正文内容 评论(0)

2006年的11月份,NVIDIA首先推出了支持DX10规范的新一代显卡,首批显卡包括定位旗舰的GeForce 8800 Ultra(定价800-1000$)、高端的GeForce 8800 GTX(599$)以及次高端的GeForce 8800 GTS(399-499$),这三款显卡全部基于NVIDIA的G80架构,率先支持了DX10规范(与当前的情景有几分相像)。
G80架构的成功是NVIDIA近三年最为得意的资本之一,即便是当前的中低端显卡也受益于G80衍生出的G92/G94架构,由8800 GTX工艺升级而来的9800 GTX再到现在的GTS 250酣战了对手三代显卡,直到现在仍是玩家的最佳选择之一。G80架构能够实现这一切都要归功于当时架构设计的优异,NVIDIA放弃了以往显卡的矢量运算单元,改用复杂但是效率更高的标量运算。
前面已经提到AMD与NVIDIA在流处理器设计思路上的不同,DX10规格了统一渲染单元的功能,但是如何具体实现统一渲染功能可由厂商定夺。AMD沿用了传统的SIMD架构,坚持4D+1D的运算方式,每个流处理器的设计方式也很简单,同时也可以大幅提高流处理器单元的数量。G80则革命性地使用了MIMD指令架构,内部单元完全针对1D标量设计,执行1D、2D、3D指令效率很高,代价则是设计复杂,晶体管规模庞大而成本高昂。
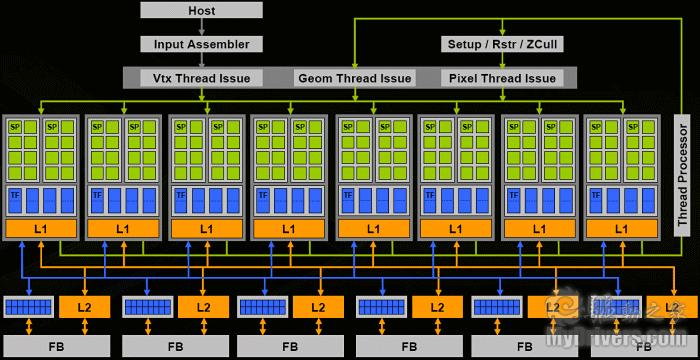
G80架构设计图
G80架构拥有128个流处理器(以下简称sp)、64个纹理单元和24个光栅单元,由8个阵列组成,每个SM单元拥有16个sp和8个纹理单元。每阵列中的sp单元也分为两组,每组8个sp,这8个sp也被称为一组streaming multiprocesser(简称SM)单元。每一个阵列都拥有独立的8个纹理过滤单元(Texture filtering unit,TF)、4个纹理寻址单元(Texture address unit,TA)以及L1缓存。详细结构如下:
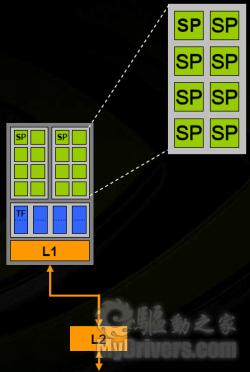
每阵列的详细结构
在有关G80显卡的分析与测试中,大家对其游戏性能更为关注,G80显卡也在这点上交出了满意的答卷。不过游戏应用并非全部,殊不知NVIDIA在推出G80之际也推出了名为CUDA(Compute Unified Device Architecture)的GPU通用计算环境技术,除了最早发布的8800 Ultra/GTX只支持CUDA 1.0,其余衍生出的核心则可以支持CUDA 1.1,以此类推的GT200架构支持CUDA 2.x,最新的Fermi将会支持CUDA 3.x。
有关显卡的通用计算并非NVIDIA首创,在此之前已经有许多公司尝试过,就连老对手ATI在Folding@Home项目上都比NVIDIA起步要早,但在DX10统一渲染器出现之前显卡通用计算技术的发展一直处于较低水平,流处理器的出现使其有了充当CPU的可能,而在支持环境上,CUDA的出现解决了软件开发环境的问题。
G80架构身上还有另外一个第一一首次支持C语言的显卡架构,而CUDA的核心其实就是一个C语言编译器,程序员无需学习额外的编程语言,直接使用他们熟知的C语言编程,通过CUDA的编译即可直接调用GPU硬件资源,而在此之前的GPU通用计算,程序必须映射到GPU能够处理的DX或者OpenGL这样晦涩难懂的API才能“骗”过GPU执行通用计算。换言之,CUDA的出现降低了GPU开发的门槛,借助GPU强大的浮点运算能力,开发者可以用标准的C语言编程实现CPU也无法企及的大规模并行计算。
很快NVIDIA就发布了Tesla品牌,借助G80架构的通用计算能力进军HPC高性能计算机市场,抢占传统CPU服务器的领地。

本文收录在
#快讯
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...