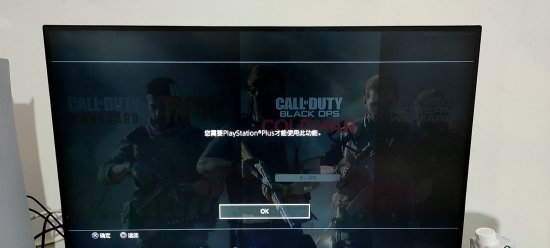
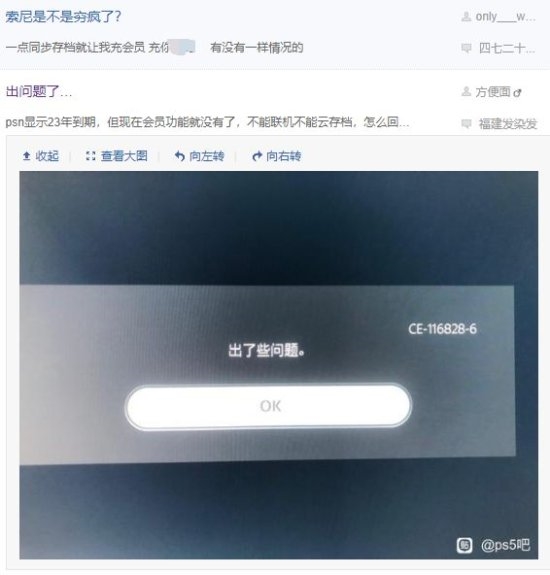
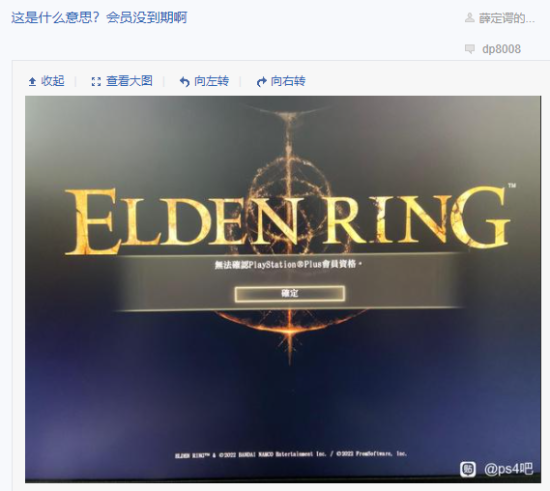
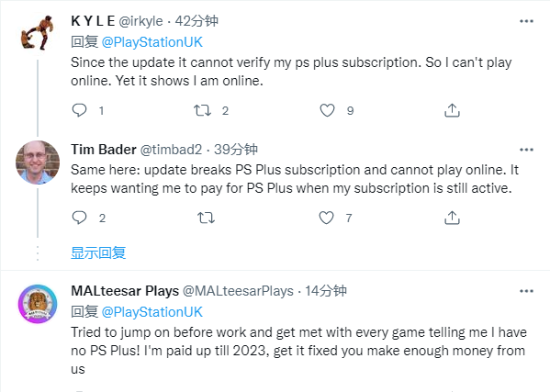
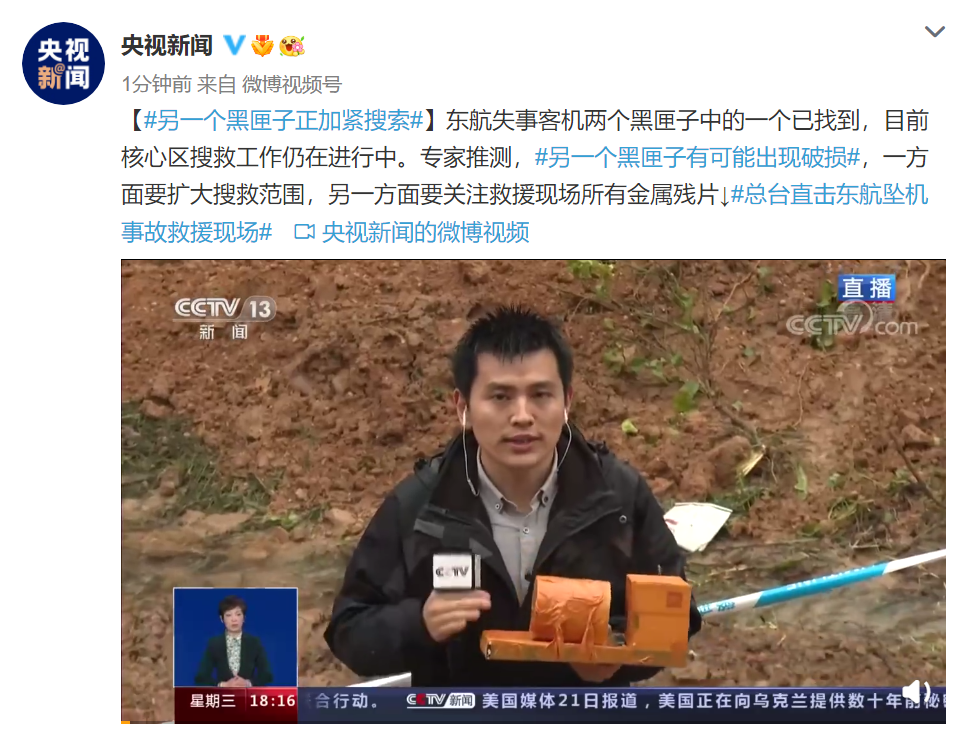
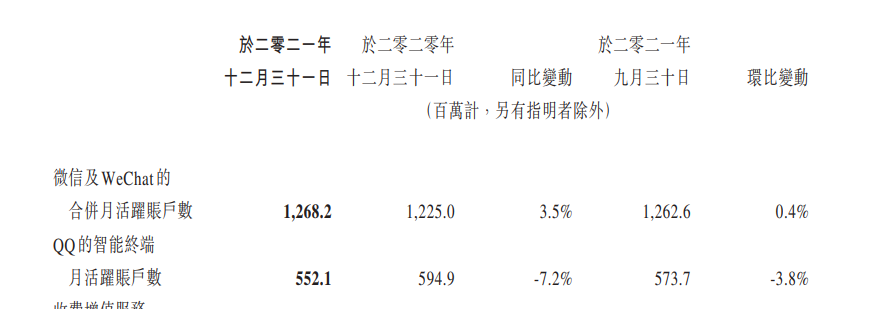
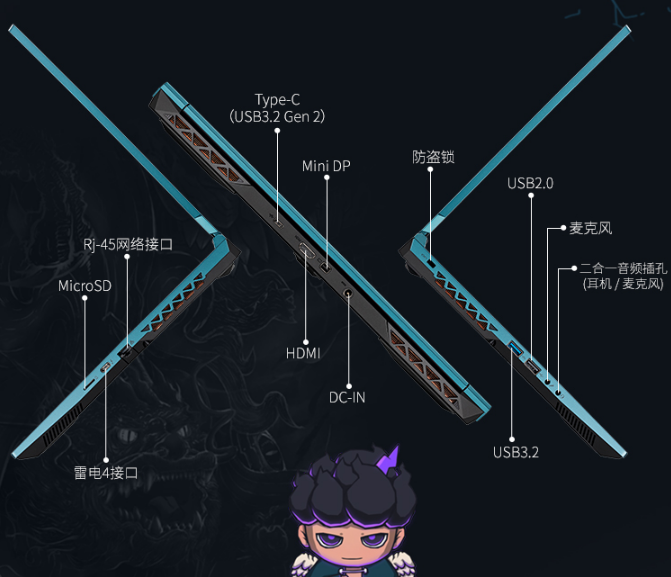
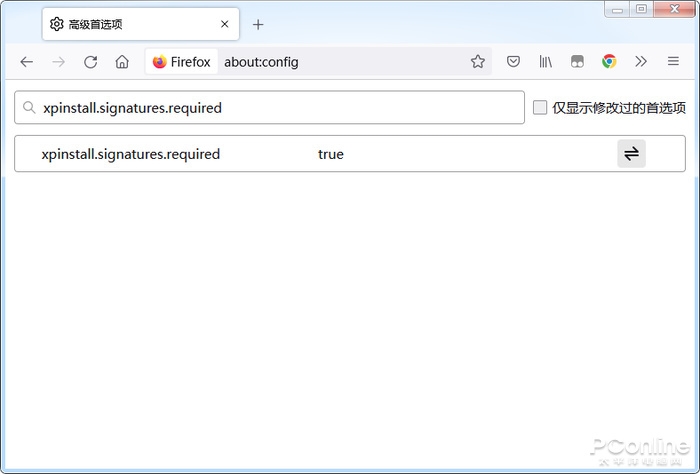
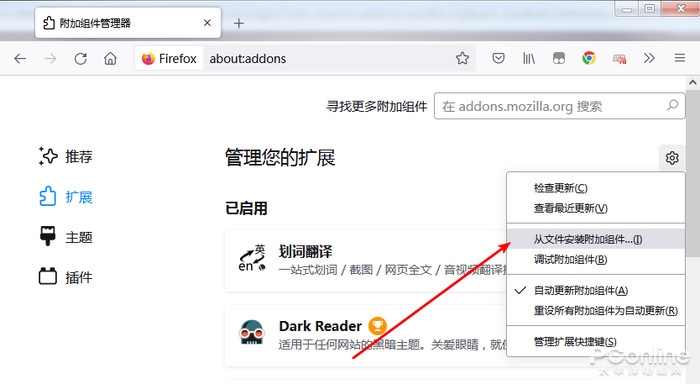
ЫћРДСЫЫћРДСЫЃЌРЯЛЦДјзХгЂЮАДяЕФзюаТвЛДњGPUРДСЫЁЃ

жЎЧАДѓМвВТЕФ5nmДэСЫЃЌвЛЪжДѓОЊЯВЃЌРЯЛЦжБНгЩЯСЫЬЈЛ§Еч4nmЙЄвеЁЃ
аТПЈШЁУћH100ЃЌВЩгУШЋаТHopperМмЙЙЃЌжБНгМЏГЩСЫ800вкИіОЇЬхЙмЃЌБШЩЯвЛДњA100зузуЖрСЫ260вкИіЁЃ

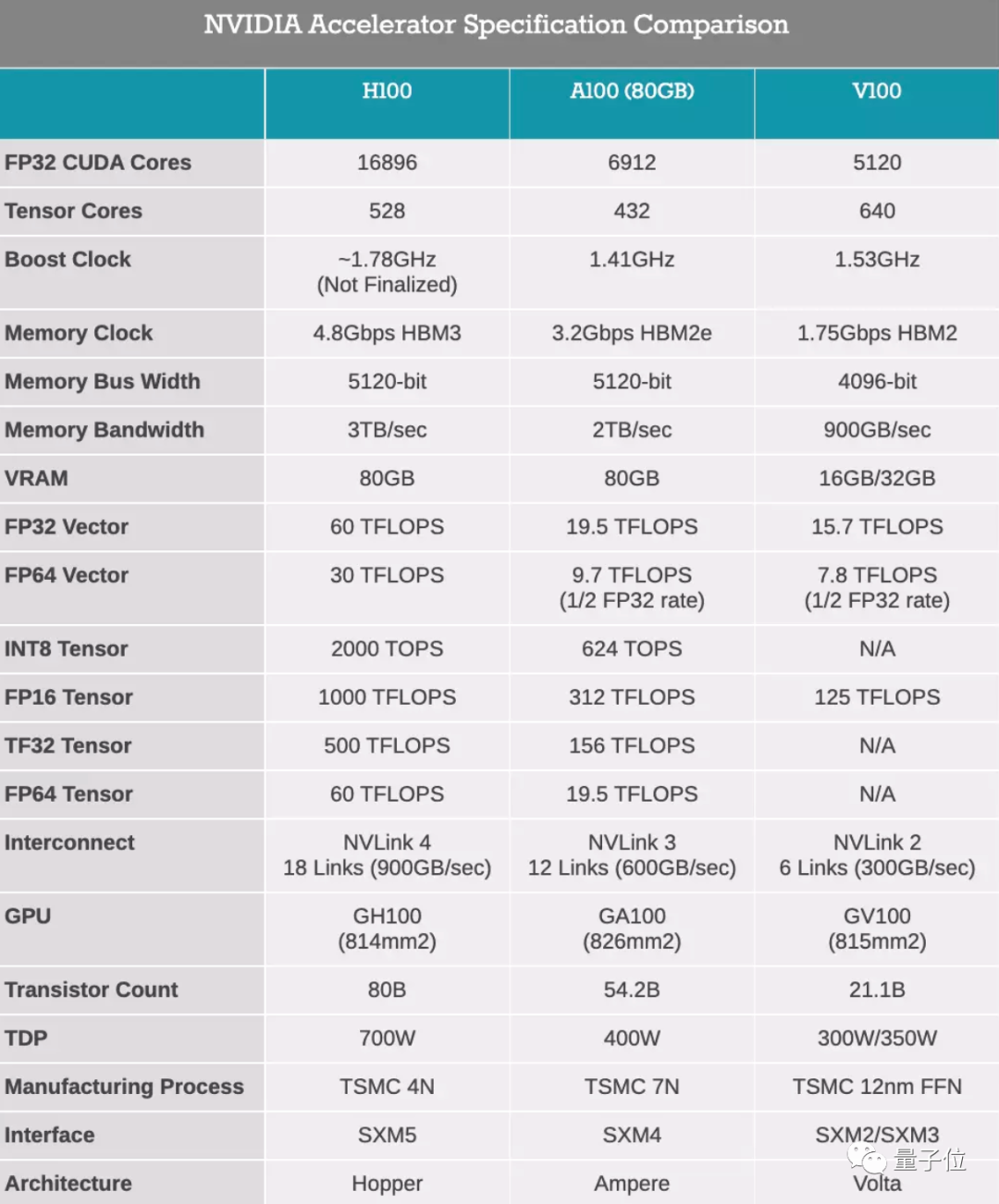
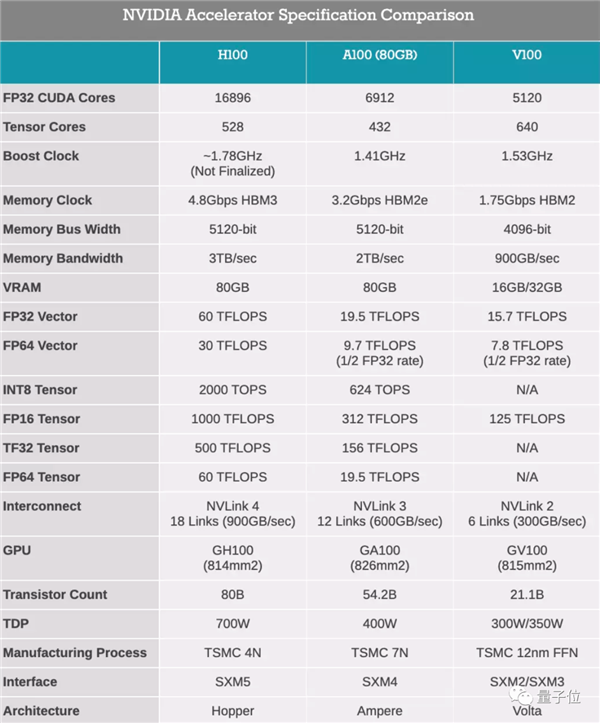
ФкКЫЪ§СПдђьЕНСЫЧАЫљЮДгаЕФ16896ИіЃЌДяЕНЩЯвЛДњA100ПЈЕФ2.5БЖЁЃ
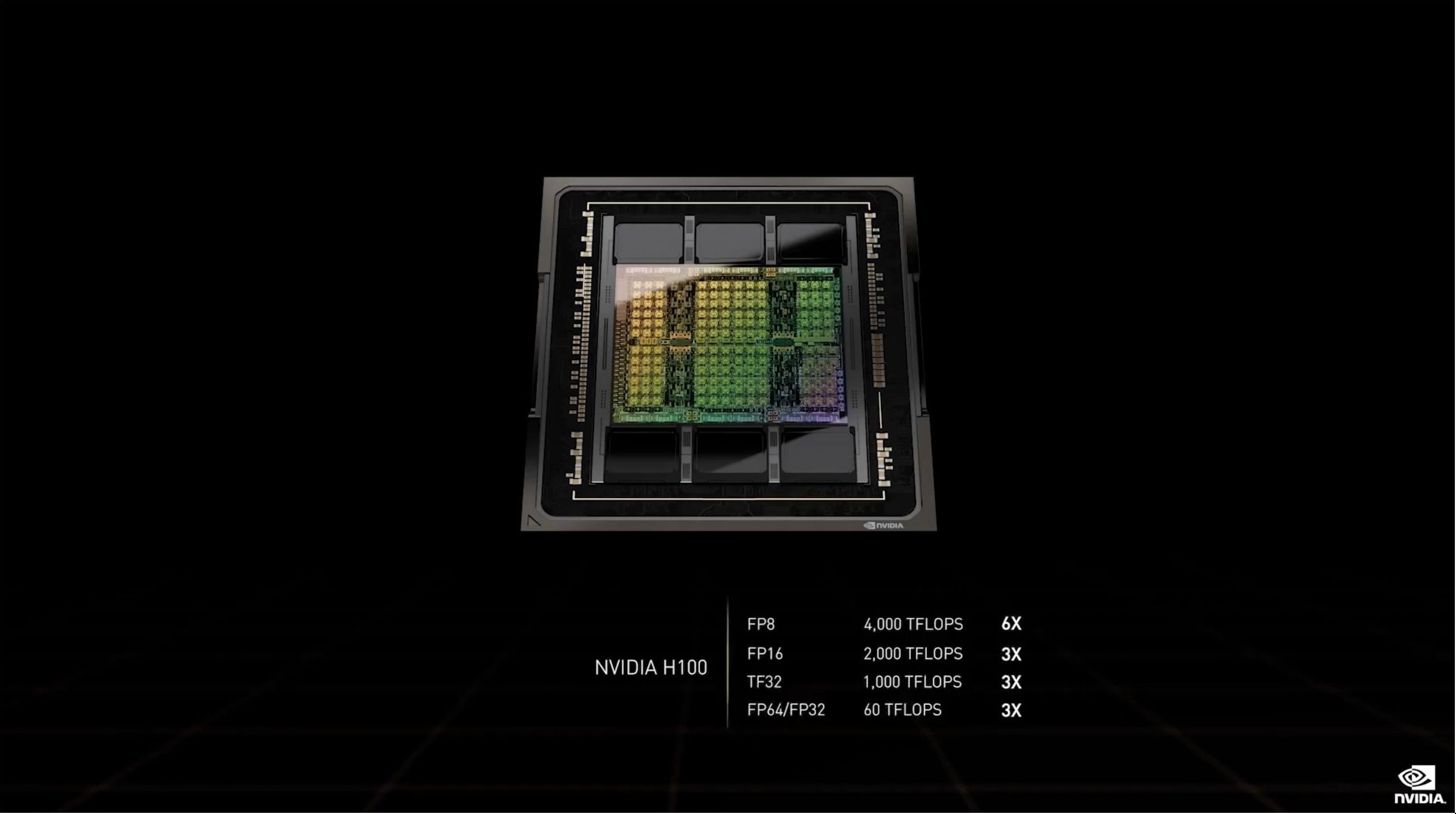
ИЁЕуМЦЫуКЭеХСПКЫаФдЫЫуФмСІвВЫцжЎЗСЫжСЩй3БЖЃЌБШШчFP32ОЭДяЕНСЫДяЕН60ЭђвкДЮ/УыЁЃ
ЬиБ№зЂвтЕФЪЧЃЌH100УцЯђAIМЦЫуЃЌеыЖдTransformerДюдиСЫгХЛЏв§ЧцЃЌШУДѓФЃаЭбЕСЗЫйЖШжБНг x 6ЁЃ
ЃЈПЩЫужЊЕР5300вкВЮЪ§ЕФЭўе№Ьь-ЭМСщБГКѓЕФУиОїСЫЁЃЃЉ
зїЮЊвЛПюадФмБЌеЈЕФШЋаТGPUЃЌВЛГівтЭтЃЌH100НЋгыЧАБВV100ЁЂA100вЛбљГЩЮЊAIДгвЕепаФаФФюФюЕФДѓБІБДЁЃ
ВЛЙ§ВЛЕУВЛЬсЃЌЫќЕФЙІКФвВБЌеЈСЫЃЌДяЕНСЫЪЗЮоЧАР§ЕФ700WЃЌжиЛиКЫЕЏМЖБ№ЁЃ
ЙигкздбаЕФGrace CPUЃЌетДЮДѓЛсвВЙЋВМСЫИќЖрЯИНкЁЃ
УЛЯыЕНЃЌРЯЛЦДгПтПЫФЧРябЇРДвЛЪж1+1=2ЃЌСНПщCPU“еГ”дквЛЦ№зщГЩСЫCPUГЌМЖаОЦЌ——Grace CPU SuperchipЁЃ
Grace CPUВЩгУзюаТArm v9МмЙЙЃЌСНПщзмЙВгЕга144ИіКЫаФЃЌгЕга1TB/sЕФФкДцДјПэЃЌБШЦЛЙћзюаТM1 UltraЕФ800GB/sЛЙИпГівЛНиЁЃ

ЛљгкШЋаТCPUЁЂGPUЛљДЁгВМўЃЌетДЮЗЂВМЛсвВДјРДСЫЯТвЛДњЦѓвЕМЖAIЛљДЁЩшЪЉDXG H100ЁЂШЋЧђзюПьAIГЌЫуEosЁЃ
ЕБШЛЃЌгЂЮАДязїЮЊеце§ЕФдЊгюжцЯШЧ§ЃЌвВЩйВЛСЫOmniverseЩЯЕФаТНјеЙЁЃ
ЯТУцОпЬхРДПДПДЁЃ
ЪзПюHopperМмЙЙGPUЃЌадФмБЉді
зїЮЊЩЯвЛДњGPUМмЙЙA100ЃЈАВХрМмЙЙЃЉЕФМЬГаепЃЌДюдиСЫШЋаТHopperМмЙЙЕФH100гаЖрЭЛЗЩУЭНјЃП

ЛАВЛЖрЫЕЃЌЯШЩЯВЮЪ§ЃК
РЯЛЦПЩЮНЯТбЊБОЃЌЯШЪЧжБНгВЩгУСЫЬЈЛ§Еч4nmЙЄвеЃЌОЇЬхЙмвЛПкЦјМЏГЩСЫ800вкИіЁЃ
вЊжЊЕРЃЌЩЯвЛДњA100ЛЙжЛЪЧ7nmМмЙЙЃЌетДЮЗЂВМЛсГіРДЧАЃЌЭтНчВЛЩйЩљвєВТВтРЯЛЦЛсгУ5nmжЦГЬЃЌНсЙћвЛЗЂВМОЭИјДѓМвРДСЫИіДѓОЊЯВЁЃ
зюПжВРЕФЪЧCUDAКЫаФжБНгьЩ§ЕНСЫ16896ИіЃЌжБНгДяЕНСЫA100ЕФНќ2.5БЖЁЃЃЈвЊжЊЕРДгV100ЕНA100ЕФЪБКђЃЌКЫаФвВВЛЙ§діМгФЧУДвЛЫПЫПЃЉ
етДЮПЩВЛФмИаПЎРЯЛЦЕЖЗЈОЋзМСЫЁЃ
дйПДИЁЕудЫЫуКЭINT8/FP16/TF32/FP64ЕФеХСПдЫЫуЃЌадФмЛљБОШЋВПЬсЩ§3БЖВЛжЙЃЌЯрБШРДПДЃЌЧАСНДњЕФМмЙЙЩ§МЖвВЯдЕУаЁДђаЁФжЁЃ
етвВЪЙЕУH100ЕФШШЙІКФЃЈTDPЃЉжБНгДяЕНСЫЧАЫљЮДгаЕФ700wЃЌгЂЮАДя“КЫЕЏЙЄГЇ”УћИБЦфЪЕЃЈЪжЖЏЙЗЭЗЃЉЁЃ

ЛАгжЫЕЛиРДЃЌетДЮH100вВЪЧЪзПюжЇГжPCle 5.0КЭHBM3ЕФGPUЃЌЪ§ОнДІРэЫйЖШНјвЛВНЗЩЩ§——ФкДцДјПэДяЕНСЫ3TB/sЁЃ
етЪЧЪВУДИХФюЃП
РЯЛЦдкЗЂВМЛсЩЯЩёУивЛаІЃКжЛашвЊ20ИіH100дкЪжЃЌШЋЧђЛЅСЊЭјСїСПЮвгаЁЃ
ећЬхВЮЪ§ЯИНкОПОЙШчКЮЃЌгыЧАДњA100КЭV100ЖдБШвЛЯТОЭжЊЕРСЫЃК
ЁїЭМдД@anandtech
жЕЕУвЛЬсЕФЪЧЃЌHopperМмЙЙЕФаТGPUКЭгЂЮАДяCPU GraceУћзжзщдквЛЦ№ЃЌОЭГЩСЫжјУћХЎадМЦЫуЛњПЦбЇМвGrace HopperЕФУћзжЃЌетвВБЛгЂЮАДягУгкУќУћЫћУЧЕФГЌМЖаОЦЌЁЃ
Grace HopperЗЂУїСЫЪРНчЩЯЕквЛИіБрвыЦїКЭCOBOLгябдЃЌга“МЦЫуЛњШэМўЙЄГЬЕквЛЗђШЫ”жЎГЦЁЃ
бЕСЗ3950вкВЮЪ§ДѓФЃаЭНі1Ьь
ЕБШЛЃЌHopperЕФаТЬиаддЖВЛжЙЬхЯждкВЮЪ§ЩЯЁЃ
етДЮЃЌРЯЛЦЬивтдкЗЂВМЛсЩЯзХжиЬсЕНСЫHopperЪзДЮХфБИЕФTransformerв§ЧцЁЃ
рХЃЌзЈЮЊTransformerДђдьЃЌШУетРрФЃаЭдкбЕСЗЪББЃГжОЋЖШВЛБфЁЂадФмЬсЩ§6БЖЃЌвтЮЖзХбЕСЗЪБМфДгМИжмЫѕЖЬжСМИЬьЁЃ
дѕУДБэЯжЃП
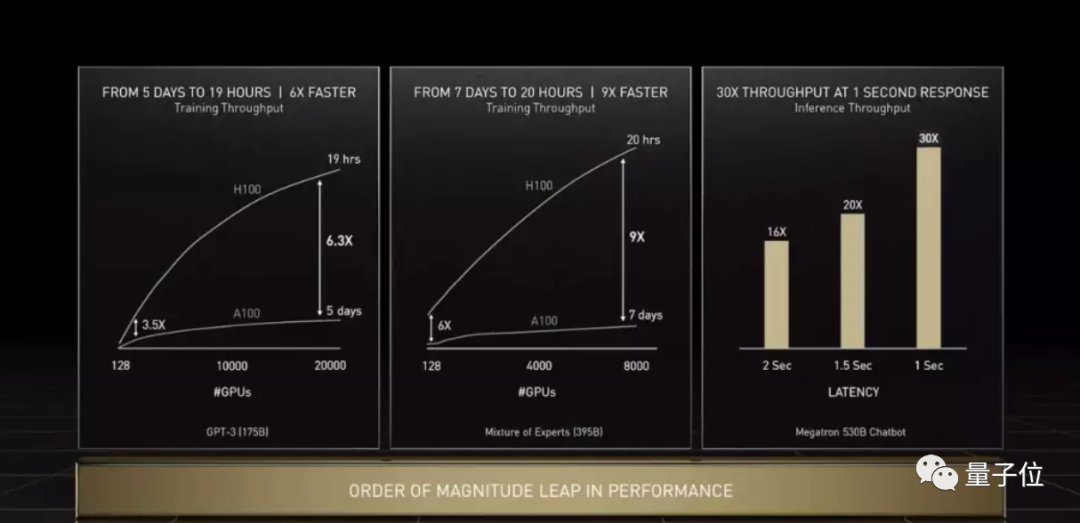
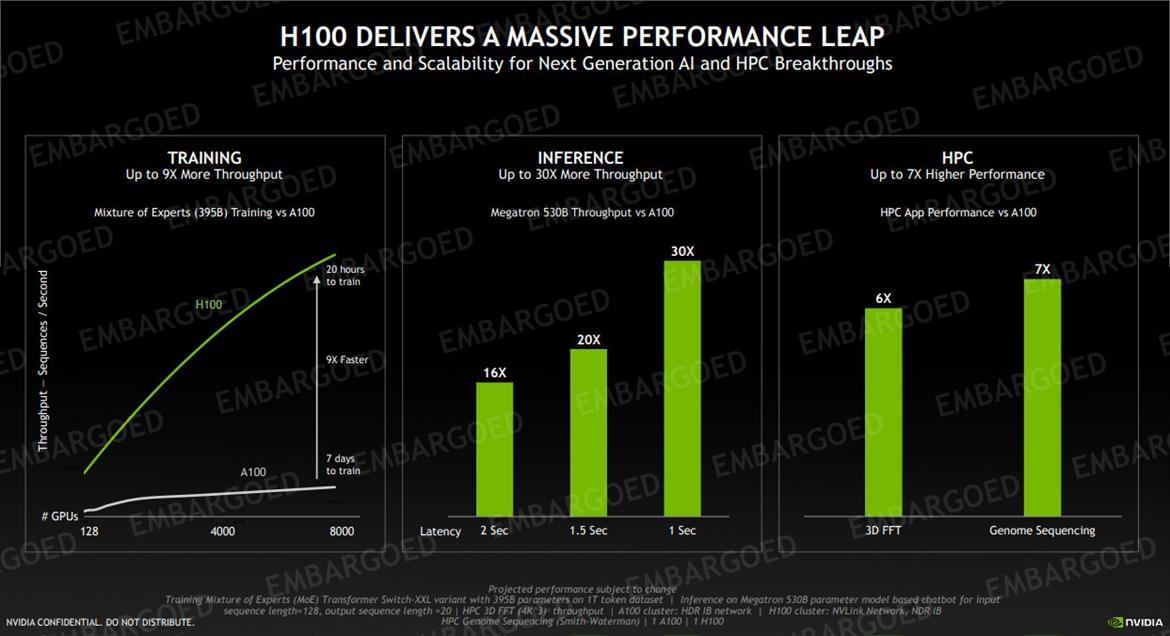
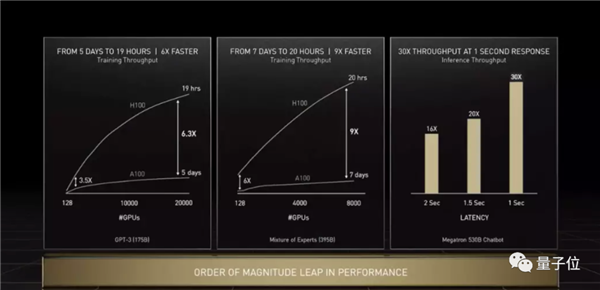
ЯждкЃЌЮоТлЪЧбЕСЗ1750вкВЮЪ§ЕФGPT-3 ЃЈ19аЁЪБЃЉЃЌЛЙЪЧ3950вкВЮЪ§ЕФTransformerДѓФЃаЭЃЈ21аЁЪБЃЉЃЌH100ЖМФмНЋбЕСЗЪБМфДгвЛжмЫѕЖЬЕН1ЬьжЎФкЃЌЫйЖШЬсЩ§ИпДя9БЖЁЃ
ЭЦРэадФмвВЪЧДѓЗљЬсЩ§ЃЌЯёгЂЮАДяЭЦГіЕФ5300вк MegatronФЃаЭЃЌдкH100ЩЯЭЦРэЪБЕФЭЬЭТСПБШA100жБНгИпГі30БЖЃЌЯьгІбгГйНЕЕЭЕН1УыЃЌПЩвдЫЕЪЧЭъУРholdзЁСЫЁЃ
ВЛЕУВЛЫЕЃЌгЂЮАДяетВЈШЗЪЕЭЛШыСЫTransformerеѓгЊЁЃ
дкДЫжЎЧАЃЌгЂЮАДявЛЯЕСаGPUгХЛЏЩшМЦЛљБОЖМЪЧеыЖдОэЛ§МмЙЙНјааЕФЃЌНгНќвЊАб“I love ОэЛ§”етМИИізжгЁдкФдУХЩЯЁЃ
вЊЙжжЛЙжTransformerзюНќЪЕдкЬЋЪмЛЖгЁЃЃЈЪжЖЏЙЗЭЗЃЉ
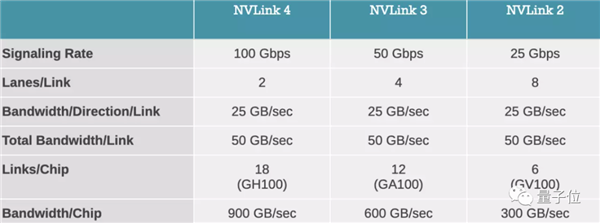
ЕБШЛЃЌH100ЕФССЕуВЛжЙШчДЫЃЌАщЫцзХЫќвдМАгЂЮАДявЛЯЕСааОЦЌЃЌЫцКѓЖМЛсв§ШыNVIDIA NVLinkЕкЫФДњЛЅСЌММЪѕЁЃ
вВОЭЪЧЫЕЃЌаОЦЌЖбЖбРжЕФаЇТЪИќИпСЫЃЌI/OДјПэИќЪЧРЉеЙжС900GB/sЁЃ
етДЮЃЌРЯЛЦЛЙзХжиЬсЕНСЫGPUЕФАВШЋадЃЌАќРЈЪЕР§жЎМфОпгаИєРыБЃЛЄЁЂаТGPUОпгаЛњУмМЦЫуЙІФмЕШЁЃ
ЕБШЛЃЌЪ§бЇМЦЫуФмСІвВЬсЩ§СЫЁЃ
етДЮH100ЩЯаТЕФDPXжИСюПЩвдМгЫйЖЏЬЌЙцЛЎЃЌдкдЫЫуТЗОЖгХЛЏКЭЛљвђзщбЇдкФкЕФвЛЯЕСаЖЏЬЌЙцЛЎЫуЗЈЪБЫйЖШЬсЩ§СЫ7БЖЁЃ
ОнРЯЛЦНщЩмЃЌH100ЛсдкНёФъЕкШ§МОЖШПЊЪМЙЉЛѕЃЌЭјгбЕїйЉ“ЙРМЦвВБувЫВЛСЫ”ЁЃ
ФПЧАЃЌH100гаСНИіАцБОПЩбЁЃК
вЛИіОЭЪЧЙІТЪИпДя700WЕФSXMЃЌгУгкИпадФмЗўЮёЦїЃЛСэвЛИіЪЧЪЪгУгкИќжїСїЕФЗўЮёЦїPCIeЃЌЙІКФвВБШЩЯвЛДњA100ЕФ300WЖрСЫ50WЁЃ
4608ПщH100ЃЌДђдьШЋЧђзюПьAIГЌЫу
H100ЖМЗЂВМСЫЃЌРЯЛЦздШЛВЛЛсЗХЙ§ШЮКЮвЛИіДюНЈГЌМЖМЦЫуЛњЕФЛњЛсЁЃ
ЛљгкH100ЭЦГіЕФзюаТDGX H100МЦЫуЯЕЭГЃЌгыЩЯвЛДњ“ПОЯф”вЛбљЃЌЭЌбљвВЪЧХфБИ8ПщGPUЁЃ

ВЛЭЌЕФЪЧЃЌDGX H100ЯЕЭГдкFP8ОЋЖШЯТДяЕНСЫ32 PetaflopЕФAIадФмЃЌБШЩЯвЛДњDGX A100ЯЕЭГећећИпСЫ6БЖЁЃ
ИїGPUжЎМфЕФСЌНгЫйЖШвВБфЕУИќПьЃЌ900GB/sЕФЫйЖШНгНќЩЯвЛДњЕФ1.5БЖЁЃ
зюЙиМќЕФЪЧЃЌетДЮгЂЮАДяЛЙдкDGX H100ЛљДЁЩЯЃЌДюНЈСЫвЛЬЈEosГЌМЖМЦЫуЛњЃЌвЛОйГЩЮЊAIГЌЫуНчЕФадФмTOP 1——
ЙтОЭ18.4 ExaflopsЕФAIМЦЫуадФмЃЌОЭБШШеБОЕФ“ИЛдР”ЃЈFugakuЃЉГЌМЖМЦЫуЛњПьСЫ4БЖЁЃ
етЬЈГЌЫуХфБИСЫ576ИіDGX H100ЯЕЭГЃЌжБНггУСЫ4608ПщH100ЁЃ
МДЪЙЪЧДЋЭГПЦбЇМЦЫуЃЌЫуСІвВФмДяЕН275 Petaflops ЃЈИЛдРЪЧ442 PetaflopsЃЉЃЌѕвЩэЧА5ЕФГЌЫуЪЧУЛЪВУДЮЪЬтЁЃ

“ЦДзА”CPUЃЌХмЗжГЩСЫTOP1
БОДЮGTCДѓЛсЃЌРЯЛЦШдШЛ“ЬсСЫМИзь”ГЌМЖЗўЮёЦїаОЦЌGraceЁЃ
ЫќдкШЅФъ4дТЗнЕФGTCДѓЛсОЭвбОгаЫљССЯрЃЌКЭЕБЪБвЛбљЃЌРЯЛЦБэЪОЃКгаЭћ2023ФъПЩвдПЊЪМЙЉЛѕЃЌЗДе§НёФъЪЧВЛПЩФмХіЩЯСЫЁЃ
ВЛЙ§ЃЌGraceЕФадФмЕЙЪЧжЕЕУвЛЬсЃЌгаСЫ“ОЊШЫНјеЙ”ЁЃ
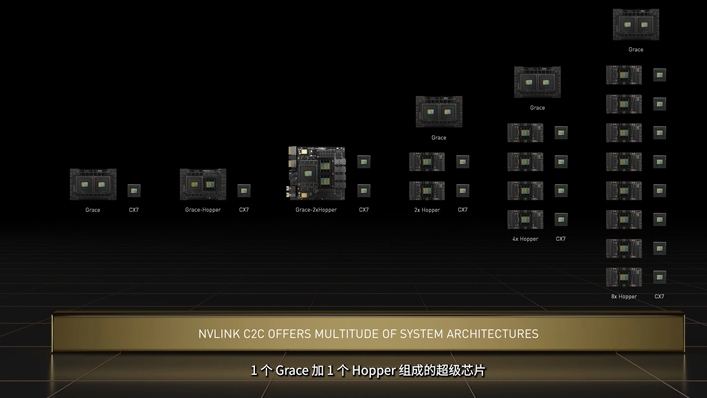
ЫќБЛгУдкСНИіГЌМЖаОЦЌжаЃК
вЛИіЪЧGrace HopperГЌМЖаОЦЌЃЌЕЅMCMЃЌгЩвЛИіGrace CPUКЭвЛИіHopperМмЙЙЕФGPUзщГЩЁЃ
вЛИіЪЧGrace CPUГЌМЖаОЦЌЃЌгЩСНИіGrace CPUзщГЩЃЌЭЈЙ§NVIDIA NVLink-C2CММЪѕЛЅСЌЃЌАќРЈ144ИіArmКЫаФЃЌВЂгазХИпДя1TB/sЕФФкДцДјПэ——ДјПэЬсЩ§2БЖЕФЭЌЪБЃЌФмКФ“жЛвЊ”500wЁЃ

КмФбВЛШУШЫСЊЯыЕНЦЛЙћИеЗЂЕФM1 UltraЃЌПДРДЦЌМфЛЅСЌММЪѕЕФНјеЙЃЌШУ“ЦДзА”ГЩСЫаОЦЌаавЕвЛДѓЧїЪЦЁЃ

GraceГЌМЖаОЦЌдкSPECrate?2017_int_baseЛљзМВтЪджаЕФФЃФтадФмДяЕНСЫ740ЗжЃЌЪЧЕБЧАDGX A100 ДюдиЕФCPUЕФ1.5БЖЃЈ460ЗжЃЉЁЃ
GraceГЌМЖаОЦЌПЩвддЫаадкЫљгаЕФNVIDIAМЦЫуЦНЬЈЃЌМШПЩзїЮЊЖРСЂЕФДПCPUЯЕЭГЃЌвВПЩзїЮЊ GPUМгЫйЗўЮёЦїЃЌРћгУNVLink-C2CММЪѕДюдивЛПщжСАЫПщЛљгкHopperМмЙЙЕФGPUЁЃ

ЃЈрХЃЌИеЫЕЭъЃЌРЯЛЦЕФаОЦЌЖбЖбРжОЭЖбЩЯСЫЁЃЃЉ
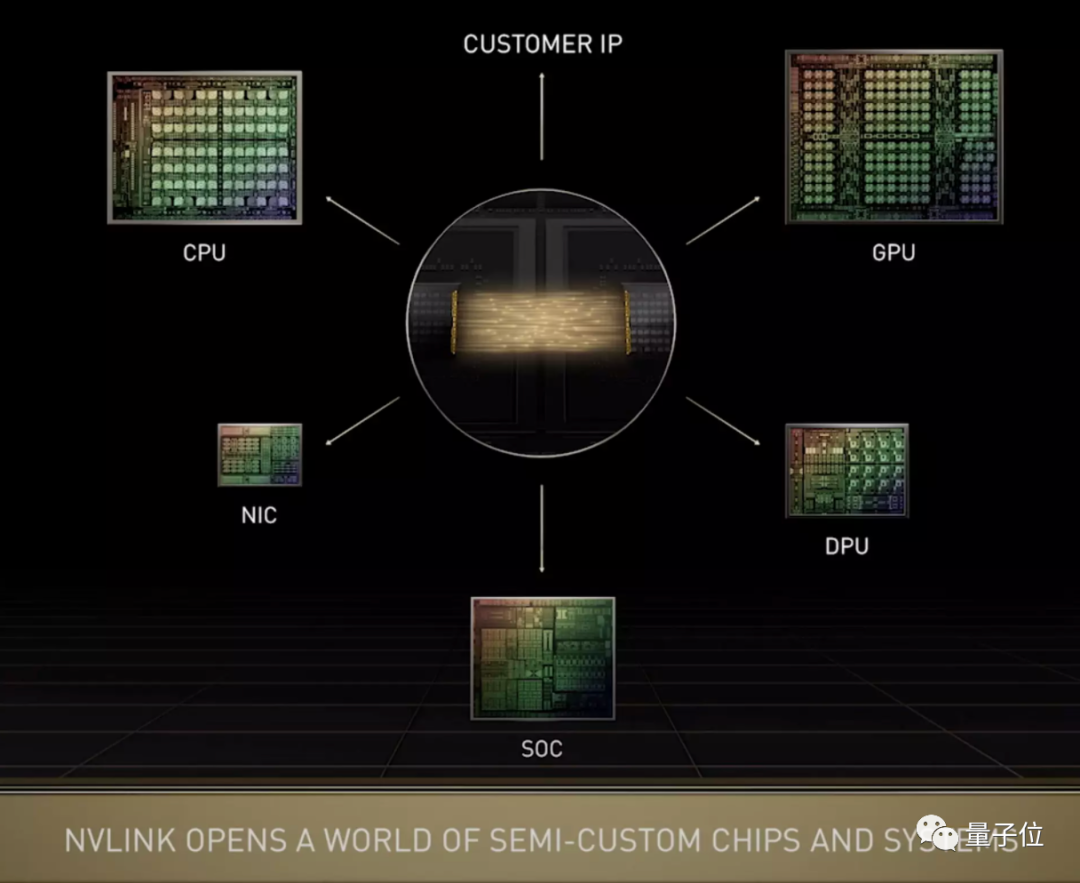
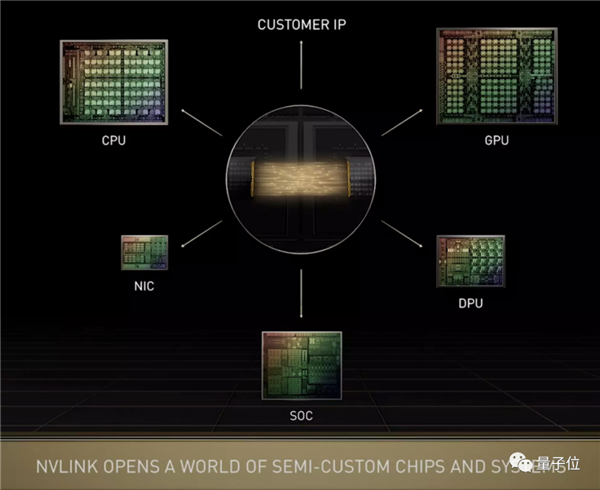
жЕЕУвЛЬсЕФЪЧЃЌгЂЮАДяЖдЕкШ§ЗНЖЈжЦаОЦЌПЊЗХСЫNVLink-C2CЁЃ
ЫќЪЧвЛжжГЌПьЫйЕФаОЦЌЕНаОЦЌЁЂТуЦЌЕНТуЦЌЕФЛЅСЌММЪѕЃЌНЋжЇГжЖЈжЦТуЦЌгыNVIDIA GPUЁЂCPUЁЂDPUЁЂNIC КЭSOCжЎМфЪЕЯжвЛжТЕФЛЅСЌЁЃ
ЛђаэЃЌШЮЬьЬУаТеЦЛњПЩвдЦкД§вЛВЈЃП
СЌЙЄвЕвВвЊдкдЊгюжцРяИу
ЕБШЛЃЌГ§СЫЩЯЪіФкШнжЎЭтЃЌетДЮгЂЮАДявВЭИТЖСЫВЛЩйгыЙЄвЕгІгУЯрЙиЕФАИР§ЁЃ
ЖјЮоТлЪЧздЖЏМнЪЛЁЂЛЙЪЧАќРЈащФтЙЄГЇЕФЪ§зжТЯЩњЕШГЁОАЃЌЖМгыМЦЫуЛњфжШОКЭЗТецММЪѕгазХУмВЛПЩЗжЕФЙиЯЕЁЃ
гЂЮАДяШЯЮЊЃЌЙЄвЕЩЯЭЌбљФмЭЈЙ§дкащФтЛЗОГжаФЃФтЕФЗНЪНЃЌРДдіМгAIбЕСЗЕФЪ§ОнСПЃЌЛЛЖјбджЎОЭЪЧ“дкдЊгюжцРяИуДѓбЕСЗ”ЁЃ
Р§ШчЃЌШУAIжЧФмМнЪЛдкдЊгюжцРя“СЗГЕ”ЃЌРћгУЗТецГіРДЕФЪ§ОнИуГіАыецЪЕЛЗОГЃЌдіМгвЛаЉПЩФмЭЛЗЂЙЪеЯЕФЛЗОГФЃФтЃК

гжР§ШчЃЌИуГіЕШБШР§ЁЂгыЯжЪЕЛЗОГжаВФСЯЕШВЮЪ§ЭъШЋвЛбљЕФ“Ъ§зжЙЄГЇ”ЃЌдкНЈдьЧАЯШЬсЧАПЊЙЄЪддЫааЃЌвдМАЪБХХВщПЩФмГіЯжЮЪЬтЕФЛЗОГЁЃ

Г§СЫЪ§зжТЯЩњЃЌЪ§зжзЪВњЕФЩњВњвВЪЧдЊгюжцдчЦкНЈЩшНзЖЮашвЊзХжиПМТЧЕФВПЗжЁЃ
дкетЗНУцЃЌгЂЮАДяЭЦГіСЫЫцЪБЫцЕиФмдкдЦЖЫазїЕФOmniverse CloudЁЃ
зюгавтЫМЕФЪЧЃЌетДЮЗЂВМЛсЩЯЛЙбнЪОСЫвЛЬзAIЧ§ЖЏащФтНЧЩЋЯЕЭГЁЃ
ЯжЪЕжа3ЬьЃЌащФтНЧЩЋдкдЊгюжцРяППЧПЛЏбЇЯАПрСЗ10ФъЙІЗђЁЃ

ЕШСЗГЩвЛЩэБОСьЃЌГіРДЮоТлЕНгЮЯЗЛЙЪЧЖЏЛРяЖМЪЧИіКУ“ЖЏзїбндБ”ЁЃ
гУЫќЩњГЩЖЏЛЮоашдйАѓЖЈЙЧїРЁЂkжЁЃЌгУздШЛгябдЯТжИСюМДПЩЃЌОЭЯёЕМбнКЭецШЫбндБвЛбљЙЕЭЈЃЌДѓДѓЫѕЖЬПЊЗЂСїГЬЁЃ

вЊТлдЊгюжцЛљНЈЛЙЕУПДРЯЛЦАЁЁЃ
VenturebeatЖдДЫЦРМлГЦЃЌ“етаЉАИР§ИјдЊгюжцИГгшСЫеце§ЕФвтвх”ЁЃ
ФЧУДЃЌФуПДКУгЂЮАДяЕФomniverseЧАОАТ№ЃП
ИќЖрЯъЧщЃЌПЩвдДСЭъећбнНВЕижЗЃЈДјжазжХЖЃЉЃКhttps://www.nvidia.cn/gtc-global/keynote/?nvid=nv-int-bnr-223538&sfdcid=Internal_banners
ВЮПМСДНгЃК
[1]https://www.anandtech.com/show/17327/nvidia-hopper-gpu-architecture-and-h100-accelerator-announced
[2]https://venturebeat.com/2022/03/22/nvidia-gtc-how-to-build-the-industrial-metaverse/
|