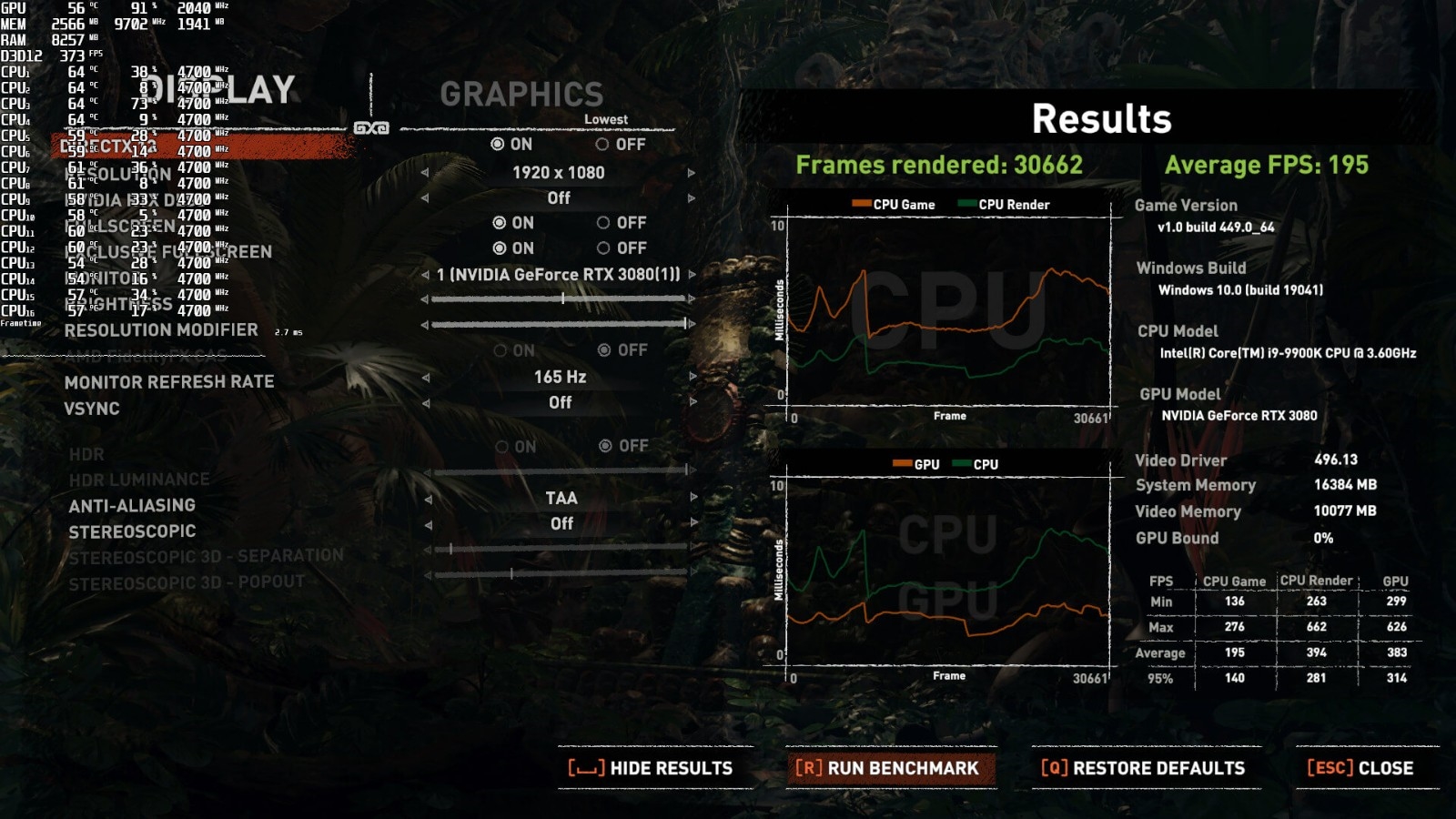
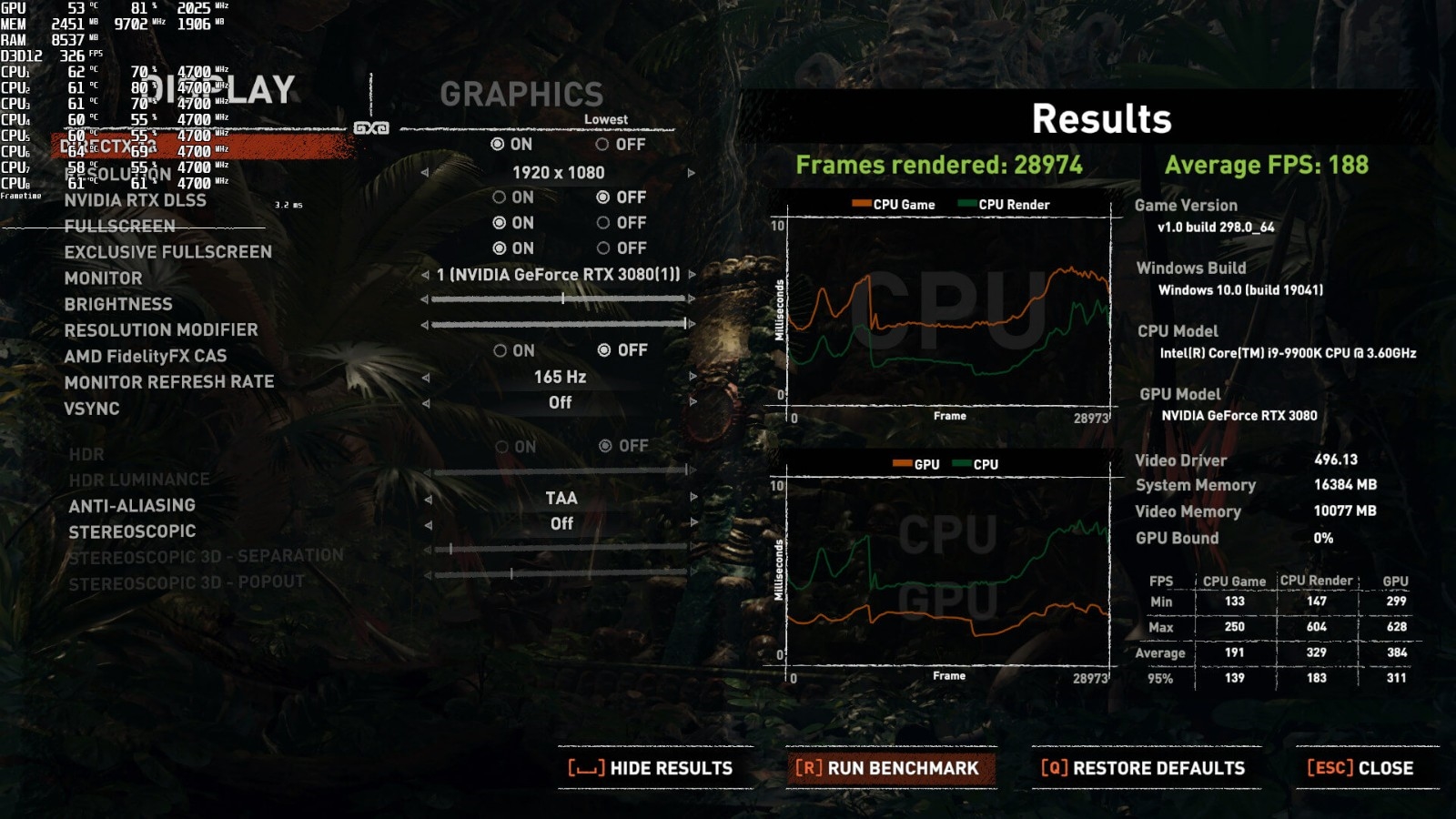
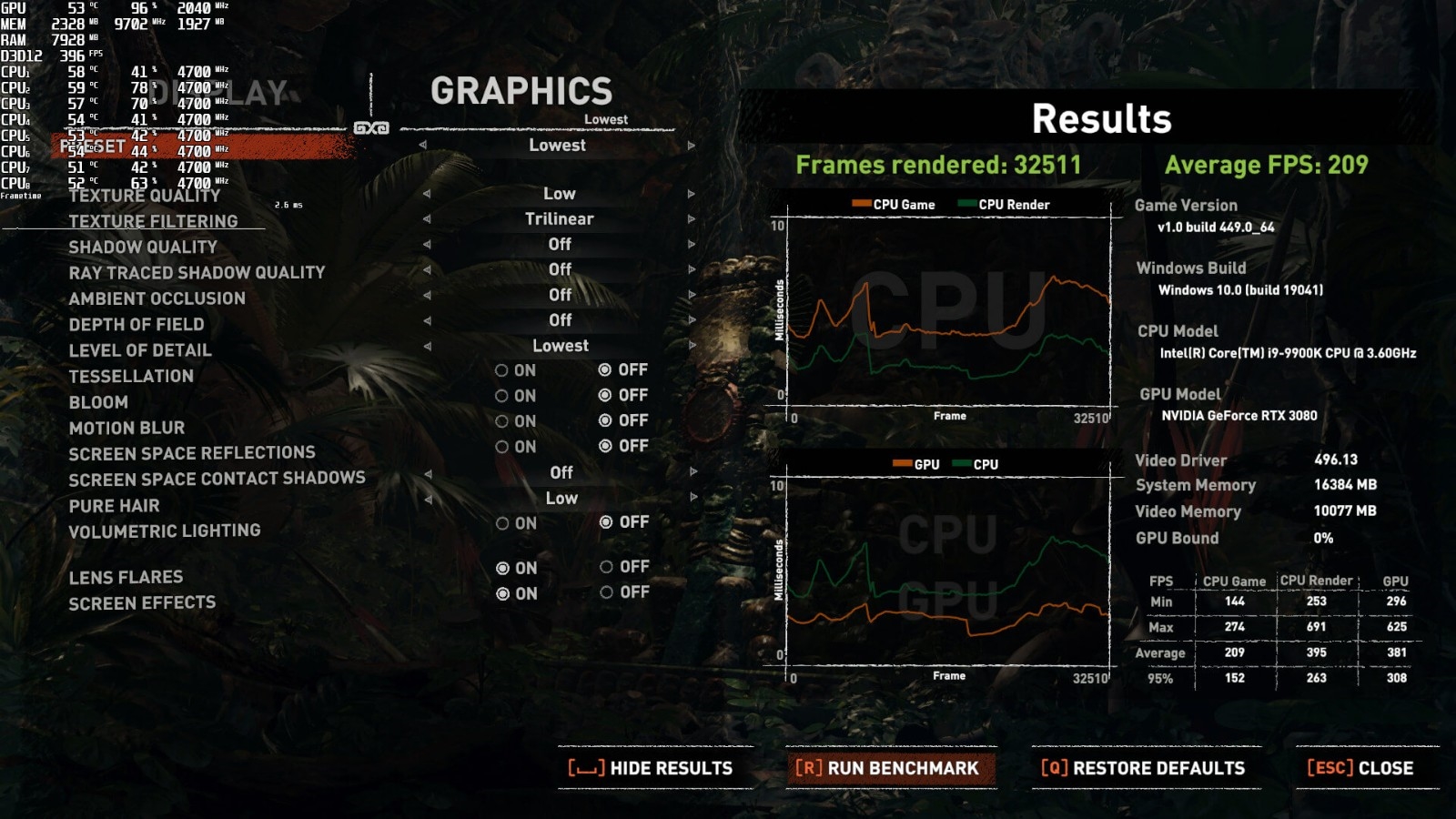
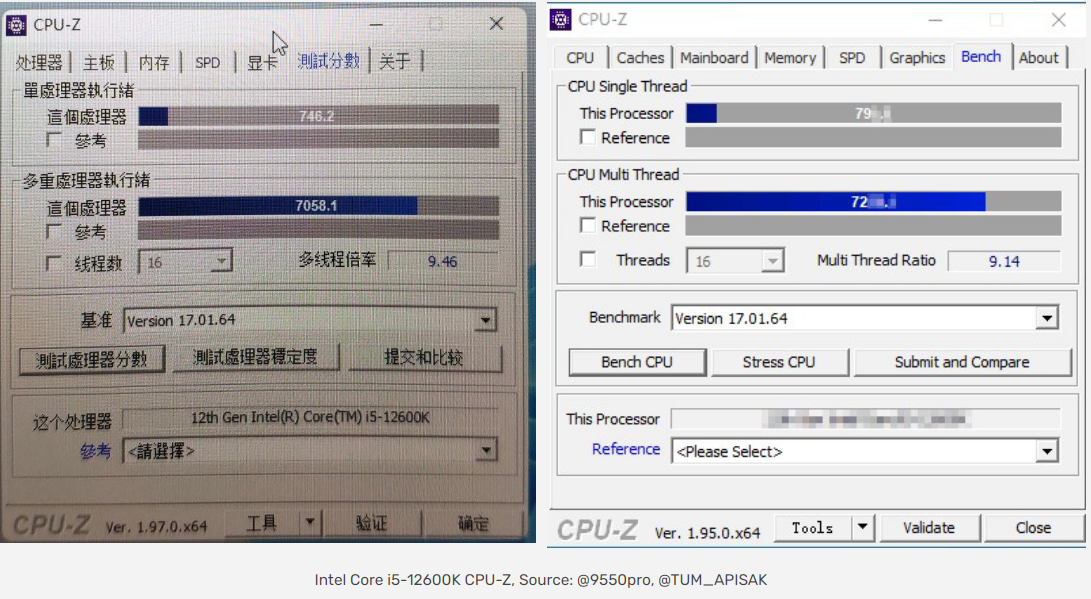
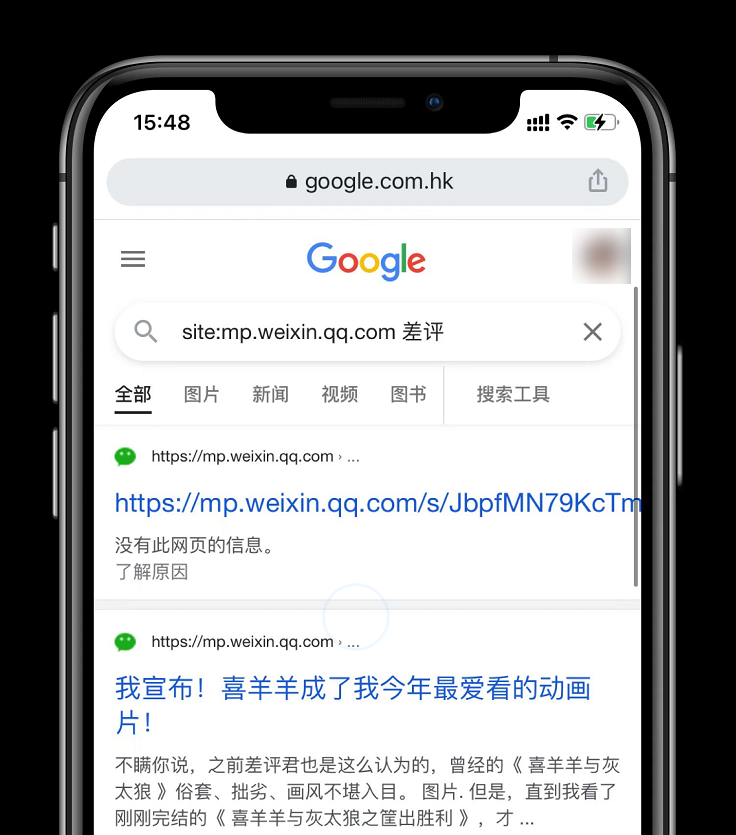
ЧАЬьЪРГЌПДЕНвЛИіЬћзгЫЕЃЌ дк Google КЭ Bing ФмЫбЕНЮЂаХЙЋжкКХЕФЮФеТСЫЁЃ
ХоЃЌдѕУДПЩФмЁЃ
ЪРГЌвЛБпВЛаХЃЌвЛБпИЯНєФУ Google ВтЪдСЫвЛЯТЃЌЗЂЯжВюЦРЕФЮФеТШЗЪЕгаБЛЪеТМНјШЅЁЃ
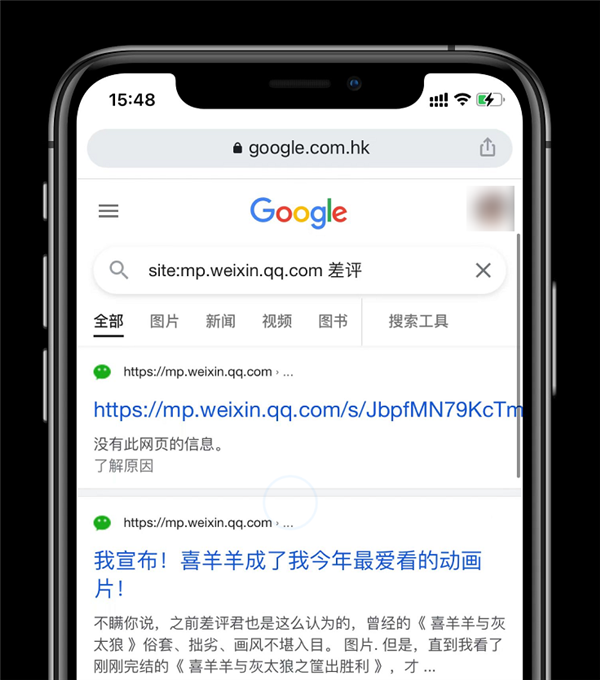
рыЃЌвЊетбљЯТШЅЃЌдкАйЖШРяЫбЮЂаХЮФеТЪЧВЛЪЧвВПьСЫЃП
ЯыБиГ§СЫЪРГЌЃЌКмЖрЭјгбгІИУЖМЭІЦкД§етМўЪТЕФЁЃБЯОЙгаЪБКђЫбзЪСЯЃЌдкАйЖШКЭЮЂаХжЎМфЧаРДЧаШЅЛЙЭІТщЗГЕФЁЃ
ЫЯыЕНЪРГЌЛЙУЛРжКЧЙЛЃЌЬкбЖТэЩЯОЭБйвЅСЫЃК
ЪЧЙЋжкКХЕФ robots авщГіЯжТЉЖДЃЌШУЫбЫїЦНЬЈЕФХРГцХРЕНСЫЃЌЯждквбОаоИДСЫЁЃ
уЃЌИуАыЬьАзИпаЫвЛГЁЁЃ
ВЛЙ§ЃЌНёЬьЪРГЌЛЙЪЧЯыОЭетИі robots авщКЭДѓМвЬНЬжвЛЯТЁЃ
вђЮЊЫЕЦ№РДФуПЩФмВЛаХЃЌЮвУЧдкАйЖШРяЧАЫбВЛЕНЙЋжкКХЮФеТЃЌКѓЫбВЛЕНЬдБІЩЬЦЗЃЌЖМЪЧвђЮЊ robots авщЁЃ
robots авщЦфЪЕКмМђЕЅЃЌОЭЪЧвЛИіЗХдкЭјеОИљФПТМЕФЮФБОЃЌЫќаДУїСЫЫбЫїв§ЧцПЩвд/ВЛПЩвдЪеТМФФаЉаХЯЂЁЃ
ЮЂаХЙЋжкКХЕФ robots авщ Ј

гаШЫПЩФмЛсЫЕЃЌдРДОЭЪЧетМИаазжКІЕУЛЅСЊЭјВЛФмЛЅСЊСЫЃПВЛВЛЃЌетЙј robots авщПЩВЛБГЁЃ
robots авщдБОжЛЪЧАяжњЫбЫїв§ЧцИќИпаЇЕиЪеТМаХЯЂЃЌжЛВЛЙ§ЯждкШЫУЧгУзХгУзХж№НЅБфСЫЮЖЁЃ
етЪТЛЙЕУДгЩЯЪРМЭ 90 ФъДњГѕЦкЫЕЦ№ЁЃ
дкЫбЫїв§ЧцЕЎЩњжЎЧАЃЌШЫУЧвЊВщзЪСЯЃЌжЛФмвЛИіИіНјШыЯрЙиЭјвГЃЌаЇТЪЗЧГЃЕЭЯТЁЃ
КѓРДгаСЫЫбЫїв§ЧцЃЌЫбЫїв§ЧцЭЈЙ§ЪЭЗХЭјТчХРГцЃЈ вВПЩвдНажЉжы ЃЉЃЌзЅШЁИїИіЭјвГРяЕФаХЯЂЃЌВЂАбетаЉаХЯЂЪеТМЦ№РДЙЉДѓМвВщбЏЃЌетВХМЋДѓЬсИпСЫШЫУЧЕФаЇТЪЁЃ
ЕЋЪЧЃЌФЧЛсХРГцОЭИњаЁКкХжвЛбљЃЌзЅШЁаХЯЂРДЭъШЋВЛЬєЪГЁЃ
ВЛЙмЪЧУЛгУЕФРЌЛјаХЯЂЃЌЛЙЪЧЭјеОживЊЕФФкВПЪ§ОнЃЌВЛЗжЧрКьдэАзЕивЛЖйТвзЅЃЌШЋЖМвЊЁЃ
етжжДжБЉЕФзЅЗЈВЛНіНЕЕЭСЫгУЛЇЫбЕНгагУаХЯЂЕФаЇТЪЃЌЛЙЛсШУЭјвГЕФживЊЪ§ОнаЙТЖЃЌЗўЮёЦїЙ§диЮоЗЈдЫааЁЃ
Ыљвддк 1994 ФъГѕЃЌКЩРМгаЮЛЭјТчЙЄГЬЪІЬсГіСЫ robots авщЁЃ
ОЭКУБШБіЙнЗПМфУХЩЯЙвзХЕФ“ ЧыЮ№ДђШХ ”ЃЌ“ ЛЖгДђЩЈ ”ХЦзгЃЌИцЫпАЂвЬФФаЉЗПМфЪЧПЩвдДђЩЈЕФЁЃ
УПИіЭјеОЕФИљФПТМЯТвВАкзХвЛЗн robots авщЃЌавщРяИцЫпХРГцЃКФФаЉЖЋЮїФуПЩвдзЅЃЌФФаЉЖЋЮїФуВЛФмзЅЁЃ
ЫфЫЕетИі robots авщФПЧАЛЙУЛБЛШЮКЮЙњМЪзщжЏВЩФЩЃЌУЛгажЦдМадЃЌжЛФмЫуИіО§згавщЃКФуВЛЬ§ЃЌОЭВЛЪЧИіе§ШЫО§згЁЃ
ЕЋЫќБЯОЙЮЊСЫАяжњЫбЫїХРГцИќгааЇЕизЅШЁЖдгУЛЇгагУЕФаХЯЂЃЌИќКУДйНјаХЯЂЙВЯэЁЃЫљвддкЙњЭтВЛЙмЪЧдчЦкЕФ altavista ЛЙЪЧКѓРДЕФ Google ЁЂБигІЃЌДѓМввВЖМзёЪизХетвЛЬзавщЁЃЭЌбљ 2012 Фъ 11 дТжаЙњЛЅСЊЭјаЛсЗЂВМСЫЁЖ ЛЅСЊЭјЫбЫїв§ЧцЗўЮёздТЩЙЋдМ ЁЗЃЌвВЙцЖЈСЫЃКЫбЫїв§ЧцвЊзёЪиЭјеОЕФ robots авщЃЌЕЋЧАЬсЪЧетИі robots авщЪЧКЯРэЕФЁЃ

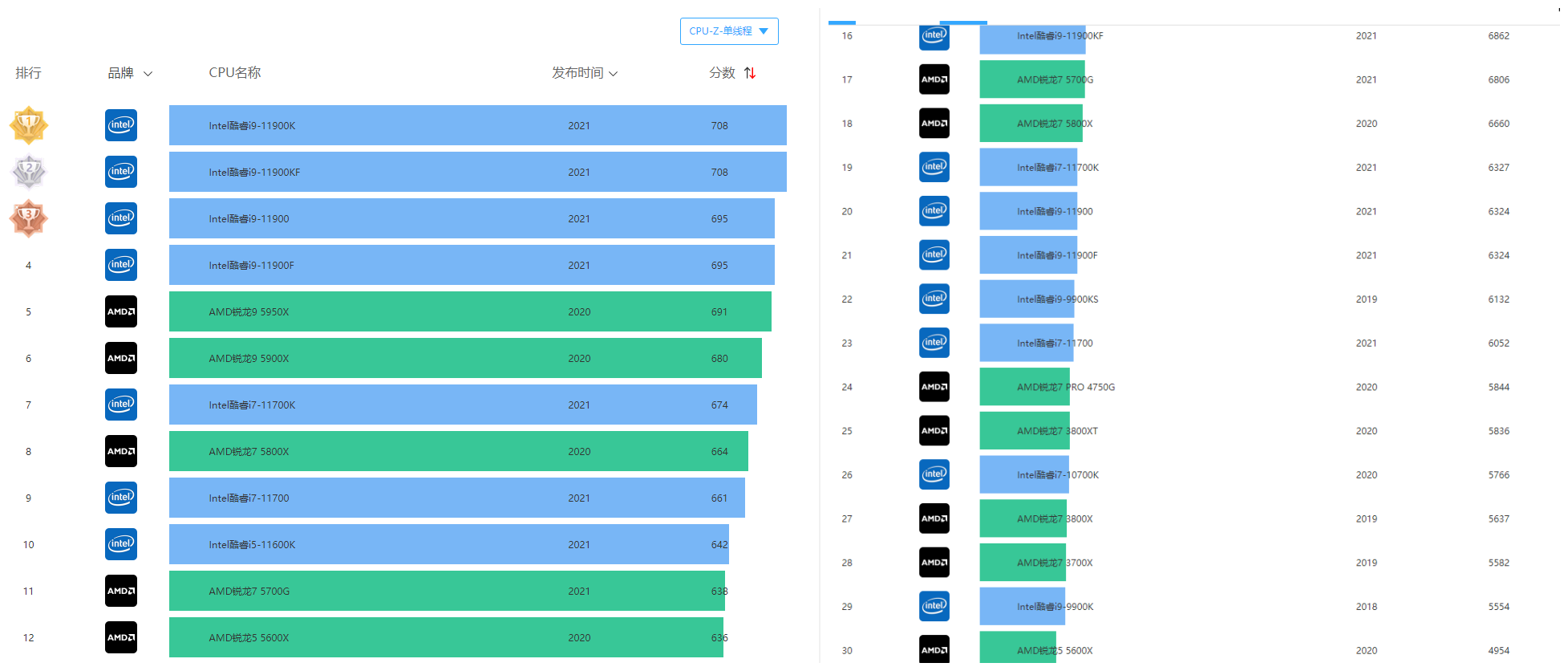
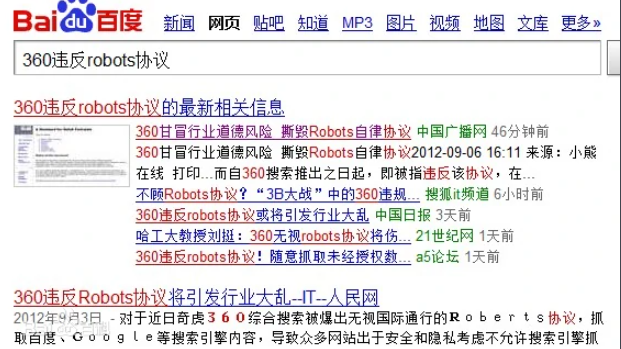
етИіЙЋдМЖд 12 МвЗЂЦ№ЕЅЮЛЩњаЇЃЌГЩдБАќРЈАйЖШЁЂЬкбЖЁЂЦцЛЂ 360ЁЂЫбЙЗЁЂЭјвзЁЂаТРЫЕШЁЃЭМдДАйЖШАйПЦ Ј

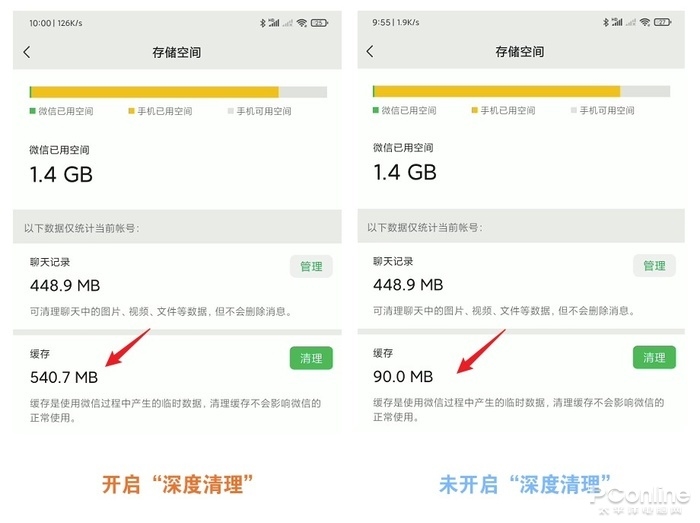
ШчНёОјДѓЖрЪ§ЫбЫїв§ЧцЕФХРГцдкЗУЮЪЭјеОЪБЃЌЕквЛМўЪТОЭЯШЖСЯТЭјеОЕФ robots авщЁЃдкСЫНтФФаЉаХЯЂЪЧПЩвдзЅШЁжЎКѓЃЌВХЛсааЖЏЁЃБШШчЬдБІЕФ robots авщЃЌЫфШЛжЛгаМђЕЅЕФ 4 аазжЃЌЕЋаДУїСЫЃКАйЖШХРГцЃЈ Baiduspider ЃЉВЛдЪаэЃЈ Disallow ЃЉзЅШЁШЮКЮФкШнЃЈ / ЃЉЁЃАйЖШХРГцЙ§РДПДЕНавщКѓЃЌОЭЫуаФРяФбЪмЃЌвВжЛФмЩЖвВВЛХіТэЩЯРыПЊЁЃ
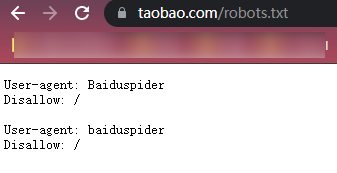
ФЧПЩФмгаШЫЫЕЃЌетМШШЛЪЧО§згавщЃЌЛсВЛЛсгаШЫВЛЕБ“ О§зг ”ФиЃПЕБШЛгаЃЌrobots авщжЛЯрЕБгквЛИіИцжЊЪщЃЌХРГцЃЈ БГКѓЕФШЫ ЃЉПЩвдВЛЬ§ФуЕФЁЃКЭДѓМвЫЕСНИіЮЅБГ robots авщЕФР§згЁЃЕквЛИіР§згЪЧ BE КЭ eBay ЕФОРЗзЁЃ
BE ЪЧвЛИіЬсЙЉХФТєаХЯЂЕФОлКЯЭјеОЁЃЫќРћгУХРГцзЅШЁ eBay ЕШХФТєЭјеОЕФЩЬЦЗаХЯЂЃЌШЛКѓЗХдкздМКЭјеОЩЯзЌШЁСїСПЁЃОЁЙм eBay дчвбаДКУСЫ robots авщЃЌИцЫп BE ХРГцВЛзМзЅШЁШЮКЮФкШнЁЃЕЋ BE ШЯЮЊетРрХФТєаХЯЂЖМЪЧДѓжкЩЯДЋЕФЃЌeBay ЩшжУ robots авщВЛШУздМКзЅШЁЃЌВЛКЯРэАЁЁЃ
КѓРДЗЈдКОЙ§ЖрЗНЕїВщШЁжЄЃЌШЯЮЊ ebay ЭјеОЩЯФкШнЪєгкЫНгаВЦВњЃЌЫќгУ robots авщБЃЛЄЫНгаВЦВњЪЧКЯРэЕФЁЃзюКѓШЯЖЈ BE ЧжШЈЁЃЯыБиДѓМвФмПДГіРДЃЌЗЈдКХаЖЈНсЙћВЂВЛЪЧЕЅДППДгаУЛгаЮЅБГrobots авщЃЌзюжївЊЛЙЕУПДетИі robots авщКЯВЛКЯРэЁЃ

ЭЌбљЃЌЛЙгаИіР§згвВжЄУїСЫетЕуЁЃДѓВПЗжШЫЖМжЊЕР 3Q ДѓеНЃЌЕЋПЩФмУЛЬ§Й§ 360 КЭАйЖШЕФ“ 3B ДѓеН ”ЁЃ
2012 Фъ 8 дТ 360 ЫбЫїИеЩЯЯпЃЌЫќзЅШЁСЫАйЖШЦьЯТЕФФкШнЃЈ АйЖШжЊЕРЃЌЬљАЩ ЃЉВЂвдПьееЕФаЮЪНЬсЙЉИјгУЛЇЁЃЕЋЪЧЃЌАйЖШЕФ robots авщаДУїСЫжЛгаВПЗжЫбЫїв§ЧцПЩвдзЅШЁЃЌЕБжаУЛАќРЈ 360 ЫбЫїЁЃвВОЭЪЧЫЕ 360 ЮЅБГСЫАйЖШ robots авщЁЃ
ЭМдДАйЖШАйПЦ Ј
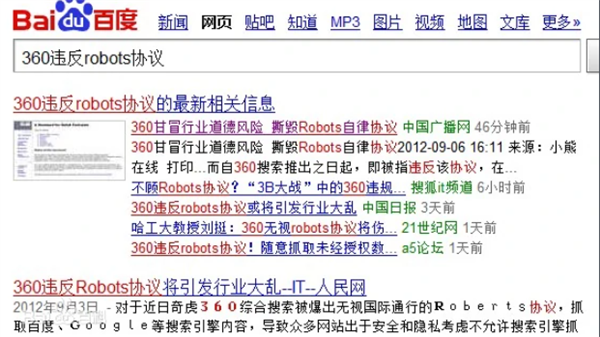
КѓРДАйЖШЯыСЫвЛИіЗЈзгЃЌжЛвЊдк 360 ЫбЫїжаЫбЕНАйЖШЯрЙиЭјеОЃЌЕуЛїКѓОЭЛсЬјзЊЕНАйЖШЫбЫїв§ЧцЭјеОЁЃдйЕНКѓРДЫћУЧФжЩЯСЫЗЈЭЅЁЃ
етМўЪТШЅФъВХЫуе§ЪННсАИЃЌХаОіЪщДѓИХгавЛЭђЖрзжАЩЃЌПЩАбЪРГЌПДСЫКУвЛЛсЁЃВЛЙмЪЧ 360 АбАйЖШПьееЬсЙЉИјгУЛЇЃЌЛЙЪЧАйЖШЕФЬјзЊДыЪЉЃЌетаЉВйзїЗЈдКЖМНјааСЫЯргІЕФХаОіЃЌЕЋЪЧИњЮвУЧЮФеТУЛЬЋДѓЙиЯЕЁЃЪРГЌжЛдкетРяЫЕЯТЃКЖдгк 360 ЫбЫїЮЅБГАйЖШ robots авщЕФзЅШЁааЮЊЃЌЪЧдѕУДХаЖЈЕФЁЃЪзЯШ 360 дк 2012 Фъ 8 дТЮЅБГ robots авщЪЧгаВЛКЯРэдкЯШЃЌЕЋЪЧЭЌФъ 11 дТЗЂВМСЫЁЖ здТЩЬѕдМ ЁЗЁЃ
ЬѕдМПЩЪЧЙцЖЈСЫ robots авщЯожЦЫбЫїв§ЧцЕУгае§ЕБРэгЩЃКБШШчЮЊСЫБЃЛЄУєИааХЯЂЁЂЙЋжкРћвцЛђепЮЌГжЭјеОе§ГЃдЫааЁЃЕЋАйЖШЯожЦ 360 ЫбЫїзЅШЁЕФФкШнЃЌМШВЛЪЧживЊУєИааХЯЂЃЌБЛзЅШЁСЫвВВЛЛсШУАйЖШВЛФмдЫааСЫЛђепЫ№КІСЫЙЋЙВРћвцЁЃЁЃ

етОЭПЩвдХаЖЈАйЖШУЛгае§ЕБРэгЩОмОј 360 зЅШЁЃЌ 360 ЕФзЅШЁааЮЊвВВЂЗЧВЛе§ЕБОКељааЮЊЁЃ

ЫљвдАЁЃЌВЛЪЧаДСЫ robots авщОЭвЛЖЈдкРэЃЌФуетИіавщЪзЯШЕУКЯРэВХааЁЃЕЋЙиМќЪЧЃЌетИіКЯРэЕФНчЯогаЪБКђВЛЪЧКмКУЖЈЁЃЁЃБШШчЯждкВЛЩйЛЅСЊЭјЙЋЫОгУ robots авщзшжЙЫбЫїв§ЧцЪеТМЃЌЯожЦСЫаХЯЂЗжЯэЁЃФуЫЕЫћУЧЪЧдкКЯРэЩшжУ robots вВУЛДэЃЌБЯОЙЪЧЮЊСЫБЃЛЄздМКЕФЪ§ОнШЈвцЁЃЕЋетЪЧВЛЪЧКЭЛЅСЊЭјЕФГѕждБГЕРЖјГлСЫФиЁЃЁЃ
ОЭФУЪРГЌздМКОРњРДНВЁЃжЎЧАаДИіЗДеЉЦЕФЮФеТЃЌАйЖШВщСЫДѓАыЬьзЪСЯВЛЙЛЃЌВюЕуЗХЦњЁЃКѓРДдкЮЂаХРяЫбЃЌВХдквЛМвЙЋжкКХЮФеТЩЯевЕНЯрЙизЪСЯЁЃзюКѓвЊевЪгЦЕзїЮЊЖЏЭМЫиВФЃЌЮвгжХмШЅЖЬЪгЦЕЦНЬЈЁЃЁЃвЊжЊЕРдјМИКЮЪБЃЌЮвУЧУїУїПЩвдКмЧсвзЕФВщбЏЕНаХЯЂЃЌЯждквђЮЊИїДѓЭјеОЕФ robots авщБфГЩСЫШчДЫРЇФбЁЃЁЃ
ИќЗэДЬЕФЪЧЃЌ robots авщдБОзіГіРДжЛЪЧЮЊСЫЬсИпХРГцаЇТЪЃЌИќКУЕиДйНјаХЯЂСїЖЏЕФЁЃЁЃетЪЧВЛЪЧгаЕуБфЮЖСЫЁЃЁЃ
|