DeepSeek千般好,万般好,就是联网搜索还用不了(愁.jpg)。
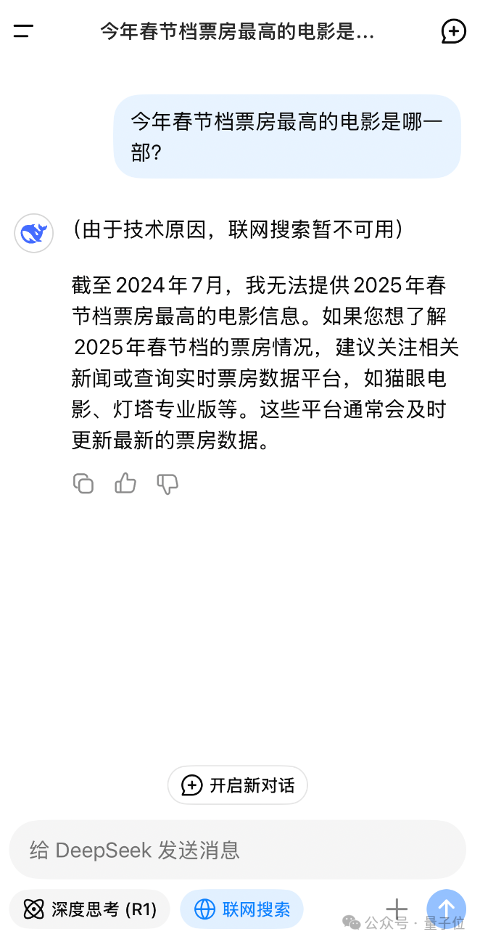
但先别急,这块拼图也被国产AI搜索玩家用自己的能力补全了:
就在刚刚,秘塔AI搜索宣布融合了DeepSeek-R1满血版。
这意味着现在起,R1推理能力已经可以链接全网实时信息一起用了!
也意味着从今天开始,DeepSeek-R1还链接上了秘塔AI搜索背后数千万的高质量论文信息。
如此一来,就实现了「国产最强推理+全网实时搜索+高质量知识库」结合,答得更快,答得更准。
咱们就是说先来一波鲜测!大家快来围观看一看。

首波鲜测:构建哪吒票房预测模型
已知的是,DeepSeek-R1满血版体验下来,最突出特点就是复杂推理。而国产秘塔AI搜索,则是拥有强大的联网检索能力,而且能够结合背后海量知识库/论文数据,给出某个技术发展情况,堪称学术知识利器。
两者强强联合,能够迸发出什么样的火花?
首先,页面端只是一个小小的变化——
新增了个开关,打开「长思考」就能使用新功能了,有简洁、深入、研究三种模式。想要深入体验效果的,可以选择后两种。

接下来,咱们就来看点实际的效果展示。
之前大家玩DeepSeek整了不少花活,比如用特定的人设来撰写诗词、新年献词之类。
把这个需求扔给秘塔,看看效果如何:
模仿《少年中国说》,写一篇文章,介绍杭州崛起的国产科技和AI力量。
秘塔AI搜索很快完成了一篇《杭州AI说》。
主动提到“杭州六小龙”,提到杭州教育和人才方面、产业集群和创新生态的特色,以及模仿《少年中国说》的结构,擅用排比、比喻。

最后一句有点子意思:智领时代,杭州正当!
测试完吟诗作赋的能力,接下来试一些难度比较大的,用上数学建模那种的。
问题一:
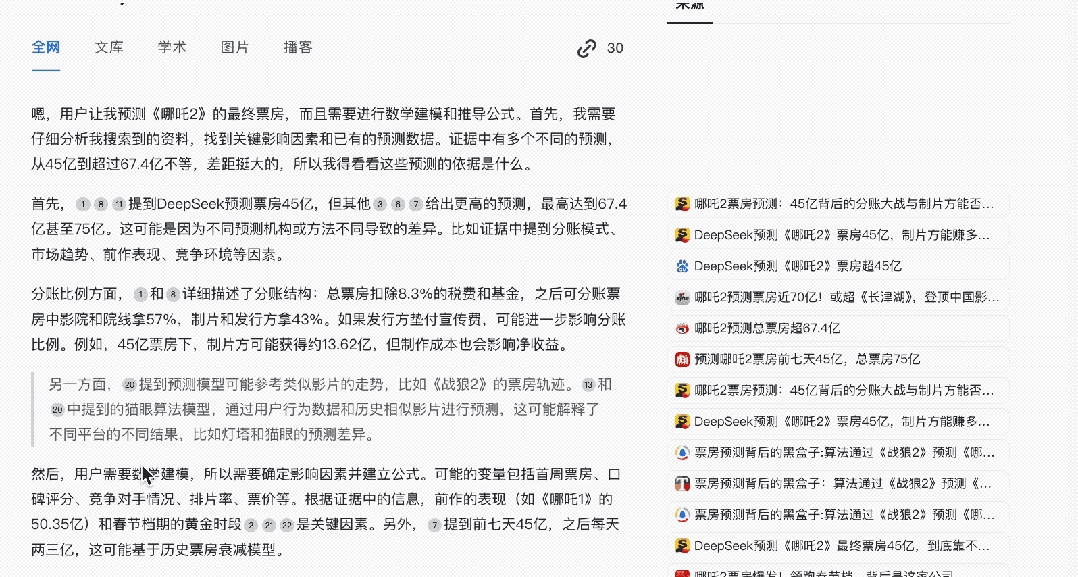
预测《哪吒2》的最终票房成绩,要求:进行数学建模,给出推导的公式。
先来看结果:最终将超越《长津湖》成国内影史票房冠军,票房预测区间为60-67亿。公式为:

嗯,这个答案感觉跟大家感知到的大差不差,有点子道理~
那再来看看它具体是如何思考的。
整个思考过程,很像复刻了DeepSeek的深度思考模式~

它结合海量搜索到的材料,想到多个可能的变量因素(比如首周票房和衰减率、观影人次、分账比例等),可能的建模步骤和模型等等,最终确定了基准数据和三大关键影响因素(口碑效应、竞争环境、市场容量)。

然后就是数学模型的构建,采用首周票房驱动模型,其衰减率结合多个因素的影响。

好好好,感觉有模有样的。
最终结果且不论,单是这个过程有实时联网:它知道最新实时票房以及各方预测结果,还有复杂的数学推理过程,指数求和都给搬来了……
把DeepSeek复杂推理的特点完美地融入到了里面。
那么接下来,来上点有难度的,预测一下英伟达股票:假如我很有钱,这时候买入,能不能抄底。
问题二:
我现在购入英伟达股票,十万预算,一年之后大概能赚多少。
这次咱们尝试一下「研究」这种模式,与「深入」模式不同的是,它在回答问题之后还会针对一些行业问题进行研究和思考。
比如主要竞争对手及其市场份额变化、芯片量产进度情况、未来趋势等等。感觉知识从脑子里一闪而过~


在考虑到过往财报表现、短期市场预期、技术迭代、风险挑战等多重因素,最终得出:
合理预期收益范围在10%-30%之间(约11万-13万元)。

不过最后还是建议说,投资有风险,大家需谨慎。
不错不错,既有客观的估算,也有善意的提醒,咱们就是说还是在考虑考虑吧(不是因为没钱哈)。

考验了这些通用的现实问题,那就来测测秘塔本身的强项——拥有海量的高质量知识/论文数据,再结合了DeepSeek的联网+推理能力之后,能碰撞出什么样的火花?
这两年海内外大模型发展神速,也吸引了众多人才想要参到这场技术浪潮中,对于想入行或者刚入行的人来说,OpenAI的模型进展绝对代表着技术风向,那么就来考考秘塔。
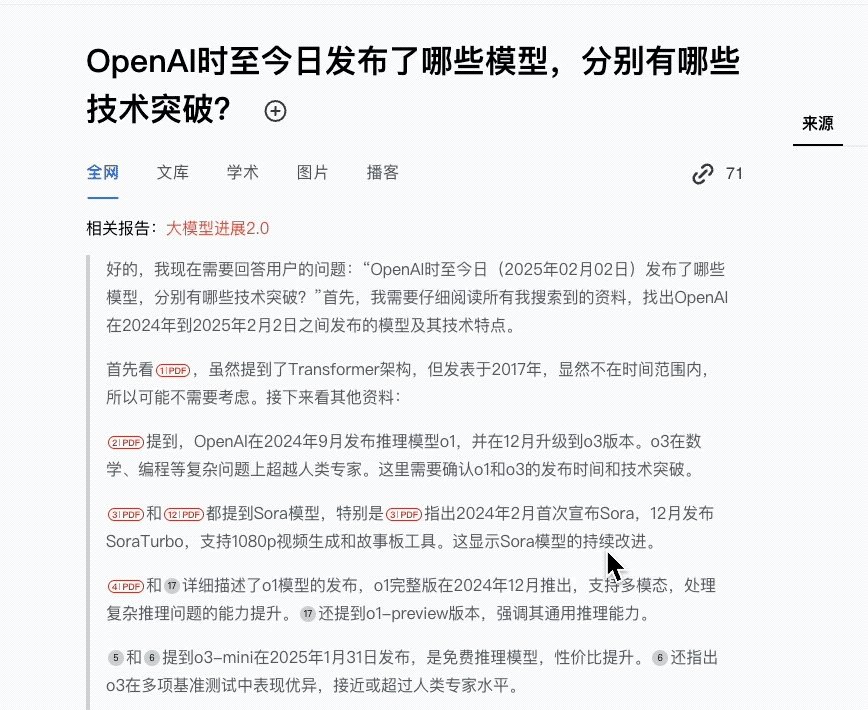
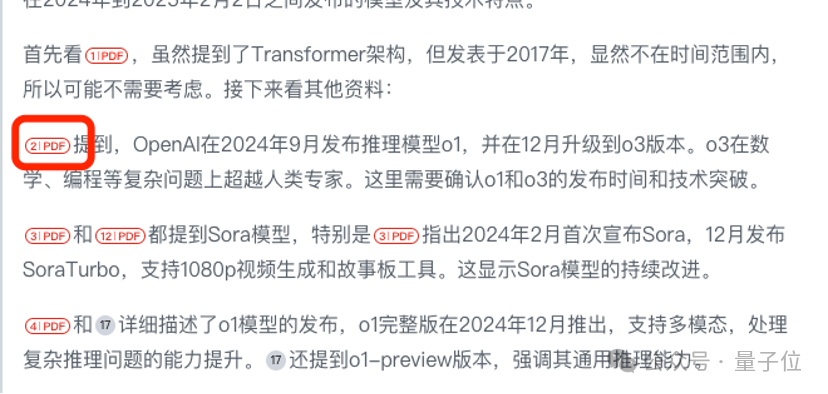
OpenAI时至今日发布了哪些模型,分别有哪些技术突破?

首先,时间正确。(o゜▽゜)o☆[BINGO!]

其次,它主要分析了2024年以来Sora系列、o1系列模型以及GPT-4 Turbo等重要模型。
以此总结出四大技术突破方向:

值得一提的是,它还提及了GPT-5未发布,以及推理模型、多模态模型市场竞争激烈。
而且里面都有具体的引用细节,点击即可查看。

这对于学术圈搞科研的、又或者科技圈技术党来说,真滴是很友好。

能够看到的是,秘塔强大的AI检索能力结合DeepSeek强推理,能够在多方面提升用户体验。包括不限于深度理解与上下文感知、复杂查询处理的能力。
而结合秘塔本身背后海量知识库和知识图谱,能够提供关联性强、更为深度的搜索结果。
太好了,学术科研党有救了
过去半个月里,相信大伙没有一天不被DeepSeek刷屏。
DeepSeek-R1性能与成本远超预期,于是国内国外,先是AI技术圈,然后是更广一点的科技圈,再然后是更广大的普通人……至今,春节假期即将结束,这股热度还远远没有复平。
当然,不可否认,崛起的DeepSeek也面临着种种困难。但有目共睹的是,国产玩家以务实的态度提供各方支援和补足。
例如大年三十,DeepSeek服务器突遭大规模DDoS网络攻击和暴力破解攻击,多家国内安全厂商鼎力相助,抵御攻击,共同维护DeepSeek的服务。
例如DeepSeek的DAU达1909万,阿里云、硅基流动上线DeepSeek-R1等模型,以官网持平的效果来分流替代。
再例如,面对用户们急迫想用上“DeepSeek模型+搜索”的需求时,秘塔AI搜索又出手了。

这次让秘塔AI搜索结合DeepSeek-R1,是急用户之所急,但并不是两个强效AI工具/能力的简单能力相加。
若从AI搜索角度出发,以往AI搜索工具痛点被补齐了。
对接DeepSeek-R1满血版的顶尖推理能力后,秘塔AI搜索可以更准确地理解用户查询的意图,处理更复杂的查询(如多条件筛选、语义模糊的查询等),从而返回更快速、相关、精准的信息结果。
而在信息爆炸的时代,增强推理能力就能让AI通过分析信息的来源、内容的逻辑性等,帮助过滤谣言等虚假信息内容,增强搜索结果的信息真实性和可靠性。
而从推理能力角度出发,有了秘塔AI搜索联网+知识库能力的DeepSeek-R1更是如虎添翼。
坐拥全球顶尖推理能力,又拥有了AI联网搜索及背后的高质量索引库,不光可以实时查询最新资料,还能全网无死角搜罗、摘取、分析各种论文,进一步形成思维导图汇总。
小到查询一项研究/技术的最新进展,大到纵观一个学科从滥觞至今的技术发展,无一不可为。
真的,翻来覆去看秘塔AI搜索+DeepSeek-R1这一招,得出一个结论:
学术圈、科研党们有福了!
只是有点感慨,要是这个创新融合早一点推出,前几天白天走亲戚、晚上赶KDD 2025、ICML 2025、Sigcomm 2025的ddl的朋友们,想来也不会那么痛哭流涕了。

其实回过头来看,DeepSeek之所以能够掀起一浪高过一浪的关注,就是其团队一直在对模型训练和使用成本狠狠砍一刀,直至DeepSeek-R1以1/50的价格表现出不输OpenAI o1的性能。
而以秘塔AI搜索为代表的AI搜索,恰恰正是大模型推理价格下降的最早应用试验田。
我们日日期待大模型训练与使用成本能被打下来,更期待被砍下价格门槛的大模型,能让每一个工作党、学术党、普通人都用起来,用得顺手。
如今,两者强强联合,实现一站式实时联网+搜索+推理,真正做到了推理能力的普及大众,也做到了AI搜索由点到线及面。
最后,照惯例在文末放上使用直通车,大家可以再秘塔AI搜索直接玩起来了~
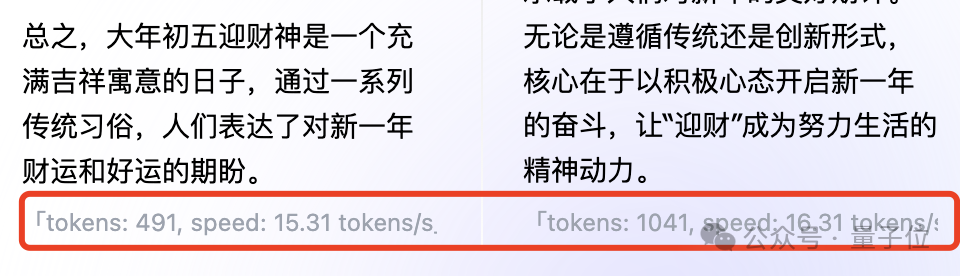
One More Thing今天大年初五,传统习俗迎财神。
突然很好奇,财神爷到底是E人还是I人。
秘塔给出的回答是:

好好好,不管E不E的,祝大家新的一年发大财!
p.s.目前,接入DeepSeek的秘塔AI搜索已经上线网页版,APP稍晚些时候上线~
|