正文内容 评论(0)

[Core和Yonah的不同点:(四)增加了的解码单元]
Core微架构最明显的变化之一就是增加了一组解码单元,拥有四组解码单元也就是四组指令编译器。首先要说明的是由于X86指令集的指令长度、格式与定址模式都相当复杂,为了简化数据通路的设计,从很久以前开始,X86处理器就采用了将X86指令解码成1个或多个长度相同、格式固定、类似RISC指令形式的微指令的设计方法,尤其是涉及存储器访问的load、store(读取、存储)指令。所以现在的X86处理器的执行单元真正执行的指令是解码后的微指令,而不是X86指令。
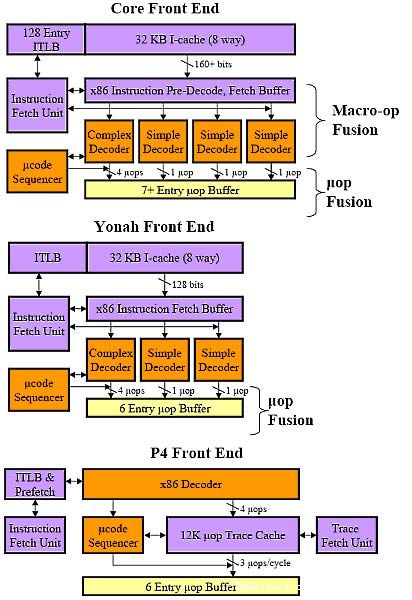
三种架构的解码单元示意图
从图中我们可以很明显地看到Core相对Yonah增加了一组解码单元,Core拥有的四组解码单元由一个复杂解码单元(Complex Decoder)和三个简单解码单元(Simple Decoder)构成,每周期可以生成7条微指令。而Yonah微架构拥有3三个解码单元,由一个复杂解码单元和两个简单解码单元构成,每周期可以生成6条微指令。由于X86指令集的指令长度、格式与定址模式都相当混乱,导致X86指令解码器的设计是非常困难的。因此在处理器市场已经有超过十年的时间,X86处理器世界没有出现过4组解码单元的设计了。而增加解码单元,特别是复杂解码单元,固然会大大增强处理器的解码能力,但是解码单元复杂的电路也必然会提高内核的复杂度和处理器的功耗。Intel在NetBurst微架构的设计中引入Trace Cache来取代占用大量晶体管的复杂解码单元就是出于这个原因。也正是因此我们无法比较解码单元的数量,只能知道NetBurst微架构每周期只能生成3条微指令。
那有一个新的问题,既然前文已经提到增加解码单元会提高内核的复杂度和处理器的功耗那在已经有NetBurst高功耗的前车之鉴下,Intel又为什么采取这些这些增加处理器功耗的改动呢?
经过分析我们可以明白,首先Intel为了提高处理器的效能、命中率和功耗不得不大幅缩短流水线级数,但是随着流水线级数的缩短频率肯定达不到以前的水准,那既要保证低功耗又要保证高性能Intel只得增加执行单元的数量来弥补品率下降带来的性能损失,然而,在执行单元大幅增加的情况下,不增加解码单元就会产生很大的瓶颈。于是Intel采取增加一个简单解码单元的措施是在最小幅度增加功耗的同时保证解码能力的上升,可以说是一个不得不采取的折衷措施。
实质上在解码单元部分Core微架构就是Yonah微架构的翻版,最明显的变化就是增加了一组简单解码单元。同样是古老的Pentium Pro的微架构的延伸,只不过在一个复杂解码单元和两个简单解码单元的基础上增加了一个简单解码单元,一个简单解码单元负责处理对应一条微指令的简单X86指令,而一个复杂解码单元负责处理对应4条微指令的复杂X86指令,这样的解码单元每周期最多能生成7条微指令。Intel一直坚持将简单指令与复杂指令分离就是为了提高简单指令的执行效率(当然,Pentium采取了不同的做法,不过并不成功)。
那难道,Intel进行了那么多年的创新又回到Pentium Pro的老路上了。不得不承认Intel是在照搬以前的模式,不过是“旧瓶装新酒”。那既然说它是旧瓶装新酒那肯定还是有新东西的,那它相对P6位架构最大的变化就是从Yonah开始每个简单解码单元都可以进行128bit SSE指令的解码,而相对于P6这只有复杂解码单元才能胜任。
同样可以得出结论如果Core微架构的所有四组解码单元都具备了这样的能力,那结合微指令融合技术和宏指令融合技术,Core微架构的解码单元的实力就不仅仅是增加一个简单解码单元那么简单了。
本文收录在
#快讯
- 热门文章
- 换一波

- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...