正文内容 评论(0)

[全新技术 Ultra-Threads Shader Engine]
为了更加有效的同时运行多线程运算,ATi在Radeon X1000的设计中加入了智能化的线程分配处理器——Ultra-Threading Dispatch Processor(超线程分配处理器)。
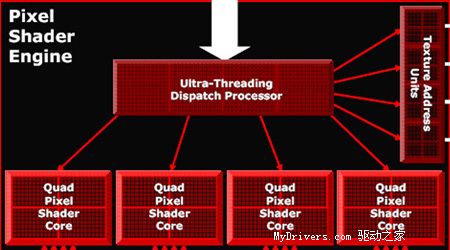
Ultra-Threaded Pixel Shader Engine能把一个较大的Pixel Shader的运算分拆为大量较小的执行序,然后平均的分给各个Pixel Shader Core Unit,在同样的Shader程序下其执行序被分割成细少的Pixel Blocks,排除了部份Unit需要等待其它Unit完成的结果而造成闲置,减少了不必要的延迟并提供更快的执行效率。
这个Ultra-Threading分配引擎也可以在某些像素着色引擎空闲时重新分配新的任务。这样的情况多数发生shader在等待数据或者完成了任务的时候,比如在纹理存储进缓存或显存的过程中。根据ATi的官方介绍,这样的设计可以将X1000的Pixel Shader运算资源的利用率提升到的90%。
而ATi X1000在运算分支程序的时候,能够把每个线程的分成很多个4X4像素的小块来分别处理,在这样的一个像素块里碰到两条不同分支的机会就非常小,降低了出现SI2D的机会,这可以使动态分支拥在更高的运算效率。
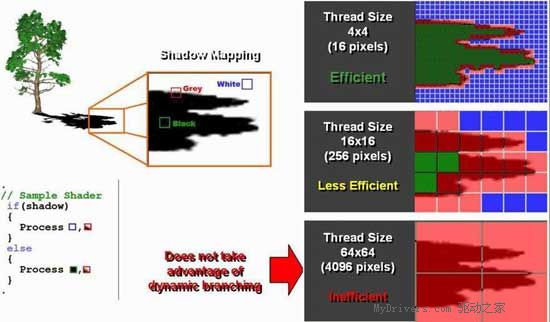
ATi的Ultra-Threading设计还能够提高Pixel Shader 3.0动态分支的性能。动态分支被认为是Pixel Shader 3.0的重要新特性,可以让Pixel Shader根据计算出来的数值来跑不同的分支或者循环。如果正确使用的话,动态分支能显著的提高显卡3D性能。例如在使用shadow map的时候,如果要对阴影作边缘柔和取样,使用动态分支可以在遇到不需要作取样像素的时候就跳过去,以节省大量的pixel shader计算资源。但是需要注意的是,目前显示核心的Pixel Shader都是采用传统的SIMD架构,动态分支的运作往往会破坏掉程序的并行性,使得动态分支带来的益处被浪费掉。

本文收录在
#快讯
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...