正文内容 评论(0)

[Core和Yonah的不同点:(七)改进的执行单元子系统]
按照Intel的官方说法:Core微架构的执行单元部分拥有3个调度端口,通过这3个端口来调度执行单元。执行单元包括3个64bit的整数执行单元(ALU)、2个128bit的浮点执行单元(FPU)和3个128bit的SSE执行单元。其中,位于端口1的整数执行单元可以处理128bit的Shift和Rotate操作。而2个浮点单元和3个SSE单元可以共享资源。
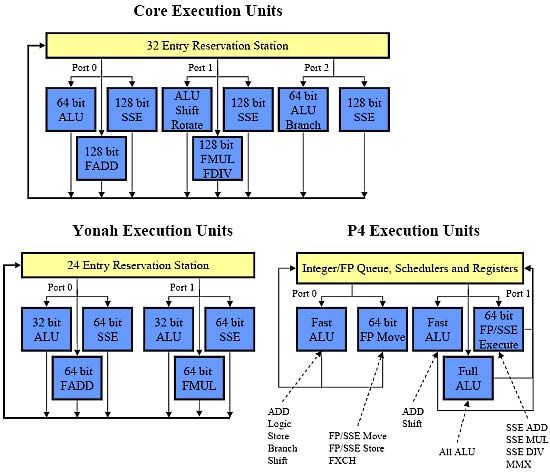
Core、Yonah和NetBurst的执行单元子系统
从图中我们可以明显地看到Core微架构运算单元的改进相对Yonah是大刀阔斧式的,不仅仅像解码单元那样紧紧食粮的增加,而且在运算单元的指令宽度上进行了从新设计,使得实际运算能力有很大的提高。我将其分为整数、浮点数和SSE多媒体指令集三部分加以论述。
Core微架构的调度端口从Yonah微架构和NetBurst微架构的2个端口增加到了3个。Core 微架构的执行单元子系统每个周期最多可以执行3条操作,而Yonah微架构最多只能执行2条操作。不过对于 NetBurst 微架构来说由于其算法不同每个周期最多可以执行4条操作(但前提是必须是4个简单的整数单元操作,不过由于这种情况不大多见,因而实际上NetBurst架构很少能够真正执行4条操作)。而且Core 微架构的功能单元的安排相对平衡,对于整数操作可以在连续多个周期内保证单周期执行3个操作的吞吐量,而NetBurst微架构在很多情况下只能单周期执行1个操作,效率的差别一下拉开了。而且Core微架构的3个64bit的整数执行单元并非完全相同。同样分为1个复杂整数执行单元和2个简单整数执行单元,这种情况已经在解码单元出现过。值得注意的事Core微架构是Intel的X86处理器第一次可以在一周期内完成一次64bit的整数运算,可以大大改善整数运算性能。由于拥有3个整数执行单元端口,所以Core微架构处理器可以在一周期内最多执行3组64bit的整数运算。
既然整数运算有了如此大的提高,那想必浮点数运算也不会弱吧。Core 微构架拥有2个浮点执行单元,位于端口0的浮点执行单元负责加减等简单的浮点运算,位于端口1的浮点执行单元则负责乘除等浮点运算。这样,在Core 微架构中,浮点加减指令与浮点乘除指令被划分成两部分,使其具备了在一周期中完成两条浮点指令的能力。
而且在SSE指令集的运算上也有着同样的改善,3个128bit的SSE运算单元并不完全相同,在移位和乘法的资源方面有微小的差异,但是都可以在单周期内完成1个128bit的 SSE 操作。而NetBurst 微架构只有2个64bit的SSE单元,需要2个周期来执行1个128bit的操作。Yonah 微架构同样只有2个64bit的SSE单元。因此从SSE指令的执行资源来看,Core微架构比Yonah微架构和NetBurst微架构有3倍的性能提升。
本文收录在
#快讯
- 热门文章
- 换一波

- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...