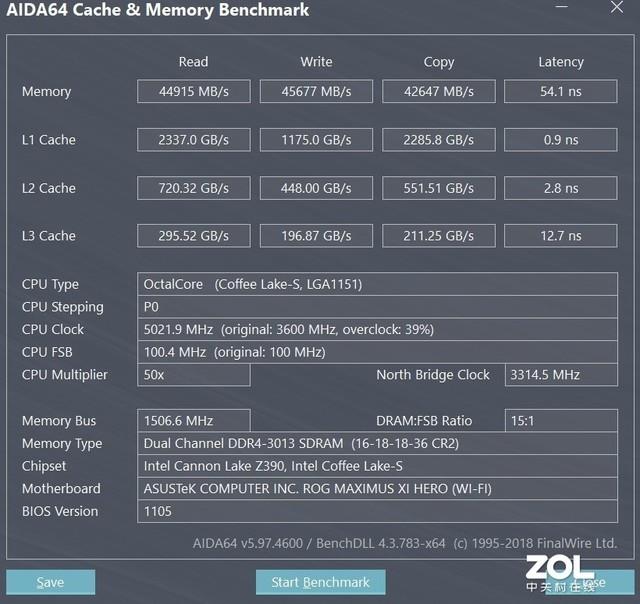
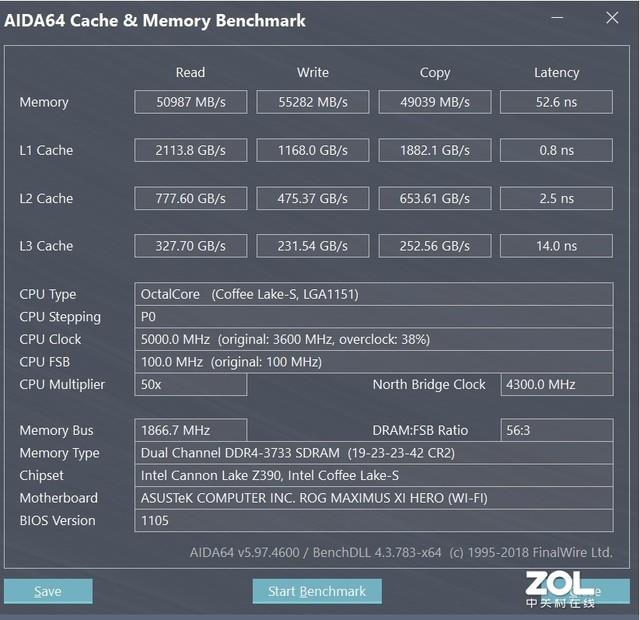
����Ƶ��Ϊ��Ҫý�飬vlog����Ƶ����Ҳ��Ϊһ��ְҵ�ĵ��£��������Լ���Ƶ�IJ��������ǹ��������������ͷͺ������֮һ�������ϵ�Ȼ�����������������ȵ���١��������ɵķ�����������ܲ�֪��������ѧϰҲ���������з��Ӵ����á�
join into data����λ����Lianne��Justin����һ��Ӳ�˵ļ������������ǵķ���������YouTubeһ���½�����Ľ�������Sydney Cummings��
Sydneyӵ�����������˶�ҽѧ��(NASM)��˽�˽���֤��ͬʱҲ��һλ�����˶�Ա�������˺�ע���� 2016 �� 5 �� 17 �գ��ۼƲ����� 27,031,566��Ŀǰӵ�� 21 ���˿��ÿ�춼�ȶ����£������о����塣��ע�⣬�����о�����ͨ�� Python ʵ�֡�
Sydney Cummings?�ı��ⶼ��һ����·���������һ�������ǡ�30�����ֱۺ�ǿ׳�μ�������ȼ��310��·�����ͨ������ʱ�䡢���岿λ�����ĵĿ�·���Լ��������ڶ����������Դʻ㡣���ڵ�������Ƶ֮ǰ���ͻ�֪��������Ϣ��
30����——�ҽ��� 30 �������������ѵ����
�����ֱۺ��μ�——�ҽ��������ֱۺ��μ���רע��������
ȼ��310��·��——�һ�ȼ���൱��Ŀ�·�
�������Ϲؼ���Ϣ��Ԥ�ȵ����������������������裺�۲����ݡ�����Ȼ���Դ�����������Ƶ���з��ࡢѡ������������Ŀ�ꡢ�������������Ķ�����������������һ�����߾�������ôһ��һ��չ���о��ġ�
��ǰ����ץȡ����
��ʵ�кܶͬ�ķ�����ץȡ YouTube ���ݡ�������ֻ�Ǹ�һ������Ŀ����������ѡ����һ��ֻ��Ҫ�ֹ�����������������ߵļ�����
�����Ƿֲ����裺
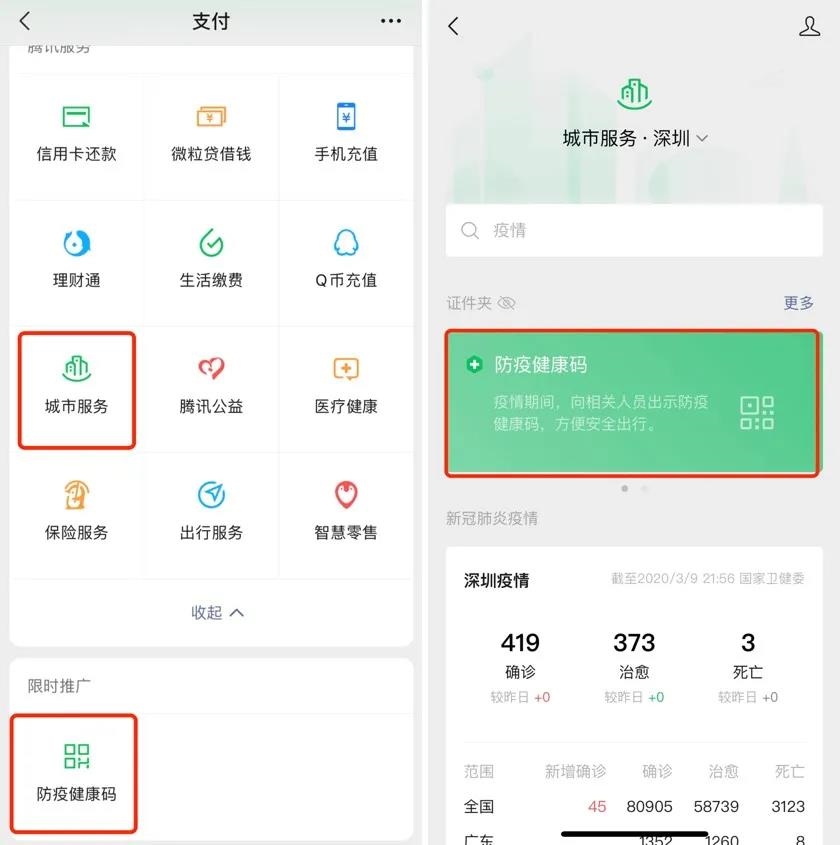
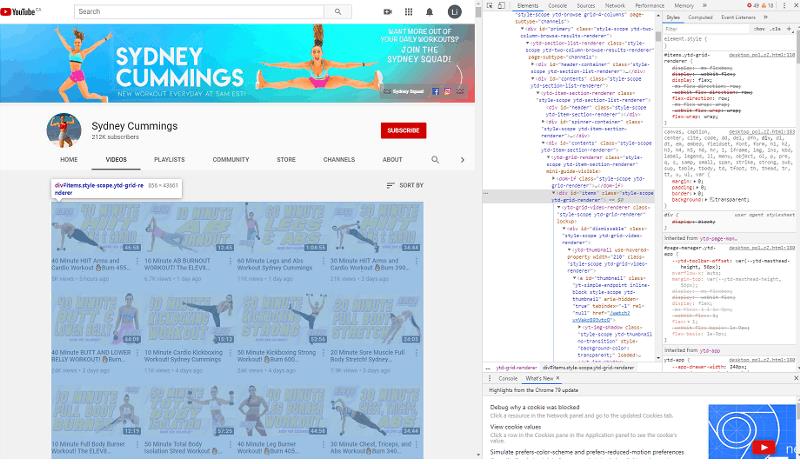
ѡ��������Ƶ��
�Ҽ��������µ���Ƶ��ѡ��“Inspect“��
�������ͣ��ÿһ���ϣ��ҵ�������ʾ��������Ƶ����ͼ���� HTML ����/Ԫ�ؼ���
���磬���ʹ�� Chrome �������������������������
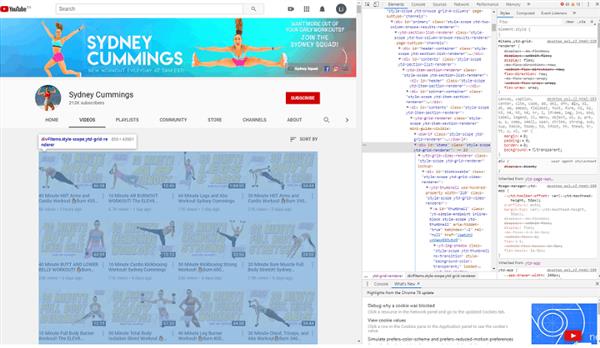
ͼƬ��Դ��Sydney’s YouTube Video page �����ߣ�Sydney
�Ҽ�����Ԫ�ز�ѡ��“����”��Ȼ��ѡ��“����Ԫ��”��
�����Ƶ�Ԫ��ճ�����ı��ļ��в����棬����ʹ�� JupyterLab �ı��ļ������䱣��Ϊ sydney.txt��
ʹ�� Python ��ȡ��Ϣ���������ݡ�
������������Ȥ�IJ����ˣ����ǽ�����������м�����ȡ���������о�����Щ����Ӱ���Ų�������
����1���۲�����
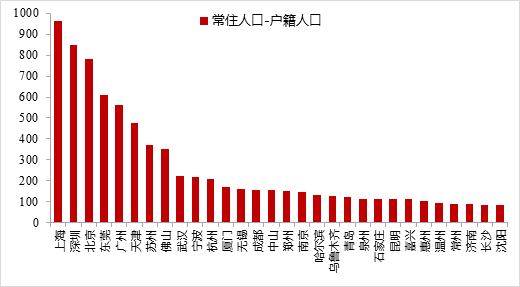
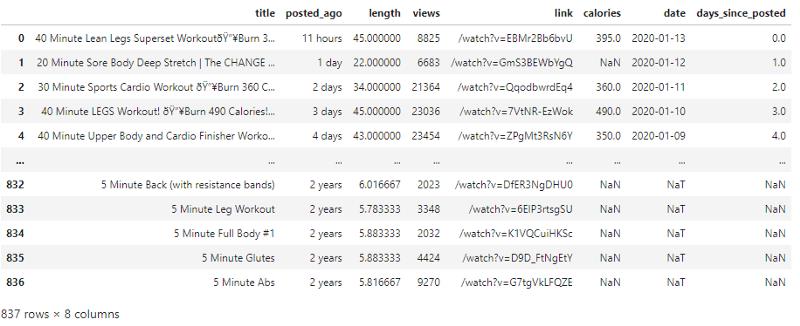
�����ݵ��뵽 Python ���������һ������ɵģ����������ݼ� df_videos��һ���� 837 ����Ƶ��
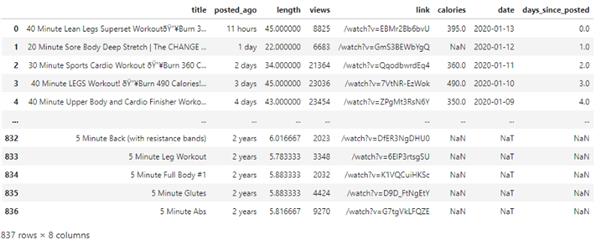
df_videos �� 8 ������������ÿ����Ƶϸ�ڣ����������⡢���ǰ�����ġ���Ƶ���ȡ�����������ַ����·������������ڡ����������������
���⣬����ע��������ص�����Ϊ������������ϴ�ͬһ����Ƶ���ڽ������ķ����н�������ⲿ�ֲ����������
����2���� NLP ����Ƶ���з���
����һ���У����Ǹ��ݱ����еĹؼ��ʶ���Ƶ���з��ࡣ
������ǣ�
�����Ƶ��Ե��������ĸ���λ��
�����Ƶ��Ŀ�����������Ǽ��ʣ�
������ʲô�����ؼ��ʣ�
����ʹ������Ȼ���Թ��߰�(NLTK)��Python ��һ�����õĿ�Դ NLP �⣬���������⡣
���ɹؼ����б�
���ȣ���ǻ���Ƶ�ı��⡣�˹���ʹ�÷ָ�������ո�" "���������ı��ַ������Ϊ��ͬ�ı�ǣ����ʣ������������������Ϳ��Ը��õ������ı���
��Щ�������� 538 ����ͬ�ĵ��ʣ������г���ʹ��Ƶ����ߵı��/���ʡ����Է��֣�Ƶ��ʹ�õľ����Ǽ����ʣ���Ҳ�ٴ�֤������ȷʵϲ�������ʽ����Ƶ���⡣

���ڸ�Ƶ���б������ߴ����� 3 ���ؼ����б��������ڽ��������ڶ���Ƶ���з��ࡣ
body_keywords������—�ؼ��ʣ�——���ʶ����Ƶ��Ե����岿λ����“����”���塢“����”��“��”��
workout_type_keywords������—���ؼ��֣�——���ֶ������ͣ���“����”��“��չ”��“����”��
�����ؼ���——��������õ����Թ���Ĺؼ��ʣ���“ѵ��Ӫ”��“��ƣ����”��“����”��toning����
�ʸɹؼ����б�
���γ���Щ�ؼ����б���������ȡ�˴ʸɡ�����Ϊ��ȷ��������ܹ�ʶ�����ʡ����磬ABS �� Abdominal Exercise�������������ļ�д������“abs”��“ab”����ͬ�Ĵʸ�“ab”��
YouTube ����ı�Ǻʹʸ�
���˹ؼ��ʣ�������Ҫ��Ǻ���ȡ����ʸɡ���Щ���̿�Ϊ��һ��ƥ��ؼ��ֺͱ����б�������
����3����������
����ͷ�Է籩������ѡ������������——���ڹؼ��ʺͻ���ʱ�䡣
���ڹؼ��ʵ�����Indicator Features
����ǰһ���Ĺ����������� 3 ���ؼ����б��;���ı��⣬����ƥ������������Ƶ���з��ࡣ
���� body_keywords �� workout_type_keywords ���࣬һ����Ƶ��������ؼ��ʡ�������ƥ��֮ǰ������������ 2 ��������area ����� workout_type �������͡���Щ������һ����Ƶ���������岿λ�Ͷ����������ӳ�һ���ַ�����
���磬һ��������Ƶ����ͬʱ��“����”��“��”������ͬʱ��“����”��“����”������Ƶ����������Ϊ“����+��”����������Ϊ“����+����”��
ͬʱ������Ҳʶ��������ƵĹؼ��֣���“�ܹ�”��“��ȫ”��“����”��“����”�������ǹ���һ�顣
������Ǵ��������ֲ�ͬ���͵�����������dummy features����
is _ { } _����ʶ����Ƶ�Ƿ�����ض����岿λ��
is_ { } _������ȷ���������ͣ�
title_contains_{}���鿴�����Ƿ���������ؼ��ʡ�
Ϊ������������Ƶ����“�Ȳ���������ѵ��”Ӧ���� _leg_area = True, is_strength_workout = True�� title_contains_burnout = True��������������Ϊ False��
Frequency Features
�����������⣬��������������������num_body_areas�� num_workout_types���� num_other_keyword����������һ����Ƶ�������ᵽ�Ĺؼ��ʵ�������
�ٸ����ӣ�һ��������“�������Ȳ���������ѵ��”�� num_body_areas �� num_workout_types ���� 2��
��Щ����������ȷ����Ƶ��Ӧ���������岿λ��������͵����������
Rate Features
���ͬ����Ҫ���ǣ����ߴ�����һ��������calories_per_min��ÿ���ӿ�·������������·���ȼ���ٶȡ��Ͼ������ڶ���ҪһЩ��ȷ�ģ��������ģ�����Ŀ�ꡣ
��Ȼ����������Ҳ�������һЩ������������Ƶ������Ҳ��ת��ʱ������ǰ�������ֶ��������ﲻ������
����ʱ�����е�����
�����������ڹؼ��ʵ������������Ѿ������ܻ�ӭ��Ƶ�����͡������Ƿ���ζ�Ų���Ӧ��һֱ����ͬ���͵���Ƶ��
Ϊ�˻ش�������⣬���ǻ�������һЩ����ʱ�����е�������
num_same_area����ȥ 30 ���ڷ��������ͬһ�������Ƶ��������ǰ��Ƶ�����������磬����= 6��˵�����˵�ǰ��Ƶ����ϰ���ʱ����ȥ 30 ���л��� 5 ������������Ƶ��
num_same_workout ������������ num_same_area��ֻ��ͳ�Ƶ��ǽ������͡����磬����= 3��˵�����˵�ǰ��Ƶ HIIT �������ڹ�ȥ 30 ���ڻ��� 2 �� HIIT ������Ƶ��
last_same_area��������һ�����ͬһ�����岿λ��Ƶ��ȥ�����������磬������= 10��˵����Ը�������һ����Ƶ�������� 10 ��ǰ��
last_same_workout��ͬ last_same_area��ֻ����Խ������͡�
num_unique_areas����ȥ 30 ���ڶ����˼��鲻ͬ�����岿λ��
num _ unique _workouts����ȥ30�췢���IJ�ͬ����������Ƶ��������
��Щ�����������˽������ϲ����ͬ�Ļ��Dz�ͬ���͵���Ƶ��
��Ҫ˵�����ǣ�����ż���ᷢ���뽡���ص���Ƶ�����������ܴ���������δ����Щ�����������������Ҳ���˵���ǰ 30 �����Ƶ����Ϊ����ȱ���㹻����ʷ���ݡ�
�������뿴�����������̵ľ�����̡�
���ع����Լ���Test for Multicollinearity
ʲô�Ƕ��ع����Լ��飬ά���ٿƵĽ����ǣ����ع�����(Ҳ�ƹ�����)��һ���������ж�Ԫ�ع�ģ���е�һ��Ԥ������������൱�ߵ�ȷ�ȴ�����Ԥ�����������Ԥ�⡣���ع����Բ��ή��ģ�������Ԥ��������ɿ��ԣ��������������ݼ�������ˣ���ֻӰ�쵥��Ԥ�����ӵļ��㡣
Ϊʲô�����Ҫ��
���販��ֻ����һ��������ѵ��������������Ƶ����һ�IJ��������Ǹ��ߡ���ô����������ʱ��Ӧ�ù������Ƿ�������һ��������Ϊ����������ѵ���أ�Ϊ�˻����ʵ�Ĵ𰸣����߱���ȷ������֮��û��ǿ�����ԡ�
�ɶ����( pairwise correlations)�dz��õķ������������ֶ������(����һ��)ʱ�����ܻ�ͬʱ���ڹ����ԡ�
��ˣ�����ʹ����һ�ָ����ӵķ���——k�۽�����֤�� K-fold cross-validation�����ﵽĿ�ġ�
��ϸ��������:
�����жϣ�ѡ��һ��ؼ����������Թ����ԡ�
����ѡ���˶���YouTube��Ƶ������������Ҫ��������ͬʱ���������������������ɵ�������rand0,rand1, rand2�����Ƚ�����֮��Ĺ�ϵʱ�����dz䵱anchor�����һ����������Щ���������Ȳ�̫��Ҫ��̫����ʱ����ô���Ͳ���Ŀ����������Ҫ�Ա�����
Ϊk�۽�����֤����Щ������
�ڴ˹����У�����ת������������categorical features����area��workout_type������ת��ȷ��ÿ�����������K��ֵ��
ʹ������һ��������ΪĿ�꣬����������Ϊ�Ա�������ѵ��Ԥ��ģ�͡�
�����������߱���ÿ����������ʹ�������������һ��ģ����Ԥ��������������һ�����ݶ�����ģ�ͣ�Gradient Boosting Model ��GBM)��K����֤�����Ҹ���Ŀ�����������ֵĻ��Ƿ���ģ�Ӧ�ò�ͬ��ģ�ͺͷ���(ģ��Ԥ����������ָ��)��
��Ŀ������������ʱ������ʹ��Gradient Boosting Regressorģ�ͺ;��������(RMSE)����Ŀ�������Ƿ�������ʱ����ʹ��Gradient Boosting Classifier ģ�ͺ�Accuracy(����)��
����ÿ��Ŀ�꣬���Ǵ�ӡ��K����֤����(ƽ����)������Ҫ��5���Ա�����
�о��÷ֺ�ÿ��Ŀ����������Ҫ�Ա�����
������ͼ�о�ÿ��Ŀ�������������Ա����Ĺ�ϵ����Ȼ���IJ����о��������̣������������ӡ�
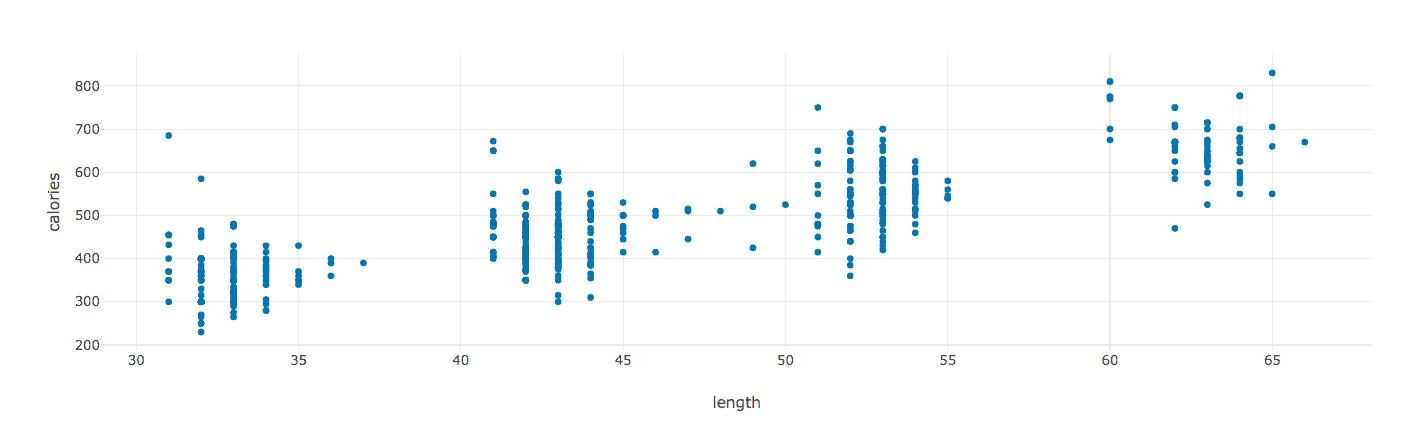
���߷���length����Ƶ���ȣ��� calories��������صġ�������ֺ�ֱ�ۣ���Ϊ������ʱ��Խ�������ĵĿ�·���Խ�ࡣ
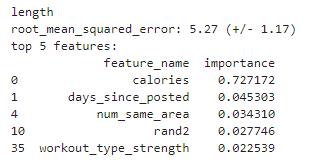
���ֹ�ϵ�������⡣
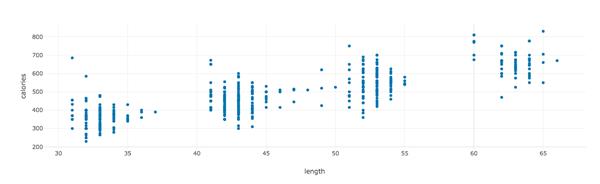
length�� calories֮���������أ�������ǿ�Ȼ������Խ�����ֱ�ӹ鵽һ�顣��Ϊ40-45���ӵ���Ƶ���ĵ�������30-35���ӡ�50-55���ӣ�������60����ӵ���Ƶ�������ص����֡���ˣ�����������������
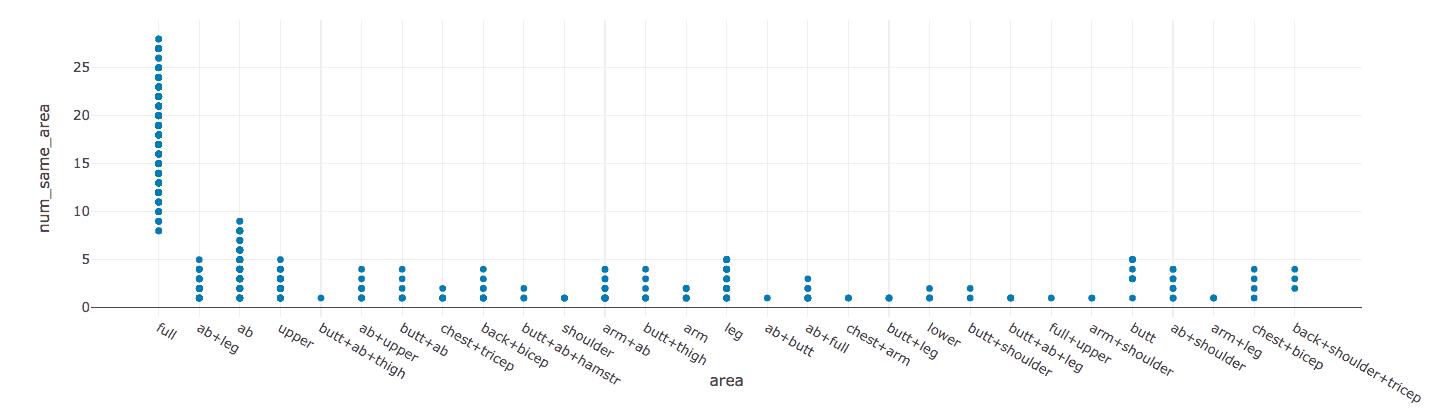
���⣬���߷���num_same_area��area_full����������Ҳ����صģ���������е����˾��ȣ���������ʼ���ܡ�
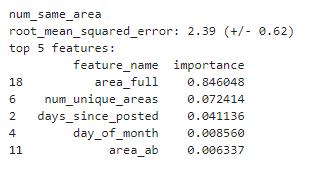
��ͼ��ʾ��num_same_area��area֮��Ĺ�ϵ��
num_same_area������ͳ�Ƶ����ڹ�ȥ30���ڷ����������ͬһ��λ��Ƶ(������ǰ��Ƶ)��������area_ful����ȫ������������Sydney��Ƶ����������͡���ˣ���num_same_area�ܴ�ʱ����ô��Щ��Ƶ�������ȫ���Ķ�����
�������Ƿ��ָ��ߵ� num_same_area(>=10) ȷʵ�ᵼ�¸��ߵ�YouTube���������������֪��������Ϊarea_full ������Ϊ num_same_area����ˣ����߷����� num_same_area������Ҳ��Ϊ��ͬ����������num_same_workouts������
����4������Ŀ��
����ܻ��ǵã�����о���Ŀ��������YouTube�IJ��������Dz���˵�������ǿ���ֱ���ò�������ΪĿ���أ�
����ע�⣡��������ƫ̬�ֲ�����������ֵ��27��641�Σ�����ߵ���Ƶ�ﵽ130�����ֲ�ƽ����ģ�͵Ľ����Դ������⡣
��ˣ����ߴ���������views_quartile��������ΪĿ�ꡣ
���ǽ���Ƶ��Ϊ����——�߲�����Ƶ(“high”)�͵Ͳ�����Ƶ(“low”)��“high”ռ�ܲ�������75%��Ҳ���Dz�����35578�����ϵ���Ƶ��ʣ�µĶ��鵽“low”��
ͨ�����ַ�ʽ������ʹ��Ԥ��ģ�����ҵ���������ߵ�25%����Ƶ��������ϡ�
����5������������
������һ�й��������Ǹ���Ŀ��views_quartile����һ��������ģ������
Ϊ�˱��������ϣ����߽�һ��Ҷ�ӽڵ����С��������Ϊ10��Ϊ�������Ǹ��������⣬���߽���������������Ϊ8�㡣
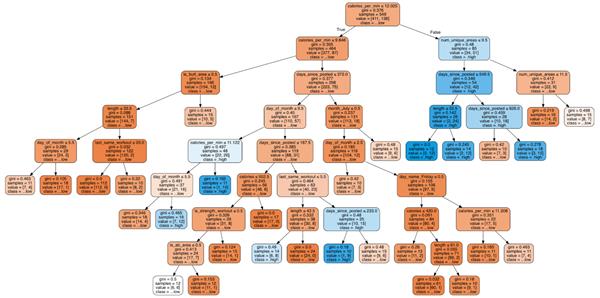
���� 6���Ķ�������
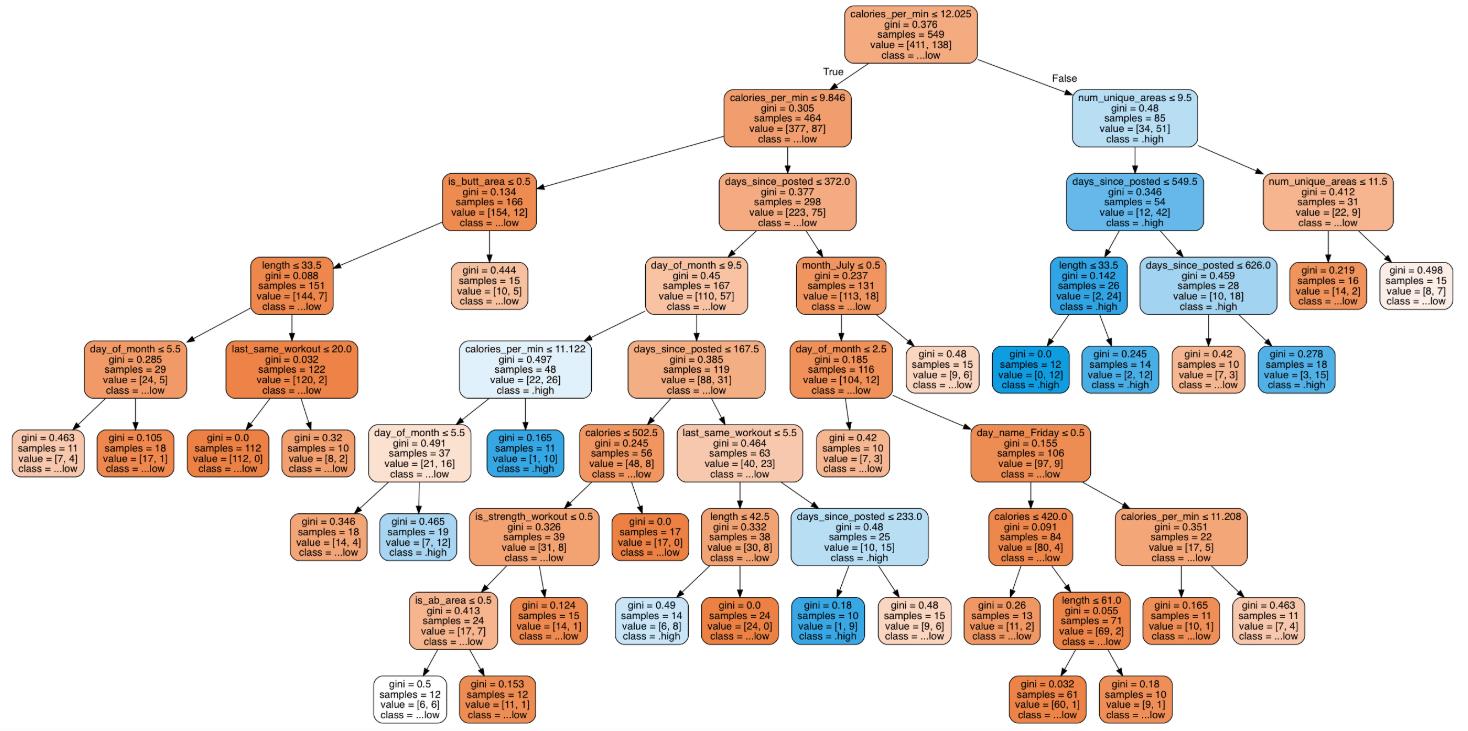
�����һ���У����߽��о����ܽᵼ�¸��ߵͲ�������“��֧”�����ǵ�������ʲô�أ�
����1��calories_per_min������Ҫ������
û����calories_per_min������Ҫ�������������ƺ���̫���Ľ������ͻ����岿λ��
ÿ�������ĵĿ�·��≥ 12.025���ڸ����ģ�60%��51/(34+51) ������Ƶ���нϸߵĹۿ��ʡ�
ÿ����ȼ�յĿ�·������(≤ 9.846)����Ƶ��Զû���ܻ�ӭ��ֻ�� 7.2%��12/(154+12) =���нϸߵIJ��š�
��ÿ�������Ŀ�·����9.846��12.025֮�����Ƶ����������Ҳ������ϴ����á�
����2����ͬ��λ�����ַ�ʽ������������߲�����
������ֳ������������ѵ����Ǹ��ָ����Ķ���������
����ȥһ���£����岻ͬ��λ�Ķ�������(num_unique_area)�ܸߣ�≥ 10ʱ����Ƶ�Ĺۿ�����͡���ʹÿ����ȼ�յĿ�·��ܸߣ����������Ȼ������
���ǰ�����۵㣬78%��42/(12+42) ������Ƶ����������»���˸���IJ��ţ�
ÿ����ȼ�յ������ܸ�(≥ 12.025)
��ȥһ���������岻ͬ��λ�Ķ����������� (< 10).��
����3���β��������ܻ�ӭ
��һ����Ƶ���ĵĿ�·�����(calories_per_min ≤ 9.846)ʱ����ֻҪ���β�������33%��5/(10+5) �����ܻ�ø߲��ţ���Ȼ��ֻ��4.6%��7/(144+7) ����Ƶӵ�нϸ߲��š�
���飺�����߲���
���ϣ����߸�Sydney������������飺
����1��ȼ�տ�·��
��������������ÿ�������ĵĿ�·��������Ҫ��������12.025�Ǹ�ħ�����֡�
�±��Dz�ͬʱ������ƵӦ��ȼ�ն��ٿ�·��Ľڵ㣺
30���ӽ�����361��·��
40���ӽ�����481��·��
50���ӽ�����601��·��
60���ӽ�����722��·��
���������һ�����룺����(ʱ���Ϳ�·��)���˵Ĵ̼�ֻ�������ϣ���ҿ��ܾ���ϲ��������·���ǰ��λ����ʱ����ö࣬��˵�������ø��̵�ʱ�䣬���ĸ���Ŀ�·�
����2�����ò�ͬ�����岿λ�ؼ���
Sometimes less is more.
���Dz�ϲ��������������̫�ͬ�����岿λ������ģ�ͣ���һ�������������10�����岿λ����ϸ��á�
����ע�Sydney�����������Ƶ��ʹ���˸��ٵ����岿λ�ؼ��ʡ������Ե�һ���ǣ���һֱ��ʹ��“�ֱ�”��“����”����������“��ͷ��”��“����”�����Ĵʡ�
����3�����������
Sydney�Ķ����߿��ܸ�����Ůʿ������������“�β�”���ԣ������������ֱۼ��⡣����Ը������ȼ�ո��ٵĿ�·������ø��������β���Ҳ��SydneyӦ��һֱΪȼ�ո��ٿ�·�����Ƶ����һЩ�β��˶���
����4��δ����֤���뷨
����˵���³������µĻ�� �³���������Ƶ���п��ܻ�ø��ߵ��������Ҳ������ϲ���趨�µ�Ŀ������ʼ�µ�һ���¡��ڶ���������5���ڷ�����ͬ���͵Ķ�����
�������Ҳ��ʾ������о�Ҳ��һЩ���ƣ�
��Щ�����ǻ��ڹ�ȥ�ı��֡��� YouTubers��������ƹ�ȥ��·���������뷨�����ڴˣ����ǿ��Խ�����ѧϰӦ�õ����ǵľ����������ϡ�
ֻ���з����˱��⣬����һЩ������Ϣ�����綩�����������Ա������ͳ�ƣ����п����̲��Ÿ������������ȷ�ķ��ֺͽ��͡�

|