APU�ڽ�������Щ����ģ��ȫ�����ϵ�һ�龧Ƭ���������������֮��Ĵ�����APU�ڲ���GPUͼ�����С�UVD���������뱱��ģ�鼰�ڴ������֮���ͨ���ߴ�27GB/s���ڴ���������ڴ�֮��Ĵ���Ҳͬ���ﵽ��27GB/s�����⣬GPU���ڴ�֮��Ҳ����ֱ��ͨ�ţ�������������������������GPU��ִ��Ч�ʡ�
��ǿ��������������
����Fusion APU��һ��ȫ�µ�CPU��GPU���ںϷ�����GPU���ֽ�������ĿǰAMD Radeon HD 6300M/6250M��ͬ�����ͼ�κ��ģ�����֧��DirectX 11�⣬����ͨ��OpenCL֧��GPU�������㡣Fusion APU�ں˼ܹ�����������������ȫ�µ�“Bobcat”�ܹ���
Bobcat��AMDȫ�¼ܹ�����һ�����������ģ���Bulldozerһ����BobcatҲ����������ִ�е�Ԫ���㵥Ԫ�ֱ����������ֻ����Bobcat�ں˵���������“��”��Bulldozer���١���ô��ʲô����������“��”�أ��������б�Ҫ����һ��Bulldozer�ܹ��������õ����ں�������
Bulldozer���ں�����������ģ�黯��ƣ������е�����У�ÿ���������Ķ�Ӧ��һ��ռ���������㵥Ԫ��128bit�������㵥Ԫ������Bulldozer�ܹ��У�ÿ���������ľ��������������㵥Ԫ��һ��������256bit�ĸ������㵥Ԫ��ͬʱ�����256bit�ĸ������㵥Ԫ���Ը�����Ҫ���Ϊ2��128bit�ĸ������㵥Ԫ���������������㵥Ԫ����ʹ�ã�������1��256bit�������㵥Ԫ��ģʽ��ij��������Ԫ��ռ������һ�������ĵ�Ԫ��AMD��Ϊ“����ģ��”����Ҳ����Bulldozer��ν“1.5��”˵�����������������Bulldozer����������ʱ�����ڷ����������DZ�Ȼ�ģ�������“����ģ��”��ɵ�“��”���Ϊ��AMD��Ⱥ���̼߳����еĻ�����λ����Bobcat���������е�“����ģ��”��ֻ������һ��������Ԫ��һ�����㣬����֧�ּ�Ⱥ���̼߳�������ÿ��������ģ���ֻӵ��һ��“��”��Ԫ������˵��“��”�����ﱻ����Ϊ��������������ÿ����������Ԫ��ͬ��һ��“��”��
AMDΪʲôҪ�ں�������е�������������Ԫ����Ŀ������AMD���칹������Բ���ϵ������˵�����е�GPU����ԶԶǿ��CPU�ĸ��������������AMD�����GPU��CPUЭͬ�����ƽ̨ս���£������±����������CPU�ĸ���������������罫������㽻��GPU��ɡ�����������£�����������������Ϊ��Լ����ƽ̨���ܵ�ƿ������ô������ʶ������APU�����������������ɾ���һ�ֱ�Ȼ��ѡ��
 
��ͼ��ΪBobcat��һ��“��”������������Ԫ��INT��ֻ�൱��Bulldozer����ͼ�ң��İ��“��”��
AMD��Bulldozer��Bobcat�ܹ�ͨ���������̵߳�������������������Ӷ��ﵽ�˴������������Ӧ�õ����ܡ���Ҫ˵���ģ������ڼܹ�������������Bobcat�ܹ���Ȼ������Bulldozer�ܹ��Ļ��������ÿ�������䱸64KBһ�����棨32KBָ���+32KB���ݻ��棩��512KB�������棬������֧��ISA��SSE1/2/3��SSSE3ָ������⻯������
֧����������ִ��ָ��ܹ�
����ִ��ָ��ܹ�����������һ���µļ�������һ��Ƶ�Ŀ���ǽ����ڴ���������ִ��ָ��ķ�ʽ��������ܡ������ֽṹ�£�CPU���Ը����ذ���ָ�������Ϊ�ȴ���ȡ�ڴ���Ϣ�����ض���ִ����Դ���˷�ʱ�䡣���ֽṹ�����бף��ô��Ǵ����������ܵõ����������������ǹ��ĵ����Ӻͺ��ijߴ�����ӡ���ˣ�Ϊ�˿��ƹ��ļ����ijߴ�������ɱ�����Ӣ�ض�������������г��Ƴ����趯���������ֻع鵽��ǰ��˳��ִ��ָ�ʽ����Ҳ���趯�ܹ�ʵ�ֳ����ܺĵ��ؾ���֮ǰ��ʢ��C3ϵ�е�C7ϵ�д�������Ҳʹ�����Ƽ���������������ó���ָ��ֻ���ϸ��ռ���˳�����У�����ַ���Ӳ����Դ��Ч�ʣ��Ӷ��������ܵ���——�趯�����������ܲ�ǿ���⡣���AMD���˿ɳ�֮����
AMD��APU�Խ�������������ִ��ָ��ܹ���������������������ͬʱֻ�ܽ�������ָ���Ȼ���ͬһʱ������K8/K10��3ָ��ִ�������Լ�Bulldozer��4ָ��ִ�����������٣��������˳��ִ����Ƶ��趯��ȣ�Bobcat��Ȼ������ָ��Ч�ܷ���ռ�ݲ������ơ�
ȫ��C6���ܸ�ʡ��
�Ӽ���������˵��APU��AMD��һ�μ�������——ͨ�����ϵĵ�оƬ���ܹ��������GPU��CPU˫оƬ������ɵĹ�Ч�⣬��оƬ��ƻ�������Ƚ��ͱʼDZ����Ե��ڲ�����Ѷȣ�������ʵ�ָ�С���ܺĺ����ĵ������ʱ�䡣��һ���棬APU���������µ�C6����ģʽ��

Bobcat�ļܹ�
������������ģʽ����ͳ��ΪC-states��C0��������������������ģʽ����ʱ������������Ч����100%����C0���ϵĸ���ģʽ�����ڽڵ�ģʽ������ģʽ����Խ�ߣ��������ĵ�·���źű��ص��IJ���Ҳ��Խ�ࡣ���磬C1״̬�ĺĵ����϶������C2״̬����������������ʱ����Ҳ���ֻص���C0ģʽ����AMD��C6ģʽ�У�������������ȫ�رգ���������Ҳ����ղ��رգ���������ֻ��һС���ֻ��汣�ֹ����Թ���ʱ���ѡ�����������C6ģʽ�����ѵ�ʱ�����е��ڲ���Ԫ��������̬�洢��Ԫ�ڶ�ȡ������Ϣ����˵�������������ʱ������ǰ�����Ĺ��������ᶪʧ����C6ģʽ�£�Bobcat�ں˿����ڲ���1W�Ĺ�����ά�ֹ�������ʱȴ�����ṩ��������ʱ90%�����ܣ�����˫����Ƶ�Ontario APU��TDP����ֻ��9W֮�͡�
AMD���ƶ��г���Ұ��
AMD��Fusion APU����������һ���Ӵ�ļ��壬��������ƶ�ƽ̨�������Ƴ���Ӧ���ͺţ���Ŀǰ�ľ���̬���������ƶ�ƽ̨��Ȼ������֮�ء�����ƶ�ƽ̨��AMD�����˷dz�ϸ�µĹ滮��APU��������ƽ̨��������Ʒ�ߣ���λ�����г���“Sabine”ƽ̨������“Llano”APU����λ���ᱡ�����ż������г������“Brazos”ƽ̨����“Ontario”����“Zacate”������APU��
“Sabine”ƽ̨��Ҫ��Ը߶˺������ʼDZ���Llano APU������Ŀǰ��Phenom �������ܹ�������˫�˻����ĺ���ơ��������õ�DirectX 11ͼ�κ��Ľ�ӵ��240�������������������µ�32nm�������죬���Ŀ�����35W��
“Brazos”ƽ̨��������ᱡ�ͱʼDZ������ż������ʼDZ���һ�������Zacate APU���Լ�����С������Ontario APU���г������в���̨����40nm���մ�����Zacate APU����E-240��E-350�����ͺţ��ֱ�Ϊ����1.5GHz��˫��1.6GHz�Ĺ��ͼ�κ���ΪAMD Radeon HD 6310���߱�80������������500MHz����Ƶ��,�ܹ�Ϊ�û��ṩ���������������飬��AMD VISION�ı�ʶ����Ontario APU��ӵ��C-30��C-50�����ͺţ�������Ҫ����һЩ������ƹ��Ľ���9W���ṩ���廥����������飬�������µ�HD Internet��ʶ��
|
APU�ͺ�
|
������
������
|
������
����Ƶ��
|
GPU�ͺ�
|
������
������
|
GPU
����Ƶ��
|
TDP
|
|
AMD E-350��Zacate��
|
2
|
1.6GHz
|
Radeon
HD 6310
|
80
|
500MHz
|
18W
|
|
AMD E-240��Zacate��
|
1
|
1.5GHz
|
Radeon
HD 6310
|
80
|
500MHz
|
18W
|
|
AMD C-50��Ontario��
|
2
|
1.0GHz
|
Radeon
HD 6250
|
80
|
280MHz
|
9W
|
|
AMD C-30��Ontario��
|
1
|
1.2GHz
|
Radeon
HD 6250
|
80
|
280MHz
|
9W
|
����APU����ȫ�µ��ں˼ܹ���ƣ����AMDרΪ�����Ƴ�������HudsonоƬ�顣�����õ�оƬ��ƣ�����Ϊ“Fusion Controller Hub”��Fusion���������ģ������FCH������ƶ�ƽ̨��HudsonоƬ�齫��Ϊ���ֲ�ͬ�汾��Hudson-M1��Hudson-M2��Hudson-M3�����е�һ���ӦBrazosƽ̨��Zacate/Ontario APU���������������Sabineƽ̨��Llano APU����
Fusion APU�ܷ����ƶ��г�������
Fusion APU��һ��������CPU��GPU�ں���һ��IJ�Ʒ�����ĵ�����ͳ������ҵ���x86 CPU�������
�����ؽ����Ż���GPU�����ں���һ�𣬲������߸��Ե����Ʒ�������������ƶ�ƽ̨��˵��APU���������Զ����ģ����ɻ��ɴ���Ƚ��ͱʼDZ��ڲ���Ƶ��Ѷȣ�������Ч������ɢ��Ч�ʣ����������Ĺ��ģ���������ʱ�䡣����APU�ij��ֽ������һ��ȫ�µıʼDZ��ڲ��ܹ���Ӱ����Զ�����ϸ������ġ����ͳɱ���Ч�������Ͻ�Լ����̼��������ʱ�����⡣������AMD���䶨��Ϊ“APU��ֵ�;���”�ij��ᱡ�ʼDZ������г��ϣ�APU������������AMD��һö�ذ�ը������͵���1W�Ĺ�����ƣ��Լ������ֽ��Ʒһ��ĺ������ʵ��90%������ˮƽ��AMD��ȫ�л����ڳ��ᱡ�г��������Լ��ķǶԳ����ƣ��������������г��϶�Ӣ�ض��γ���ս��(��/ͼ ����Ʈѩ)
|