正文内容 评论(0)

计算机每个像素都是由RGB(红绿蓝三原色)组成,并附加alpha灰度值表示各颜色的透明度,顶点则包含XYZW四个坐标。因此在进行图像处理时像素单元可以同时进行R、G、B以及Aplha四次运算得出像素的颜色,顶点单元也可以一次进行XYZW四次矢量坐标运算,DX10之前的架构都是这种SIMD(Single Instruction Multiple Data,单指令多数据)架构,这种架构在进行4D矢量运算时效率最高,可以100%满负载执行而不浪费运算单元。
除了矢量运算,游戏中的标量运算也越来越多,执行1D标量计算时传统SIMD架构的利用率就只有原来的25%,这将带来不可避免的效能降低。AMD之前也采取过变通手法,将4D矢量改为3D矢量+1D标量运算,NVIDIA的G70中除了3D+1D组合之外还有2D矢量+2D标量的运算方式。随着DX10中统一渲染单元的到来,SIMD架构的缺陷日益显现,厂商需要新的架构设计。
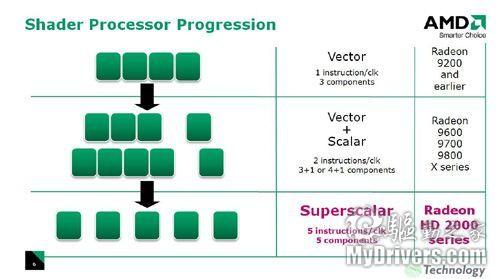
AMD将传统的4D矢量运算改良为4D+1D架构
AMD的解决方法是将原有的4D矢量运算拓展到4D矢量+1D标量架构,并命名为Supersclar(超标量),而4D+1D的运算架构也一直使用至现在的DX11显卡上。AMD的Supersclar架构在一个周期内可以进行5次矢量运算或者一次标量+一次矢量运算,而且5D指令只需要一个发射端口,每个流处理器所需的晶体管较少,设计难度也大大减小,缺陷依然是遇到标量运算时效率降低,AMD通过大幅增加流处理器单元的数量并增加分支预测单元(Branch Execution Unit)改善指令分配问题,在驱动设计上要付出更多努力。
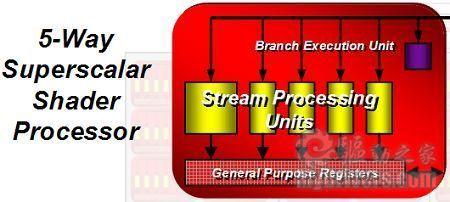
AMD的Superscalar架构沿用至今
与AMD的循序渐进相比,NVIDIA的解决方式更有革命性。NVIDIA的首款DX10架构G80中使用了标量设计,所有运算不管是4D矢量、3D+1D、2D+2D或者1D标量全都转为标量计算,这样标量运算中效率一直为100%,不过矢量运算中也存在着效率下降的问题,因为G80一个周期内只能执行一次运算,执行4D矢量需要四个周期才能完成。NVIDA采用异步架构将流处理器的频率与核心频率分离,流处理器的频率大幅提升至1.3G以上,几乎达到了核心频率的两倍,即使是4D矢量运算速度也有保证。
NVIDIA的标量流处理器无异于一次突破,此后的游戏以及通用计算程序中证明了此架构的优秀。除了频率提高一倍的流处理器弥补了数量上的劣势外,最主要的还是全标量架构的高执行效率,G80中每个指令都可以1D标量进行运算,利用率可以一直保持在100%,而AMD的4D+1D架构需要将指令组合成适合5D运算的VLIW(超长指令)才能保证充分利用所有流处理器,一旦重组不成功或者指令不适合重组,那就无法发挥出流处理器数量众多的优势,因此AMD显卡的理论浮点运算能力非常强劲,但在实际应用中相比NVIDIA的显卡并不突出,甚至有所不如,从Folding@home中的贡献排名中也一窥而知。
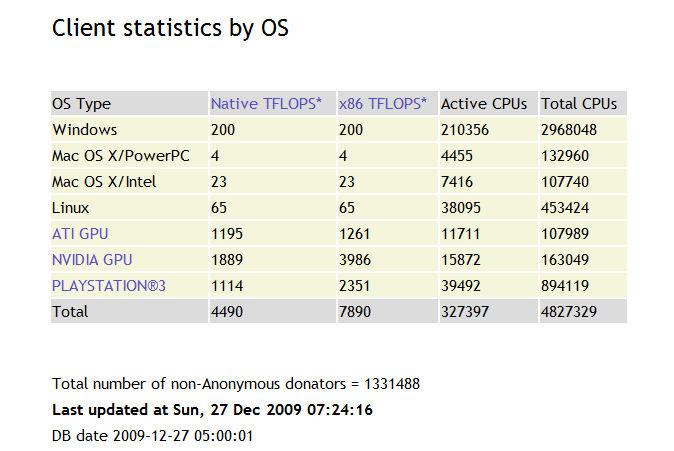
截至今年12月27日的Folding@home贡献度排名
上述有关A、N架构设计的不同只是一个方面,有关两家在具体架构设计上的差异之处还有许多,总体来看AMD直到目前为止的DX11显卡依然延续了R600开创的4D+1D超标量结构,但是设计难度较小,可以通过新工艺大幅提高sp单元数量来获得性能提升,而NVIDIA则走了另一条路,1D标量流处理器执行效率高,异步分频也可以弥补数量上的损失,实际效果也非常好,但要面临设计负责、成本高昂的难题。除了游戏方面的应用,高效率的1D标量设计还有助于NVIDIA实现GPGPU通用计算,这也是NVIDIA近两年来一直在谋划的新战略。

本文收录在
#快讯
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...