正文内容 评论(0)

承接上文,由于先天性设计的优势,SIMD能够有效提高GPU的矢量处理性能,尤其是在顶点和像素都是4D矢量的时候,只需要一个指令端口就能在单周期内完成预运算,可以做到100%效率运行不浪费运算单元。虽然早期SIMD执行效率很高,因为很多情况都是4D矢量的运算操作。但随着3D技术的不断发展,图形API和Shader指令中的标量运算也开始不断增多,1D/2D/3D混合指令频率出现,这时SIMD架构的弊端就显现出来了。当执行1D标量指令运算的时候,SIMD的效率就会下降到原来的1/4,也就是说在一个运算周期内3/4的运算单元都被浪费了。
混合型SIMD架构的出现
遇到问题的时候,当时的ATI和NVIDIA都在寻求改进。进入DX9时代之后,混合型SIMD设计得到采用,不再使用单纯的4D矢量架构,允许矢量和标量指令可以并行运算(也就是Co-issue技术)。比如当时的ATI的R300就采用了3D矢量+1D标量架构,而NVDIA的NV40之后也采用了2D矢量+2D标量和3D矢量+1D标量两种运算模式。虽然Co-isuue技术一定程度上解决了SIMD架构标量指令执行率低的问题,但遇到需要分支预测运算的情况,依然无法发挥ALU的最大运算能力。
除了SIMD架构的弊端之外,VS和PS构成的所谓“分离式”渲染架构也遭遇了麻烦。在全新一代图形API DirectX 10的到来之前,顶点渲染和像素渲染各自独立进行,而且一旦当架构确定下来,VS和PS的比例就会固定。微软认为这种分离渲染架构不够灵活,不同的GPU,其VS和PS的比例不一样,大大限制了开发人员自由发挥的空间。另外,不同的应用程序和游戏对像素渲染和顶点渲染的需求不一样,导致GPU的运算资源得不到充分利用。
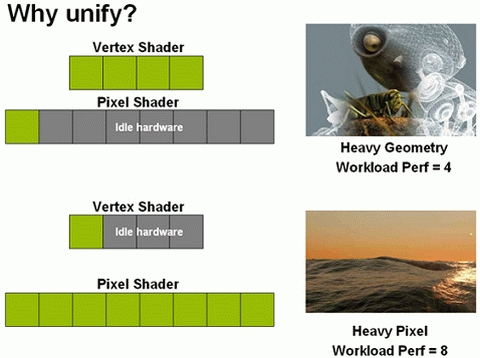
分离式渲染架构:VS和PS负载不均

统一渲染架构:VS和PS负载均衡
举例来说,许多大型3D游戏中的独立渲染场景中,遇到高负载几何工作的时候,VS处理压力增大大,而PS单元工作较少很多时候都被闲置;反之,遇到高负载像素工作的时候,PS处理压力增大,而VS又处于闲置状态。加上传统的PS和VS以前都是各自为战,彼此不相干涉,PS也帮不上VS任何忙,也就造成了GPU执行效率的降低。传统的管线架构已经跟不上时代了,而这也就促使了DirectX 10中统一渲染架构(Unified Shader Architecture)的出现。
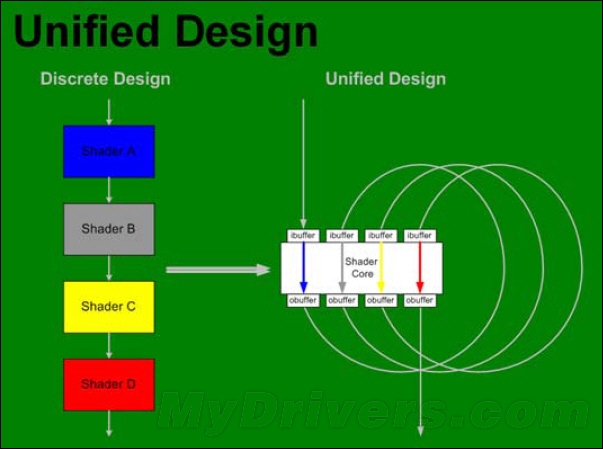
分离式架构和统一架构的差异
所谓统一渲染架构,就是将传统的VS、PS以及DirectX 10新引入的GS进行统一分装。与传统GPU架构不同,此时的GPU不再分配单独的渲染管线,所有的运算单元都可以处理任何一种Shader运算(不论顶点操作、像素操作还是几何操作),而这种运算单元就是经常提到的统一渲染单元(Unified Shader,US)。它的出现避免了传统GPU架构中PS和VS资源分配不合理的现象,也使得GPU的利用率更高。US的概念一直沿用至今,一般来说US的数量越多,GPU的3D渲染执行能力就越强,所以US的数量也就成了判断显卡性能的一个主要标准。
本文收录在
#快讯
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...