正文内容 评论(0)

[全新技术 Memory Controller & CrossFire]
除了加强了Pixel Shader引擎的效率上升外,ATi还在新一代X1000核心中改用全新的内存控制器技术,称为"Ring Bus Memory Controller"技术。传统显卡技术,为了提高显存的传输效率,通常都会用直接提高内存的带宽,不过提高带宽只能为提高突发传送时带来便利,但如果程序并不需要太高的带宽,则更高的带宽也是枉然,相反有效地运用内存宽带才是最重要。
在Ring Bus的架构下,Client Interface会向内存控制器作出读取要求,而控制器同样会安排数据由显存颗粒中读取,但却不会回传至内存控制器,而只是把东西放在Ring Bus,然后Client Interface自行由Ring Bus取回所需要的数据封包,因此显存减少回传的工作,达到减少延迟而令效率提高的目的。
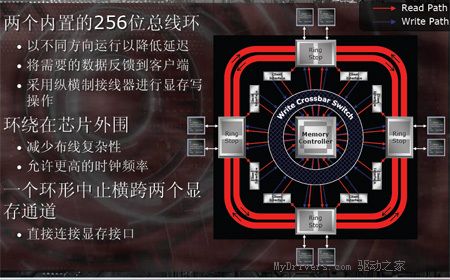
如图所示,Radeon X1000系列显卡内置两个256位的总线环,环路总线围绕在内核心的周围,这样可以简化线路设计及使连接处于最优化状态。这意味着任何时候内核各部件都能处于最短的连接线路状态,这样在显存进行数据写入操作过程中有效降低延迟及降低信号品质。由于采用环路总线技术,RADEON X1800/X1600可以支持象GDDR4这样的高频率显存,而在传统的显存架构之所以不能支持高频GDDR4显存,很大原因就是GPU内部线路之间的串扰等原因所造成的。
ATi官方宣称,采用了这样的环路读取、Crossbar写入的设计后,显存总线的频率可以比以前的产品提高一倍,使得X1000系列可以充分利用先进的显存技术。此外ATi还提到,X1000系列显存控制器的Ring Stop能够由驱动程序控制,可以通过驱动程序的CATALYST A.I(智能参数设定),为特定的应用程序设定判断优先次序,让显存控制器优先处理最迫切、对性能影响最大的数据请求。
除了采用环路总线设计提升显存子系统的性能,ATi在X1000系列的中还引了一种称为“联合缓存存取工作模式”来提升显存系统的性能。此前,显示核心上采用的缓存都是直接映射,即每个缓存的入口都映射至一块专门确定了的图形模块区域。虽然这可以让缓存的执行过程简单化,不过也带来了另一个问题:当出现显存客户端需要交换两个数据时,而这两个数据刚好要位于被缓存映射的同一块显存区块内,那么这两块数据就会出现抢占缓存空间的情况,这时写数据的时候就会产生迟延的问题,降低缓存的命中率,增加了显存存取的压力。
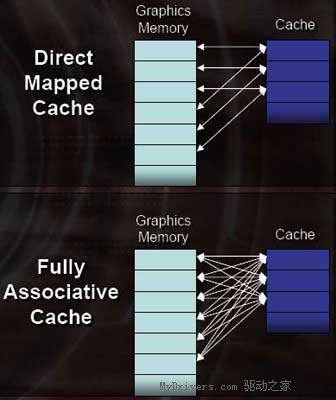
在联合缓存架构中,缓存不再只是映射到特定一个或者某几个的显存地址,而是任意空闲的显存。在频率是一样的情况下,联合缓存工作效率要远高于直接映射缓存。这样,RADEON X1000在高分辨率或在启用全屏抗锯齿及各向异性过滤方面的将拥有更好的表现。
除此之外,HyperZ也得到了改进,采用了更复杂的算法来避免渲染不可见的材质,ATi说新算法的HyperZ工作效率将比RADEON X850中的提升了50%。(注意:RADEON X1300系列并不支持环路总线技术,但ATi表示会另辟蹊径来改进RADEON X1300显存子系统的性能)
CrossFire是通过两片显卡各自运算,然后透过CrossFire版本拥有DMS接口输入Composting Engine内再组合成完整画面,再输至显示器,而所谓的CrossFire Engine就是Silcon Image Sil1611及1612为DVI接收及输出芯片,Analog Devices的ADV7123高速Digital to Analog转换芯片及XILUNX Spartan XC3S400的系统逻辑DSP芯片成组成。可是Silcon Image Sil1611只支持最高1600x 1200的影像,也是旧版CrossFire最大分辩率只能支持1600x 1200(主要是受Silcon Image Sil1611芯片的制约)。此外ATi也决定推出X1800及X1600版本的CrossFire Edition,期望把CrossFire进一步普及。

本文收录在
#快讯
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...