正文内容 评论(0)

10月23日,在北京召开的2019 ARM技术峰会上,ARM正式发布了全新的Ethos-N77/N57/N37系列NPU IP,进一步加码人工智能(AI)计算。
与此同时,ARM还推出了针对主流移动游戏市场的高能效的Mali G57 GPU和针对主流及入门级市场的单位面积最高效的Mali-D37 DPU。
ARMv8及后续架构将不受限制的继续支持中国合作伙伴!
今年9月25日,ARM中国在深圳召开媒体沟通会,针对此前外界盛传的“ARM断供华为”一事,ARM表示与华为仍是合作伙伴,ARMv8及后续指令集可继续授权!
10月23日,在2019 ARM技术峰会北京站上,ARM董事长兼CEO吴雄昂在开场致辞当中再度重申,经过法务严谨的调查及相关调整,目前无论是ARMv8,还是后续的架构都是源自英国的技术,将可不受限制的继续支持中国的合作伙伴!

此外,吴雄昂还指出,ARM在中国的合作伙伴已经超过200家,中国合作伙伴出货的基于ARM架构的芯片已超过了160亿颗,国产SoC芯片95%都是基于ARM架构的。
吴雄昂强调,ARM是唯一非源于美国的主流计算架构。ARM中国承接ARM在中国的业务和技术,在ARM标准之下自主创新、赋能产能,把中国工程师能力调动起来打造知识产权。这些知识产权将不只是提供给中国产业,还要通过统一标准面向全球。
加码AI计算,ARM发布Ethos系列NPU IP
根据ARM及研究机构的预计,到 2028 年,移动设备的数量将从现在的17亿台增长到 22 亿台,智能的IP Camera将由现在的1.6亿台增长到13亿台。在终端侧具有人工智能的设备将会由现在的3亿台增长到32亿台。足见人工智能市场增长之迅速。
而随着AI技术的兴起和广泛应用,AI对于芯片的算力也提出了更高的要求。作为全球最大的处理器IP供应商,ARM的Cortex CPU和Mali GPU在以智能手机为代表的移动终端市场占据了极大的市场份额,但是在AI计算领域,ARM此前一直都是依托于其Cortex CPU、Mali GPU及相关软件开发工具来提升其AI计算的能力。
但是,传统的CPU、GPU核心并不是AI计算的最佳载体。因此越来越多的芯片厂商开始推出了AI专用芯片,或者在SoC当中加入AI计算专用的NPU内核。
比如华为2017年就率先推出了集成NPU内核的麒麟970处理器,同时苹果推出的A11处理器也首次集成了NPU内核。此后,高通、联发科、三星、展锐等手机芯片厂商也纷纷开始在SoC当中集成自己的NPU内核。
在此趋势之下,为了应对市场对于AI内核的需求,ARM在2018年年初也公布了针对AI的Project Trillium项目,其中就包括了全新的机器学习处理器IP、目标检测处理器IP和神经网络软件库。经过了近两年的时间,现在Project Trillium项目的成果也开始正式产品化。

▲ARM市场营销副总裁Ian Smythe
今天,ARM市场营销副总裁Ian Smythe在ARM技术峰会上正式发布了全新的Ethos系列NPU IP,包括针对高端市场的Ethos-N77、针对主流市场的Ethos-N57和低端市场的Ethos-N37。
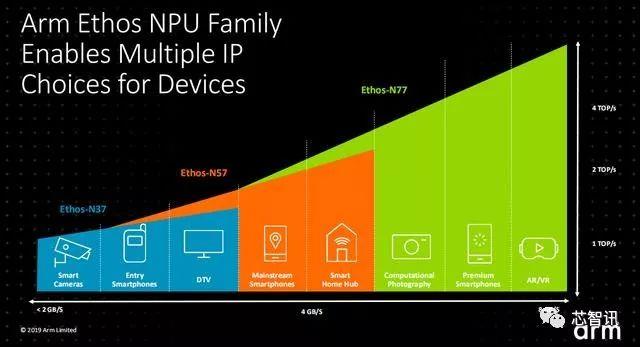

Ethos-N77实际上就是ARM去年公布的Project Trillium项目中的那款机器学习处理器IP,其内部集成了可配置的1-4MB的SRAM,在1GHz主频下,7nm工艺下,可以提供最高4 TOPS的AI算力,每瓦性能高达5 TOP。另外,之前Proj
m项目公布的数据显示,Ethos-N77的单位面积算力为4.6 TOPs/mm?(最新发布的可能有进一步提升)。
那么Ethos-N77的这个性能在市场上处于什么水平呢?

根据资料显示,华为麒麟970 NPU是基于寒武纪1A IP,算力是1.92TOPS。而苹果A11的NPU算力仅为 TOPS,A12的NPU性能为5TOPS。而根据此前高通骁龙855发布之时的数据显示,其整体(包括CPU+GPU+DSP等)的AI算力(超过7 TOPS)是华为麒麟980的两倍,照此估算的话,0.6麒麟980的NPU性能大概在3.5 TOPS左右。
另外据了解,华为麒麟980的NPU是基于寒武纪IH8,是针对低功耗场景视觉领域的NPU内核IP,而寒武纪IH8有 4 种可选的配置1T、2T、4T、8T OPS@1GHz,麒麟980应该是4TOPS的版本。而麒麟990系列的NPU并未公布具体的OPS数据,不过其采用了全新的达芬奇架构以及两个大核+一个小核的配置,性能应该更强。
在单位面积的算力方面,根据芯智讯此前的估算,麒麟970的NPU的单位面积性能大概是1.48 TOPs/mm2,而麒麟980和990没有相应数据可以参考。而根据TechInsights的拆解,苹果A12的NPU内核的面积为5.79mm2,也就是说苹果A12的NPU的单位面积算力约为0.86TOPS/mm2。
在每瓦算力方面,华为公布的资料显示,麒麟810的每瓦算力可以达到6TOPS。苹果的NPU未有相应数据。寒武纪新的NPU内核1M在7nm下每瓦性能为5TOPS。
从上面的数据对比来看,Ethos-N77的AI性能与苹果A12和麒麟980的NPU相当,相比麒麟990系列的NPU性能可能要弱一些。在单位面积算力方面,远高于苹果A12和麒麟970的NPU。在每瓦算力方面,也是远高于苹果A12的NPU,略低于麒麟810。
综合来看,ARM Ethos-N77各方面都还是比较出色的,达到了目前旗舰级NPU的水准。
需要指出的是,4 TOPS的性能是单个Ethos-N77核心在1GHz主频下的性能,如果配置双核的话,那么性能无疑将进一步提升,当然功耗和面积会进一步提升。
ARM此前就表示,Ethos系列IP是具有高可扩展性、兼容性和可编程的,可以提供计算性能最低从2 GOPS到超过70 TOPS的产品。
另外,ARM还推出了针对主流市场的Ethos-N57,内置了512KB SRAM,在1GHz主频下,算力最高可达2TOPS;而针对低端市场的Ethos-N37,是为了提供面积最小的ML推论处理器(小于1mm?)而设计,其同样也内置了512KB SRAM,在1GHz主频下,算力可达1TOPS。
ARM表示,Ethos-N57和Ethos-N37针对Int8与Int16数据类型的支持性进行了优化,通过如创新的Winograd技术的落地,使性能比同类NPU提升超过200%,并且配备了先进的数据管理技术,以减少数据的移动与相关的耗电,在ML在性能与成本、面积、带宽与电池寿命之间达成了比较好的平衡。
据芯智讯了解,除了移动市场之外,ARM的Ethos系列IP未来也将会开始进入物联网、工业、汽车、网络以及服务器市场。
开源的AI开发框架ARM NN
我们都知道,此前高通骁龙845/855系列都并未内置专门的NPU内核,但是其仍然提供了较高的AI能力,而这一切得益于其神经网络引擎Neural Processing Engine的助力。即采用更为弹性的异构的机器学习架构,在通用平台内做内核优化,使得AI计算合理的分布在CPU、GPU、DSP等每个单元上,从而可以针对不同移动终端提供弹性调用各个处理单元来进行AI计算。
而ARM此次在发布Ethos系列NPU IP的同时,也推出了开源AI开发框架ARM NN,强化异构的AI计算,进一步提升整体的AI性能。

据介绍,ARM NN是属于偏底层的架构,而且在其基础之上,可以支持其他的更高层级第三方的NN框架,并提供完整工具链,可实现在AI计算上对于ARM CPU/GPU/NPU内核的合理调用,实现更高效的异构的AI计算。
ARM表示,由于不同的SoC对于AI的加速方法是不一样的,因此第三方应用及开发者要用到片上系统的加速能力是比较困难的。而开源的ARM NN的推出,将降低开发者调用ARM内核的难度,进一步提升开发人员的体验。

此外,为了推进基于ARM NN的内容创建和开发,ARM还与Unity(Unity最目前主要的3D引擎,50%的3D游戏,75%的VR内容都是基于Unity引擎开发)达成合作,进一步优化Unity引擎,使得基于Unity的开发者能够更容易的访问和更高效的利用ARM的内核,在ARM CPU/GPU/NPU之间获得更好的性能。可以实现一次开发,即可获得ARM全系列的内核的支持(即可支持众多基于ARM不同类型的内核的SoC),无需再重新编译。
Mali G57 GPU:为主流市场带来智能与沉浸式体验
今年6月,ARM针对高端市场推出了首款基于全新Valhall架构的GPU——Mali-G77。今天,ARM针对游戏市场推出了第二款基于Valhall架构的高性能、高能效的GPU内核——Mali-G57。(Vahall架构进一步提升了并行执行的能力,同时在代码上也做了尽量的简化,从编译角度来讲也更加友好。)

据介绍,Mali-G57的性能相比上一代的Mali-G52在能效上提升了30%,性能密度提升了30%,机器学习性能提升了60%。并且Mali-G57还加入了针对虚拟现实(VR)提供注视点渲染支持,再加上机器学习性能的提升,可以支持更复杂的XR实境应用。而且,Mali-G57还支持1-6个核心的配置,可以满足不同市场定位的智能手机的需求。
ARM表示,Mali-G57可以将优质的智能与沉浸式体验带到主流市场,包括高保真游戏、媲美电玩主机的移动设备图型效果、DTV的4K/8K用户接口,以及更为复杂的虚拟现实和增强现实的负荷。
Mali-D37:ARM单位面积效率最高的DPU
在今天的技术论坛上,ARM还推出了目前单位面积最高效的显示处理器Mali-D37。

据介绍,Mali-D37是ARM第一个面向主流市场的基于Komeda架构DPU,拥有极高的单位面积效率,在支持全高清(Full HD)与2K分辨率的组态下,16nm制程的面积将小于1mm?。
在性能方面,Mali-D37保留了高阶的Mali-D71关键的显示功能,包括与Assertive Display 5结合使用后,可混合显示高动态对比(HDR)与标准动态对比(SDR)的合成内容。另外,Mali-D37其通过将部分GPU核心显示的工作负载卸载到Mali-D37来工作,以减少GPU的工作以及对于内存的访问,使得系统的功耗可以降低30%。
ARM表示,Mali-D37可以支持入门级智能手机、平板电脑等成本较低的设备,获得2K级别的视觉效果与性能支持。
ARM的通用型NPU能否获得成功?
从目前的市场趋势来看,AI芯片正越来越向专用化的方向发展,越来越多的算法厂商也都纷纷基于自身的算法推出了自己的AI芯片。同样,正如前面我们所提到的,目前华为、苹果、高通、三星、展锐等众多的手机芯片厂商也都有推出自己的NPU内核。那么ARM的“通用型”的Ethos NPU IP真的有市场吗?
对此,ARM市场营销副总裁Ian Smythe表示,ARM的Ethos NPU IP并不是孤立存在的,其主要的优势在于,在其本身提供出色的AI性能的同时,可以更好与ARM的CPU、GPU进行协同,以实现异构的AI计算,从而进一步提升整个系统层级的AI性能、降低功耗。而且,目前AI市场还是在初期,很多的AI算法仍在快速迭代,选择“通用型”的NPU是比较安全的做法。

在采访当中,Ian Smythe向芯智讯确认,ARM的Ethos NPU IP也可被集成于比如RISC-V等其他架构的SoC当中,但是Ian Smythe也强调,这样并不能发挥出Ethos NPU与其它非ARM CPU/GPU在AI计算上的协同优势。
另外,ARM的Ethos NPU IP还实现了对于高中低阶的全面覆盖,但是目前众多的芯片厂商主要还是在其高端SoC当中集成了NPU,而随着AI计算向边缘侧部署的趋势,未来市场对于NPU的需求也将会越来越大。Ethos NPU IP的推出,将可帮助芯片设计厂商更简单、更低成本的获得不同档位的NPU内核的支持。
另一方面,目前的Android应用生态基本都是基于ARM架构的处理器,因此,如果采用ARM的Ethos NPU IP,结合开源的ARM NN框架,应用开发者将可以更简单、高效的调用ARM的CPU/GPU/NPU内核,可以为用户带来更为出色的AI体验。而且,可以实现一次开发,即可获得ARM全系列的内核的支持(这也意味着,可支持众多基于ARM不同类型的内核的SoC),无需再重新编译。而对于其他的芯片厂商的NPU来说,开发者要想实现灵活高效的调用NPU,充分发挥其AI性能,则需要针对性的进行优化,而且还需要其提供相应的权限和工具。即便是开发者开发应用实现对于A厂商的NPU调用,同样的应用要想实现对于B厂商NPU的调用,可能需要重新进行编译。显然,对于应用开发者来说,ARM的NPU所具备的生态优势无疑是其他厂商所无法比拟的。
最后,Ian Smythe强调,ARM对于AI性能的提升是多维度的,一方面会持续推出更高性能的NPU IP,同时也在不断提升ARM CPU/GPU的AI性能。

值得一提的是,Ian Smythe在演讲当中透露,ARM在下下一代的大核架构Matterhorn当中,加入Matrix Multiple(MatMul),令其ML(机器学习)性能与前代CPU相比提升一倍。
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...