������ƶ��豸��Ϊ��Ҫ����ƽ̨�Ĵ�ʱ��������ע��ҵ���˶���˵��ARM���ù�˾��Ϊ�����ƶ��ߣ��ṩ���ִ������ܹ��Լ����IJο���ƣ��������ѳ�Ϊ���������ƶ��豸�Ķ���֮Դ�����ڹ�ȥ��5~7��������������ֻ���ƽ�����SoC���ܵķ��ٷ�չ�� ARM������ԶԶ�������ƶ���Ƕ��ʽ�豸������ҵ����������������������ػ�����ʩ�ȸ߶��������Ÿ��������ռ䣬������ARM�����Ĺ�˾��˵������һ���dz�������ͼ���г��� ����������ARM���ƶ���Ƕ��ʽ�豸����ȡ���˾�ijɹ���������Ϊֹʼ��δ�ܴ����������ܲ�Ʒ������ ��Ȼ�ڹ�ȥ��ʮ���У�������ڡ�ARM������������ͻ����ܹ��г���������Ԥ�Բ�����Ҳ�в�ͬ�Ĺ�Ӧ����ͼʵ����һĿ�꣬Ȼ��ǰ������Ʒ��û�л�óɹ���ARM�ķ�������̬ϵͳҲ�������൱������ѡ� 
������������֮�� ȥ�����У�ȫ�µ�Cortex A76�ܹ���ճ�����ARM���������������������������δ�������CPU·��ͼ������������PC�ʼDZ�����������Intelչ�����澺������������8CX�Ȳ�Ʒ�����л���Ҫ�ȴ��ܾã�����ýAnandtech�Ѿ��õ�����������Cortex A76���ƶ��豸������֤��ARM���������ܺ�Ч�������� �����ARM�ַ��������Ǽܹ�Neoverse����ϣ��ͨ����һ����������ƴ�����������ܣ�������ڷ������ͻ�����ʩ����ľ������� ��Щ�¼ܹ���ARM��˵������Ҫ�����Ǵ������г���һ��ת�۵㣺ARM�����������ܱ����Ѿ��ӽ���Intel��AMD����������ARM�����ı���ÿ��25~30%�����������������ԽIntel��AMD�ĵ������ȡ� 
��ȥ�����¶���ARM��������̬ϵͳ��˵�Ƿdz�ֵ����ϲ�ġ���ȥ���Hotchips����ϣ���ʿͨչʾ��ȫ�µ�A64FX�����ܼ��㴦���������������˹�˾��SPARC�ܹ���ϵת��ARMv8�ܹ���ϵ�����ṩ�˵�һ����ARM�ܹ���ʵ����SVE������չʸ����չ����оƬ�� Cavium��ThunderX2Ҳȡ��������ӡ����̵����ܷ�Ծ��ʹ���´�������Ϊ�����ܹ���Intel��AMD�����Ĵ������� ǰ���ӣ������ֿ����˻�Ϊ�Ƴ���ȫ������920������оƬ����оƬ������Ϊҵ��������ߵ�ARM������CPU�� �������ֲ�Ʒ֮�����Ĺ����ǣ�ÿ�ֲ�Ʒ�������˸���Ӧ����ʵʩ����ARMv8�ܹ����ɵĶ�����ϵ�ṹ����������Ŭ������ʵ����������һ�����⣺ARM�Լ��ķ������ͻ�����ʩ�г��ƻ���ʲô�� �˴Σ����ǽ���ϸ����Neoverse N1�����ƽ̨�����ǽ���Ϊδ������ARM�Ļ�����ʩս�Եĺ��ģ�������ʵ�ַ�������̬ϵͳ�� Neoverse N1 CPU������Э���� Neoverse N1ƽ̨�ĺ�����Neoverse N1 CPU����CPUƷ����ƽ̨Ʒ������ͬ��������ARM��������ƽ̨������CPU���ģ���������Χ�Ļ���IP��ʹ����ϵͳ������չ�����ϵͳ�� 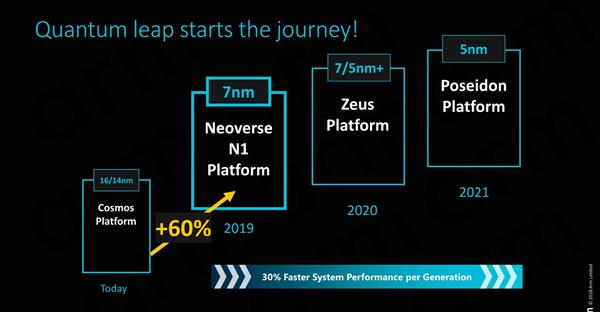
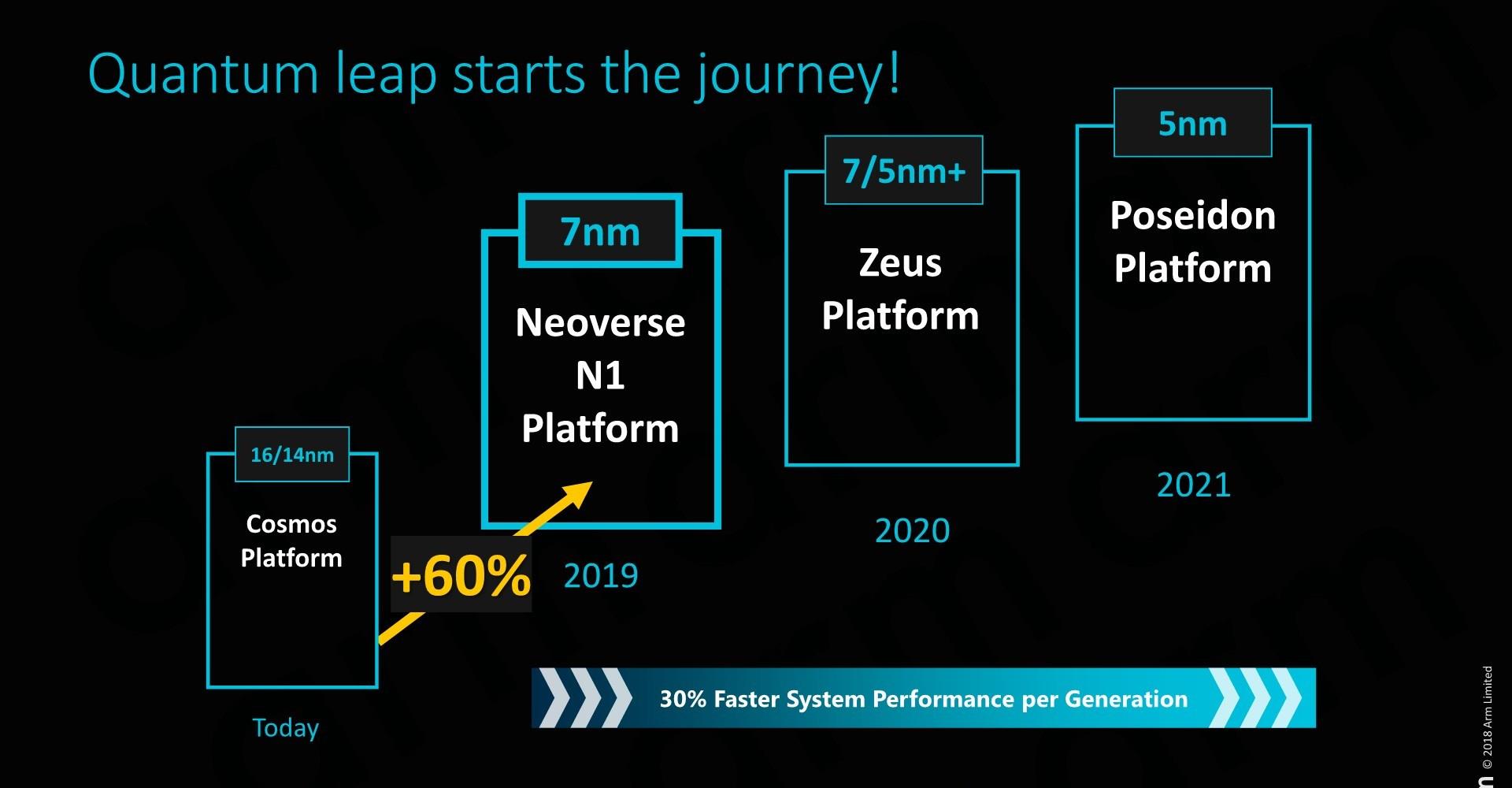
Neoverse N1ƽ̨��CPU������ARM��רΪ�������ͻ�����ʩ�г���Ƶ�ר�ü���IP�����ǶԹ�ȥIP��Ʒ���ش�ı䣬���н�Ϊ���Ѳ�Ʒ����ҵ��������ṩ��ͬ��CPU IP����ЩIP����֮����¼��������ʹARMΪ�µĻ����ܹ�Ŀ���Ʒ�����µ�Ӫ�����ƣ����NeoverseƷ�Ƶ����������������ߵ�Cortex CPUƷ���������� Neoverse N1ƽ̨������ARM��˹͡������ġ��ڶ�����˹͡���塱�ĵ�һ�ε�����Neoverse N1ԭ��Ϊ��ս����������Cortex A76���Ӧ�ķ��������������ġ�ͬʱ����˹͡�Ŷӿ����Ѿ�����˵ڶ��ε��������Zeus�ܹ�����ƹ��������Poseidon�ܹ�����Ϊ��һ��������һ�ε�����Ȼ���������ݸ��ɷ������������Ŷ���Ƶ���һ���ܹ����塣 ����Neoverse N1��Cortex A76�ܹ����ֵܣ��������֮����Ȼ�кܶ�����֮��������ȥ������ϸ������Cortex A76�ܹ�����Щ���ϸ��Ҳͬ��������Neoverse N1�����߽�����Ӧ������ʩ����������Щ���졣 
�߲����Ŀ����ԣ�ARM��Ŀ���ƺ��൱ֱ�ӣ�����һ��������Э�ļܹ�������Ϊδ�������ڿ��ظ�ʹ�õĻ����� �ر�ֵ��һ����ǣ����Ǵ�Cortex A76�Ͽ��Կ�����ARM���ڵ����ܹ���ƣ�ʹ���ܹ��ڻ�����ʩ�����������Ƶ�����С�����Intel��AMD�ڷ�����CPU�ϲ��õIJ����γ��������ĶԱȡ� ARM�ڷ�����CPU�ϵ��������ڿ���ͬʱ�Ż����ܡ����ĺ��������Intel��AMD���ò�����Щָ����������Э��ʹ���Ʒ��Ȼ���Ӧ�����Ѽ���Ʒ�������Ƶļܹ�����Ƶ�������dz����ޣ���ȡ���ڸ�����SKU��Ե����ĸ�ϸ���г��� 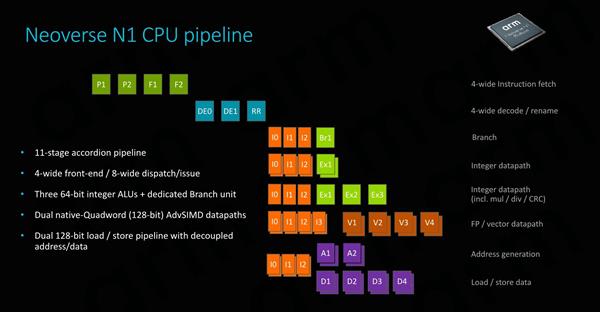
Neoverse N1����ˮ�߽ṹ��Cortex A76��ͬ����Ϊ11������ˮ����ƣ�ǰ�˶���4���Ķ�ȡ/��������ARM�����Ϊ���ַ��١��ܵ�����Ϊ����ָ��Ȳ�ͬ�����������ӳ����е�����½��ڶ�Ԥ������һ��ȡ���ص��������Ƚ����һ�������ص�������ˮ�߳��ȼ��ٵ�9���� ִ�к��Ҳ��������Cortex A76��ȫ��ͬ��ӵ��2�������Ӽ�����ļ�ALU��1�������˳�����ĸ���ALU���Լ�2�������������������ȫ��128λSIMD��ˮ�ߡ� �����������Ǵ������ܹ���һ����Ҫָ�꣬ARMΪNeoverse N1���������128λ����/�洢��Ԫ���ܹ�ά���㹻�Ĵ������ṩ�ͷ���ִ����ˮ�ߡ� �ܹ�ǰ����Cortex A76ͬ���dz����ƣ���������L1��L2���е��ӳٷ������ܡ������ARM��������ҵ�繫֪��һЩ���ķ�֧Ŀ��ͷ���Ԥ����������Ա��������������ģ�����С����֧Ԥ��ͻ�������ʧ�ܵĸ�����������ܡ� 
�ڻ����νṹ���棬Neoverse N1��Cortex A76���ܴ��ߵ�L1����������Ϊ64KB����ȡ�ӳ�Ϊ4�����ڣ�����Neoverse N1�����IJ�ͬ���ڻ�������ȫһ�µġ� ��Ҫע����ǣ�Ӳ��I-cache��һ���Բ�����ISA��Ҫ��ģ���ĿǰΪֹ��ͨ������ͨ������ά����������ɵġ� ΪN1ʵ��Ӳ��һ���Զ�ARM��˵�dz���Ҫ����Ϊ���������������ܲ������������ʵ�֣����ARM��Ҫ�ڳ����ģ�ͻ��о��о��������ͱ���߱���Щ���ԡ�ӵ��I-Cache��һ���Ա���Ϊ��һ���ؼ���֧�����أ�����ʹϵͳ���зdz�����ں˼�����ARM��ʾ16�����ϵ�ϵͳ������߱���һ���ԡ� L2�����ѡ��512KB��1MB�����ã�ʹ��512KB����ʱ��Cortex A76������ͬ����1MB���������Ӧ���ڴ�ռ�ø����Ӧ�ó���������L2����ӱ���1MB������û�д��۵ģ�����û�����ӳ�����2�����ڣ��ﵽ11�����ڵĸ���ʹ���ӳ١� 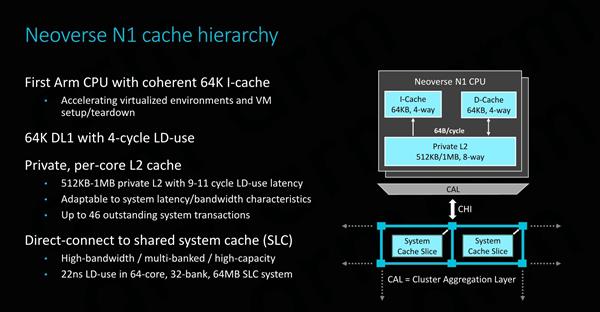
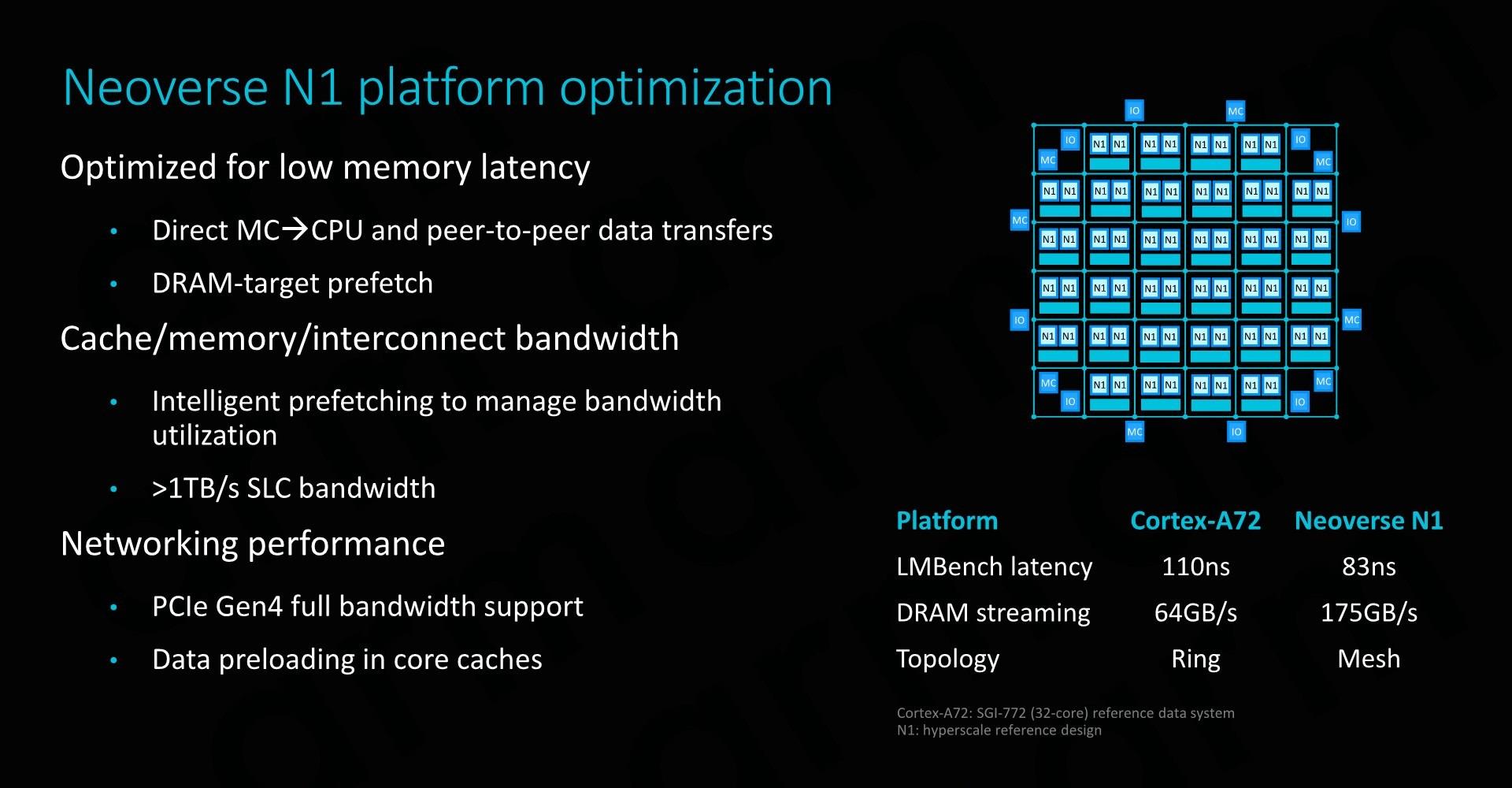
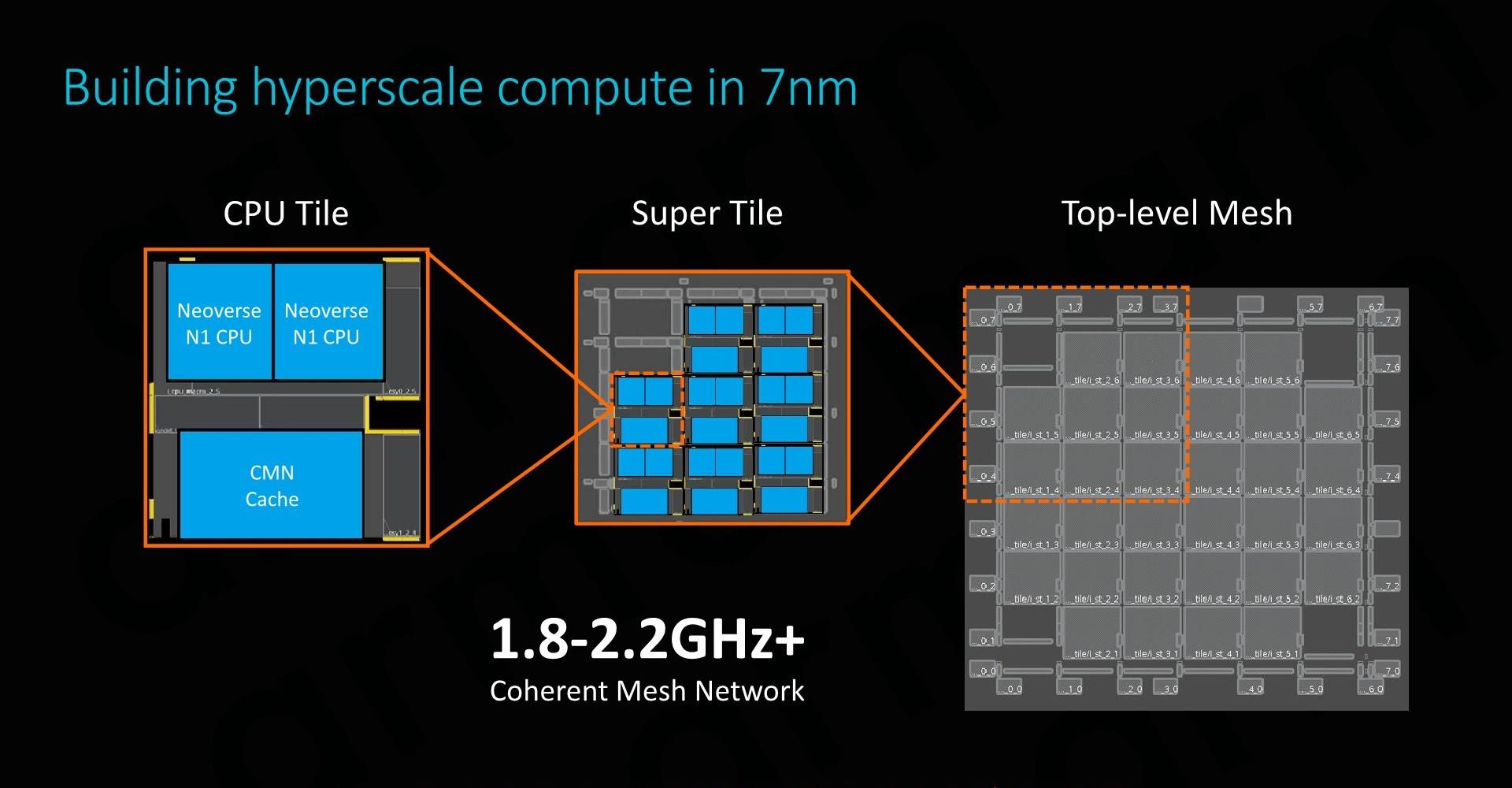
Neoverse N1��Cortex A76��һ���ܴ���������ڣ��ڽ��д�߶Ȼ������ʱ��Neoverse N1����ȥѰ�Ҽ�Ⱥ�����ǻ�ʹ��mash�����ķ�ʽ�� ��ͼ��ʾ������������ͨ��һ��CAL������ۺϲ㡣ÿ��CAL���֧�������ӿڣ������Ϊʲô������ÿ������Ⱥ����ֻ�ܿ�������CPU�������������������ļ�Ⱥ����Ȼ��CAL���ӵ������XP������㣩����������������Ľ�����/·���������ÿ��XP�����������ö˿ڣ���ARM�ο����ʾ���У��ڶ����˿�����һ��ϵͳ�����档 ��64��ϵͳ����2MBϵͳ�������ʾ��ϵͳ�У�����64MB�����ƽ������ʹ���ӳ�Ϊ22ns��ARM�������ӳ���������������������������ԭ����ϵͳ�������mesh��������CPU�첽��Ƶ���ϣ�ͨ�����ں�Ƶ�ʵ�2/3���ҡ� ֱ��������Neoverse N1��CMN-600��һ�������������������ֻ���������ƽ̨�ϣ�����Cortex�ܹ����Dz�����ʵ�ֵġ������ϣ���ɾ����DSU������L3��̽����������������ֱ�ӽ�CPU�ں����ӵ�CMN��CHI�ӿڡ���ˣ��ڴ��������CPU����֮���ͨ�ű�����ֻ��Ҫͨ��һ���м�㣬��mash���籾���� 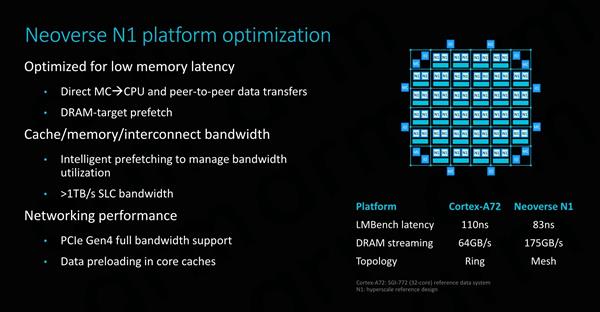
ֱ�Ӵ��ڴ��������CPU���ݴ�������е����Խ��ͣ���CPU���ڴ������������������ʱ�����ܹ�����ͬʱ�������䷢�͡�Ԥȡ����������ͬʱͨ��mesh������XP���ڵ��̽�������������������Ȼ������·�ɵ��ڴ����������ˣ��ڴ����������ǰ֪������ĵ����������Ѿ���ʼ��ȡ���ݣ��Ӷ����ز�����Ч���ڴ��ӳ٣��������������䰴����˳����С� Ԥȡ������ϵͳ�����ܷdz���Ҫ�����ܹ�������Ԥȡ������Ч�Ż�ϵͳ����������˵�ھ���64���ĺ�8��DDR4 3200�ڴ�ͨ����Neoverse N1�ο�ϵͳ�У�����ʵ�ָߴ�175GB/s���ڴ������ARM���������ӳ����ݣ���ARM�����ݱ�ʾLMBench���ݣ�ͬʱ������256MB������ȵ�2MB��ҳ�档ѡ���ҳ����Լ���TLB����©�������ӽ�ʵ�ʵ��ڴ��ӳ٣������ARM����������·��������Ļ���ԭ���� ���ǻ�û�л�����������˴�ҳ��ľ�Ʒϵͳ������AMD��EPYC 7601��LRDIMM DDR4 2666 19-19-19������оƬ�ĸ��ٻ����νṹ��ĩ��ͨ��������LMBench�IJ�����ʵ��Լ73ns���ӳ٣������ƿ������ӳٲ��Խ�TLBʧ����С�����ӳ�ԼΪ57ns��Intel W-3175X��RDIMM DDR 2666 24-19-19������ͬ�������ӳٷֱ�Ϊ94ns��64ns�� 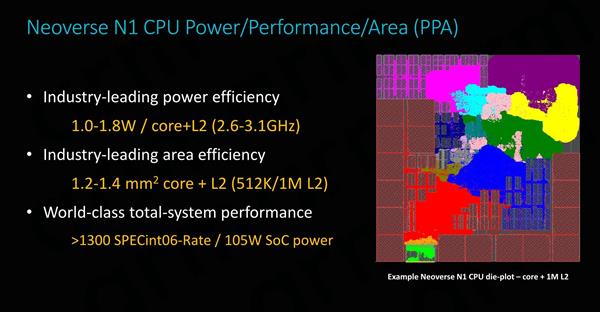
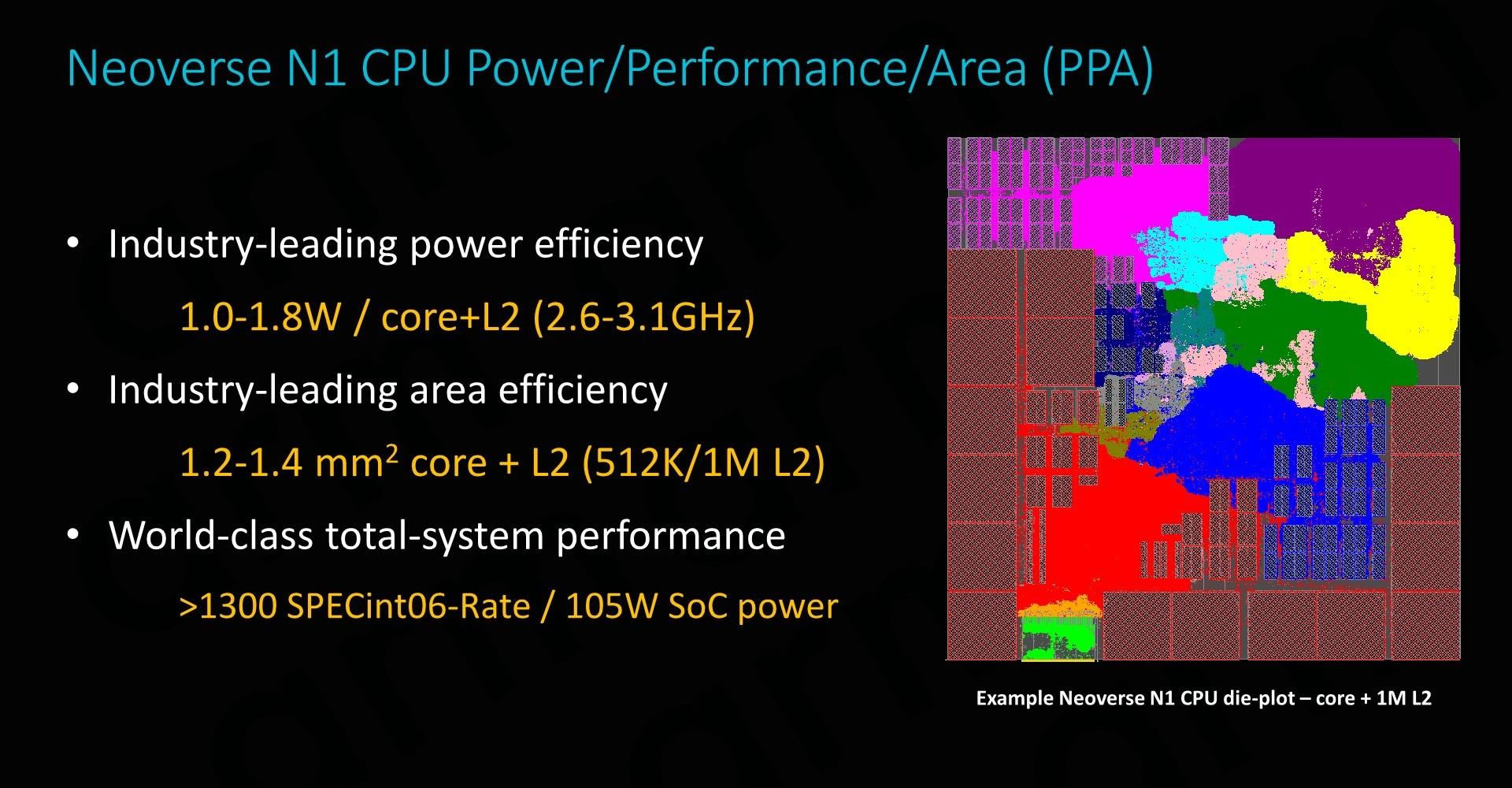
ʹ��̨����7nm���������Neoverse N1оƬ����dz�С����ʹ��512KB��������ʱ�������ԼΪ1.2ƽ�����ף�������980����Cortex A76��1.26ƽ����������ͬ����L2����ӱ���1MB�������Ҳֻ��1.4ƽ�����ס� ��Ƶ�ʷ�Χ���棬ARM����������0.75V��ѹ�´ﵽ2.6GHz����1V��ѹ�¿�ʵ��3.1GHz��������Ƶ������ĩ�ˣ�����44���Ĺ���ֻ�ܵõ�19��Ƶ�ʺ�������ߣ���˴������Ӧ�̶�ϣ�����ӽ����������и���Ч�IJ��֡� �����Ӿ�������������Neoverse N1�Ĺ���ֻ��1~1.8W����Ϊ64��SoC�ṩ�˳���Ŀռ䣬ARM����64��Neoverse N1�ο���Ƶ��ܹ���Ԥ��ԼΪ105W�� Neoverse N1�����ģ�ο���� ARM�ṩNeoverse N1�������ο���ƣ����а���һ����ȫ��ARM�Լ���֤��IP�����ײο���Ƶ�Ŀ����Ϊ��Ӧ���ṩ����㡱����ѡ��������ǾͿ�����������ٵ�Ŭ����ʵ�����ŵ����ܡ� 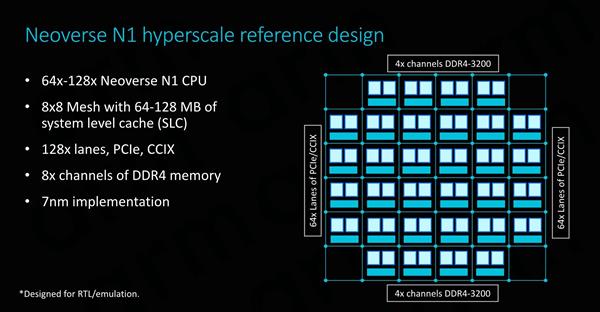
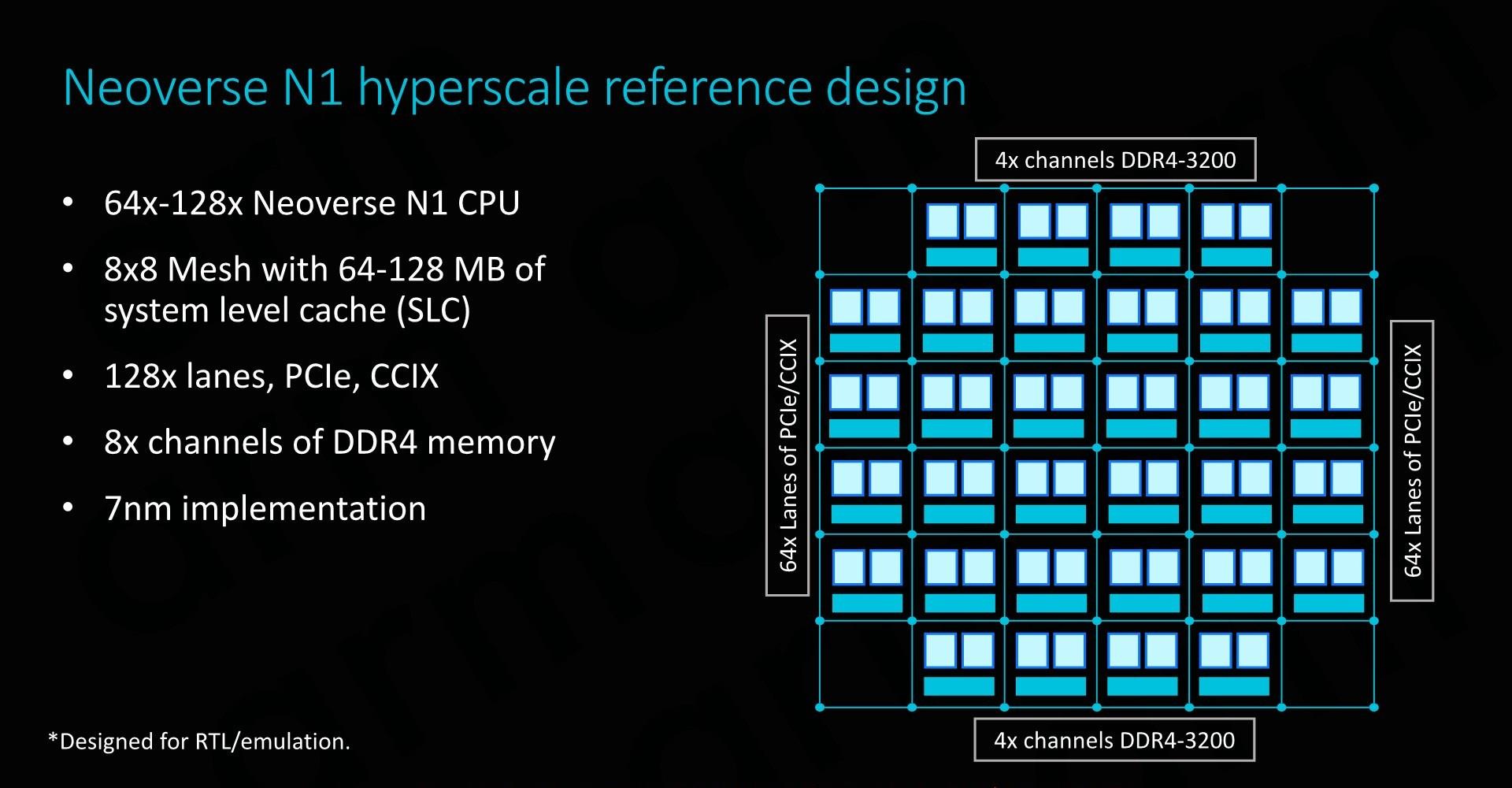
Neoverse N1�IJο�����пɲ���64��128�������ã������ھ���64 MB��128MB ϵͳ�������CMN-600 mash�����С�I/O�ӿڷ��棬128��PCI-E 4.0ͨ���ֱ�����I/O��CCIX�ӿڣ����ṩ�㹻��I/O������ ���ڴ淽�棬ARMΪ��������8ͨ��DDR4�����������֧��3200MHz������ʵ���ϣ�ARM�Ѿ������������з��ڴ����������Ϊ���������¿ͻ���ʹ�ø��Ե��ڲ���ƣ�����ѡ���������������Ӧ�̣���Cadence��Synopsys����ѡ���� ����Ŀǰ�IJο������˵��ARM�Լ���DMC-520�ڴ��������Ȼ�����µģ��Ҷ��ڹ�˾��˵��һ���ܺ������ģ�顣������δ������DDR5�����Ľ��µ��ڴ������Ҳ�����ò������ڵ�����IP�� 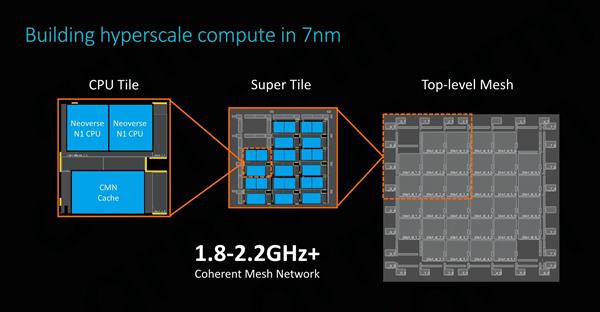
SoC������ʵ�ֽ�ʹ�ñ�����ƵĿɸ��÷ֲ㹹���顣ÿ��CPUģ��������Neoverse N1�ںˡ�һ��ϵͳ�����棬�Լ�CMN�Ľ����ͱ��ؽڵ��һ������ɡ�ͨ����ת�;���������CPUģ�飬�����������յ�SoC�������� ��7nm���սڵ��ϣ�ARM��64��Neoverse N1�ο���ƴ���64MB���ٻ��棬оƬ�ߴ�ӽ�400ƽ�����ף������Ը��ڹ�Ӧ����Ҫ�Ŀ�������Ŀ�ꡣΪ�˻������ֵ��ǣ�ARMͬʱ�����СоƬ��Ƶ��뷨���ö��СоƬͨ��CCIX��·����ͨ�ţ���֤�˱�Ҫ������ԣ���Ӧ�̿����о��������ƽ�������� 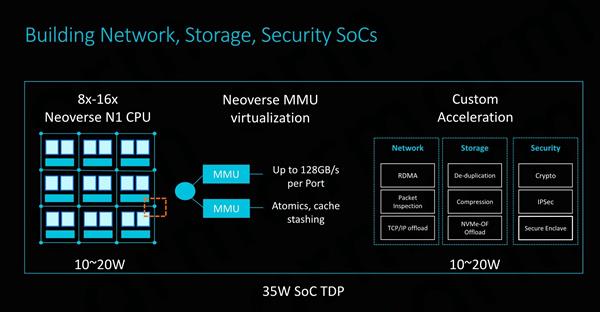
���������ļ�������Ҳ������ƺ�����Ե�һ����Ҫ���棬Ϊ���ڴ���ϵͳ������ȵ������������������������ʵ�������ھ������ܼ�����Ч����ʽ������ʵ�ָ��������Ĺؼ��� CMN-600�������佻��������ôӶ˿ڣ�ͨ���ߴ�128GB/s�ĸߴ����������ڴ������Ԫ���ӣ���������������̶����ܵ�Ӳ��ģ�顣 CCIX��ARM�dz���Ҫ����Ϊ��ʹ���Ʒ����ܹ��������IP��Ʒ���ɡ� Ϊ�ⲿIPģ�����ø��ٻ���һ������һ���dz����������Ĺ��ܣ���Ϊ�������˹�Ӧ�̵�������ơ� ����������ζ������ֻ�ǿ���һ������ڴ�飬�������ϵͳ��Ҫ�������������֪���������ڴ���ĸ���������Ч�ģ���Щ���ǡ� ��IP���ɷ��棬ARM�ṩ��CMN-600���ɵ�CCIXһ�����أ�����һ���棬���ǵ�����IP�ṩ���ṩCCIXת��������Ρ� 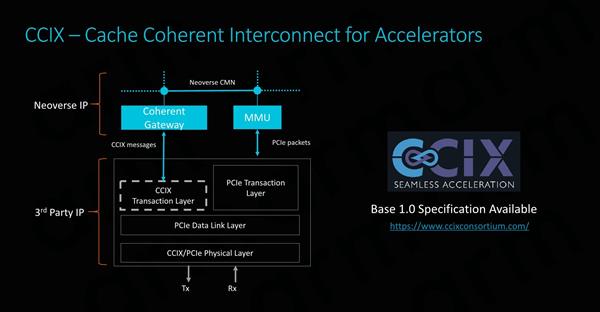
��ARM��˵��CCIX�dz���Ҫ�����������Ʒ����ܹ��������IP��Ʒ���ɡ�Ϊ�ⲿIP�����û���һ������һ���dz��������������ԣ��ɴ���Ӧ�̵�������ƣ�������Ҫϵͳ������������������Щ����Ч�ڴ档��IP���ɷ��棬ARM�ṩ����CMN-600���ɵ�CCIX������أ���������IP�ṩ�����ṩCCIX����㡣 ��оƬ��������У���Ӧ�̻��������һ��׳��������磬��֧��ʵ��ʹ������и���ͻ�����Ͽ��ĵ�������������Ӧ�̶��Զ���һ���dz�ͷ�۵����⣬��Ϊ�����Ҫ���ӵ�ģ�ͣ����ڴ��������£����������Ҫ����������ṩ�ȶ��Ա�֤���ⷴ������������ʵʩ�ĸ����Ժͳɱ��� 
ARMּ��ͨ����ר������������ʽ�ṩ��ϸ���ȵ�DVFS����̬��ѹƵ�ʵ�����������������Щ���⡣����������CPU�����ڲ�����ϸ����ӵ�Ԫ���鿴ʵ���ж��پ�������ڻ�����������������Ϣ������ϵͳ�������Ը���DVFS״̬����ʹ��Ӧ���ܹ���������������Ϊ�����ص��ݲ�Ӷ���ʡʵʩ�ɱ��� ����Ԥ�� �������ܺ�Ч�ʵ����ۣ���Ȼ��Ҫ�þ������������������ARM����Neoverse N1ʱ��������������ݶ��������Cortex A72�ĸĽ����Ⲣû�н�Neoverse N1�������ھ������������ص����ݵ㡣Cortex A72��һ��2015���Ƴ��ļܹ��������Ʒ֮������3~4���ʱ���ȡ� 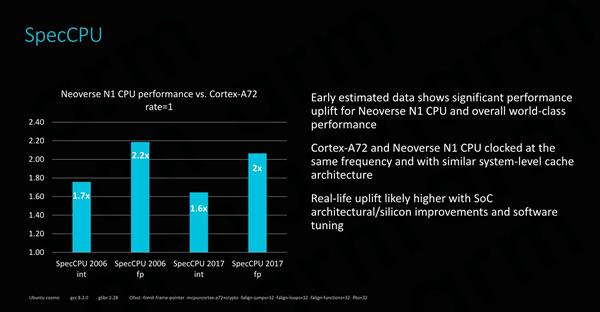
����ͬƵ����ͬ������ϵͳ�������Cortex A72ƽ̨��ȣ�ȫ�µ�Neoverse N1ƽֱ̨������ѹ����̬�����ʤ����SPEC�ĵ��̲߳����У�Neoverse N1����������PPC��ÿʱ�����ܣ��;����������Cortex A72������60��~70�����������������������ӡ����̣������ߴ�100��~120�����Ҽ���Neoverse N1������������SoC����ĸĽ��������Ż���ʵ�ʵ����ܱ��ֽ�����ߡ� �����н��������ȣ�ARM�ٴε����˷dz�����������ݽ�������������������ʵ���˳���2����������������Ȼ��Neoverse N1֧��ARMv8.2ָ�Ҳ��ζ����֧��8λ�����FP16�뾫��ָ���Щָ���ر��ʺϻ���ѧϰ�������أ�ʵ���˱�ǰһ��ƽ̨��5�������������� 
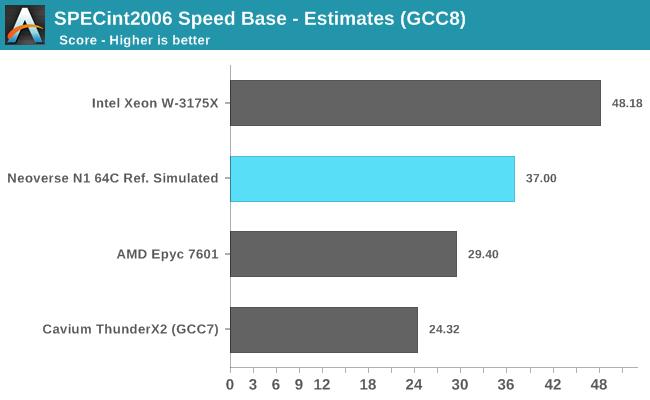
���������ٶ�ԼΪ2.6GHz��64��Neoverse N1�����ģ�ο���ƣ���105��TDP�£���SPECint2006���̵߳÷�ԼΪ37�������̵߳÷�Ԥ��ԼΪ1310�� ������һ���ܲ�����ʵ�����еIJ�Ʒ�ϲ���ģ�������ARM�ķ�����Ⱥ��ʹ��RTLģ����й�������ġ� 
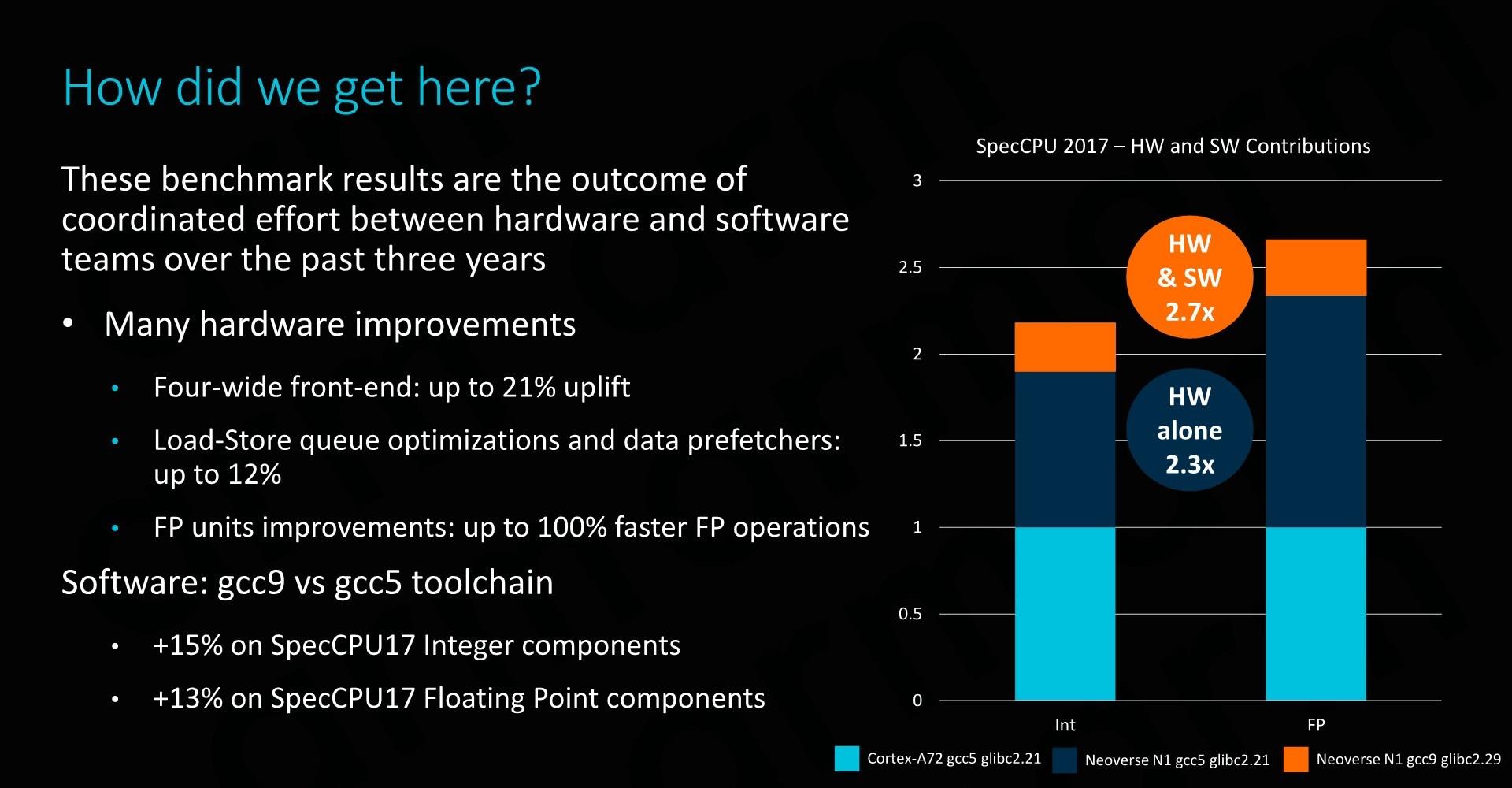
Neoverse N1�ĵ��̵߳÷֣����Ը�����ͬԴ��Cortex A76�ϲ�����26�֣�Ʋ�������ͱ������Ŀ��Dz��ᣬ���42%���ܲ����ԭ��֮һ������Neoverse N1ӵ�и��õ��ڴ�ͻ���ϵͳ������ϵͳ������Cortex A76�����ƶ�SoC��6�����ڵ��̹߳��������У��߳̿�����ȫ����64MBϵͳ�����棬���Cortex A76��Ƶ�L3�����16���� ARMǿ�����ڸ�����̬ϵͳ���ܵ��ڶ�Ŭ���У������ṩ���õ�Ӳ��֮�⣬����Ҫ�ṩ���õ��������ڹ�ȥ�ļ����ARMͶ���˴����������Ľ���Դ���ߺͱ����������罫���°�GCC9��ɰ��GCC5���бȽϣ����������㹤�����ص����������13~15%������Щ�Ż�������ʵ�������ĸĽ���������ּ������SPEC�ֵܷ�����Եĸı䡣 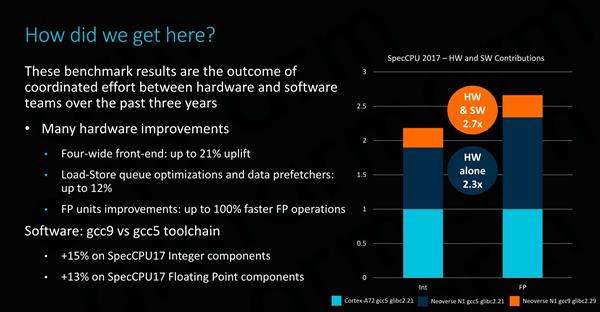
�͵��߳����ܶ��ԣ�Neoverse N1�������dz���ɫ�����Ժܴ�����ƻ�����Ŀǰ������ѵ�ARM������CPU����Cavium��ThunderX2�� ��Ȼ���������������IJ�Ʒ���ⲻ��Ҫ�����ƹ�Ӧ��Intel��AMD���жԱȣ���Intel��AMD���µġ�Ҳ����õ�Xeon W-3172X�Լ�EPYC 7601�ϣ�ͬ��ʹ��GCC8����һ��������ļ����С� Intel��Xeon W-3172X����˵����ߴ����Եij����ģCPU������4.5GHz�ĵ����ƵƵ�ʿ��ṩ���CPU����ǿ�ĵ��߳����ܡ� AMD��EPYC 7601����һ�����д����Ե����ݵ㣬��3.2GHz��Ƶ�ʺ�Neoverse N1���еıȣ�ʵ�ʳɼ�����Ҳȷʵ��ˡ� 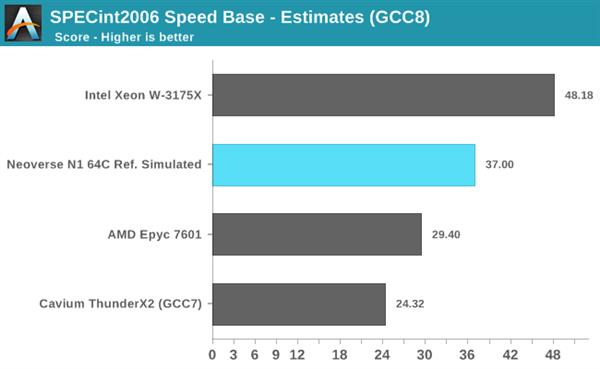
������SPECrate2006�Ķ��̲߳��ԣ���������ƽ̨�������չ������û�����л����̼߳�ͨ�ţ�������ֻ�Dz������ж�����̡� ��ARM������ģ����Խ��������64�˵�Neoverse N1��105�ߵ�TPDʵ���˼��ߵ����ܺ�Ч�ʣ�x86����������������ܹ������� 
��Ȼ���ԱȽϵ���64��ARMƽ̨��32/28��x86ƽ̨��ò��ʹ��AMD�����Ƴ���64��Rome�������Ÿ���ƽ������������������ʹAMD��64�˴�������ʵ��Ŀǰ˫�������ܣ���TDPҲ��̫���ܽ��͵�Neoverse N1����105 �ߵ�ˮƽ��EPYC 7601��TDP ��180�ߣ��� �ܽ� Neoverse N1��������һ������ļܹ�����������ARMһ�����ȵĵ�ԴЧ�ʣ�ʵ���˷�ֵ�������ܺ�����������֮������ƽ�⡣ ARM��Neoverse N1�������յļ����߱��кܸߵ�������ϣ����Intel�ȹ�Ӧ��������x86����������ٹ̵��г��ݶARM���ھ����Ŭ������ȻNeoverse N1�����Ϊ�콢x86�ĺ��ľ������֣����ڿ���������չ��������ĵĹ��������У����ṹ���ش���в�� ��Ȼ����ʵ��Ӳ����Ʒ����֮ǰ�����ǻ��������κζ��ۣ���ARM��ǰ��Cortex A76������Ԥ��dz�����ʵ���豸�ϵIJ��������������������ɸ���Neoverse N1������Ԥ�������Σ�ʵ��Ԥ���е����ܿ϶�����ϣ���ġ� �����µ�Ӳ��IP����ӡ����̣���ͬ����Ҫ����ARM�ڼ�ǿARM������̬ϵͳ�����Ŭ�����벻ͬ��ҵ��Ӳ����������������������ͼ�ٽ�������ջ����ARM�Ļ������ԣ��ⲻ��������ʹ��ARM�Լ���Ӳ��IP�Ĺ�Ӧ�̣�����������ѡ��ʹ���Լ��Ķ���CPU��SoC��ƵĹ�Ӧ�̡�ͬ������Щ��ͼ�Ľ��ͼ�ǿ�Լ���Ʒ�Ĺ�Ӧ�̣�Ҳ����������ǿARM����̬ϵͳ�������ϣ��������˾֮��ļ���Ŭ����δ����������ö����� 
���Կ�����ARM���dz�����ضԴ�������ʩ���裬��ȥ��һ�����ARM��̬ϵͳ��˵�Ǹ����Եģ����ǵ�һ�ο�����ARM����ƽ̨��Intel��AMD���������̾�������ȻARMû��¶˭������ʹ��Neoverse N1ƽ̨����Ϣ����ARM���ɱ粵�س�Ϊ��ҵ������ �ݴ�Neoverse N1����δ��12~18�����ڽ�����ҵ�����⽫��ARM�Ĺؼ�ʱ�̡����һ�н�չ˳����ARM�ͺ������ʵ���˳�ŵ�ĸĽ���δ��1~2�����������ҵ�ؽ�ӭ��һ���ش�ת�䡣 ��ע����������Դ��Anandtech���������룩 |



































































































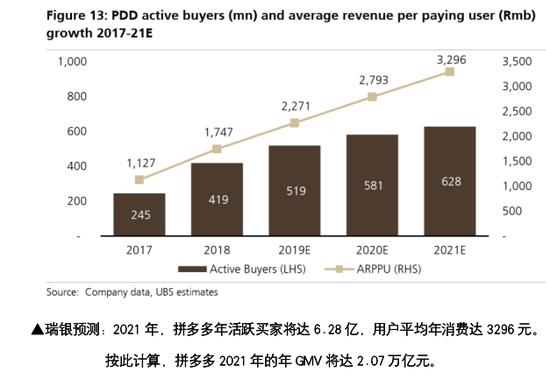





































































































![[MD:Title]](/img/20190311/82a007caf60a4c2f840df051774c2ea9.jpg)





![[MD:Title]](/img/20190311/e1cc541e386048c2b845a43b7cea6d77.jpg)