正文内容 评论(0)

进入DX10时代之后,竞争对手AMD已经升级了三代显卡架构,而NVIDIA依然是靠G80架构打头阵,虽然期间也推出过工艺升级的G92架构,但这只是一次次的马甲战略而已,NVIDIA真正的新架构是与RV700几乎同期发布的GT200,这是一款规模庞大的GPU架构,晶体管数量达到了惊人的14亿,NVIDIA的GPU架构设计继续走“巨核心”之路。
G80作为游戏显卡毫无疑问是非常优秀的,但是它无法承担实现NVIDIA的通用计算梦想的重任,因为G80的运算能力不足,而且只支持单精度浮点运算,缺少了商业计算中更为重要的双精度浮点运算,而GT200架构中增加了双精度浮点运算支持。

GT200架构设计图
G80中设计了8组TPC(thread processing cluster)阵列,每阵列2个SM(streaming multiprocesser)单元,总计128个流处理器,而GT200中设计了10组TPC阵列,每TPC的SM单元提高到3个,总计240个流处理器。同时每个TPC阵列包括8个TF纹理过滤单元总计80个纹理处理器,ROP总数则提高到32个。
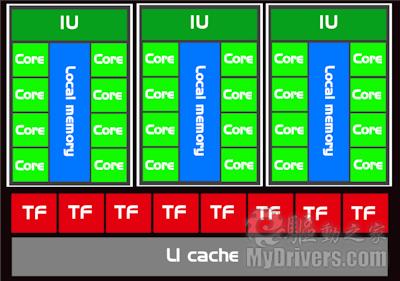
TPC阵列结构
具体到每一个TPC阵列,其包含3个SM单元24个流处理器,每SM单元可执行的线程数由G80的768条提升到1024条,所以总的线程执行能力达到了G80的2.5倍(10*3*1024/8*2*768=2.5)。图中Local memory缓存容量从G80的16K翻倍到32K,共享L1缓存同样从8K翻倍到16K,每个SM中寄存器数量因此从8192个答复增加至16384个,可容纳的指令更多。
GT200中引入注目的一项改进便是SM单元中增加了FP64双精度浮点运算,而G80中仅能支持FP32单精度运算。尽管代价高昂,执行双精度运算时GT200的效能仅有单精度时的1/8,但双精度运算却是必须的,因为GT200除了应付游戏(游戏应用不需要双精度运算)之外还要进军HPC高性能计算机行业,如果不支持双精度浮点运算那就毫无竞争力。
应该说GT200的架构设计是成功的,但是NVIDIA没有想到AMD的RV770能获得意想不到的成功。在顶级性能上AMD的HD 4870只相当于低阶的GTX 260,远落后于GTX 280,但是GT200的成本太高了,而且NVIDIA的生产工艺也落后于AMD,65nm工艺生产出的GT200显卡核心面积达到了576平方毫米,同时显卡的功耗、发热以及PCB配件都处于较高水平,市场上销售的产品过于昂贵,消费者并不买账,即使是改进到55nm之后仍未被普通消费者认可,NVIDIA以GT200实现GPU中心论的梦想遭到了对手顽强的狙击后不得不面对现实。

本文收录在
#快讯
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...