正文内容 评论(0)

[低端显卡市场,性价比是关键——TurboCache技术运应而生]
与高端产品注重强大的性能表现不同,低端产品往往更多的考虑产品价格因素,同时低端市场庞大的出货量也为厂商带来了比重相对更大的利润,因此如何有效降低成本,抢占足够多的低端市场分额便成为所有厂商考虑最多的问题。对于消费者来说他们也希望显卡在性能上有更高的表现,在价格上足够低廉,这成为摆在各家厂商之间的难题。
这种现象在目前的显卡市场可以说得到了最好的诠释,NVIDIA与ATi在不断推出性能强大的标志性顶级产品的同时,也将更多的精力投入到了总体利润更大的低端市场。从一块显卡的结构来看,其成本主要由三部分组成,核心、PCB板以及显存。对于核心来说,通过减少管线数量降低硬件规格,从而降低晶体管数量来实现生产成本的降低是一种有效的方法。而显存的成本则取决于容量和位宽,换句话说便是取决于采用了显存颗粒的数量和规格。相比之下PCB板以及所用各类元件在成本中的比重就相对小了许多,真正想要降低显卡的整体成本还是需要从核心以及显存下手。
在此之前,我们能够想到的降低显卡投入的最佳方法便是整合,通过将图形核心整合到主板芯片组中,利用系统内存来完成图像处理所需要的纹理渲染工作。这种方法既节省了PCB板和原料,又去掉了显存颗粒的成本开销,能够最大限度的降低显卡的价格。对于消费者来说只要在主板上多投入一小部分资金,便能够节省下购买一块独立外置显卡的成本。然而一利必有一弊,这种方式的结果便是带来了差强人意的图形处理能力,而且由于集成图形核心需要固定的占用一部分内存容量和系统带宽,对系统性能的制约也是不言而喻的。虽然Intel全新915G芯片组集成的GMA900图形核心,已经实现了对DirectX9的部分支持,但实际上它也只能用来运行2D游戏或一些过气3D游戏,对于最新的大型3D游戏依然望尘莫及。
而单独配置核心处理能力强,并且具有128MB甚至更高显存容量的独立显卡,虽然在性能上能够大大强于集成显卡,并且能够满足大多数主流游戏的需求,但相对较高的价格也令大多数入门级平台的消费者不愿接受。
以上的两种方案都是不太令消费者们满意的,因为他们既需要更好的性能,又需要比较容易被接受的价格。在现有的集成显卡与独立的低端显卡之间,如何寻找到一种更为折中更具性价比的解决方案是所有人都非常关心的,也正是这种需求使得TurboCache技术得以诞生。
[PCI-Express带来显卡发展新希望]
目前的主流显卡多采用AGP接口进行数据的传输和交换,但是随着人们对游戏真实效果的追求,新一代的3D游戏特效对显卡的着色器、纹理处理能力以及存储空间都提出了日益苛刻的要求。
例如,在游戏孤岛惊魂、Unreal3引擎以及最新的测试软件3DMark05中都加入了MRT技术,这项大量使用多渲染对象的技术,需要大量的渲染目标空间来保存位置、坐标、色彩、素材等数据,并且需要将所生成的每个象素的数据作为参数,从而实现阴影、光照、景深模糊等真实的视觉效果。
如此一来,AGP的传输带宽便不足以应付如此大量的数据交换。而3D应用对显存容量的更高要求也使得显卡板载的显存容量不断提升,从而产品成本不能得到很好的控制。对于集成显卡来说,极高的内存容量以及数据传输需求更是系统以及原有总线带宽所不能满足的。
Intel倡导的平台革命把PCI-Express推到了前台,这也使所有人看到了新的希望。虽然在AGP时代也有技术支持显卡对于内存的映射,但较低的带宽限制了这类技术的发挥。AGP8X的最大带宽只有2.1GB/s,而PCIE16X的采用能够将这一数值提升到4GB/s,也许在某些人看来这种性能的提升并不能算是惊人,但事实上这并不是PCIE真正的潜能。实际上PCIE接口还可以工作在全双工模式下。在这种模式下PCIE显卡接口将会拥有两条专用的通道,每一条专用通道只作单向的数据传输,因此两条通道同时工作便可以使PCIE 16X的传输速率达到8GB/s。
不过有些遗憾的是,这种全双工模式并没有得到Intel最新一代芯片组915/925的支持,这主要是由于全双工模式还有一些技术问题尚待解决。而NVIDIA最新推出的nForce4芯片组则很好的解决了这一技术问题,也因此能够实现上下行各4GB/s的传输速率。PCI-Express总线技术的推出,为这种内存映射技术的充分发挥提供了广阔的平台。
NVIDIA很好的把握住了这一时机,推出了创造性的TurboCache技术,利用PCI-Express总线的高带宽优势,实现了显卡对系统内存的实时调用,让显卡能够像读取显存一样来直接使用系统内存。最大化的实现了性能与价格的平衡。在NV的TurboCache技术推出后不久,ATI、XGI等厂商也纷纷宣称要推出类似得技术,究竟这项技术有什么样的优势和特点呢?让芯片巨头们都如此看好呢?让我们一起来深入研究一下吧。
[通通透透看TurboCache——原理及技术分析]
TurboCache的中文名为“智能加速引擎”,其最大的一个特性就是支持了将图像直接渲染到内存。顾名思义,直接渲染到内存的技术便是通过PCIE的总线通道,直接对系统内存进行读写访问,而读写的内容便是以往需要用显存来存放和处理的图象数据。
在AGP平台中,板载显卡其实使用了与此类似的技术,但那时的图形核心只能通过AGP总线对内存进行访问,并且我们需要在Bios中划分出固定容量的内存,来放置图形处理需要的顶点和纹理数据。这样做有两点不足:首先AGP总线的带宽不能满足越来越高的数据传输需要,大大限制了核心性能的发挥;其次在内存被固定的划分给图形核心后便不能改变容量,而系统也不能对这部分内存加以利用,这便造成了内存资源的浪费。
TurboCache技术很好的解决了这两个问题。由于PCIE总线的传输带宽远高于AGP总线,因此图形核心能够高速的与内存进行数据交换。如此一来显示核心便能够直接的利用内存,当进行纹理渲染时能够实时的对内存进行读取和写入操作。除此之外,对内存的实时调用也另TurboCache技术不需要划分固定容量的内存,系统能够根据图形处理工作的需要来访问内存。
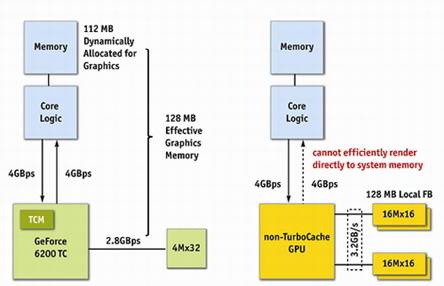
再来看看与同样采用PCIE总线,但没有使用TurboCache技术产品的对比。我们以16MB/32bit显存版本的GeForce6200TurboCache为例,可以看出,由于利用了nForce4平台的双向PCIE总线带宽以及显存的带宽,GeForce6200 TurboCache显示核心能够与系统内存进行上下行各4GB的数据交换,并且还能与本地显存通过2.8GB/s的带宽交换数据。
而普通的128MB/64bit的PCIE显卡,虽然连接到双向8GB/s的PCIE总线,但由于只利用板载显存因此只能使用单向的下行4GB/s的带宽用于核心与显存的数据交换,而本地显存带宽即使为3.2GB/s,但图形核心的整体效率也大打折扣。
此外,从这张图中我们也能够清楚的了解到,采用TurboCache技术的这款产品只需要板载16MB的显存,但通过动态分配最高达112MB的系统内存,实现了128MB的显示存储系统。而没有采用TurboCache的产品如果想要拥有128MB的显存容量,就只能通过显卡板载的方式来实现了。二者相比,规格和成本已经见了分晓。
[TurboCache构架、MMU(内存管理单元)作用大]
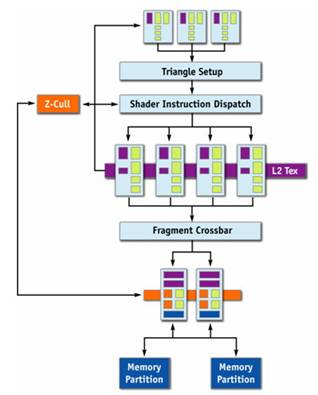
以往典型的三维图形管线主要分为四个流水线步骤:1.几何处理(转换和照明)、2.设置(顶点处理过程,也既是将顶点数据转换为画面所显示的像素的过程)、3.纹理应用(同样是将纹理效果转化应用到像素的过程)、4.光栅处理(这一过程就是应用照明和其它环境光阴效果到显示画面,以生成最终的像素值)。下图很好的说明了这一流程。
而TurboCache技术则针对以往的构架,重新进行了三维管线的改进。增加了MMU(内存管理单元),这里的MMU(内存管理单元)其实就是在系统内存与核心内部的相应流水管线建立了连接通道,它能够同时调用和动态的分配本地及系统内存容量,使得GPU能够高效的利用系统内存进行渲染和纹理处理。此外,通过更改多种管线要素,新的架构除了能够有效的利用PCIE的高速传输带宽,还能够处理由于通过PCI Express接口接入系统而增加的时延。
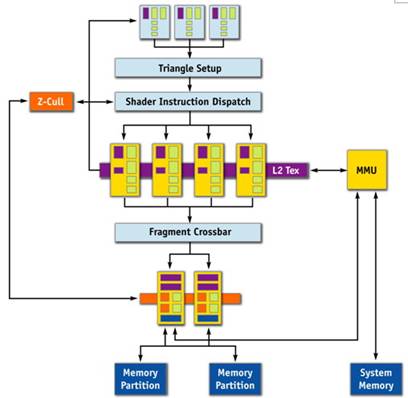
除了在GPU中配置独特的MMU(内存管理单元)硬件支持TurboCache外,驱动程序中也针对TurboCache技术进行了相应的修改,实现了以智能化的方式确定色彩、纹理和Z轴缓冲数据的位置。这种处理能力也能够最大限度的提高每种应用的性能。
此外,TurboCache的内存管理单元(MMU)还能够按照应用的需要,将更多内存分配用于图形处理。当该应用关闭时,分配用于图形处理的内存将被释放,以供系统使用。这个过程是在后台完成的,并随应用的不同而不同。依靠这种方式,TurboCache技术通过智能化地分配本地图形内存与系统内存之间的负载,平衡了渲染过程中系统总带宽的占用。其中,用于显示刷新的扫描输出缓冲存储空间则始终由本地显存提供。
[红花需绿叶——芯片组的支持影响TurboCache性能发挥]
与以往一款显卡产品在定型后性能仅仅取决于核心频率及显存频率和容量不同,采用TurboCache技术的显卡性能还会受到芯片组的影响。我们前面提到,nForce4芯片组与Intel的915/925芯片组由于技术原因存在PCIE通道的差异。下面就让我们以32MB/64bit显存版本的GeForce6200TurboCache为例,具体来看一看芯片组的差别。
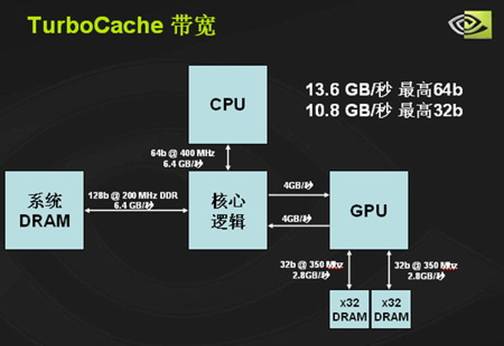
这是在使用NVIDIA的nForce4芯片组主板时的情况,由于nForce4能够支持双向的PCIE数据传输,因此GPU能够最大利用上行和下行各4GB/s的双向带宽与芯片组进行数据传输,同时与本地显存的数据交换带宽最高能达到双向的5.6GB/s。
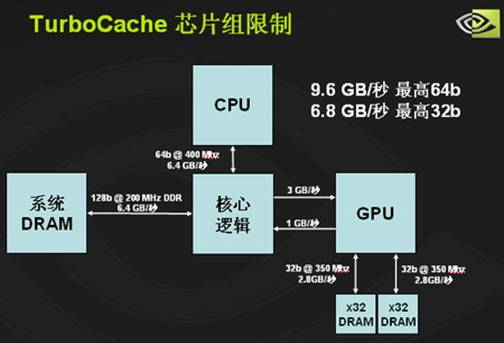
而如果显卡搭配的是Intel的915/925系列芯片组,由于目前芯片组规格问题,只能够实现上行1GB/s,下行3GB/s一共4GB/s的PCIE有效带宽。此时GPU的有效带宽便大大降低,最高只能达到9.6GB/s。
通过下面这个表格,我们能够更加清晰的了解不同芯片组及内存搭配的带宽情况。
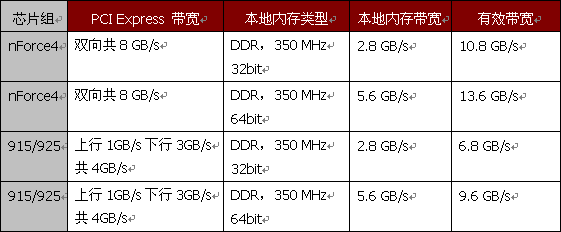
因此,在选择与采用TurboCache技术的显卡进行搭配的主板时,也要三思而行。
[丰俭由人,规格灵活——多种设计、不同显存搭配]
为了适应不同用户的需求,NVIDIA此次推出的采用TurboCache技术的GeForce6200显卡
还分别制定了不同的规格。从PCB的板型以及搭载的内存颗粒来看,一共有采用mBGA封装显存颗粒的P282公版和采用TSOP封装显存颗粒的P262公版。

这是搭配mBGA显存颗粒的P282公版。在内存的选择上共有两种方案,分别是采用一颗显存的16MB/32bit方案和采用两颗显存的32MB/64bit方案。采用两颗显存的方案会占用更少的系统内存,同时显存位宽也会提升一倍,当然在显卡的成本上也会有一定的增加。


这是采用TSOP显存的P262公版,在显存的搭配上同样很灵活,可以选用8MX16、16MX16和32MX16这三种规格的显存。而显存数量也可以是两颗或者四颗。这样一来,就能有多达六种的组合方式,板载显存容量也从最低的32MB到最高的256MB。但目前常见的还是以下两种规格的产品:

可见,这种板型的产品能够获得更大的动态显示存储空间,因此性能更为出色,不过它对系统内存的容量也提出了比较高的要求。
[GeForce6200 TurboCache性能究竟如何——基准测试初步了解性能]
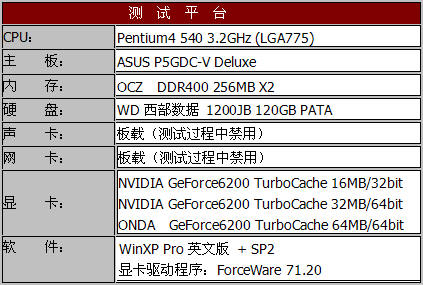
由于设备的原因,我们没有搭配采用nForce4芯片组的主板对GeForce6200 TurboCache显卡进行测试,而是选择了一款采用915G芯片组的ASUS P5GDC-V Deluxe主板,这也使我们能够将GeForce6200 TurboCache与915G板载的GMA900图形核心加以对比。
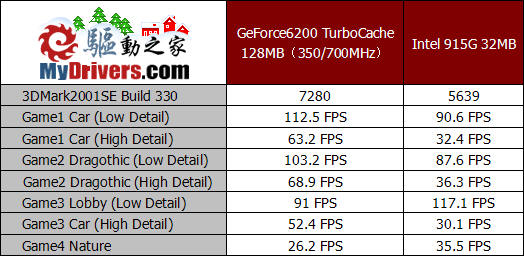
虽然3DMark03和3DMark05的推出已经逐渐使3DMark2001失去了其在测试中的地位,但对于低端显卡来说,它依然有足够的能力去检验显卡的真实性能。由于GeForce6200 TC采用了共享部分系统内存的TurboCache技术,因此我们也选择了Intel的915G芯片组集成的图形核心来与它进行对比。从3DMark2001SE的测试成绩来看,由于具备了最新的DirectX9技术,以及对SM3.0的支持,GeForce6200 TC的性能远远超过了915G,部分项目的性能已经达到了915G的两倍。
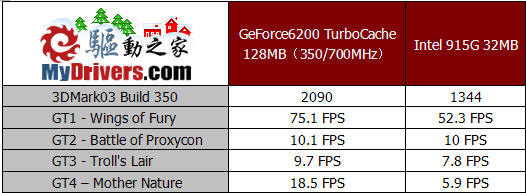
与3DMark2001SE主要检验了显卡的DirectX7和DirectX8性能不同,3DMark03则更加偏重于测试显卡DirectX8和DirectX9的性能,这在最后一项测试Mother Nature中得以更好的体现。此时GeForce6200 TC的DirectX9性能也表现得更为出色,由于915G的集成图形核心并没有提供完整的DirectX9硬件加速,而GeForce6200 TC完整的象素渲染管线和顶点着色引擎则使其在测试中表现远远超过了915G。
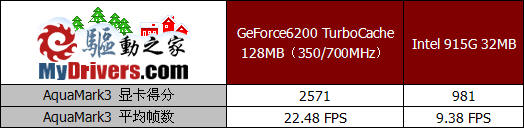
AquaMark3接近真实游戏的测试环境以及特效引擎能够充分的模拟显卡在游戏中的实际表现,并且其测试的公正性也是有目共睹的。由于采用了完全DirectX9的引擎设计,因此在这项测试中,GeForce6200 TC依靠完整的硬件加速功能在成绩上大幅领先,而Intel的915G却很难流畅的运行。
游戏测试:
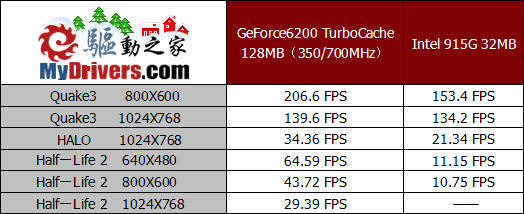
游戏中的表现最能体现显卡的性能,而且对大多数人来说显卡的最大用途也是游戏。我们选择了三款发布时间有一定间隔的游戏,Quake3、Halo和Half-Life2,既考虑到作为低端显卡,日常多应用于对显卡性能要求不高的游戏,又考虑到用户对于显卡能够运行最新游戏的需求,因此也用最新的游戏Half-Life 2对其进行了考察。从测试成绩能够看出,虽然板载的显存只有16MB容量、32bit的显存位宽,但GeForce6200 TC却完全能够流畅的运行Quake3和Halo,相比之下915G的表现便差强人意了。对于全新的Half-Life 2,GeForce6200 TC也能够轻松的胜任,在1024X768的标准分辨率下,平均帧数也接近30FPS,保证了较为流畅的运行,而降低分辨率则能够取得更加流畅的游戏效果。此时只有部分DirectX9硬件加速的915G即使在640X480的最低分辨率下也只能有11.15 FPS的性能表现。
[意外的发现——超频测试中的提升频率与性能]
由于GeForce6200 TurboCache与以往的显卡不同,因此我们也不能像以往测试中那样对核心及全部显存进行时钟频率的调节,这是因为大部分的显存容量都来自于内存的共享,而内存频率多数也都是与系统保持同步,并且内存的超频余地是很小的。从上表的测试成绩我们能够看出,这款产品核心及显存还是有一定超频幅度的,我们将核心以及板载显存的频率分别提升了50MHz和100MHz,从而保持了核心及显存的频率同步,也能够保证显卡性能的充分发挥。
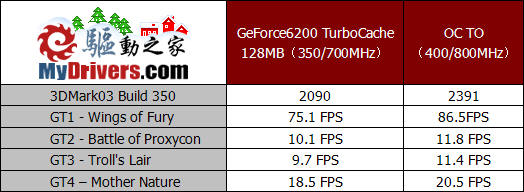
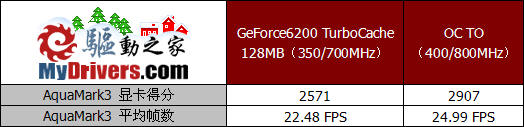
通过对GeForce6200 TurboCache核心以及显卡板载显存的超频我们也发现了一些有趣的问题。通过3DMark03和AquaMark 3的两项测试的对比,我们发现测试得分的提升与频率的提升完全成正比,提升幅度都是接近百分之十四,难道显卡的性能并没有受到内存运行频率较低的限制?这个问题我们觉得值得研究,简单试想一下,通过TurboCache技术的介绍我们能够了解到,这项技术是将以往需要在显存中处理的各种渲染和贴图纹理数据,改为由系统内存进行处理,这部分数据在处理的过程中并不需要较高的运算能力,但由于数据量相对较大,因此对显存的传输带宽以及显存容量都提出了较高的要求。而双通道DDR400内存能够提供足够的内存容量和高达6.4GB/sec的最高传输带宽,因此有足够的能力满足显卡对纹理渲染等工作的需要。反而在这种情况下,应用程序以及游戏对显示核心的多边形生成速度、顶点及象素处理能力都提出了更高的要求,由于核心频率较低也因此成为了整体性能的瓶颈,而提升频率的作用自然就非常明显了。当然,由于没有经过足够的验证和测试,我们也不能肯定的对此下结论,对于这种现象究竟是什么原因造成的,以及在采用其它PCIE芯片组的平台上会不会有相同的情况发生,我们只能通过以后更为详细和全面的测试来加以证实了。
[两根内存是否必要——双通道与单通道能影响TurboCache多少性能?]
由于GeForce6200 TurboCache需要大量的共享内存来实现大部分的纹理渲染,对内存带宽的需求还是很大的,因此这便对内存的选择提出了要求,我们也对单通道和双通道两种情况下的性能进行了对比测试。
普通的单通道内存系统都只具有一个64位的内存控制器,而双通道内存系统则有2个64位的内存控制器,在双通道模式下具有128bit的内存位宽,从而在理论上把内存带宽提高一倍。以DDR400为例,其在单通道情况下的内存带宽只有3.2GB/sec,而如果采用双通道内存则能够实现6.4GB/sec的内存带宽。此外,虽然双64位内存体系所提供的带宽等同于一个128位内存体系所提供的带宽,但是二者所达到效果却是不同的。双通道体系包含了两个独立的、具备互补性的智能内存控制器,理论上来说,两个内存控制器都能够在彼此间零延迟的情况下同时运作。两个内存控制器的这种互补设计可以让等待时间缩减50%。双通道DDR的两个内存控制器在功能上是完全一样的,并且两个控制器的时序参数都是可以单独编程设定的。
通过前面的GeForce6200 TC技术规格分析,我们发现即使在受到芯片组限制的情况下,TurboCache的逻辑核心依然能够达到 4GB/sec的传输带宽,而如果采用nForce4芯片组的话则能够达到PCI-E上下行一共8GB/sec的带宽需求。因此能够看出,TurboCache技术对内存带宽的需求还是相当大的。从理论上来说,双通道的DDR400内存应该是很必要的,那测试的结果又是如何呢?
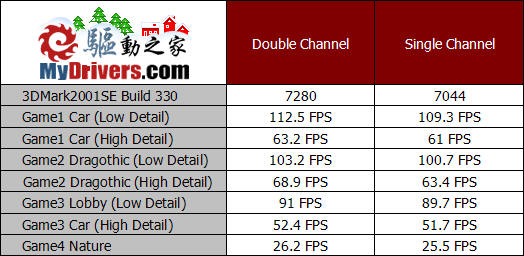
从测试成绩来看,单通道确实对显卡的性能造成了一定的影响,3DMark2001SE的各项测试成绩都有所下降,而最终得分也下降了百分之三,看来单通道的内存带宽确实成为了显卡性能的瓶颈。
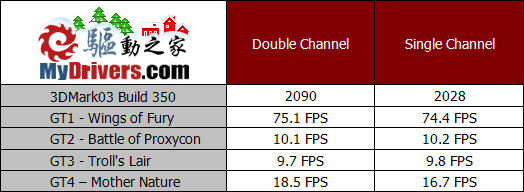
3DMark03的测试中结果也依然相似,成绩下降了接近百分之三。而在最后一项对显示带宽要求更高的测试中,成绩下降则更为明显,达到了9.7%。看来随着游戏纹理渲染需求的增加,内存带宽不足的问题也更加明显了。
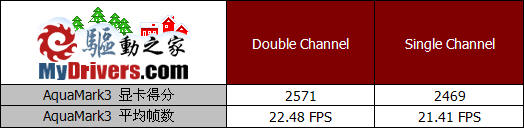
AquaMark3的众多测试场景也都是需要进行大量的纹理渲染,在单通道模式下成绩下降也接近百分之四,而平均帧数也有所降低。
综合以上的几项测试,我们能够清楚的了解到内存带宽对于GeForce6200 TurboCache的性能影响,通过对比双通道内存由于带宽高出一倍的优势,因此性能更为出色。而单通道由于只有3.2GB/sec的内存带宽,因此性能稍显逊色。
不过我们也发现,内存带宽一倍的差距并没有造成显卡性能上巨大的差异。究其原因,我们认为是由于测试平台采用了Intel 915芯片组,前面曾经提到,不同的芯片组由于采用了不同的PCI-E传输方式,因此并不能完全发挥PCI-E总线的带宽优势。而Intel 915芯片组的PCI-E带宽最高只有上行的3GB/sec和下行的1GB/sec,总带宽只有4GB/sec,因此双通道内存的带宽只有4GB/sec能够被显卡所采用。这也就是为什么采用双通道和单通道DDR400内存的性能差别并不是很大,因为这实际上只是4GB/sec与3.2GB/sec之间的性能差别。
由于我们手中并没有其它的PCI-E平台,例如nForce4和K8T890,因此对于这个问题的探讨也只能止步于此。不过通过数据我们也能够推测出,由于nForce4平台的PCI-E通道设计实现了对8GB/sec的双向数据带宽,由于总线的带宽瓶颈被打破,因此采用双通达内存将会获得更大的性能提升,而双通道与单通道之间的性能差距也会更加明显。这个问题我们也会在今后的测试中逐步去验证。
[内存频率——影响TurboCache性能的另一个因素么?]
前面提到了内存带宽对于GeForce6200 TurboCache的性能有很大影响,我们也都知道内存的带宽由颗粒的位宽和显存的频率所决定,除了单通道与双通道存在带宽差别,不同频率的内存产品也会造成带宽的不同,那么搭配拥有更高频率的DDR2-533内存,会不会有比普通的DDR-400内存更加出色的性能表现呢?我们带着这样的疑问对搭配不同内存后,GeForce6200 TurboCache的性能进行了对比。
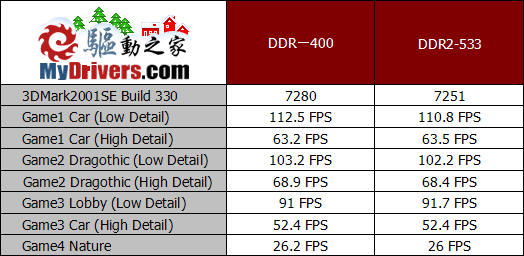
测试成绩有些出乎我们的意料,在换用频率更高带宽更大的DDR2-533内存之后,3DMark2001SE的测试成绩反而有所下降。
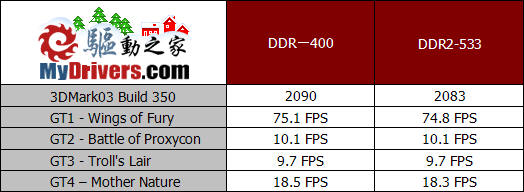
3DMark03的测试结果也依然如此,不过差距十分微小,我们认为这种成绩上的差别很有可能是测试误差造成的。通过几个测试游戏分项的性能表现,也能够看出采用两种不同频率的内存性能完全是相同的。
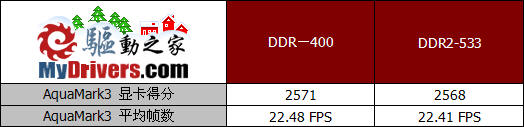
在AquaMark3中,采用DDR2-533内存的平台也没有什么性能起色,看来显存频率和带宽的巨大提升并没有对显卡的性能有实质的促进作用。
为此,我们也想到了多种原因来解释这种现象。
1.虽然DDR2-533拥有更高的时钟频率,因此能够提供更大的传输带宽,但DDR2较高的延迟问题在低频率下对系统性能的影响也是不容忽视的,因此很有可能是这种高延迟影响了显卡性能以至于系统性能的发挥。
2.Intel 915芯片组的PCIE传输带宽只有最高4GB/sec,会不会是这种较为保守的传输模式,限制了DDR2-533使GeForce6200 TurboCache性能的进一步提升?我们在上一部分也已经提到,这样的总线带宽连DDR-400的传输带宽需求都不能满足。如果这种假设成立,那目前的915/925平台已经不能满足TurboCache技术的需要,DDR2内存也没有了任何意义;反而AMD平台会更加适合TurboCache技术的发挥。
当然还可能是由于其它原因,而我们现在的结论也还是一种猜测,相信随着测试的更加深入问题也会逐渐明朗。然而对于大多数消费者来说,购买DDR-400的内存构建双通道内存系统也许是最好的选择,这不仅是因为DDR2过高的价格让人难以接受,另一个重要的原因是目前AMD平台并没有引入DDR2内存,而能够充分利用PCIE带宽发挥GeForce6200 TurboCache真实性能的平台正是支持AMD64处理器的nForce4。
[是否越大越好——内存容量与 TurboCache性能的研究]
除了核心频率与显存带宽,另一个对显卡性能影响较大的因素就是显存的容量,目前主流的显卡市场128MB容量已经成为标准配置,而在3DMark05的测试中,第一个游戏测试项目便需要超过100MB的显存来进行大规模的纹理渲染,没有足够的显存容量便不可能拥有流畅的显示效果。而对于GeForce6200 TurboCache来说,能够从系统内存中划分出更多的部分用于图像处理自然会对显卡性能的提升有所帮助,但内存的过多被调用也会自然而然的影响系统的整体性能。虽然TurboCache技术能够根据需要灵活的分配调用内存的容量,但当运行大型的3D应用程序时,系统内存的总容量还是至关重要的。
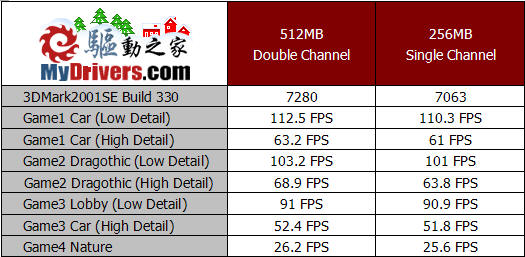
测试成绩证明了我们的推断,内存容量的减小确实影响了显卡性能的发挥,不过究竟是由于内存容量的降低,导致显卡可以调用内存的减少从而限制了显卡性能,还是由于系统整体性能的降低引起了显卡得分下降,对此我们并不能做出准确的判断。
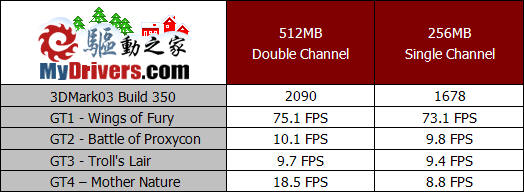
相比3DMark2001SE,3DMark03在内存容量减半的情况下成绩下降更为明显,尤其是对显卡性能要求最高的第四个游戏测试项目,在内存容量和内存带宽减半的共同作用下,成绩下降甚至超过了百分之五十。
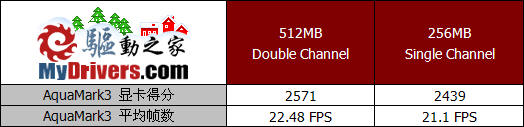
测试成绩显示了512MB内存容量对于GeForce 6200 TurboCache的必要性,在256MB内存已经不能满足日常办公应用的前提下,再被显卡调用部分容量用于图形处理,系统的整体性能可想而知,而显卡的性能也会受到很大的制约。因此,我们建议选购GeForce6200 TurboCache显卡产品的消费者,最好保证你的系统内存容量大于512MB。
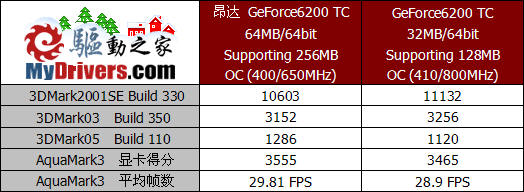
[规格最高——昂达的64MB/64bit版测试]
在测试即将结束的时候,我们又收到了昂达送测的采用P262的PCB版型设计,具有64MB/64bit显存规格的产品。
由于测试时间紧迫,我们并没有进行较为全面的测试,而是针对几个大家比较关心的测试项目以及几种比较重要的特性进行了测试。从前面的规格介绍中我们已经了解到,这种型号的GeForce6200 TurboCache不但拥有更大的板载显存容量,和更高的显存位宽,其能够调用的系统内存上限也由P282版的128MB上升为256MB,因此可以说这款产品具备所有GeForce6200 TurboCache中最大的显存容量。当然,由于采用的是TSOP封装的显存颗粒,因此显存频率也降低到了550MHz。
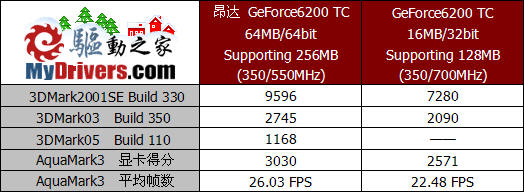
从标准频率下的测试成绩来看,64MB/64bit版本相比16MB/32bit版本在成绩上提升幅度相当大,这不但得益于板载显存容量以及显存位宽的大幅增长,也和其最高能够利用的系统内存容量有很大的关系。从中我们也能够深刻的体会到,显存带宽以及显存容量对显卡性能的作用是至关重要。
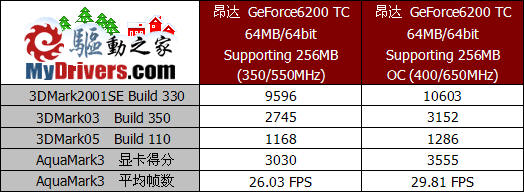
与16MB/32bit的版本相比,64MB/64bit的GeForce6200 TurboCache搭配了TSOP封装方式的显存颗粒,显存频率也降低了不少。我们尝试了简单的超频,由于核心相同因此频率提升50MHz也与之前相同,而显存由于搭配了3.6纳秒规格的颗粒,因此超频至650MHz也已经接近了极限。从测试结果来看,频率的提升进一步带来了性能表现的改观,3DMark2001SE已经突破了一万分,3DMark03的成绩也超过了3000分,而AquaMark3的测试中平均帧数也接近30FPS,已经能够流畅的运行。
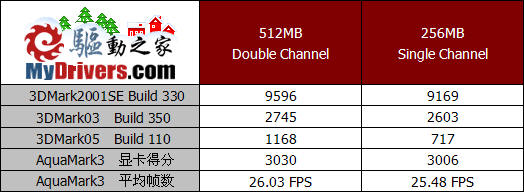
由于64MB/64bit的GeForce6200 TurboCache系统内存调用的上限已经达到了256MB,那么如果我们搭配采用256MB内存的系统,会不会发生由于系统内存被显卡大量占用而造成系统资源不足的现象?又或者会不会发生大部分内存被系统调用,显卡由于没有足够容量的内存来进行纹理渲染而导致性能大幅下降呢?带着这样的疑问我们拔下了主板上的一条256MB内存,此时的系统只具备单通道的256MB内存。测试的结果相当令人欣慰,虽然内存容量和传输带宽的减半对显卡性能造成了影响,但成绩的下降还是让人能够接受的。这同时也证明了TurboCache技术在对系统内存进行调用和释放时的处理能力很强,并没有出现我们之前设想的结果,可以看出内存容量被显卡和系统充分的加以了利用。当然,256MB的内存容量也确实有些捉襟见肘,这在对系统配置要求较高,并且需要进行大量纹理渲染的3DMark05中表现的更为明显一些。所以我们也再次建议大家,512MB的内存容量对于GeForce6200 TurboCache是必须的,内存容量低于512MB不但会影响显卡性能,对系统的整体性能也会有很大的制约。
[32MB/64bit版到位——测试阵容更加齐整]
测试的最后时刻,又有一款新产品加入了进来,我们收到了NVIDIA公版搭配32MB/64bit显存颗粒的版本,它其实和16MB/32bit的版本采用了完全相同的PCB设计,只是在PCB板的背部空焊位增加了另一颗显存颗粒。通过简单的显存增加,这款产品在显存容量和显存位宽上都翻了一番,那它的性能表现如何呢?
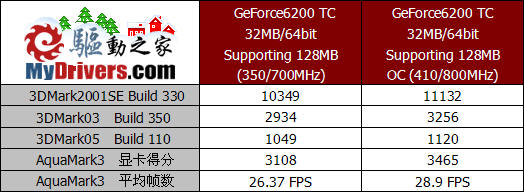
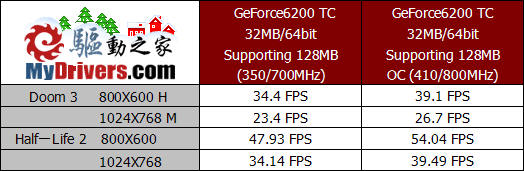
这是32MB/64bit版本GeForce6200 TurboCache的测试成绩,除了默认频率的成绩我们还尝试了超频,由于与16MB/32bit版本的PCB设计完全相同,因此超频幅度也比较接近。显存位宽和显存容量的提升,使这一版本的性能有了明显提升,超频后效果也更好。
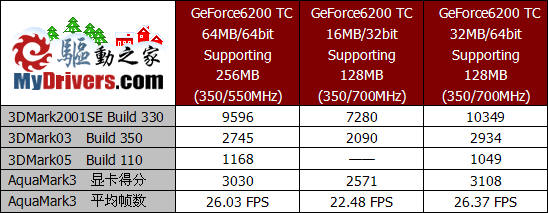
加入了这款产品的成绩后,我们已经对GeForce6200 TurboCache中的几款典型产品进行了测试和对比,我们的测试也可以算是比较完整了。从中我们能够了解到,64bit显存位宽的产品性能相比32bit的产品有很大提升,因此在选购产品时64bit位宽的产品一定是首选。而对于同为64bit位宽的TSOP版本和mBGA版本,我们发现他们各有优势。对于需要较高的象素填充率的应用来说,如3DMark2001SE和3DMark03的测试中,mBGA版本依靠更高的显存频率取得了性能领先;而在对纹理渲染所需要的显存容量较高的应用环境下,如3DMark05的测试中,TSOP版本高达256MB的最大动态显存容量便显示出了优势。
而从超频的对比情况来看,TSOP版本超频后的性能提升也更为明显。在3DMark05和AquaMark3中性能领先,在其它项目中也与mBGA版本相差无几。如何选择还是需要消费者自己来衡量。
[出色的性能价格比——TurboCache技术前景广阔]
TurboCache技术的出现,打破了以往消费者对于独立显卡性价比的观念。从制造成本来看,动态分配系统内存的应用降低了显卡板载的显存数量,因此显卡整体的成本进一步降低。而从性能来讲,TurboCache技术的出现则对目前的板载整合显卡造成了极大的威胁,与原有形式的独立显卡相比也丝毫不逊色。更高的性价比使得采用TurboCache技术的GeForce6200必将受到消费者的欢迎。
此外,TurboCache技术也充分利用了PCIE总线构架的新特性,发挥了PCIE总线的高带宽优势,除了起到减少显存投入降低显卡成本的作用,更能有效的促进PCIE平台的普及,相信随着这款产品的价格到达一个合适的价位以后,它很有可能成为PCIE平台使用最为广泛的一款产品。
除了目前的应用之外,我们还会很容易的联想到笔记本显卡,NVIDIA之前发布的全新的笔记本图形显示架构MXM,也同样利用了PCIE的总线构架,因此能否在未来的笔记本图形产品中见到TurboCache技术的身影,也是我们十分期待的。
另外,面向于低端市场的采用Turbo Cache技术的显卡产品,由于其最大的特点在于能够充分利用PCIE带宽对系统内存进行实时调用,因此如果能够将这项技术直接应用到主板产品上,从而进一步提升板载显卡的性能,那一定也非常具有竞争力。
因此,我们对TurboCache技术的未来也充满了期望,相信通过与PCIE技术的紧密集合,这项技术的应用前景将是十分广阔的。
[显卡图片赏析-NVIDIA公版]



[显卡图片赏析-昂达PCX6200 TC 64MB/64bit]



本文收录在
#快讯
- 热门文章
- 换一波

- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...