正文内容 评论(0)

在RV870核心当中,可以看到两组SIMD阵列呈对称型排列,其中每组阵列当中均有800个流处理单元设计,事实上在单一SIMD引擎当中,采用的排列方式依然是RV770的设计方式。从RV770到RV870,规格正好翻了一倍,可以看做由两个RV770核心封装在一起。虽然由GT200到GF100,流处理器也增加了一倍多,由240个增加到512个(完整的GF100核心,GTX480采用480个),虽然表面看来都是规格的增加,但事实上GF100的架构发生了很大的变化。
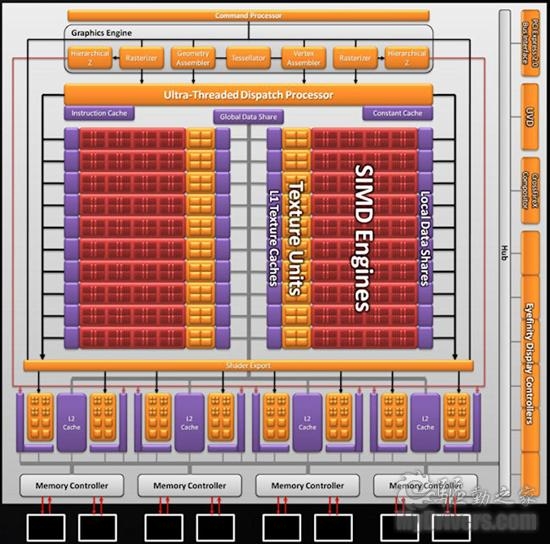
RV870核心架构图
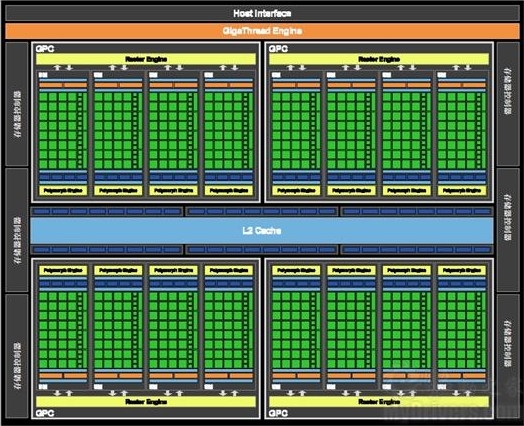
GF100核心架构图
总体来看,GF100核心主要划分为Host Interface(主接口,主要负责PCI-E通讯传输,包括读取CPU指令等)、GigaThread Engine(主线程调度引擎)、四组Graphics Processing Clusters(GPC,图形处理集群,GPU的核心部分),其中每个GPC包含四组流式多处理器(SM)、四个PolyMorph引擎(多形体引擎,执行曲面细分的主要单元)、一个Raster引擎(也就是原有的光栅引擎经过重新设计并且位置也有所改变),而每组流式多处理器内又有32个流处理器(NVIDIA称之为CUDA核心,完整的核心拥有512个),六组Memory Controller(GDDR5显存控制器,每组显存控制器位宽为64bit,总位宽384bit)、L2 Cache(二级缓存,容量为768KB)、六组ROP单元(每组包含8个ROP,共48个)。
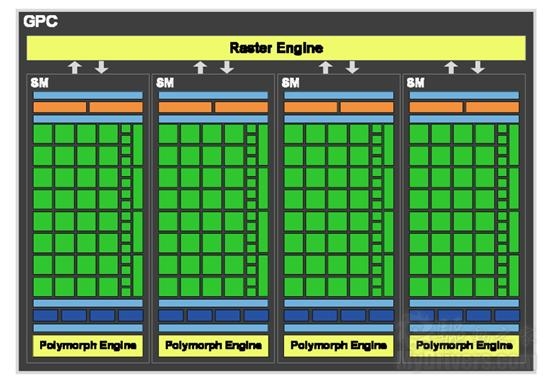
GPC单元架构图
四组(16个)SM都是高度并行的多处理器,能在任何时候支持最多48个Wrap。512个CUDA核心都是统一的处理器核心,能够执行顶点、像素、几何学和计算内核等不同任务。48个ROP单元可用于像素混合、抗锯齿、原子存储等操作,每组6个由一个64位显存控制器进行控制。统一的二级缓存则能够提供载入、存储、纹理操作等服务。
所以GF100架构实际的运作流程就是在GPU通过主接口获取了CPU的指令之后,GigaThread引擎将会从系统当中调取GPU所需计算的数据,并且拷贝到存储器当中。随后,GigaThread引擎将这些数据为不同的SM创建和分派线程块。每组SM会将GigaThread引擎分配来的线程块分配至Warp(32个线程的群组,后文当中为大家详细介绍),再由Warp调度器重新分配为线程,并由分派单元派发至每个CUDA核心或者其他执行单元上。
如果此时某一个SM阵列当中的工作出现无法完成的情况,例如在完成了Tessellation(曲面细分)以及光栅化之后即将进入其他流程,但是单个SM阵列无法完成全部工作,那么GigaThread引擎能够将这些已完成的数据重新分配到其他的SM阵列当中,避免了因为某一个SM阵列数据量过大,导致所有SM阵列空循环,从而提高执行效率。
如果说RV870类似一个“双核心”的GPU,那么GF100就可以看做“四核心”设计了。相比GT200,GF100引入了GPC,并在在每组GPC以及SM阵列中加入了Rester引擎以及PolyMorph引擎,事实上这也是GF100相对老一代架构针对DX11作出的最大改变。
本文收录在
#快讯
- 热门文章
- 换一波

- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...