正文内容 评论(0)
【推土机模块化架构(二)】
浮点
推土机中的浮点单元也经过了完全重新设计,可以在不同核心之间共享资源。每个推土机模块内都有共享的两个128位乘法累加单元(FMAC),可以每个核心执行128位指令,或者每个模块执行256位指令。
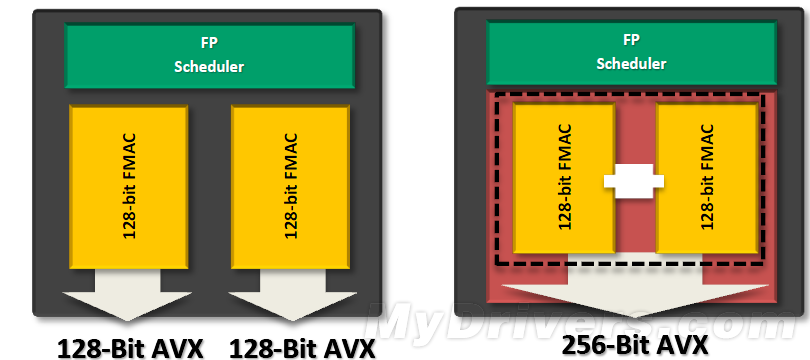
推土机浮点单元还改进支持了大量新的指令集。Phenom II X6仅有128位浮点,Intel Sandy Bridge增加了SSSE3/SSE4.1/SSE4.2、128/256位AVX、每周期两个128位AVX、每周期128位AVX+SSE。推土机不但将这些照单全收,还独家支持FMA4乘加指令、XOP扩展操作指令(曾经的SSE5)。
另外在每个时钟周期内,推土机运行双精度x87指令的速度为8FLOPSs,持平Sandy Bridge且比Phenom II X6快一半,128位AVX指令的执行速度则是64FLOPS,前者达到了Sandy Bridge的两倍。

那么指令集都有什么用呢?下边简单列举几个:
SSSE3/SSE4.1/SSE4.2(Intel、AMD共有):视频编码与转码、生物统计算法、文字密集型应用。
AESNI PCLMULQDQ(Intel、AMD共有):AES加密应用、安全网络交易、磁盘加密(微软BitLocker)、数据库加密(Orocle)、云安全。
AVX(Intel、AMD共有):浮点密集型应用,诸如信号处理与地震、多媒体、科学计算、金融分析、3D建模。
FMA4/XOP(AMD独有):高性能计算应用,诸如数字应用、多媒体应用、音频算法。
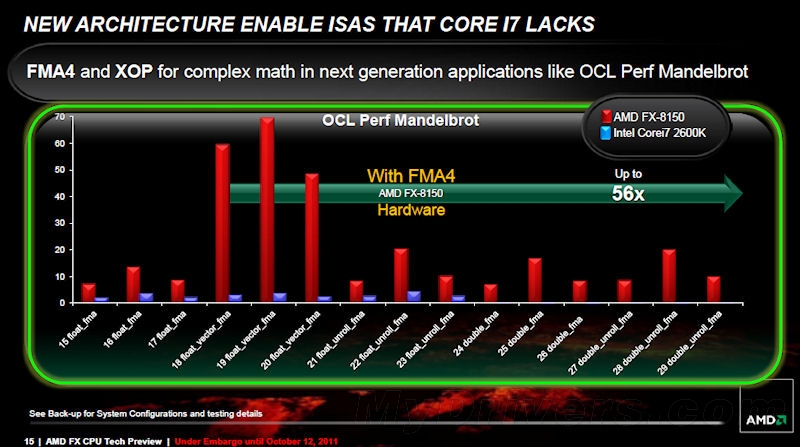
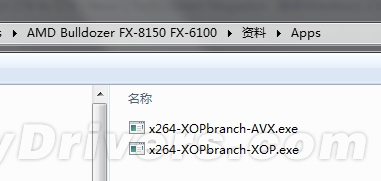
指令集的变化自然需要软件的支持才能发挥效力,尤其是FMA、XOP两大独家指令。如果软件还在使用老的浮点指令,推土机的特点显然就发挥不出来。在操作系统和软件程序完善之前,可以运行一下AMD提供的两个XOP、AVX补丁程序,再跑分就会有明显的不同。
其实,这两个小程序正是近日网上传闻的所谓“鸡血补丁”,而且有时候确实能“鸡血”一下,比如让FX-8150 wPrime 32M运算时间从15秒钟缩短到10秒钟。
共享前端
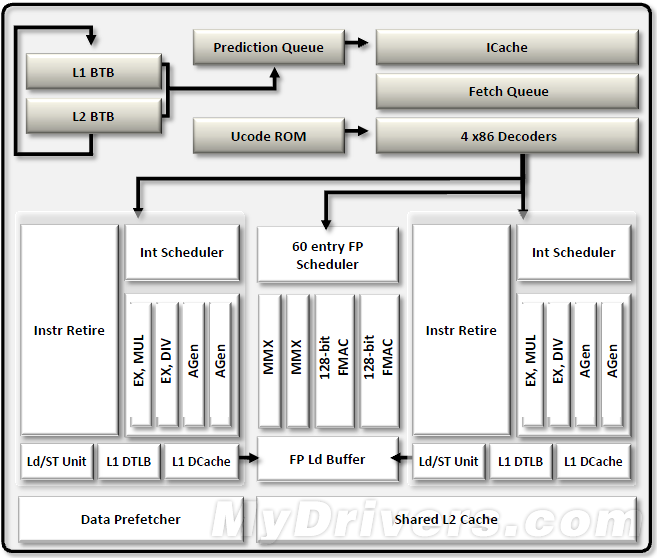
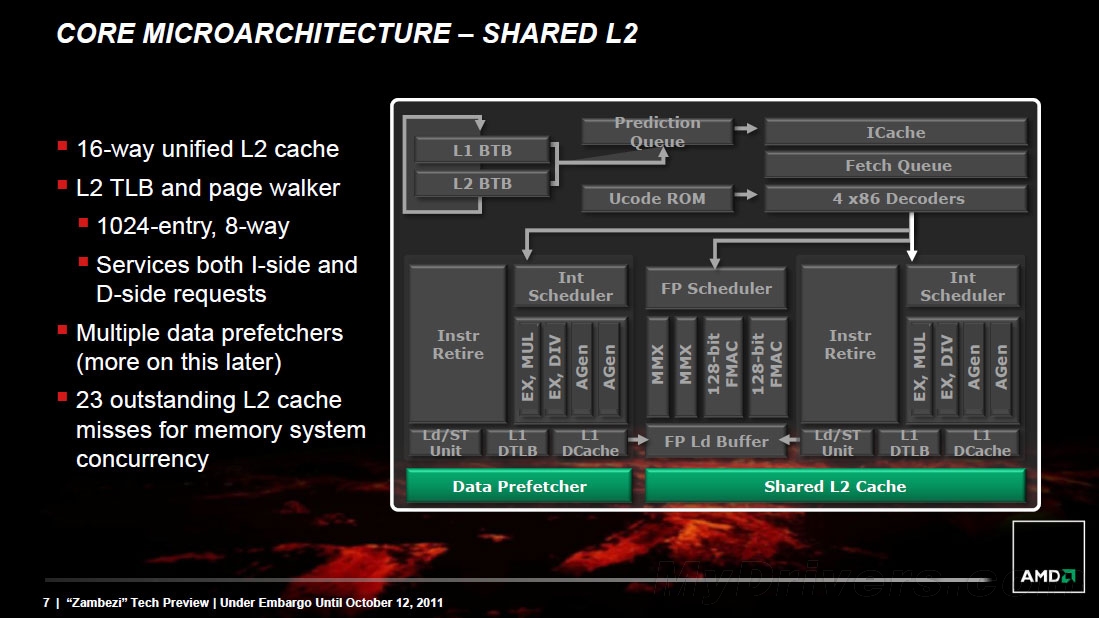
前端(Front End)的任务是驱动处理管线、确保核心随时获取所需信息。在推土机中,每个前端配合一个模块,并负责为其中的两个核心分配线程。AMD在这里也做了大刀阔斧的改进,涉及不相关预测和拾取管线、预测定向指令预取器等等。一个预测队列可以管理一级、二级分支目标缓冲(存储目标地址)所需的直接、间接分支。推土机模块可以在每个时钟周期内解码最多四条指令,而K10 Phenom II只有三条。换句话说,推土机从三发射变成了四发射,就像Intel Sandy Bridge。
预测管线会生成一个拾取地址队列。拾取管线则在每个时钟周期内从指令缓存里拉取32个字节加入拾取队列,再送往解码器。
推土机和Sandy Bridge一样使用了物理寄存器文件(PRF)。这是一个单独的位置,用于保持执行指令的寄存器结果。这种设计可以消除不必要的数据移动和复制,只保留一个拷贝而不用对数据进行广播。

缓存
推土机的每个核心都有64KB一级数据缓存、64KB一级指令缓存、32-entry全关联数据页表缓存(DATA TLB)、完整乱序载入/保存单元,后者可以在每个时钟周期内载入两个128位或载入一个128位指令。
每个模块配备2MB 16路关联二级缓存、124-entry二级页表缓存,可同时处理指令和数据请求。推土机支持最多23个二级缓存不命中,用于保持内存系统一致性。
最后,一颗推土机处理器的所有模块与核心共享8MB 64路关联三级缓存。
本文收录在
#快讯
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...