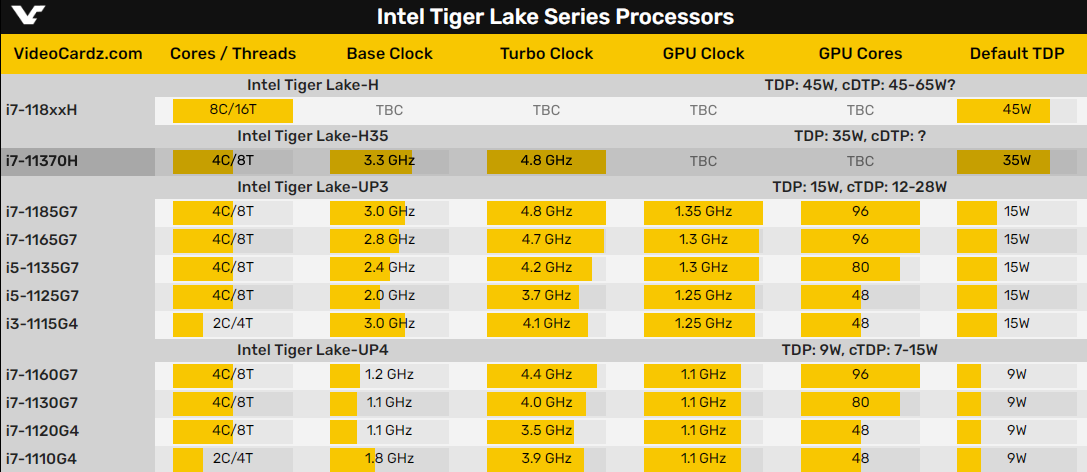
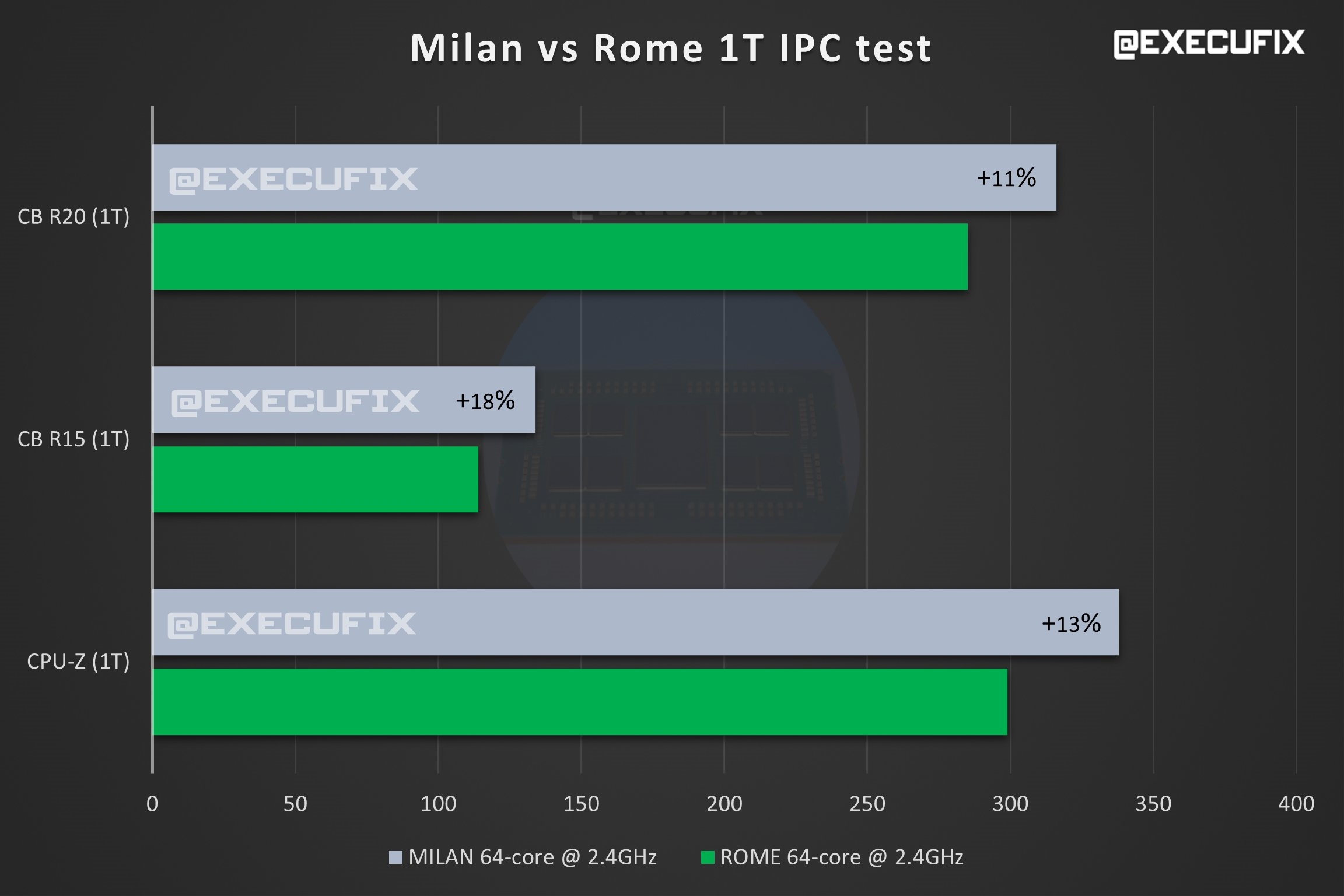
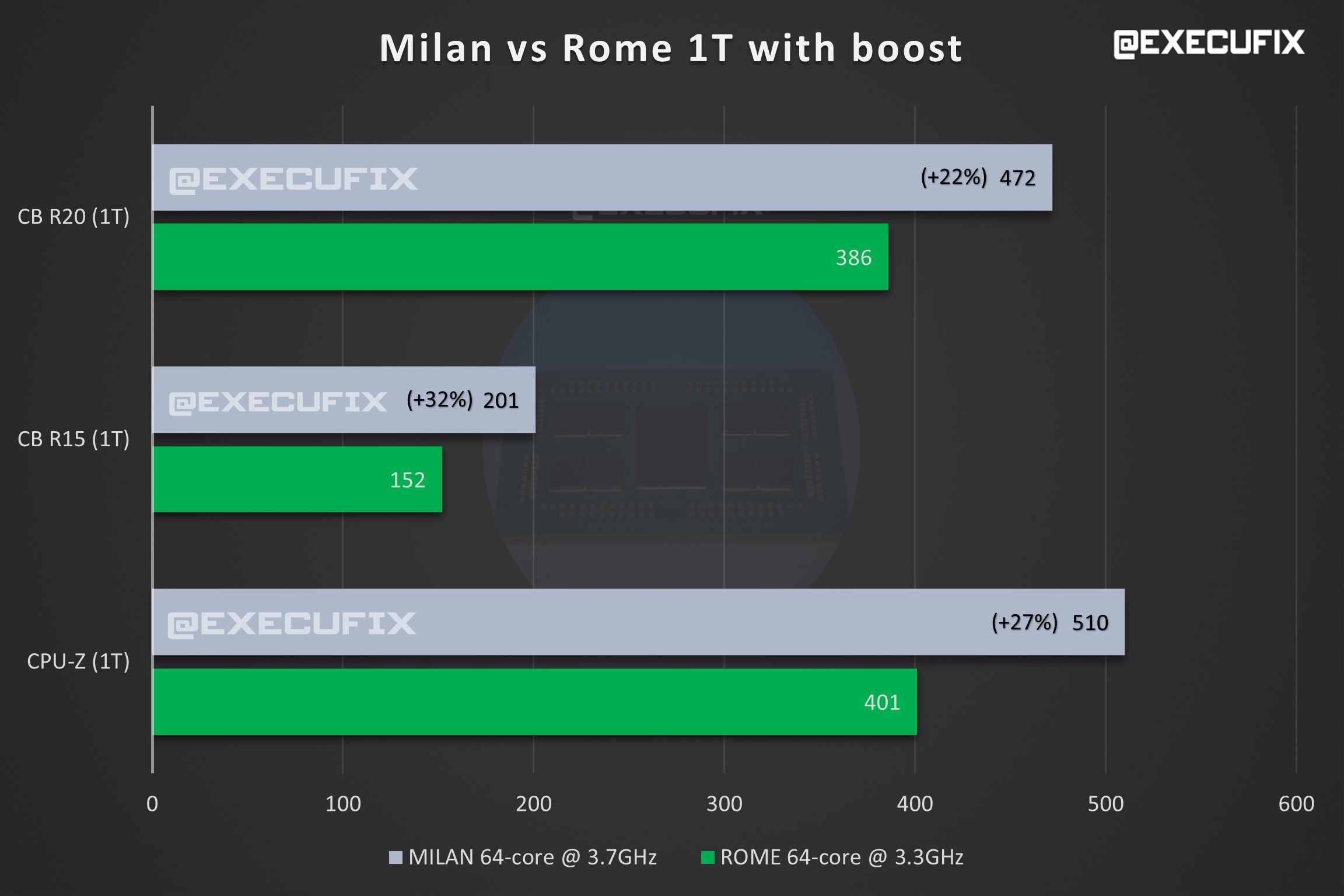
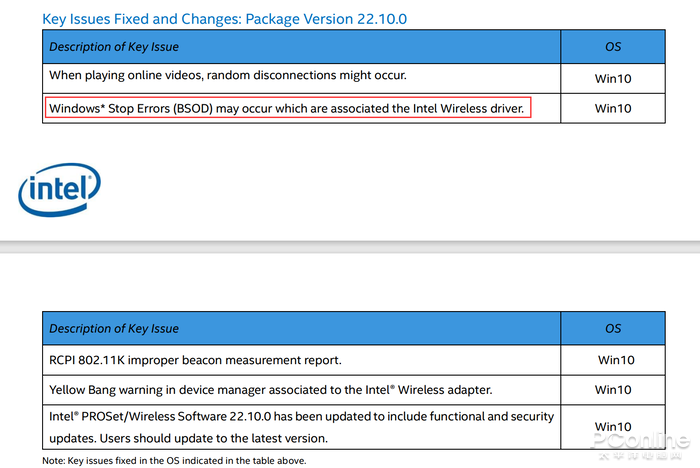
|
����GPU��������˵������һ�������ĵȴ��� NVIDIA��Turing��Ʒ��ά�������꣬Ȼ����2020��9����Ampereȡ��������AMD������һ�㣬���ǵ�����Ƽ����15���£���������˶Դ˲�������Ȥ��
����ϣ����������AMD�Ƴ�һ��߶˻��ͣ���NVIDIA(NVIDIA)������IJ�Ʒչ�����澺�������������ˣ����������Ѿ������˽�����ڻ�Ǯ����õ�ͼ�ο�ʱ��PC��Ϸ������ڣ��������ϣ����˺ܶ�ѡ��
�����������ǵ�оƬ��?����һ���Ӹ�������˵����һ������?��������ȥ������Ampere��RDNA 2����ξ�һ��ս��!
NVIDIA˥�ˣ�AMD�ɳ�
�ڵ��die�ߴ�
���������߶�GPUһֱ�� CPU��ö࣬�������ǵijߴ�һֱ���Ȳ�������AMD�����Ƴ���NaviоƬ���ԼΪ520mm2����֮ǰNaviоƬ�������ࡣ�������Ⲣ������������——����������������ǵ�Instinct MI100��������Լ750 mm2���е�GPU��
��һ��AMD����Ľӽ�Navi 21��С����Ϸ��������ΪRadeon R9 Fury��Nano�Կ���Ƶģ��������Ʒ��Fiji оƬ�ϲ�����GCN 3.0�ܹ���������Ƭ���Ϊ596 mm2����������̨�����28HP���սڵ��������ġ�
��2018��������AMDһֱ��ʹ��̨�����С��N7���գ������������������оƬ��Vega 20 (Radeon VII)�����Ϊ331mm2���������е�Navi GPU��������������N7P�������������ģ����Կ��ԱȽ���Щ��Ʒ��

Radeon R9 Nano���Ϳ�������GPU
��˵�������die�ߴ磬NVIDIA���������ڣ�������˵��һ���Ǽ����¡����µĻ���Ampere��оƬ��GA102����628mm2����ʵ���ϱ�����ǰ��TU102С��17%——GPU����ﵽ���˵�754mm2��
��NVIDIA���GA100оƬ(����AI����������)��ȣ�������оƬ�ijߴ綼���μ�穣���GPUΪ826 mm2�����õ���̨�����N7оƬ����Ȼ������û�б�����������������Կ�������ȷʵ��ʾ��GPU����Ŀ��ܹ�ģ��
�����Ƿ���һ��ͻ����NVIDIA����GPU�ж��Navi 21�������൱���������ܴ������Ĺ��ܲ�������оƬ����GA102��װ��283�ڸ�����ܣ���AMD����оƬ������5%���ﵽ268�ڸ���

���Dz�֪��ÿ��GPU�������ٲ㣬����������ܱȽϵ��Ǿ������die����ı��ʣ�ͨ����Ϊdie�ܶȡ�Navi 21�ľ����ԼΪÿƽ������5150�������ܣ���GA102���Ե���41.1���������NVIDIA��оƬ�ѵ��̶ȱ�AMD���Ըߣ����������ܱ�ʾ���սڵ㡣
��ǰ������Navi 21����̨���������ģ�����N7P�������������ܱ�N7�������;�����²�ƷGA102�ϣ�NVIDIA�������������������������Һ����뵼���ͷ����ʹ��������ν��8nm�ڵ�(���Ϊ8N��8NN)�ĸ����汾��ר��ΪNVIDIA��ơ�
��Щ�ڵ�ֵ��7��8����оƬ�����ʵ�ʳߴ�û�ж���ϵ:����ֻ���г�Ӫ������������ֲ�ͬ������������Ҳ����˵����ʹGA102��Navi 21�и���IJ㣬die�ߴ�ȷʵ��һ�������Ӱ�졣

һ̨300����(12Ӣ��)�ľ�ԲƬ����̨��������칤�����в��ԡ�
������������оƬ���ɸ߶Ⱦ����Ĺ�����������ƳɵĴ�Բ�̣���Ϊ��Բ��̨���������ΪAMD��NVIDIAʹ�õ���300����Բ������ڸ����die��ʹ�ø�С��die��ÿ�龧Բ�����������оƬ��
���ֲ��첻���ܴܺ����ڽ�������ɱ����棬��ÿƬ��Բ�������ɱ��ﵽ��ǧ��Ԫʱ��AMD�����NVIDIA�������ƽ�С�� ��Ȼ�����Ǽ������ǻ�̨����û����AMD / NVIDIA����ij�ֲ����ס�
���оƬ�������ܺܺõ������ƹ�������ô������Щdie�ߴ�;��������������ͽ�͵ġ� ��ˣ������������о�ÿ����GPU�IJ��֣��������DZ���Ķ�����
����die
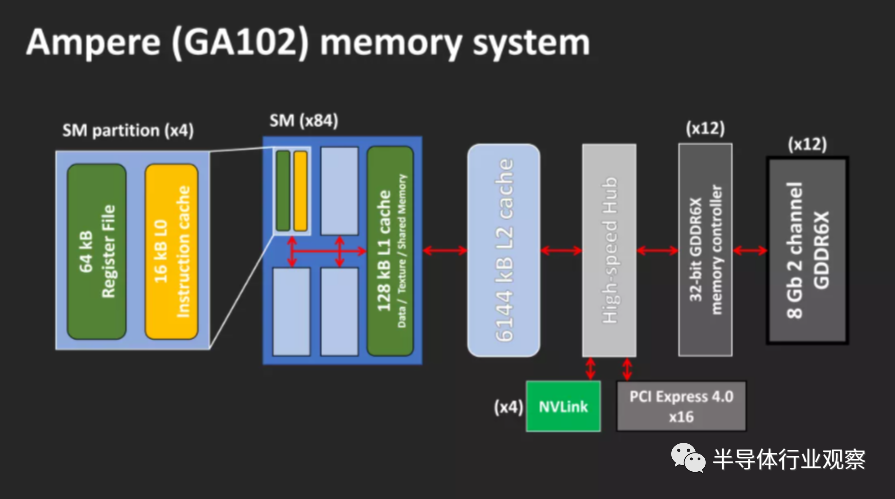
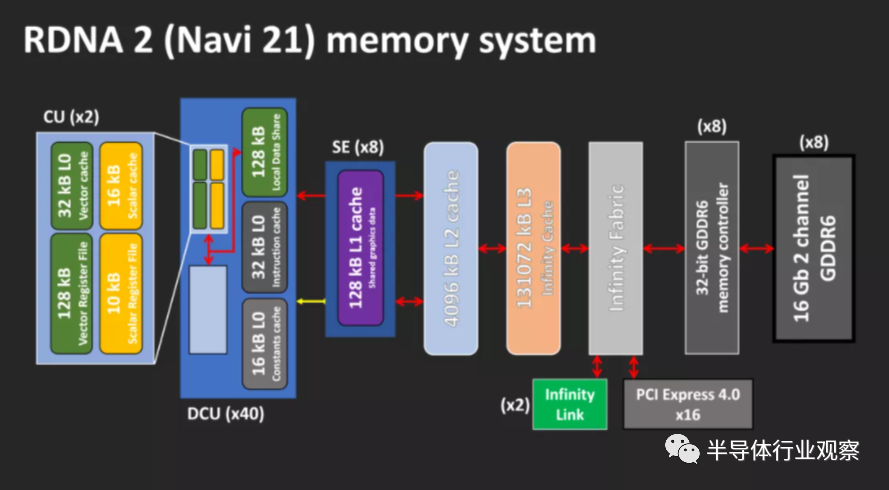
Ampere GA102��RDNA 2 Navi 21������ܹ�
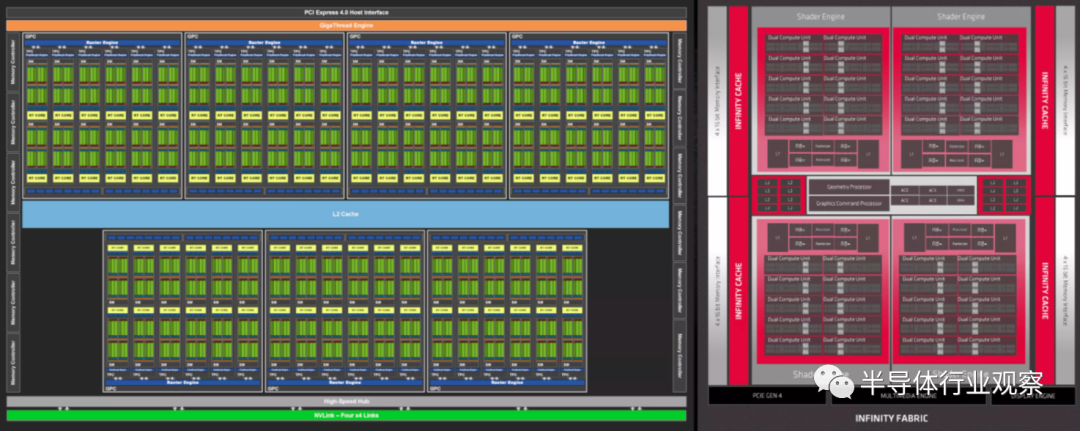
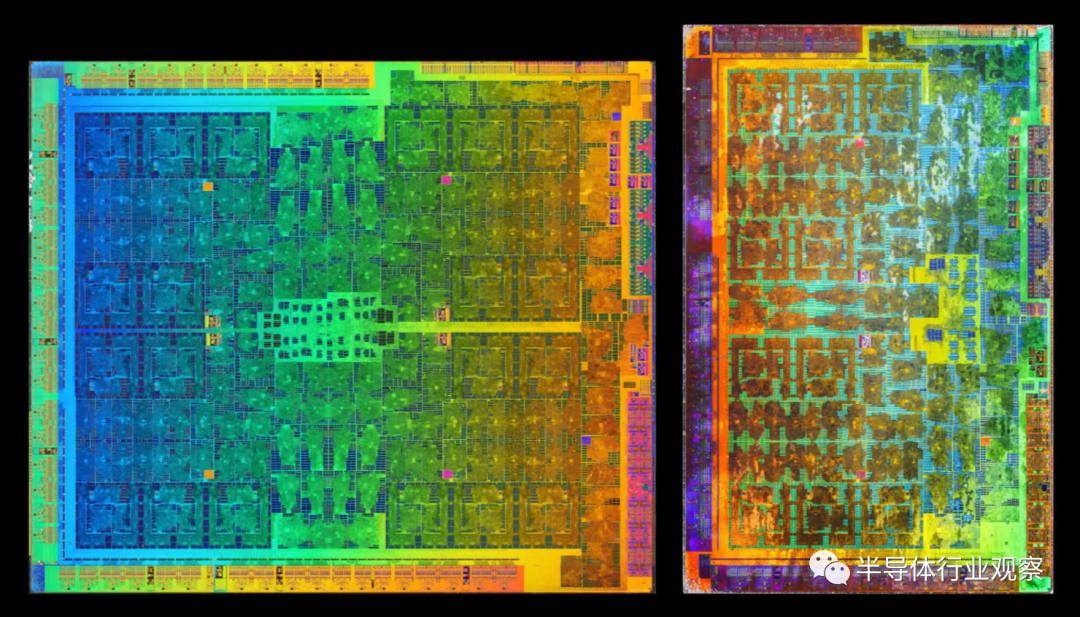
���Ǵӷ���Ampere GA102��RDNA 2 Navi 21 GPU������ܹ���ʼ���ǶԼܹ���̽��——��Щͼ����һ��������չʾ���е��������֣������Ǹ����˴������ж����������ȷָʾ��
������������£����ֶ��Ƿdz���Ϥ�ģ���Ϊ���ǻ����϶�����ǰ������չ�汾���ڴ���ָ�������Ӹ���ĵ�Ԫ��ʼ�����GPU�����ܣ���Ϊ�����µ�3D��Ƭ�У��ڸ߷ֱ����£���Ⱦ�������漰�����IJ��м��㡣
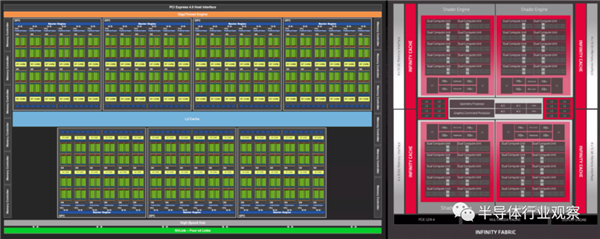
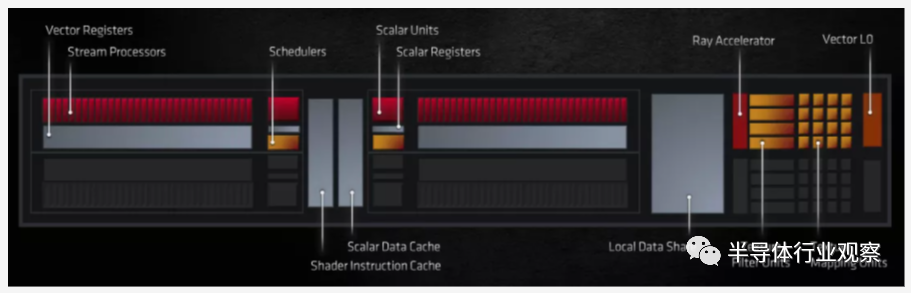
������ͼ�������õģ����Ƕ�������ض��ķ�����˵������Ȥ���ǿ������������GPU�е�λ�á�����ƴ��ʹ�����ʱ����ͨ��ϣ��������Դ����������ͻ��棩λ������λ�ã���ȷ��ÿ�������������ͬ��·����
�ӿ�ϵͳ���籾���ڴ����������Ƶ�����Ӧ�ð�װ��оƬ�ı�Ե���Ա�����ؽ��������ӵ�����GPU���Կ����ಿ�ֵ���ǧ�������ĵ����ϡ�
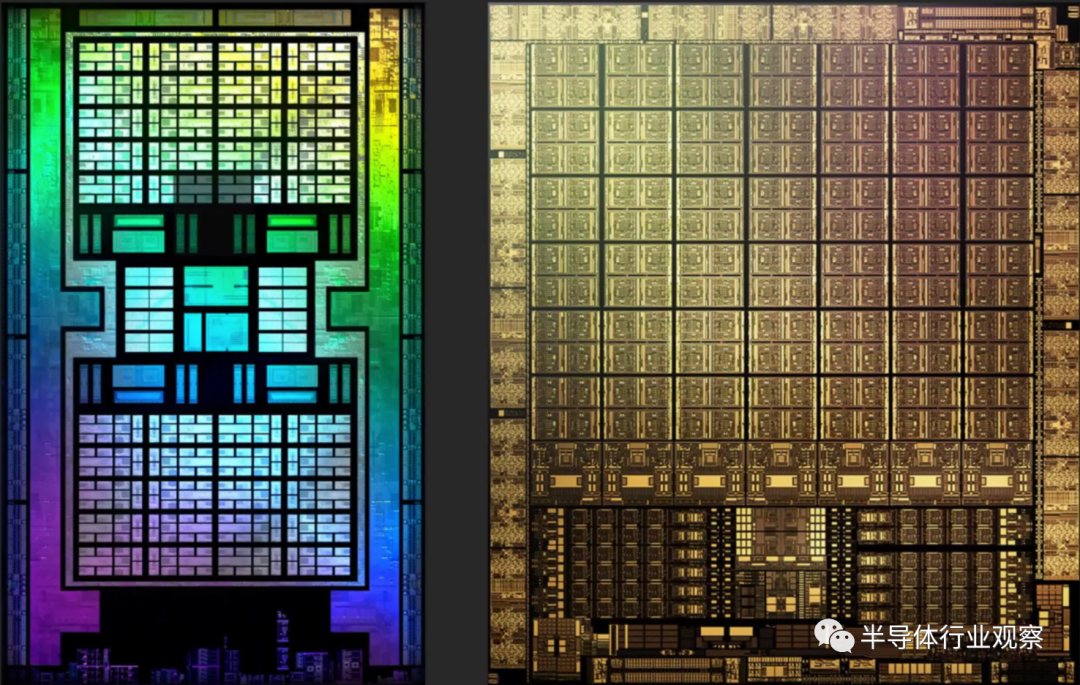
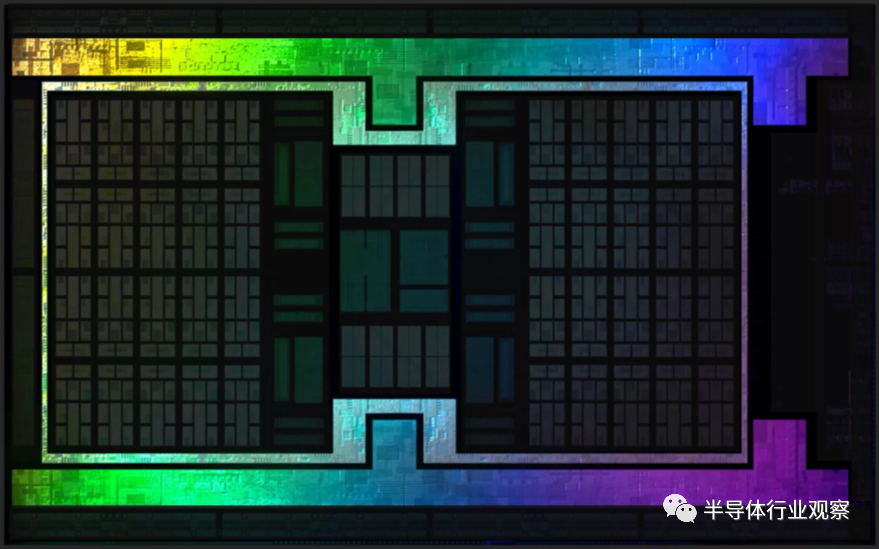
������AMD��Navi 21��NVIDIA��GA102 die��α��ɫͼ�� ����ʵ����ֻ��ʾ��оƬ�е�һ�㣻������ȷʵ�������ṩ��һ���ִ�GPU�ڲ��ļ�����ͼ��
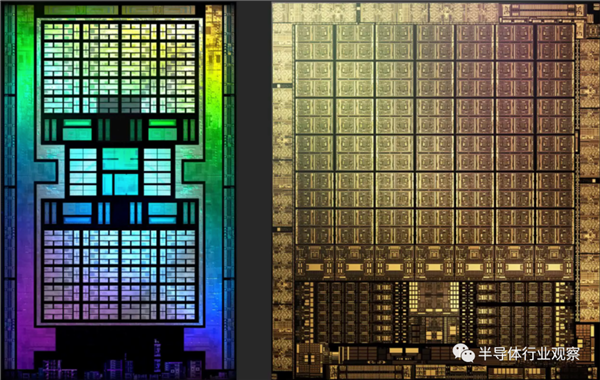
�������֮�������Ե��������ڣ�NVIDIA��оƬ������û����ѭ���л��ķ���——���е�ϵͳ�������������涼�ڵײ�������Ԫ�Գ�����ʽ���С����ǹ�ȥҲ������������ֻ����еͶ˻��͡�
���磬Pascal GP106������GeForce GTX 1060�ȣ�ʵ������GP104������GeForce GTX 1070����һ�롣 �����ǽϴ��оƬ���仺��Ϳ�����λ���м䡣 ��Щ���Ƶ��������ֵܽ�����һ�ߣ�����ֻ����Ϊ����Ѿ�������ˡ�
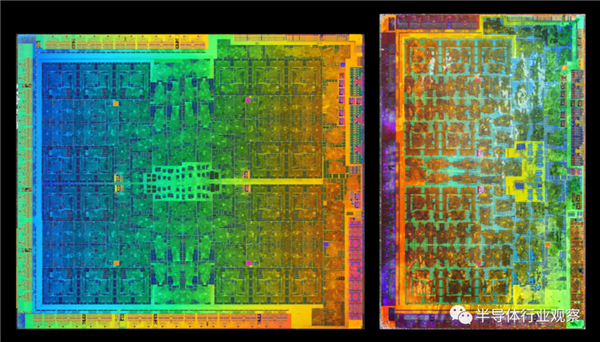
����֮ǰ���еĸ߶�GPU���֣�NVIDIA��ʹ���˾���ļ���ʽ�ṹ��Ϊʲô������б仯��?�ⲻ���������ڽӿڵ�ԭ����Ϊ�ڴ��������PCI Expressϵͳ��������die�ı�Ե��
��Ҳ���dz�����ѧԭ����Ϊ��ʹdie �Ļ���/���������ֱ������ֵ��¶ȸ��ߣ�����Ȼϣ�������м���и���Ĺ��������պ�ɢ������ ���������Dz�����ȫȷ�����ĵ�ԭ�����ǻ�������NVIDIA��оƬ��ROP����Ⱦ�������Ԫʵʩ�ĸ����йء�
���ǽ��ں������ϸ���������ǣ���������������˵����Ȼ���ֵĸı俴��������֣�������������ܲ���������Ӱ�졣������Ϊ3D��Ⱦ��������ʱ����ӳ٣�ͨ�������ڱ���ȴ����ݡ���ˣ�����һЩ����Ԫ����������Ԫ�뻺���Զ�����ӵ�������������������������ϵͳ�С�
�����Ǽ���֮ǰ��ֵ��ע�����AMD��Navi 21������ʵʩ�Ĺ��̸ı䣬����������Radeon rx5700 XT��Navi 10��ȡ�������оƬ������;���������϶���֮ǰ��оƬ����һ������������跨�ڲ��������ӹ��ĵ�����������ʱ���ٶȡ�
���磬Radeon RX 6800 XT�˶��Ļ�ʱ�Ӻ���ѹʱ�ӷֱ�Ϊ1825��2250mhz, TDPΪ300 W;Radeon RX 5700 XT����ͬ����Ϊ1605 MHz��1905 MHz��225 W��Ӣΰ��Ҳͨ��Ampere�����ʱ���ٶȣ�������ԭ����ʹ���˸�С������Ч�Ľ��̽ڵ㡣
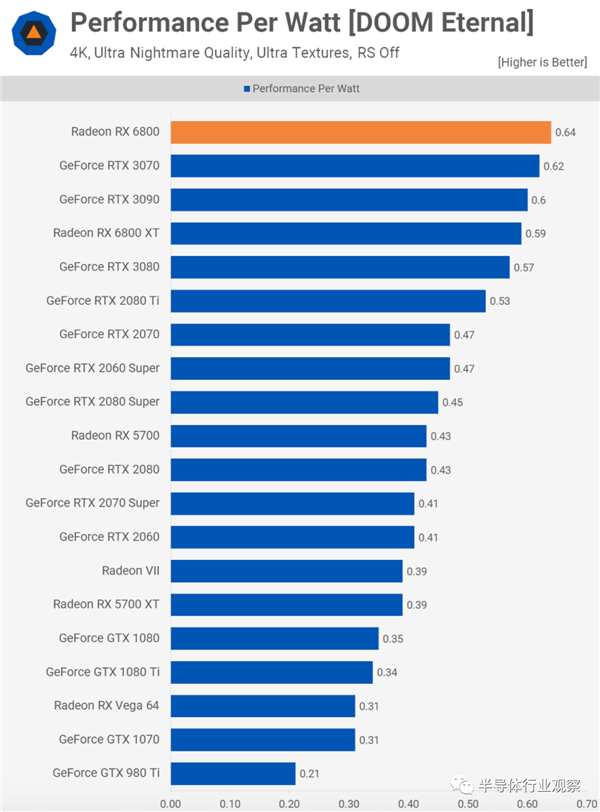
���Ƕ�Ampere��RDNA 2�Կ���ÿ�������ܼ����ʾ�����ҹ�Ӧ�����ⷽ�涼ȡ���������ĸĽ�����AMD��̨����ȡ����һЩ�൱�����ijɾ�——�Ƚ���ͼ��Radeon RX 6800��Radeon VII֮��IJ��졣
�����������״�ʹ��N7�ڵ����GPU�����������ڲ��������ʱ���ڣ����ǽ�ÿ�����������64������ȷ�����NVIDIA������̨�����������Ampere GA102�����ܻ�õöࡣ
����GPU����
оƬ�ڲ���һ����֯��ʽ
���漰��ָ��������ݴ������ʱ��Ampere��RDNA2����ѭ���Ƶ�ģʽ����֯оƬ�ڲ���һ�С���Ϸ������Աʹ��ͼ��API��д���⣬����������ͼ����������Direct3D��OpenGL��Vulkan����Щ�������������⣬�����˹��ṹ�ͼ�ָ���“�鼮”��
AMD��NVIDIAΪ���ǵ�оƬ���������������������ŷ��������:��ͨ��API����������ת��ΪGPU�ܹ�����IJ������С�����֮����ȫ��Ӳ���������ˣ�����ʲôָ������ִ�У�оƬ���ĸ�����ִ����Щָ��ȵȡ�
ָ������ij�ʼ���ɺ����ؼ�����оƬ�е�һ�鵥Ԫ��������RDNA 2�У�ͼ�κͼ�����ɫ��ͨ�������Ĺ��߽���·�ɣ���Щ���߽�ָ����Ȳ����ɵ�оƬ�����ಿ�֡�ǰ�߳�Ϊͼ������������������첽�������棨ACE����

NVIDIAֻ����һ���������������ǵ�һ�������Ԫ����GigaThread Engine����Ampere����ִ����RDNA 2��ͬ��������NVIDIA��δ����˵����ʵ�ʹ�����ʽ����֮����Щ��������Ĺ��������ڹ���������������
GPUͨ������ִ�����в�����������ܣ����������оƬ�ϸ�������һ����֯��Ρ���ֹ�������ȣ���������һ��ӵ������칫�ҵ��ڶ���ص�������Ʒ����ҵ��
AMDʹ�ñ�ǩ��ɫ�����棨SE������NVIDIA�����Ϊͼ�δ�����Ⱥ��GPC��-��ͬ�����ƣ���ͬ�Ľ�ɫ��

��оƬ�������ַ�����ԭ��ܼ��������Ԫ���ܴ����������飬��Ϊ�����ջ��ù����Ӵ���ӡ���ˣ���һЩ�ճ̰��ź���ְ֯���һ�������ƽ���������ġ���Ҳ��ζ��ÿ���������������ȫ��������������ִ��ijЩ���������һ���������Դ���������ͼ����ɫ�����������������ڴ����������ӵļ�����ɫ����
��RDNA 2�������У�ÿ��SE�����Լ�һ�̶��Ĺ��ܵ�Ԫ:������������һ���ض�����ĵ�·������Աͨ����������д���������
mitive Setup unit——��ȡ���㣬���ý��д�����ͬʱ���ɸ���Ķ���(essellation)��������
Rasterizer——�������ε�3D����ת��Ϊ���ص�2D����
Render Outputs(ROPs)——��ȡ��д��ͻ������
ԭʼ�����õ�Ԫ��ÿ��ʱ������1�������ε��������С������������ܲ��Ǻܶ࣬���Dz�Ҫ������ЩоƬ������1.8��2.2 GHz֮�䣬����ԭʼ�����ò�Ӧ�ó�ΪGPU��ƿ������Ampere��˵��ԭʼ��λ������֯����һ���ҵ��ģ����Ǻܿ�ͻὲ����
AMD��NVIDIA��û�й����ἰ���ǵĹ�դ���������߳�Ϊ��դ���棬����֪������ÿ��ʱ�����ڴ���һ�������Σ�������������أ���û�н�һ������Ϣ���������ǵ������ؾ��ȡ�
Navi 21оƬ�е�ÿ��SE����4��8��ROP���ܹ�����128����Ⱦ�����Ԫ��NVIDIA��GA102ÿGPC����2��8��ROP���������оƬ���˶�112��ROP���⿴����AMD���ⷽ�������ƣ���Ϊ�����ROP��ζ��ÿ��ʱ�ӿ��Դ�����������ء����������ĵ�Ԫ��Ҫ�Ի���ͱ����ڴ�����÷��ʣ����ǽ��ڱ��ĺ�����ϸ���ܡ����ڣ������Ǽ����о�SE/GPC��������ν�һ�����ֵġ�

AMD����ɫ���汻����Ϊ˫���㵥Ԫ��DCU����Navi 21оƬ��������10��DCU——��ע�⣬��һЩ�ĵ��У�����Ҳ������Ϊ�����鴦������WGP������Ampere��GA102�������У����DZ���Ϊ���������أ�TPC����ÿ��GPU����6��tpc��NVIDIA��Ƶ�ÿһ����Ⱥ����һ������“��������”�Ķ���——��������Ampere��ԭʼ���õ�Ԫ��
NVIDIAҲ��ÿʱ��1�������ε��ٶ����У�����NVIDIA��GPU��AMD�ĵͣ������ǵ�TPC������Navi 21��SEҪ��öࡣ��ˣ�������ͬ��ʱ���ٶȣ�GA102Ӧ����һ�����������ƣ���Ϊ������оƬӵ��42��ԭʼ���õ�Ԫ����AMD����RDNA 2ֻ��4����������ÿ����դ������6��TPC, GA102ʵ������7��������ԭʼϵͳ����Navi 21��4�������ں��ߵ�ʱ�Ӳ�û�б�ǰ�߸�75%�����漰�����δ���(����û����Ϸ�������ⷽ���ܵ�����)ʱ���ƺ�Ӣΰ�����ⷽ��������Ե��������ơ�
оƬ��֯�����һ����RDNA 2�еļ��㵥Ԫ��CU����Ampere�е���ʽ�ദ������SM������������GPU�����������ߡ�

��Щ��ͼ�δ������ڱ��е�����߲ˣ���Ϊ����ӵ���������ڴ���ͼ�Ρ���������ڵĹ�������ɫ���ĸ߶ȿɱ�̵�Ԫ������������ͼ�п����ģ�ÿһ��оƬ��ֻռ����оƬ�ռ�ĺ�Сһ���֣�����������Ȼ�Ƿdz����ӵģ����Ҷ�оƬ���������ܷdz���Ҫ��
��ĿǰΪֹ��������GPU�IJ��ֺ���֯��ʽ���棬��û��ʲô������ͻ����Э�顣����ȫ����ͬ���������ǵĹ���ȴ��ͬС�졣�����������������ĺܶ����鶼�ܿɱ���Ժ�����Ե����ƣ����һ���������һ�������е��κ����ƣ���ֻ�ܹ��Ϊ��ģ�У����ĸ�ӵ��������ɫ��
���Ƕ���CU��SM��AMD��NVIDIA��ȡ�˲�ͬ�ķ�ʽ��������ɫ������ijЩ���������кܶͬ�㣬��������������������ˡ�
����������NVIDIA�ķ�ʽ
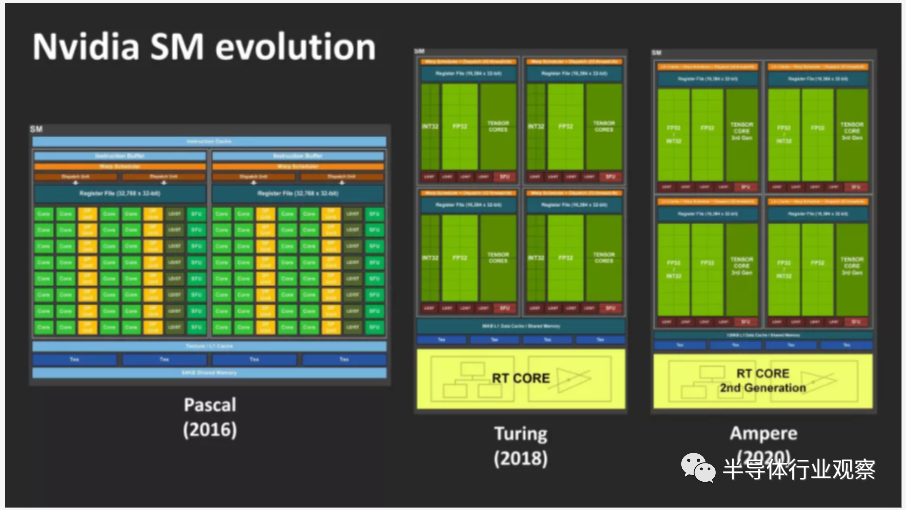
���ڰ��ࣨAmpere����RDNA 2֮ǰ��ð�ս���Ұ�⣬��������������NVIDIA��SM������û�б�Ҫ�鿴��Ƭ������ͼ����Ϊ������ȷ�����������е����ݣ����������ʹ����֯ͼ����Щ��Ӧ�ô���оƬ�и���������������з�ʽ����ֻ��ÿ�������д��ڶ����֡�
ͼ�����̨ʽ��ǰ��Pascal������ʵ���Ը��ģ�ȥ����һ��FP64��Ԫ�ͼĴ��������������������˺��߸��٣�����Ampereʵ������һ���൱�º͵ĸ���-���ٴӱ����Ͽ�����������NVIDIA���г����Ŷ��ԣ������ʹÿ��SM��CUDA�ں˵�����������һ�����ϡ�
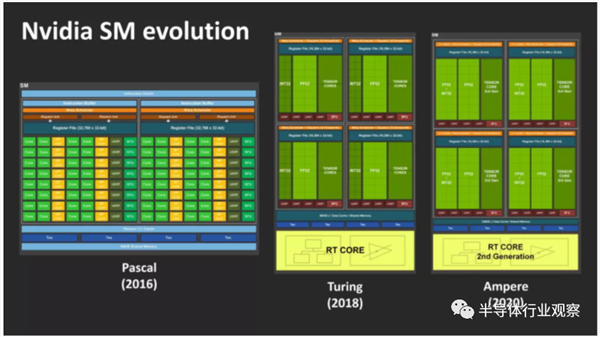
��ͼ���У����ദ���������ĸ���������ʱ��Ϊ�����飩��ÿ������������16��INT32��16x FP32����Ԫ����Щ��·ּ�ڶ�32λ����ִֵ�зdz��������ѧ���㣺INT��λ������������FP��λ��������������ʮ���ƣ���
Ӣΰ���ʾ��һ��Ampere SM�ܹ���128��CUDA�ںˣ����ϸ���˵�����Dz���ȷ��-���ߣ�������DZ�������һ�㣬��ôͼ�飨Turing��Ҳ����ˡ���оƬ�е�INT32��Ԫʵ���Ͽ��Դ�������ֵ����ֻ���Էdz������ļ������С�����Ampere��NVIDIA�ѿ���������֧�ֵĸ�����ѧ���㷶Χ����ƥ������FP32��Ԫ������ζ��ÿ��SM��CUDA�ں�������û�������ı䡣ֻ�����е�һ������ӵ�и���ܡ�
ÿ��SM�����е������ں˶�������ʱ����ͬһ��ָ���������INT / FP��Ԫ���Զ������У����Ampere SMÿ�����������Դ���128x FP32���㣬��һ����64x FP32��64x INT32��������ͼ��ֻ�Ǻ��ߡ�
��ˣ��µ�GPU����ʹFP32�������������һ����Ʒ��һ�������ڼ��㹤�����أ���������רҵӦ�ó����У�������ǰ������һ�����Ƕ�����Ϸ���ԣ�����ȴԶԶû�дﵽԤ�ڡ��������״β���GeForce RTX 3080ʱ����һ������ԣ���ʹ��������68��SM��GA102оƬ��
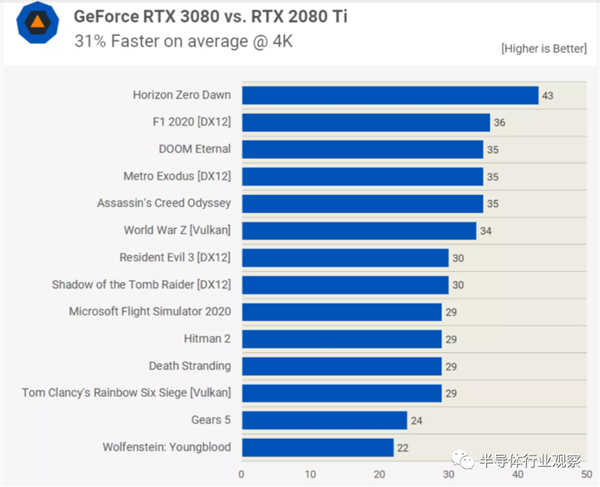
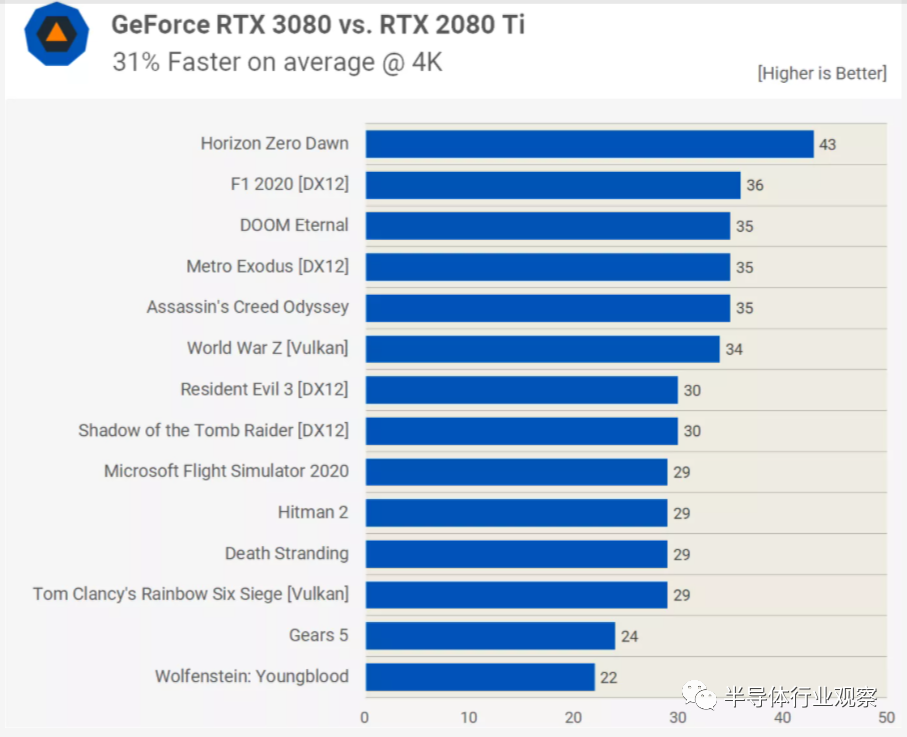
����FP32�ķ�ֵ��������GeForce 2080 Ti�߳�121������ƽ��֡���ʽ������31������ô��Ϊʲô������Щ�������������˷ѵ��أ�һ���Ĵ��ǣ���Ϸ����һֱ������FP32ָ�
��NVIDIA��2018�귢��Turingʱ������ָ���� GPU������ָ��ƽ��Լ��36���漰INT32���̡���Щ����ͨ�����ڼ����ڴ��ַ������ֵ֮��ıȽ��Լ�����/���ơ�
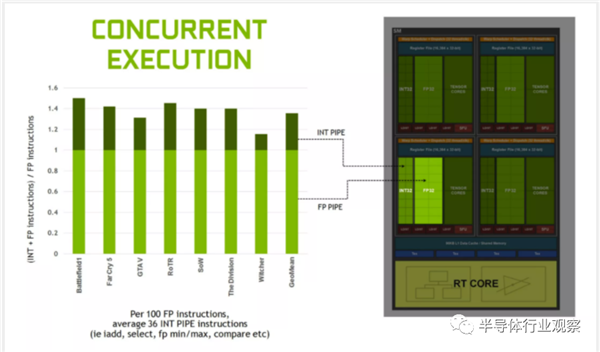
��ˣ�������Щ������˫����FP32���ܲ������ã���Ϊ������������·���ĵ�Ԫֻ��ִ�����������㡣���ң�ֻ���ڵ�ʱ��������������32���̶߳��ŶӴ�����ͬ��FP32����ʱ��SM�����Ż��л�����ģʽ����������������£������еķ�����ͼ���еķ���һ�����С�
����ζ����INT + FPģʽ������ʱ��GeForce RTX 3080֮���FP32����2080 Ti����11����FP32���ơ������Ϊʲô����Ϸ�п�����ʵ����������û��ԭʼ������Ԥ�ڵ���ô�ߵ�ԭ��
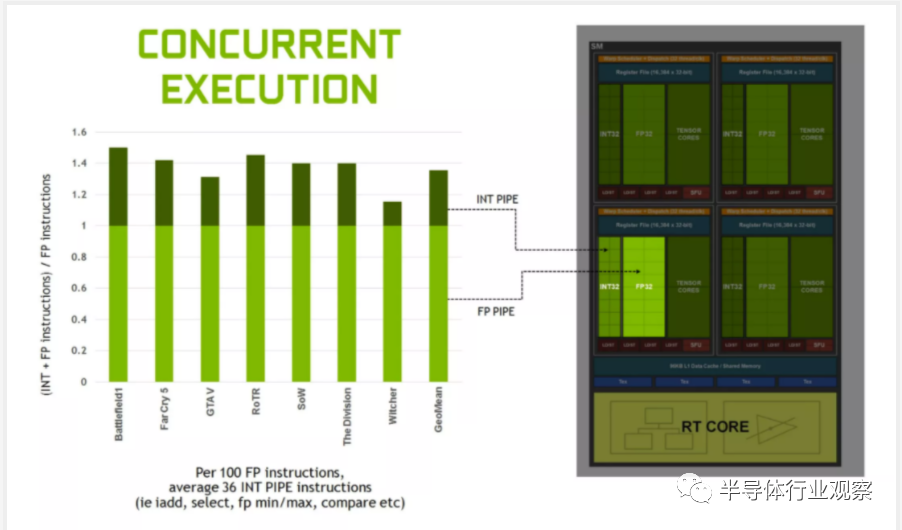
���������Ľ���ÿ��SM������Tensor Core���٣���ÿ������Turing�еĹ���ǿ��öࡣ��Щ��·ִ�зdz�����ļ��㣨���罫����FP16ֵ��˲�����һ��FP16����ۼӴ𰸣���ÿ���ں�����ÿ������ִ��32����Щ������
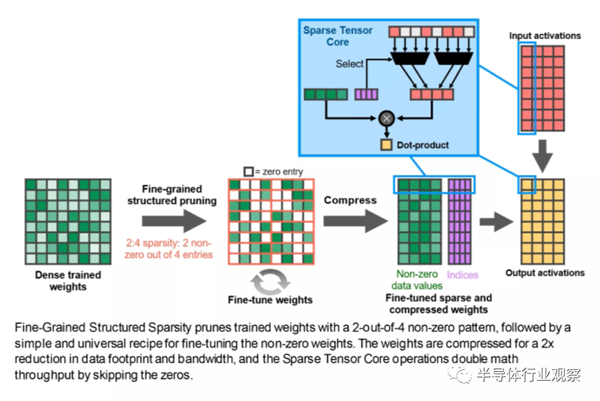
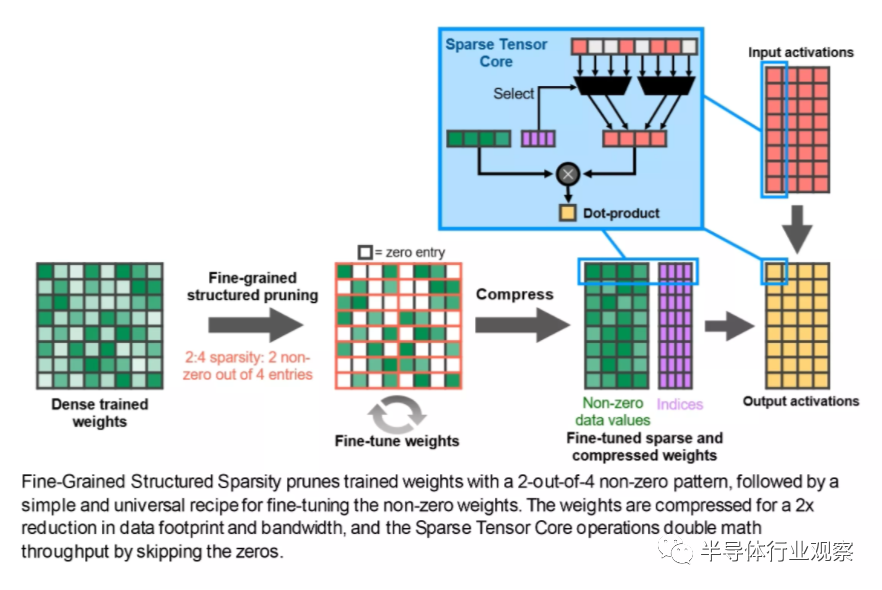
���ǻ�֧��һ����Ϊ“ϸ���Ƚṹϡ����”�������ԣ��ڲ��漰����ϸ�ڵ�����£�����ζ��ͨ������Щ�Դ�û��Ӱ������ݣ������ʿ��Է�����ͬ��������ڴ�����������˹����ܹ�����רҵ��Ա��˵�Ǹ�����Ϣ����Ŀǰ����Ϸ��������˵��û��ʲô���Եĺô���
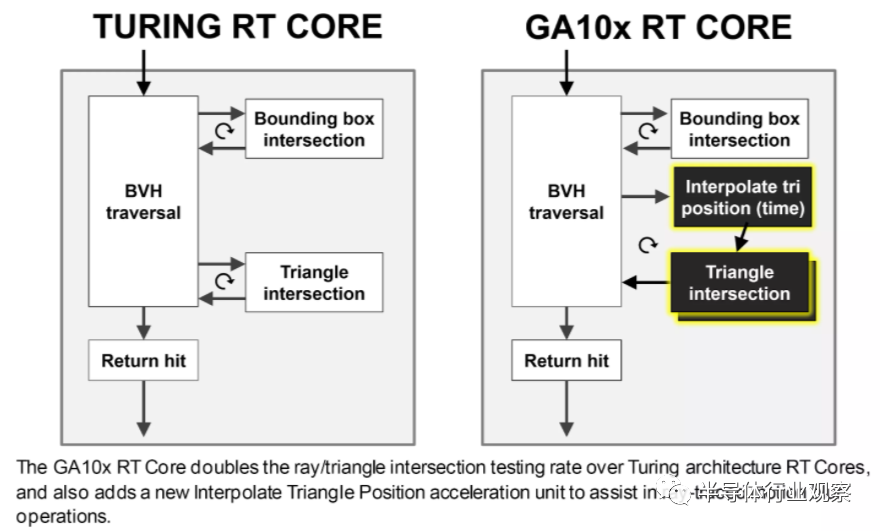
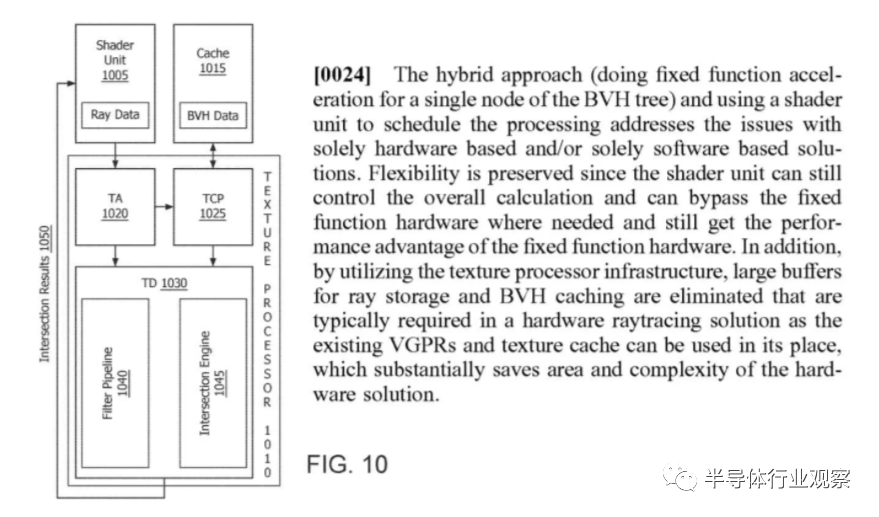
���߸��ٺ���Ҳ�ѽ����˵������������ڿ��Զ�����CUDA���Ĺ�������ˣ��ڽ���BVH���������ԭʼ�ཻ��ѧʱ��SM�����ಿ���Կ��Դ�����ɫ�������������Ƿ���ԭ���ཻ���Ե�RT���ĵIJ�������Ҳ������һ����
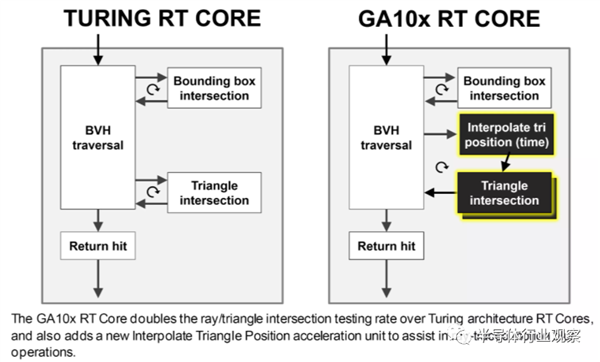
RT�ں˻����и��ӵ�Ӳ�����ɰ��������߸���Ӧ�����˶�ģ�������Ǵ˹���Ŀǰ��ͨ��NVIDIAר�е�Optix API������
��������һЩ�������������巽�������ǵ��ȶ����ݽ�֮һ����������Ҫ������ơ����ǿ��ǵ�ͼ���ԭʼ���ܲ�û��ʲô�ر�Ĵ�����˿�����һ�㲻��Ϊ�档
��ôAMD��ô�죿���Ƕ�RDNA 2�еļ��㵥Ԫ����ʲô��
Ѱ����Ĺ���
�ӱ����Ͽ���AMD�ڼ��㵥Ԫ���沢û��̫��仯-������Ȼ��������SIMD32������Ԫ��һ��SISD������Ԫ��������Ԫ�Լ����ֻ����ջ���������ǿ���ִ�е��������ͺ���ص���ѧ���㣬�Ѿ�������һЩ�仯�������Ժ���ϸ���ܡ�������ͨ�����߶��ԣ������Եı仯��AMD����Ϊ���߸����е��ض������ṩ��Ӳ�����١�
CU���ⲿ��ִ��ray-box��ray-triangle������——�밲���е�RT�ں���ͬ��Ȼ��������Ҳ������BVH�����㷨������RDNA 2������ͨ��ʹ��SIMD 32��Ԫ������ɫ������ɵġ�
����һ����ɫ���ں��ж��ٸ����������ǵ�ʱ�������ж�ߣ�ʹ�����Ϊ�����һ����Ķ��Ƶ�·���DZ�ͨ�÷������á������Ϊʲô���ȷ���GPU��ԭ����Ⱦ�����е��������ﶼ����ʹ��CPU����ɣ��������ǵ�ͨ����ʹ�䲻�ʺ��ڴˡ�
RA��Ԫ������������������Ϊ����ʵ������ͬһ�ṹ��һ���֡�����2019��7�£����Ǿͱ�����AMD�����һ��ר�������ݣ���ר��ʹ��``���''������ϸ�����˹������еĹؼ��㷨...
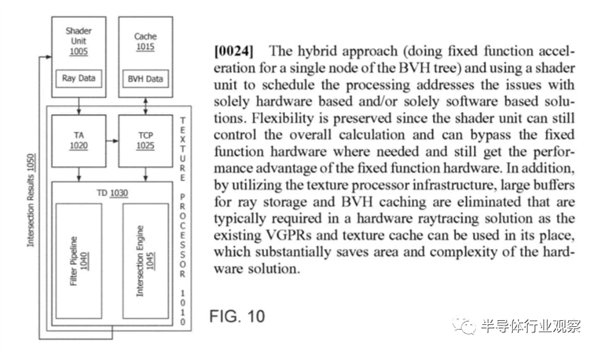
���ܸ�ϵͳȷʵ�ṩ�˸��������ԣ����������˵����ڹ����ٹ�����ʱ��Ƭ��һ���ֲ����κ����������AMD�ĵ�һ��ʵ��ȷʵ��һЩȱ�㡣��ֵ��ע����ǣ��������������κ�ʱ��ֻ�ܴ����漰������ray-primitive����IJ�����
����NVIDIA��RT����������ȫ������SM�����ಿ�ֶ����У���RNDA 2��ȣ���ͨ�����߸�������ļ��ٽṹ�ͽ�����Խ���ĥ��ʱ�����ƺ���Ampere���������Ե��������ơ�
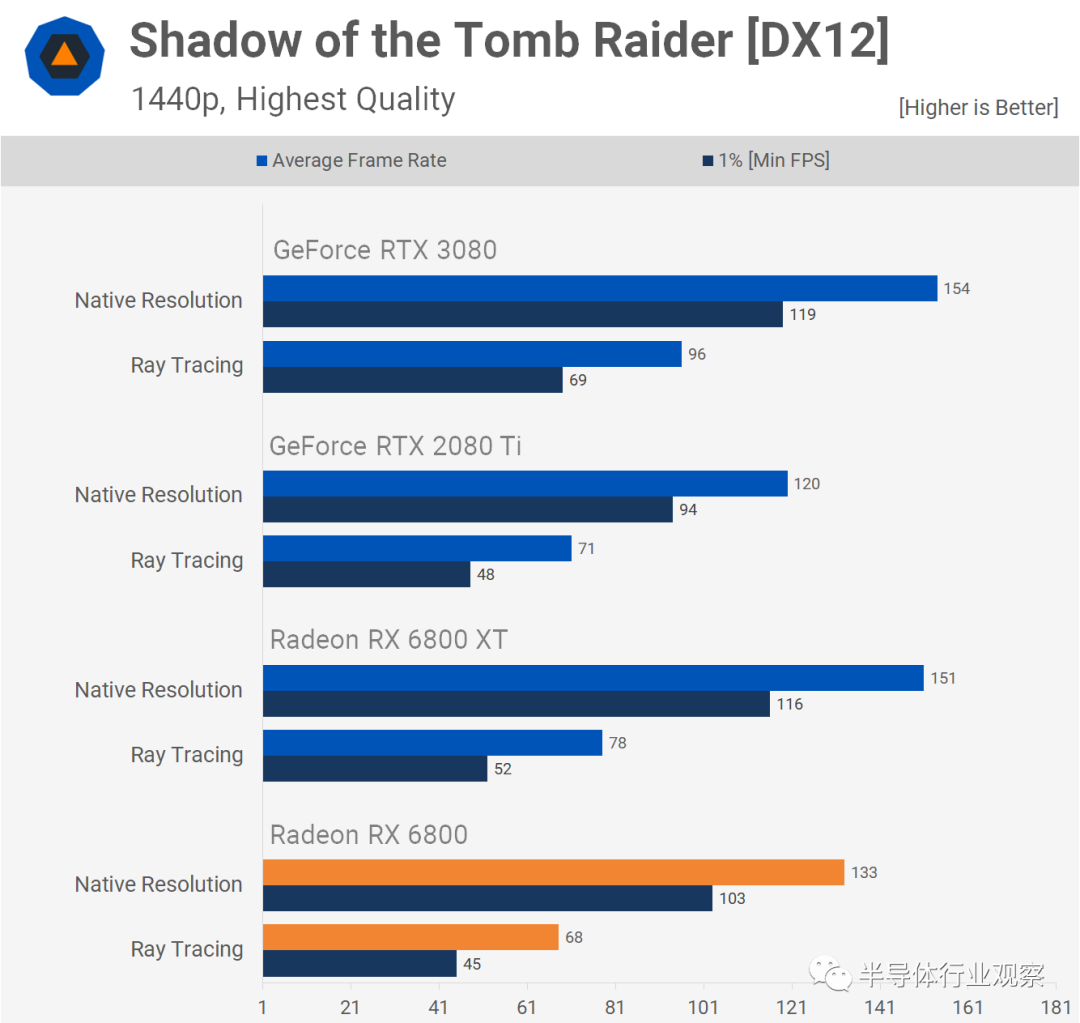
�������ǽ���Ҫ�����AMD����ͼ�ο��еĹ��������ܣ�����ĿǰΪֹ������ȷʵ����ʹ�ù����ٵ�Ӱ��ܴ�̶���ȡ�����������Ϸ��
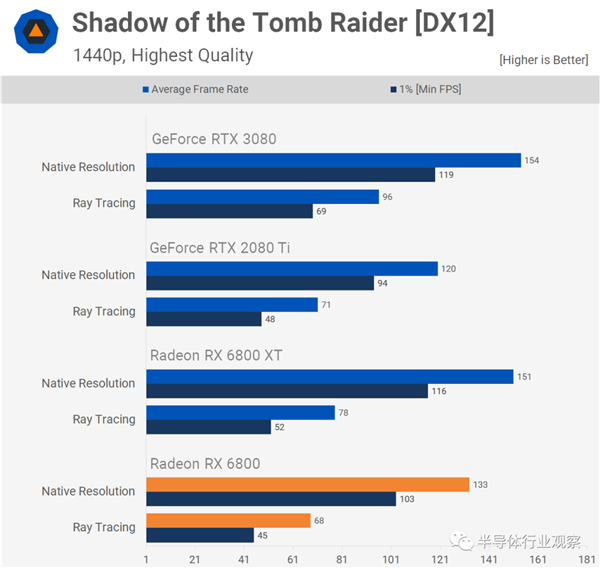
���磬��Gears 5�У�Radeon RX 6800��ʹ��Navi 21 GPU��60 CU���壩��������17����֡���ʣ����ڡ���Ĺ��Ӱ������Ӱ�У�ƽ����ʧ�ﵽ52�� �����֮�£�NVIDIA��RTX 3080��ʹ��68 SM GA102������������Ϸ�е�ƽ��֡����ʧ�ֱ�Ϊ23����40����
��Ҫ�������ٽ��и���ϸ�ķ�����˵��AMD��ʵ�֣�������Ϊ�ü����ĵ�һ�������������������о�����������Ӧ�ó������ڽ��е������ٺ����С�
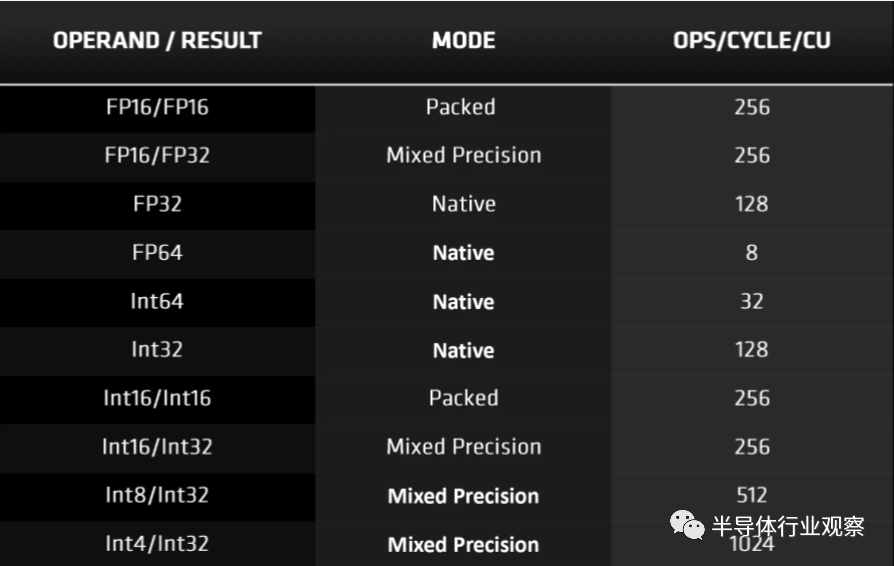
��ǰ������RDNA 2�еļ��㵥Ԫ����֧�ָ����������͡���ֵ��ע����ǵ;����������ͣ�����INT4��INT8���������ڻ���ѧϰ�㷨�е��������㣬��AMD��������AI���������ĵĵ����ܹ���CDNA�������˸���������DirectML��
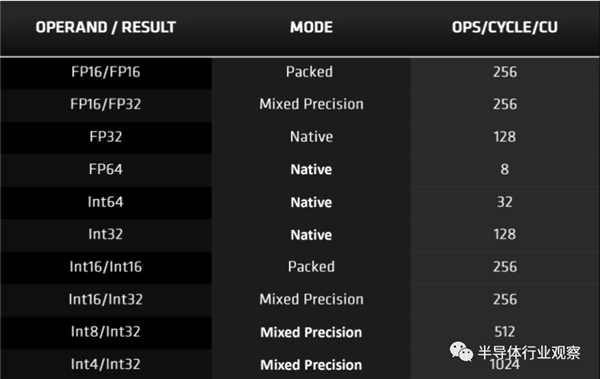
��API��Microsoft DirectX 12��������³�Ա��Ӳ������������Ͻ�Ϊ���߸��ٺ�ʱ��Ŵ��㷨�еĽ����ṩ���õļ��١����ں��ߣ�NVIDIA��Ȼӵ���Լ������ƣ���ΪDLSS�����ǵ�ϵͳʹ��SM�е�Tensor����ִ�в��ּ��㣬���Ǽ��ڿ���ͨ��DirectML�������ƵĹ��̣������Щ��Ԫ�ƺ���Щ���ࡣ���ǣ���Turing��Ampere�У�Tensor���Ļ����Դ��������漰FP16���ݸ�ʽ����ѧ���㡣
����RDNA 2�����������ʹ����ɫ����Ԫ��ʹ�ô�����ݸ�ʽ��ɵģ���ÿ��32λ�����Ĵ�������������16λ�Ĵ�������ô���ַ��������أ�AMD����SIMD32��Ԫ���Ϊʸ������������Ϊ��������Զ������ֵ����һ��ָ�
ÿ��������Ԫ����32����������������ÿ����������ֻ������������Ƭ�Σ����ʵ�ʲ��������DZ����ġ��Ȿ�����밲���е�SM������ͬ������ÿ�������黹���32������ֵЯ��һ��ָ�
���ǣ���NVIDIA����е�����SMÿ�����������Դ���128��FP32 FMA���㣨�ںϳ˼ӣ�ʱ������RDNA 2���㵥Ԫֻ�ܴ���64������ִ�б�FP16��ѧʱ��ʹ��FP16���Խ�����ߵ�ÿ������128 FMA������Ampere��Tensor������һ���ġ�
NVIDIA��SM���Դ���ָ��ʱ����ͬʱ������������ֵ������64 FP32��64 INT32�������Ҿ�������FP16������������ѧ���߸������̵Ķ�����Ԫ������AMD CU���ж�����֧�ּ�������ѧ�ı�����Ԫ����������SIMD32��Ԫ�ϳе��˴ֹ�������
��ˣ������ƺ����ⷽ��������:GA102��Navi 21ӵ�и����CU�������ڷ�ֵ������������Ժ��ṩ�Ĺ��ܷ��棬���ǵı��ָ���ɫ������AMD��һ���൱�����Ľ�����ơ�
�ڴ�ϵͳ����㻺��
ӵ�г�ǧ���������Ԫ��GPU���ڸ��ӵ���ѧ������һ·�߸��ͽ�����һ�ж��ܺã����ǵ�������Dz����㹻����ṩ�����ָ������ݣ����ǽ��ں�������������������������ƶ�ӵ�зḻ�Ķ༶���棬ӵ�о�Ĵ�����
����������������ġ�������ԣ��ڲ�������һЩ���ű仯��2�����������������50����ͼ��TU102���˶��ٶȷֱ�Ϊ4096 kB��������ÿ��SM�е�1������Ĵ�С��������һ����
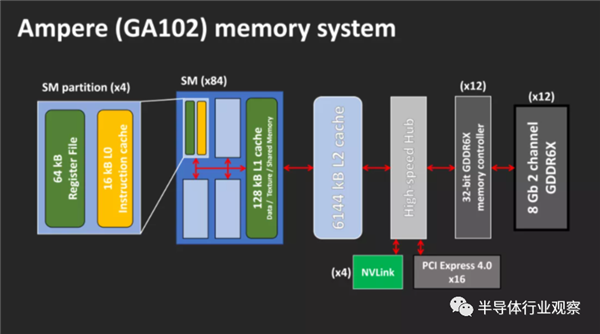
����ǰһ�����Ϳ���Ϊ���ݣ�������һ�������;������ٻ���ռ���ԣ�Ampere��L1�����ǿ����õġ����ǣ�����ͼ����ɫ�������綥�㣬���أ����첽���㣬����ʵ��������Ϊ��
64 kB�������ݺ�����
48 kB���ڹ���ͨ���ڴ�
16 kB���������ض�����
ֻ������ȫ����ģʽ������ʱ��L1�ſ�����ȫ���á��Ӻõķ�����˵�����ô���������Ҳ������һ������Ϊ�������ڿ���ÿ��ʱ�Ӷ�ȡ/д��128���ֽڣ�����û�й����ӳ��Ƿ�õ����Ƶ���Ϣ����
�ڲ��洢��ϵͳ�����ಿ����Ampere�б��ֲ��䣬���ǵ����ǽ�����GPU�ⲿʱ������������˵������һ���ܺõľ�ϲ��NVIDIA��DRAM�����������������GDDR6���İ汾�����䱾���ڴ����ӱ����Ͻ�������Ȼ��GDDR6�������������ѱ���ȫ�滻��GDDR6Xʹ���ĸ���ѹ��������ʹ�ô�ͳ��ÿ����������1λ���ź�ֻ����������ѹ������PAM��֮����ٷ��������õķ�ʽ��
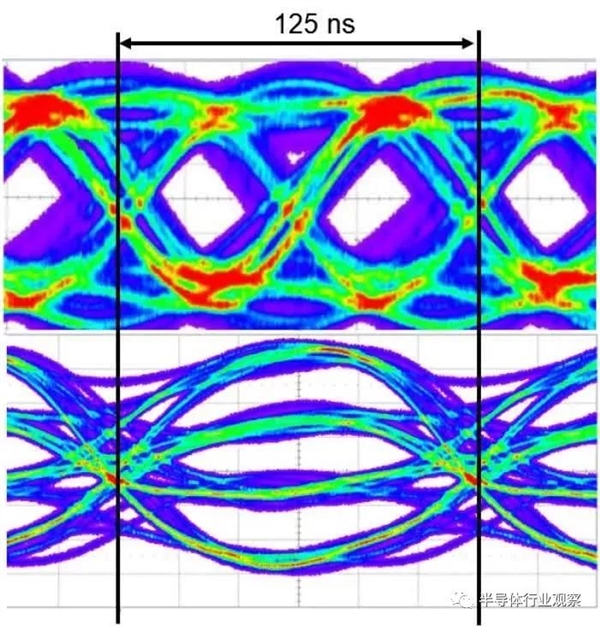
���д˸��ĺ�GDDR6Xÿ������ÿ��������Ч����2λ����-��ˣ�������ͬ��ʱ���ٶȺ�������������������һ����GeForce RTX 3090����24��GDDR6Xģ�飬�����Ե�ͨ��ģʽ���У������Ϊ19 Gbps���ṩ�ķ�ֵ�������Ϊ936 GB / s��
��GeForce RTX 2080 Ti��ȣ���������52�������Ҳ��������ӡ���ȥ��ͨ��ʹ������HBM2�ķ�ʽ����������Ĵ������֣���GDDR6��ȣ�HBM2��ʵ�ֳɱ��ܸߡ�
���ǣ�ֻ��Micron�����������ִ洢������PAM4��ʹ��Ϊ�������������˶���ĸ����ԣ����źŵĹ���Ҫ�ϸ�öࡣAMD����һ����ͬ�ĵ�·-����û��Ѱ���ⲿ�����İ���������������CPU����Ϊ����������µĶ�����������ǰ����Ʒ��ȣ�RDNA 2�е������ڴ�ϵͳû��̫��仯��ֻ��������Ҫ�仯��
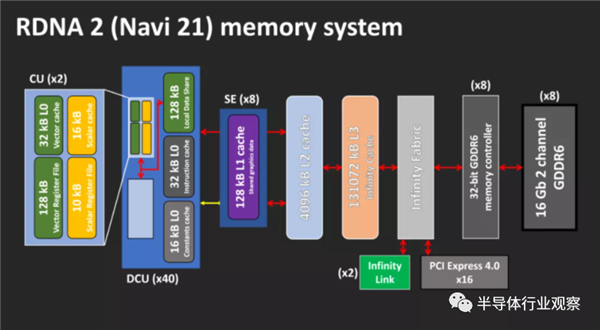
ÿ����ɫ���������ڶ�������Level 1���棬���������������ھ�������Dual Compute Unit��RDNAӵ��һ�飩��������ָı��ǿ���Ԥ�ڵġ����ǽ�128 MB��3�����滺�浽GPU�������úܶ��˸е����ȡ�������EPYCϵ��Zen 2������оƬ�е�L3���ٻ����SRAM��ƣ�AMD�ڸ�оƬ��Ƕ��������64 MB���ܶȸ��ٻ��档����������16��ӿڴ�����ÿ���ӿ�ÿ��ʱ��������λ64���ֽڡ�
��ν��������������Լ���ʱ�����ҿ�����1.94 GHz�����У��Ӷ��ṩ1986.6 GB / s���ڲ���ֵ������������������������ⲿDRAM������漰���ӳٷdz��͡����ָ��ٻ���dz��ʺϴ洢���߸��ټ��ٽṹ����������BVH�����漰�������ݼ�飬���Infinity���ٻ���Ӧ�ر�Ϊ���ṩ������
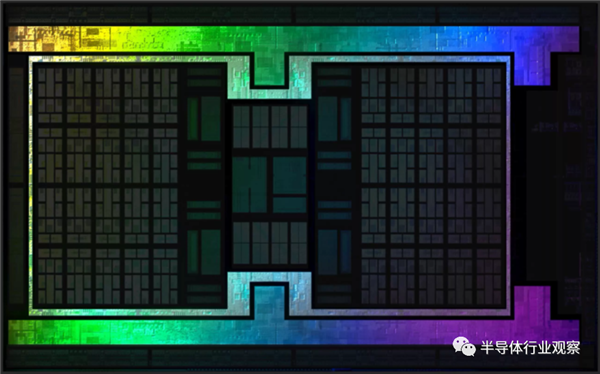
����64 MB��Infinity��������Infinity FabricϵͳĿǰ���в����RDNA 2�е�3�������Ƿ�����Zen 2 CPU����ͬ�ķ�ʽ���У�����Ϊ2��victim���档ͨ��������Ҫ������һ���ĸ��ٻ�����Ϊ�������ڳ��ռ�ʱ���Ը���Ϣ���κ��������뷢�͵�DRAM��
victim����洢�������Ѿ������ΪҪ����һ���ڴ��Ƴ���������128MB�����ݿ��ã�Infinity������ܴ洢32��������L2���漯��
��ϵͳ�Ľ���ǣ���GDDR6��������DRAM�Ϸ��õ�������١�AMD�ĽϾ�GPU���һֱ��ȱ���ڲ�����������¿�������������ǵ����ǵ�ʱ���ٶ���ߺ��Ƕ���Ļ��潫ʹ����������ʧ��
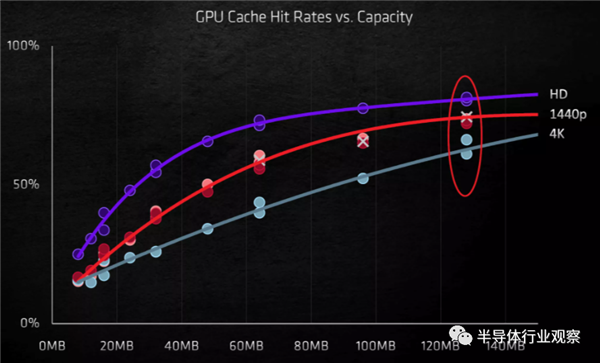
��ô��������Ƹ����أ�GDDR6X��ʹ��ΪGA102�ṩ�˵������ڴ�ľ���������Ҹ���Ļ��潫�����ڼ��ٻ���δ���У����ʹ�̵߳Ĵ���ͣ�ͣ���Ӱ�졣Navi 21�Ĵ���3��������ζ��DRAM���ؾ��������������������Ը��ߵ�ʱ���ٶ�����GPU����������������������ѷ��������
AMD�������ʹ��GDDR6�ľ�����ζ�ŵ�������Ӧ�̿���ʹ�ø�����ڴ棬ͬʱ�κ�����GeForce RTX 3080��3090�Ĺ�˾������ʹ�����⡣����GDDR6�ж���ģ���ܶȣ���GDDR6X��ǰ����8 Gb��
RDNA 2�еĻ���ϵͳ����˵�DZ�Ampere��ʹ�õĻ���ϵͳ���õķ�������Ϊ���ⲿDRAM�أ�ʹ�ö�������Ƭ��SRAMʼ�ձ��ⲿDRAM�ṩ���͵��ӳٺ��õ����ܣ��ڸ����Ĺ��ʷ�Χ�ڣ���
GPU������ȥ��
��Ⱦ���������ּܹ�������Ⱦ���ߵ�ǰ�˺ͺ�˽����˴������¡�DirectX12 Ultimate�е�Ampere��RDNA 2��ȫ�����˶���������ɫ���Ϳɱ�������ɫ������NVIDIA��оƬ���и���ɫ�ļ������ܣ�����Ҫ�鹦��NVIDIA���˸��������������
����ʹ��������ɫ������ʹ������Ա�������ӱ���Ļ�������û��һ����Ϸ�����ܻ���ȫ��������Ⱦ�����е�����Ρ���Ϊ�����ѵĹ����������ػ���߸��ٽΡ�
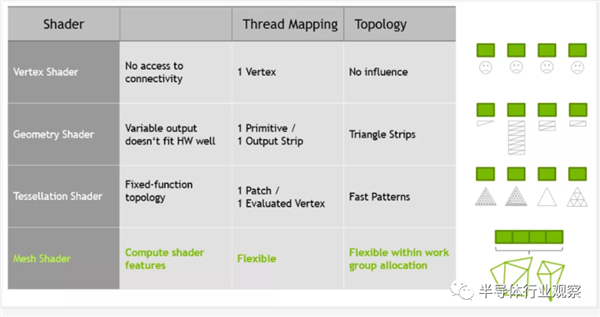
�����ʹ�ÿɱ�����ɫ���������õĵط�——�����ϸù����漰��һ�����ؿ�����ǵ���������Ӧ����������ɫ��ɫ������������Ϊ��������ܶ�������Ϸ�ķֱ��ʣ���������ֻ��Ӧ����ѡ������������Ӿ���������ʧ�������ԡ�
�����Ƿ�ʹ�ÿɱ�������ɫ������������ϵ�ṹ���Ѹ���������Ⱦ�����Ԫ��ROP�����⽫����ڸ߷ֱ����µ����ܡ���������ǰ��GPU�У�NVIDIA����ROPs���ڴ�������Ͷ����������һ��
��Turing�У�8��ROP��Ԫ(ͳ��Ϊһ������)��ֱ�����ӵ�һ����������һ��512kb�ĸ��ٻ����ϡ����Ӹ����ROP��������⣬��Ϊ����Ҫ����Ŀ������ͻ��棬��˶���Ampere���ԣ�����ROP����ȫ�������GPC��GA102ÿ��GPCӵ��12��ROP��ÿ��ʱ�����ڴ���1�����أ�������оƬ����112����λ��
AMD��������NVIDIA�ľɷ������Ƶ�ϵͳ�������ڴ��������L2����Ƭ�����������ǵ�ROP��Ҫʹ��1������������ض�/д�ͻ�ϡ���Navi 21оƬ�У��Ѿ�Ϊ�����ṩ�˼���ĸ��£�����ÿ��ROP��������ÿ��������32λ��ɫ����8�����أ�����64λ����4�����ء�
NVIDIA��ΪAmpere������RTX IO������һ�����ݴ���ϵͳ��������GPUֱ�ӷ��ʴ洢��������������������ݣ�Ȼ��ʹ��CUDA�ں˽�ѹ�����ǣ�Ŀǰ��ϵͳ�������κ���Ϸ��ʹ�ã���ΪNVIDIA����ʹ��DirectStorage API����һ��DirectX12��ǿ���ܣ�����������������δ���ù���������

Ŀǰʹ�õķ���������CPU����������һ�У�����������GPU��������������������ݴӴ洢���������Ƶ�ϵͳ�ڴ��У����н�ѹ����Ȼ���ٸ��Ƶ�ͼ�ο���DRAM�С�
�����漰�����˷ѵĸ���֮�⣬���ֻ����ڱ������Ǵ��е�——CPUһ��ֻ�ܴ���һ������NVIDIA���ƿ��Դﵽ“100��������������”��“20����CPU�����ʵ�”��������ϵͳ�ܹ�����ʵ�����в���֮ǰ��������֤�����ܹ�ʵ������Ч����

��AMD�Ƴ�RDNA 2���µ�Radeon RX 6000ͼ�ο�ʱ�������Ƴ��˳�ΪSmart Access Memory�IJ�Ʒ���ⲻ�����Ƕ�NVIDIA��RTX IO�Ĵ�——ʵ���ϣ������������������¹��ܡ�Ĭ������£�ÿ�������ķ��������У�CPU�е�PCI Express������������Ѱַ256 MB��ͼ�ο��ڴ档
��ֵ�ɻ�ַ�Ĵ�����BAR���Ĵ�С���ã���������2008�꣬PCI Express 2.0�淶�о���һ���ѡ���ܣ����Ե������С���������ĺô��ǣ�ֻ�账�����ٵķ������ɷ�����������DRAM��
�ù�����Ҫ����ϵͳ��CPU�����壬GPU�������������֧�֡���ǰ����Windows PC�ϣ�ϵͳ������Ryzen 5000 CPU��500ϵ�������Radeon RX 6000ͼ�ο����ض���ϡ�
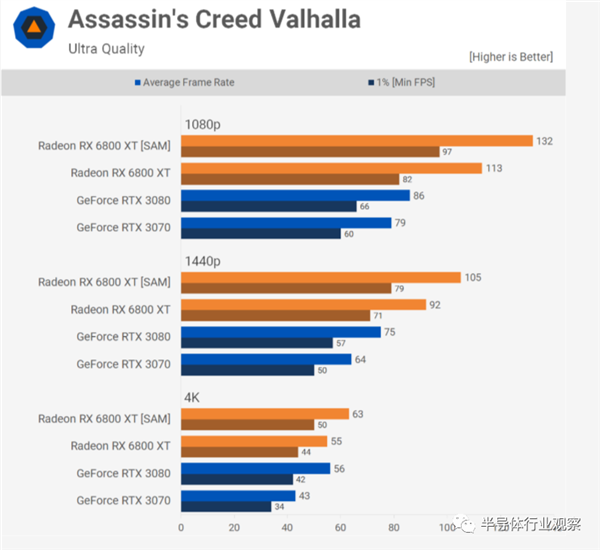
����ʱ������Ĺ��ܸ�����һЩ���˳Ծ��Ľ��——��4K�����½���������15%�Dz���С��ģ�����Ӣΰ���ʾ���ǽ��ڲ��õĽ���ΪRTX 3000��Χ�ṩ�������Ҳ�Ͳ���Ϊ���ˡ�
�Ƿ�ɵ�����С��BAR֧���Ƿ�����������ƽ̨��ϻ��д��۲죬��������ʹ���������ܻ�ӭ�ģ���ʹ������Ampere / RDNA 2����ϵ�ṹ���ܡ�
��Ƶȡ���˹㲥
��ý�����棬��Ƶ���
GPU����ͨ���ɺ��ķ�������TFLOPS��GB/s��һЩ����ָ��Ϊ����������YouTube���ݴ����ߺ�ֱ����Ϸ��������ʹ���г���ʼע��GPU����ʾ�Ͷ�ý�������������
����֧�ִ���ܵ���ʾ���۸���½��������зֱ����µij���ˢ���ʵ�����Ҳ������������ǰ��һ̨144 Hz 4K 27”��HDR��ʾ��Ҫ����2000��Ԫ;���죬������ü���һ��ļ۸������ƵĶ�����
���ּܹ���ͨ��HDMI 2.1��DisplayPort 1.4a�ṩ��ʾ�����ǰ���ṩ�˸�����źŴ�����������HDR��240 Hzʱ�����ǵĶƵ�ʾ�Ϊ4K����60 Hzʱ����ֵΪ8K������ͨ��ʹ��4��2��0ɫ�ȶ��β�����DSC 1.2aʵ�ֵġ���Щ����Ƶ�ź�ѹ���㷨�������ż��ٴ�������������ʧ̫����Ӿ����������û�����ǣ���ʹHDMI 2.1�ķ�ֵ����Ϊ6gb /s��Ҳ��������6hz�����ʴ���4Kͼ��

48Ӣ��LG CK OLED'��ʾ��'-120 Hzʱ��4K��ҪHDMI 2.1Ampere��RDNA 2��֧�ֿɱ�ˢ����ϵͳ������AMD��FreeSync������NVIDIA��G-Sync��������Ƶ�źŵı���ͽ��뷽�棬Ҳû�����Ե�����
������ʹ�����ִ������������ᷢ�ֶ�8K AV1��4K H.264��8K H.265�����֧�֣�������������������µ����ܾ�����λ�û�еõ������о������ҹ�˾��û����ϸ˵�����ǵ���ʾ�Ͷ�ý��������ڲ��ṹ���������Ǻ���Ҫ����GPU�����ಿ������ֵ�ù�ע��
��ͬ�IJ���
Ϊ�������������Ϊ��Ϸ����GPU��ʷ�İ����߽�֪��AMD��NVIDIA��ȥ�ڼܹ�ѡ��������ϲ����˽�Ȼ��ͬ�ķ��������ǣ�����3Dͼ��Խ��Խ�ܵ����������API��ͬ�ʻ���֧�䣬���ǵ��������ҲԽ��Խ���ơ�
������Ϸ����������Ⱦ����Ϊ�ܹ����»�����GPU��ҵ�Ѿ���չ�����г�����������췽����д����ʱ��NVIDIA������ʹ��Ampere ������оƬ:GA100��GA102��GA104��

GA104������GeForce RTX 3060 Ti���ҵ����һ��ֻ��GA102�ľ����——ÿ��GPCӵ�е�TPC���٣�����GPU���٣���������������ֻ������֮���������������ݶ���ȫ��ͬ����GA100���������ȫ��ͬ�IJ�Ʒ��
GA100û��RT�ˣ�Ҳû��INT32 + FP32֧�ֵ�CUDA�ˡ��෴�����������������FP64��Ԫ������ļ���/�洢ϵͳ�Լ�������L1 / L2���档��Ҳû����ʾ�����ý�����档������Ϊ����ȫ��Ϊ����AI�����ݷ����Ĵ��ģ���㼯Ⱥ����Ƶġ�
��Ӧ�ó����Ͽ���GA102/104��Ҫ����NVIDIA���г���:��Ϸ�����ߡ�רҵͼ�������Һ���ʦ���Լ�С��ģ���˹����ܺͼ��㹤����Ampere����Ҫ��Ϊ“����ͨ”�������ܹ���ͨ������ҵ������ɲ���һ�������¡�

750ƽ������Arcturus CDNARDNA 2רΪPC����Ϸ���ϵ���Ϸ����ƣ�����������ת����Ampere��ͬ��Ӧ���г���Ȼ����AMDѡ��������ǵ�GCN�ܹ�����������������������רҵ�ͻ�������
RDNA 2������“ Big Navi”����CDNA������“ Big Vega”-Instinct MI100װ��ArcturusоƬ������һ��ӵ��128�����㵥Ԫ��500�ھ����GPU����NVIDIA��GA100һ������Ҳ��������ʾ�����ý�����档
����NVIDIAƾ��Quadro����˹��(Tesla)����רҵ�г�ռ����������λ����Navi 21֮��IJ�Ʒ����ּ����֮���⣬���ǽ�������Ӧ����ơ����Ƿ��ʹRDNA 2��Ϊ���õĽṹ��ϵ; Ampere ��Ӧ�����г���Ҫ���Ƿ������������ķ�չ?
�����鿴֤��ʱ�����ƺ��ǣ�����
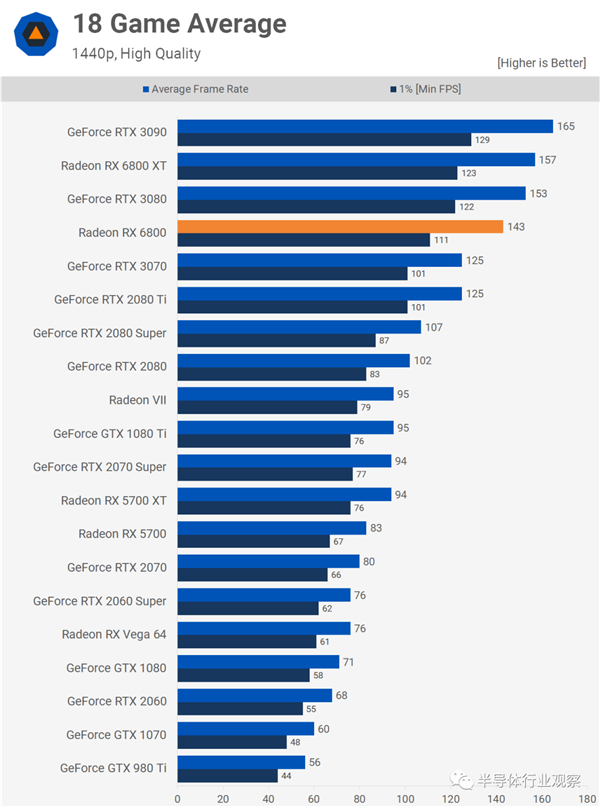
AMD���ܿ췢��Radeon RX 6900 XT����ʹ����������Navi 21(û�н���CUs)�������ܿ�����GeForce RTX 3090����á��������ſ��ϵ�GA102Ҳû�б���ȫ�ͷţ�����NVIDIA���ǿ���ѡ��������һ��“����”�汾����������ȥ��� Turing������������
�������˻�˵����ΪRDNA 2������Xboxϵ��X/S��PlayStation 5�У���Ϸ�����������ڽ����ּܹ��������ǵ���Ϸ���档���ǣ���ֻ��Ҫ�鿴��Xbox One��PlayStation 4��ʹ����GCN��ʱ�䣬������˽����������η������á�
ǰ����2013��ĵ�һ�η�����ʹ���˻���GCN 1.0�ܹ���GPU——�������ֱ���ڶ���ų���������PCͼ�ο��С�2017�귢����Xbox One Xʹ�õ���GCN 2.0������һ���Ѿ�ʹ����3���ij�����ơ�

��ô������ΪXbox One��PS4��������Ϸ��ֻҪ��ֲ��PC�ϣ�������AMD�Կ������еø�����?ʵ���ϣ���û�С���ˣ�����RDNA 2��������ӡ����̵Ĺ��ܣ������Dz�����Ϊ�ò�Ʒ����RDNA 2������ͬ��
����Щ���ն��ؽ�Ҫ����Ϊ������GPU��ƶ����зǷ����������ǰ뵼������������漣��NVIDIA��AMD�����˲�ͬ�Ĺ��ߣ���Ϊ���Ƕ�����ͼ�����ͬ������;Ampere��Ŀ�������������ˣ�RDNA 2��Ҫ�ǹ�����Ϸ�ġ�
��һ�Σ�ս�������˽��֣�����˫�����������ض���һ������������ʤ����
GPU֮ս�����������꣬һ���µľ����߽������ⳡս��:Ӣ�ض���Xeϵ��оƬ���ڲ��õĽ��������Ǿ��ܿ����ⳡս���Ľ����!
|