正文内容 评论(0)

Fermi架构中每组SM单元的可执行线程数提高到了1024条,总线程执行能力则达到了24576条,如此多的线程数如何调度分配成了一大难题,为此NVIDIA引入了新的两级分配式(Two-level Distributed Thread Scheduler)线程调度机制。
第一级是芯片级的,有个全局分配引擎负责将线程块(Thread Blocks)分配到每个SM单元中,这一过程较为简单。第二级的线程调度则是SM内部,需要将32条并行线程分配到具体执行单元中去,这一过程比较复杂,因此NVIDIA引入了Dual Warp Scheduler调度机制。

Dual Warp Scheduler双线程调度器示意图
SM单元的调度器由32条并行线程组成,NVIDIA称之为“Warp”。每组SM中都包含两条warp 调度器和两个指令发送单元(保证两个warp调度器都可以同时发送和执行指令)。由于调度器各自独立运行,每个调度器都可以发送指令到16个CUDA核心、16个Load/Store单元以及4个SFU单元中去(正好是SM单元的一半),两个调度器互不依赖因此一个周期内即可发送一个warp,而G80/G200架构中需要两个周期才能完成一个warp,相比之下Fermi执行效率大幅提升。
Dual Warp Scheduler的困难是双精度运算不支持这样的双向调度方式,好消息则是大多数指令如整数指令、浮点指令、整/浮混合指令、load(载入)、Store(存储)以及SFU指令都支持Dual Warp Scheduler,只要这两条指令是相同的。
Fermi同时支持多任务处理,那么如何在不同人物之间快速切换也变得很重要。Fermi架构支持Context Swithing(前后关联切换)可以在25微秒内切换两种不同的应用,10倍于前代架构。举例来说,当前时刻显卡在进行纹理处理,下一时刻就要进行物理加速计算,Fermi架构就可以在25微秒内保证物理加速计算所需的资源,下一时刻或许又会从物理加速计算转向别的应用,期间的切换时间越短越好。
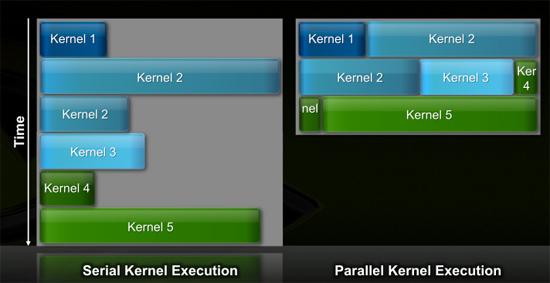
Fermi支持Concurrent Kernel Execution并行计算
上一段讲的不同程序之间的切换,Fermi并行处理的另外一个好处则是支持并发核心执行(Concurrent Kernel Execution),同一应用程序中不同但相关的核心可以同时运行,这样可以最大化利用GPU能力。举例来说,物理加速运算中可能需要请求流体以及刚体计算,这两者属于同一程序内的不同核心,以往的串行执行方式会是执行完流体运算后再进行刚体计算,而Fermi则可以同时进行流体与刚体计算。

本文收录在
#快讯
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...