正文内容 评论(0)
二、物理寄存器文件(PRF)和执行改进
类似于AMD的推土机、山猫,Intel SNB也使用了物理寄存器文件。Core 2、Nehalem架构中,每个微指令需要的每个操作数都有一份拷贝,这就意味着乱序执行硬件(调度器/重排序缓存/关联队列)必须要非常大,以便容纳微指令和相关数据。Core Duo时代是80-bit,加入SSE指令集后增至128-bit,现在又有了AVX指令集,按照趋势会翻番至256-bit。
RPF在寄存器文件中存储微指令操作数,而微指令在乱序执行引擎中只会携带指向操作数的指针,而非数据本身。这就大大降低了乱序执行硬件的功耗(转移大量数据很费电的),同时也减小了流水线的核心面积,数据流窗口也增大了三分之一。
核心面积的精简正是AVX指令(SNB最主要革新之一)集得以实现并保证良好性能的关键所在。以最小的核心面积代价,Intel将所有SIMD单元都转向了256-bit。
AVX支持256-bit操作数,相当消耗晶体管与核心面积,而RPF的使用加大了乱序执行缓冲,能够很好地满足更高吞吐量的浮点引擎。

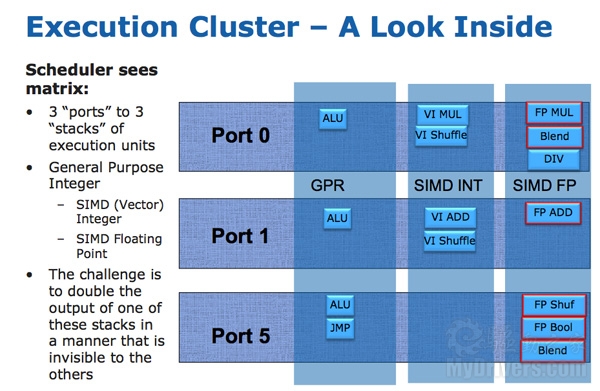
Nehalem架构中有三个执行端口和三个执行单元堆栈:
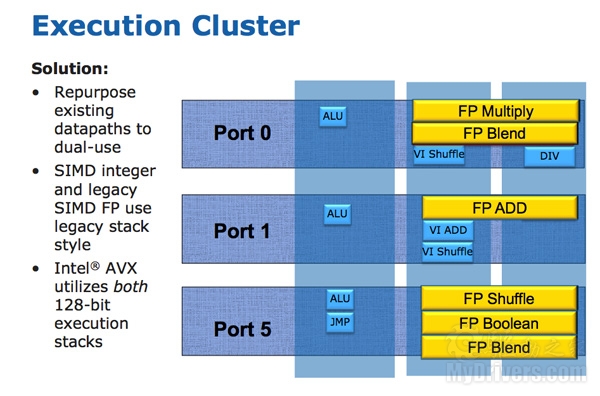
SNB允许256-bit AVX指令借用128-bit的整数SIMD数据路径,这就使用最小的核心面积实现了双倍的浮点吞吐量,每个时钟可以进行两个256-bit AVX操作。另外执行硬件和路径的上位128-bit是受电源栅极(Power Gate)控制的,标准128-bit SSE操作不会因为256-bit扩展而增加功耗。
AMD推土机架构对AVX的支持则有所不同,使用了两个128-bit SSE路径来合并成256-bit AVX操作,即使八核心(四模块)推土机的256-bit AVX吞吐量也要比四核心SNB少一半,不过实际影响完全取决于应用程序如何利用AVX。
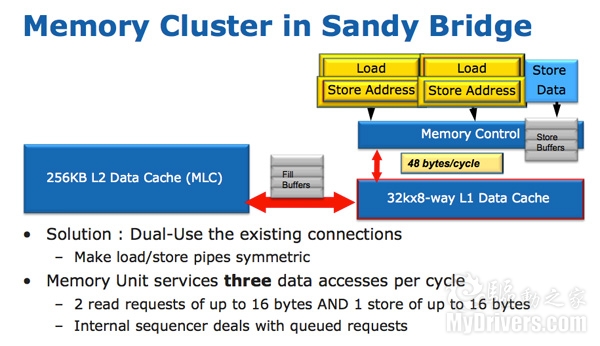
SNB的峰值浮点性能翻了一番,这就对载入和存储单元提出了更高要求。Nehalem/Westmere架构中有三个载入和存储端口:载入、存储地址、存储数据。
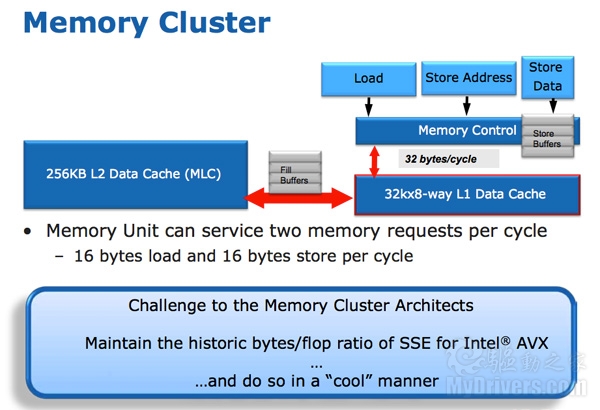
SNB架构中载入和存储地址端口是对称的,都可以执行载入或者存储地址,载入带宽因此翻倍。
SNB的整数执行也有了改进,只是比较有限。ADC指令吞吐量翻番,乘法运算可加速25%。

本文收录在
#快讯
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...