正文内容 评论(0)

早在2007年基于K10架构的65nm第一代Phenom发布之时,就已经传出AMD将要于2009年推出Bulldozer推土机的消息了,而当时的主要规划就是为了对付Intel 45nm全新架构的Nehalem处理器。和APU一样,AMD早已画好了一个“大饼”,可是这个“大饼”确实“熟”的慢了些。
说来也有些讽刺,如今四年已经过去了,Intel已经完成了从45nm到32nm两次工艺革新、Core到Nehlaem再到Sandy Bridge三代核心架构换代,而AMD方面却只从65nm升级到45nm、而且一直维持在K10架构(09年进工艺升级,架构方面也进行了优化,也就是一直沿用到现在的K10.5),并没有本质上的变化。除了各种小道消息之外,全新架构的Bulldozer推土机至今难觅踪影。
大家都在说推土机跳票、延期,但事实上AMD官方一直都未亲口确认正式发布日期,只是提及了部分处理器型号以及架构细节云云,各种所谓的“确切消息”也只是谣传罢了。虽然表面上我们并不能苛责AMD,但如此的难产让众多A饭们早已等得望眼欲穿。而在对手新一代旗舰Sandy Bridge-E以及22nm Ivy Bridge已现雏形的情况下,AMD的心情恐怕也是一样。
提到推土机的难产,其中的原因是复杂的,而且是多方面的。全新设计思路的转变、支持指令集的扩充、“模块化”架构的变革、GlobalFoundries新工艺的成熟等等都可能带影响。不过恰恰正是这些创新和改变才造就了推土机的的不平凡。尤其是在AMD处理器架构数年都未补充新鲜血液的情况下,推土机的成功与否就显得尤为重要,意义重大而且让人充满期待。

推土机终于来了!
不过好消息是,让千万人翘首企盼的推土机来了,可谓箭在弦上,只待发布!今天中午12点,推土机将正式和广大玩家见面。前几日,就有许多国外媒体已经拿到了正式版推土机,而目前国内相关的评测套装以及配套软件也已由AMD中国官方寄出,很快就会到达各大媒体的手中,相信无需多时就能看到详细的评论以及测试结果了。届时,之前的一切传言都会得到验证,而大家最关心的“推土机”能否推倒“爱妻”的好戏也会激情上演。
在评测结果正式出炉之前,我们要做的只是静静等待。除此之外,号称K8架构以来AMD处理器最大变革的推土机究竟带来哪些架构和技术上的转变呢?相信也是不少读者关心的。下面我们就根据已知的信息对其进行汇总,在面对最终结果的时候我们也能知其然,知其所以然。
Update:目前,我们驱动之家评测室已经拿到了推土机FX-8150的实物以及配套水冷,将会第一时间奉上测试结果,敬请期待!
设计理念之变:多核心下的多线程X86架构处理器诞生之后的很长一段时间内,包括AMD和Intel在内的厂商在提升CPU性能方面的思路都大同小异,无非是改进核心架构、提升处理器频率、优化和扩充指令集、加大二级缓存等等。而到了双核乃至多核CPU出现之后,AMD和Intel的处理器走向了截然不同的两种道路:增加物理核心数量和虚拟同步多线程。
首先说一下SMT(Simultaneous Multithreading,同步多线程),放在以前就是我们常说的HT(Hyper-Threading,超线程)技术。虽然这项技术在服务器领域早已应用多年,但在桌面处理器实现还要追溯到Intel的P4时代。但是出现之初并没有在P4处理其上大放异彩,而后的Core 2时代甚至遭到取消,直到上代的Nehalem架构才重新复活,重新命名为SMT,一直延续到最新的Sandy Bridge架构。不过P4时代的HT超线程和目前的SMT多线程在提升效果上已不可同日而语。
我们知道,传统CPU一个物理核心只能同步执行一个线程,所以大多数情况下都会处在等待内存以及数据总线的状态,而SMT可以使一个物理核心“同时”执行两个线程,看起来就像两颗“核心”一样。当第一个线程暂停时,将第二个资源准备充分的线程安排给核心处理,达到运算资源利用最大化。从设计原理上来看,SMT的目的也很简单,就是掩盖单个线程的延迟,以充分利用核心运算资源,以防运算单元浪费。

Intel的Nehalem架构处理器重拾超线程
SMT从成本方面来看相当廉价,因为它采用的是复制内核架构的方法来实现,增加了处理器中存储线程有关数据的单元数量,并在硬件执行单元空闲时将这些数据送往其中处理,以便增加处理器执行单元的利用度,而内部并没有增设一套额外的硬件执行单元。这样不需要增加物理核心,也耗费不了太多的晶体管和核心面积,所以比再另外增加一个物理内核更加划算。而且在操作系统中呈现出来和实实在在的物理核心并没有什么区别,所以我们经常见到四核八线程CPU在资源管理器中有八个“核心”在同时工作。
虽然SMT看起来很好,但也不是完美的。毕竟,无论如何充分利用运算资源,一颗核心始终都不可能达到两颗核心的效果。所以SMT的效率要根据实际的应用环境来定,比如遇到内存和缓存需要长时间等待的境况下,SMT就能发挥很好的作用;反之,甚至并不如一颗纯物理核心的执行效率。按照Intel之前公布的数据来看,SMT大约能带来20-30%的性能提升,换句话说也就等效于1.2-1.3个物理核心的效果。
相比之下,AMD之前的办法更加简单暴力,那就是CMP(Chip MultiProcessors,增加核心数量)。从理论上来看,直接增加物理核心的方式对CPU的性能帮助比较明显,也更加直接,尤其是在多线程应用环境下。
Phenom II X6 1100T就有六个物理内核
但这种方式也有很大的代价和瓶颈,毕竟每增加一颗物理核心就需要耗费更多的晶体管与核心面积,功耗也会随之水涨船高,而且核心数量增加到一定程度之后性能提升并不一定与之成比例,很容易受到制造工艺的限制。目前的软件以及游戏对多核心优化程度有限,很多实际应用环境只能利用其中的部分核心,而多余的核心只处在低负载状态,实际上也就被浪费了。
由于没有相关的多线程技术,单核性能也处于劣势,AMD只能靠物理多核心来对抗Intel的SMT多线程,反映到市场策略上来看就是,在价格相差不多的情况,AMD的四核/三核打Intel的双核,而六核打Intel的四核。虽然表面上AMD还能依靠这种“田忌赛马”的策略占据不小份额,但我们似乎也从其中感觉到丝丝无奈。

既非SMT,也非CMP,推土机采用了另一种设计思路。
不过好在推土机就要来了,虽然我们不期望它能一招制胜,但至少可以大大提升AMD的市场竞争力。工欲善其事必先利其器,推土机又依靠什么呢?相比之前的K10架构处理器,推土机在多线程、核心架构、指令支持、运算单元、数据总线等诸多方面都进行了革新,而其中以提高CPU的多核心下的多线程能力为主要设计目标,可见推土机既非照搬Intel的SMT也非自家传统的CMP,而是另辟蹊径,寻求新的设计思路。
事实上,在去年的年度高性能处理器研讨会Hot-Chips 22上,AMD就着重提到了推土机的多线程处理能力,而今年的Hot-Chips 23中,就此方面AMD更是不吝言辞,宣传较多。可见,多线程技术是推土机设计理念转变的重中之重。而这种多线程,AMD 称之为CMT(Cluster-Based Multi-Threading,簇式多线程)。如何实现CMT呢?就是我们下面要谈到的推土机模块化设计。
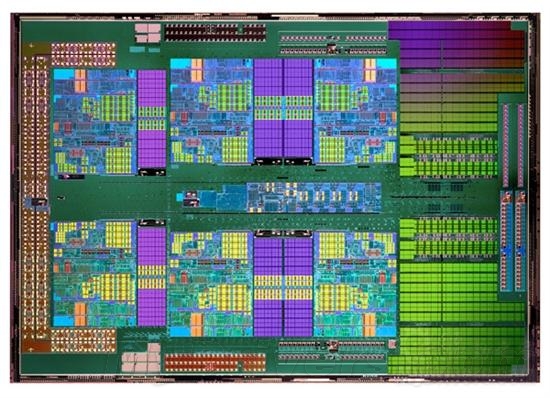
核心架构之变:一个模块两个内核在上一节的介绍中,我们了解了SMT和CMP都有各自的优缺点:SMT成本虽低,但执行效率并不如增加物理内核;CMP虽然效果不错,但很容易受到制造工艺和功耗的制约。为了最大化的提升处理器多核心多线程的性能,推土机改变了以上两种传统的设计思路,将两颗物理合理组成一颗核心,AMD称之为一个“模块”,也就是所谓的“模块化”设计。
按照AMD的说法,推土机之所以会采用这种设计思路主要是为了减少处理器多核心下的冗余电路,同时获得多线程的效能提升。确实如此,如果依然采取传统的CMP方式,随着CPU的物理内核数目越来越多,核心面积也会越来越大,功耗也随之升高,而且会造成大量重复性冗余的电路。
而减少冗余电路的最好方法就是整合,把两颗核心整合在一起。对于整数单元、一级数据缓存等等分别单独划分,而对于浮点单元、二级缓存则由两个核心共享完成。AMD表示,这种做法能够让每个核心在需要的时候完成更多功能、发挥更高性能,同时节省核心面积,比每个核心都单独割裂开来效率更高。
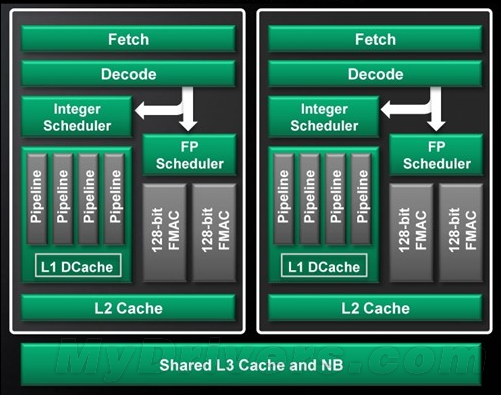
传统的物理核心
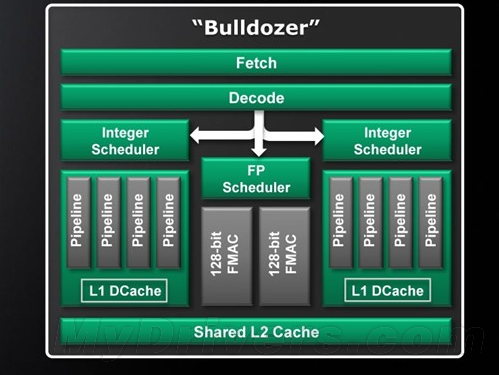
推土机的模块化核心
由上图不难看出,推土机的模块化核心不再按照传统的整数单元+浮点单元构建,而是每个模块中拥有两个整数单元(Integer Unit)和一个高度共享的弹性浮点单元(Flex Floating Point),而每个整数单元都配备了一个单独的调度器,所以可以在同一时刻同步执行两个线程,从而每个模块都能实现CMT。
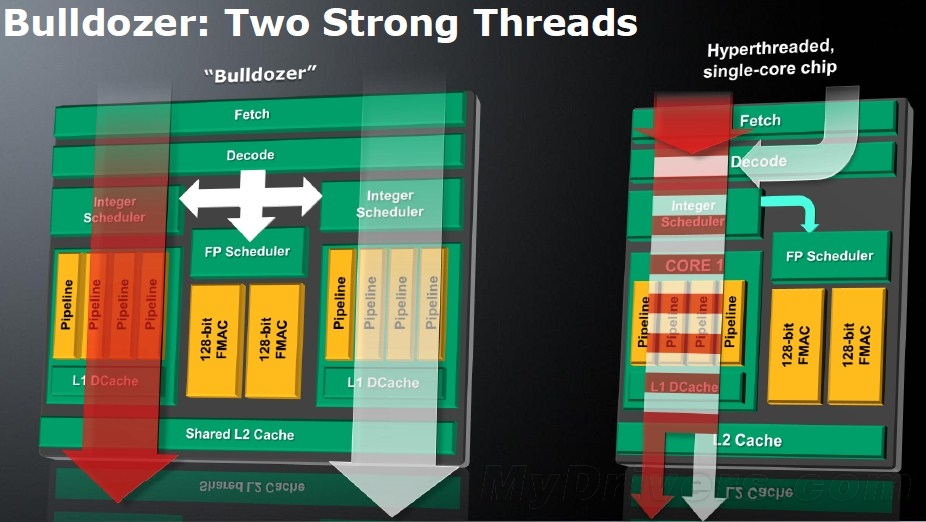
模块化设计使得推土机实现了CMT
事实上,CMT很像是CMP和SMT融合后的产物,虽然这么说并不太准确,不过道理确实如此。那么CMT相对CMP以及SMT又有何改进呢?相比CMP的优势前面已经说过了,能够大大减少冗余电路,降低功耗以及缩小核心面积。而在执行过程中,两个线程都有单独的整数执行单元是相对SMT最大的优势,毕竟实实在在的硬件计算效率还是要大大高于资源切换的。
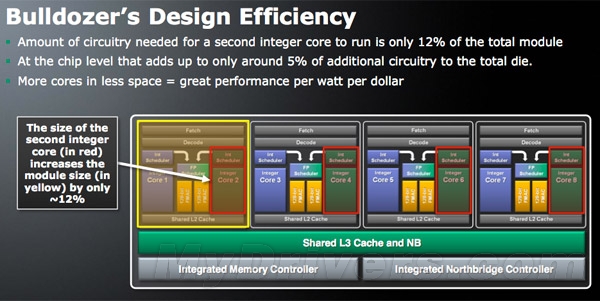
增加的整数单元所需要的电路只占总核心面积的12%,从芯片级别上讲这只会给整个内核增加5%的电路,却可以换来80%左右的整数运算性能提升。当然,CMT同样不可能做到真正的物理双核心,AMD表示平均计算下,一个单独的“推土机”核心执行两个线程可以达到1.8个物理核心的整数运算效率,也就是有80%左右的整数运算性能提升。所以综合来看,CMT综合了CMP和SMT的优点,也是推土机全新设计思路的精髓所在。
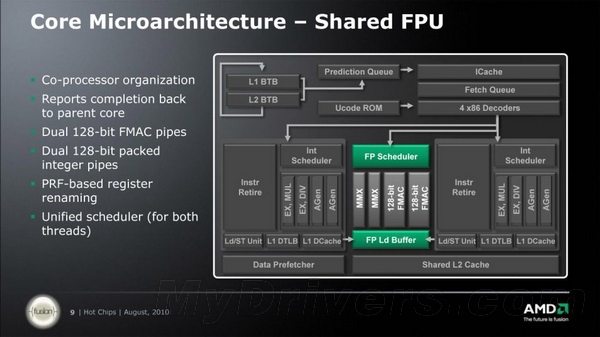
高度共享的弹性浮点单元由两个128-bit FMAC单元组成
整数运算性能提升了,那浮点运算呢?虽然在大多数情况下浮点运算占据的比例不高,仅有20%左右,而且未来也可能更多会交给擅长浮点运算的GPU去处理。上面我们也看到了一个模块内的两个内核共享一个浮点运算单元,那会不会造成推土机浮点运算性能的下降呢?对此,AMD给出的方案是增强共享浮点单元的弹性,运算指令灵活多变,以应对不同的应用情景。比如,如果指令是256-bit的,那么两个FAMC单元可以合并为一个256-bit浮点单元进行计算;如果指令不是256-bit的而是128-bit的,那么FAMC单元可以同时执行两个同样的FADD或FMUL指令,拆分即可。
按照AMD的说法,虽然推土机内部的一个模块仅有一个浮点单元而且还要共享,但这个浮点单元拥有独立的调度器,无需依赖整数调度器来分配指令,也就无需占用整数单元的资源来排定256-bit的执行方式。每个模块中的浮点单元都由两个128-bit FMAC(Fused Multiply-accumulate,混合累积乘)单元构成,这个浮点单元通用性很强,每周期可以执行任意一个FAMC(Floating-Point Multiply-Accumulators,浮点累积乘)、FADD(Floationg Point Addition,浮点加)或者FMUL(Floationg Point Multiplication,浮点乘)计算,相比之下Intel的浮点单元功能就比较单一,FADD和FMUL计算则需要专用的FADD及FMUL管线。
所以,理论上来说,共享的浮点单元并不会对推土机的浮点运算性能造成影响,相反还灵活多变而且通用性很高,不仅减小了核心面积而且能够一定程度上降低功耗。
支持指令之变:SSE5和AVX的交融除了核心架构之外,CPU的性能高低还很大程度上取决于支持的指令集。所以,以往每逢重大CPU产品发布,总会伴随着相应的指令集优化和扩充。这一次,推土机也不例外。除了SSE5,还有AVX。

X86架构处理器指令集演变
我们知道,在X86架构处理器中,SSE(Streaming SIMD Extensions,流式单指令多数据扩展)自诞生以来就占据了绝对的主导地位。不过,在此之前,每一次新版本的SSE指令集发布都似乎和AMD没有关系,无论是SSE、SEE2、SEE3还是后来的SSE4(4 .1/4.2)都是Intel率先发布的,AMD虽然有对应功能的指令集但名称均有所不同。

2007年8月30日,AMD突然宣布了下一代基于x86架构的扩展指令集,抢先发布“SSE5”,并计划配备在K10之后的下一代“Bulldozer”核心架构中,旨在先前SSE指令集的一些缺陷和不足,并充分发挥多核心、多媒体的并行优势。SSE5同样是128-bit指令集,一共有170条指令,其中基础指令64条,新增的最重要的有两条:
首先是“三操作数指令”(3-Operand Instructions)。x86指令以往只能处理双操作数,而SSE5会提高到三操作数,达到RISC架构的水平,从而把多个简单的指令集整合到更高效的一个单独指令中,提高执行效率。
然后是“熔合乘法累积”(Fused Multiply Accumulate,FMACxx)。该技术可以把乘法和其他算法结合起来,保证之用一条指令就能完成迭代运算,从而简化代码、提高效率,适用于真实图形着色、快速照相渲染、空间化音频、复向量(矢量)数学等场合。
除此之外还有整数乘法累积指令(IMAC,IMADC)、置换与条件移动指令、向量比较与测试指令、精度控制舍入与变换指令等等。
也就是说,AMD当时就已经为推土机的指令集扩展做好了准备,可是事情并没有那么简单。

Intel宣布AVX指令集规范
既然AMD抢先一步,Intel索性弃用了SSE的名称,于2008年4月份公布了AVX(Advanced Vector Extensions,高级矢量扩展)指令集规范,随后开始不断进行更新。AVX指令集提升到256-bit,理论性能可比当前128位CPU提高一倍。在AVX指令集中,同样包含了SSE5指令集的多项新特性,包括3操作数指令/4操作数指令支持,乘加指令以及部分置换指令等,但实现形式与SSE5不同。并且,AVX指令集还加入了一些SSE5中没有的新特性:SIMD浮点指令长度加倍,为旧版SSE指令增加3操作数指令支持,为未来的指令扩展预留大量OpCode空间等。由于新特性众多,再加上intel的强势,众多软件厂商都纷纷宣布支持AVX规范。
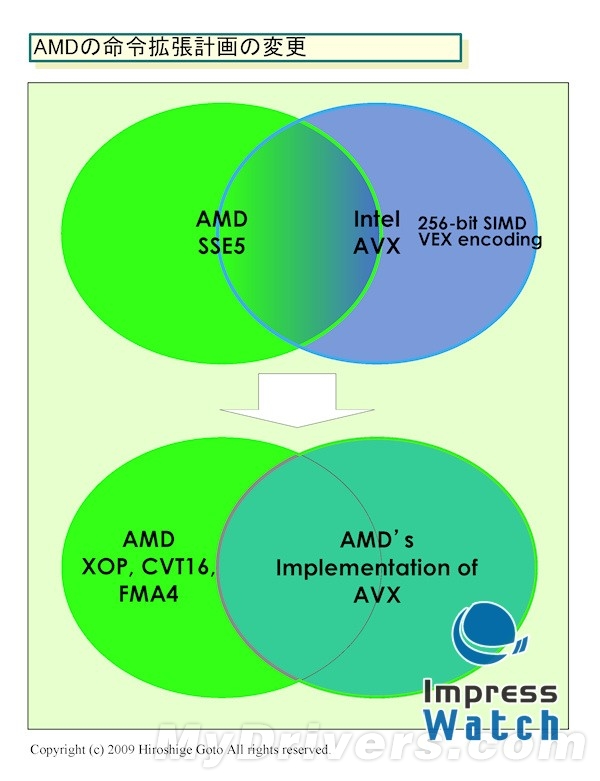
SSE5和AVX的交融
SSE5没有相关硬件支持(推土机当时还在娘胎之中),也未能获得软件厂商的青睐,AMD也与2009年5月份正式宣布支持AVX指令集规范。当然,SSE5中的众多特色指令并未摒弃,而是利用AVX规范重写,重新定义为XOP(eXtended Operations指令扩展),CVT16(半精度浮点转换)以及FMA4(4操作数乘加)。
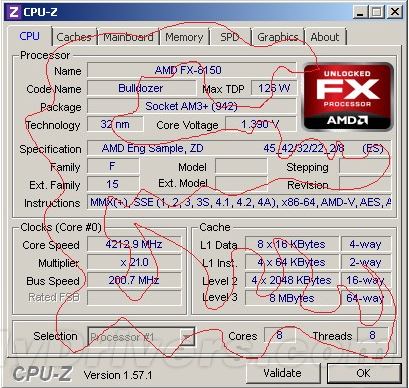
曝光推土机FX-8150 CPU-Z截图,可以看到支持的指令集相当多。
所以简单来说,推土机所支持的指令会相当丰富,即保留了SSE5原有的部分优秀指令集,也对Intel的AVX指令集完全兼容。不过,由于AVX指令集的制定权在Intel手中,未来还可能进行修改。
数据总线之变:更高速的HT3.1相比全新的模块化设计理念,CMT簇式多线程,推土机的HT总线和内存控制器方面的改变就没有那么彻底了,算是对传统设计的继承和发扬,内部规格相应升级,本质上并没有发生改变。总体来说,推土机将HT总线提升至3.1规范,将这种点对点、低延迟总线技术的速度提升到了3.2GHz,而桌面版本内存控制器支持到双通道DDR3 1866MHz规格。
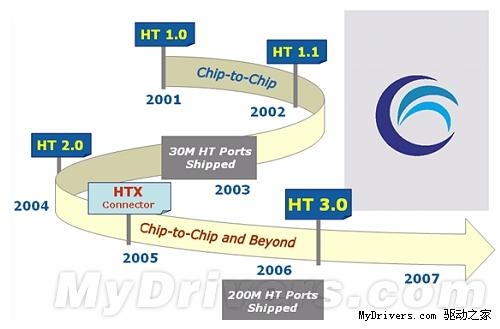
HT总线发展简史
HT总线是AMD研发的一种高速点对点单双工数据总线,主要用于芯片级的数据传输,包括CPU与CPU、CPU与芯片组、芯片组南桥与北桥等。HT总线支持2、4、8、16和32bit等五种通道模式,并采用了DDR双倍数据传。
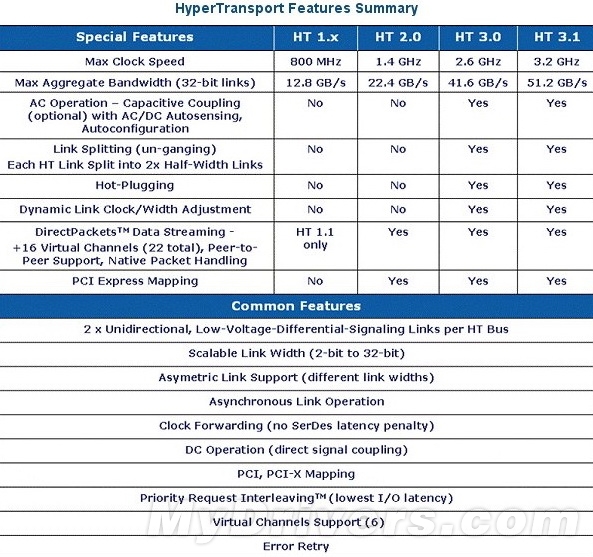
HT总线规格表
目前HT 3.0的速度最高只有2.6GHz,比如AMD的旗舰四核心处理器Phenom X4 9950 BE就是这一速度。在提速至3.2GHz后,再结合双倍数据率,HT 3.1可提供最高每位6.4GT/s的数据传输率,32-bit带宽可达51.2GB/s,相比上一代HT总线有利很大提升。
虽然内存依然只能支持到双通道,但据官方却透露相比之前有的一定的性能提升。在K10架构中,ALU和AGU共享三个管线(平均1.5个),“推土机”中每个核心整数单元管线的数量增加为4个,2个AGU使用、2个ALU使用,每周期可以执行四个内存操作,可以降低本地以及远程访问内存的时间。另外,内存频率由DDR3 1333MHz升级到1866MHz,带宽的提升还是相当明显的。
智能加速之变:第二代Turbo Core虽然多核心已经逐步成为主流,但很多时候并不是所有的CPU核心都能被同时用到,有不在少数的程序和系统应用并不支持多核心或仅支持CPU中的部分核心运行,所以单核单线程的性能依然是目前CPU一个非常重要的参数,而对于如何能够在多核心的情况下提高部分核心的性能,Intel和AMD给出了各自的答案:Turbo Boost(睿频加速)和Turbo Core(智能加速)。
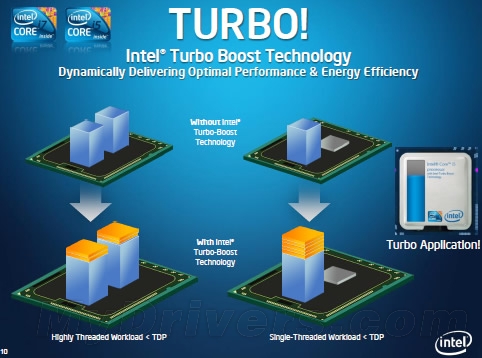
Turbo Boost睿频加速技术
在Nehalem架构处理器出现之时,Intel就引入了Turbo Boost核心/频率动态调节技术,可根据实际负载调整每个处理器核心的电压、频率,兼顾高频率和多线程应用。这一技术源于Core 2时代的IDA(Intel Dynamic Acceleration Technology,Intel动态加速技术),只不过当时的IDA只能休眠CPU中一个核心从而提升另一个核心的频率,而Turbo Boost则可以实现多个核心的动态加速,进而提高单核单线程的性能。
不过,Turbo Boost也有要求,那就是前提不能超过CPU的TDP。在支持Turbo Boost的处理器中,每个核心都带有自己的PLL (Phase Locked Loop,相位锁定回路)电路,每个核心的时钟频率都是独立的,而且每个处理核心都是有自己单独的核心电压,这样的好处是在深度睡眠的时候,个别的处理核心几乎可以完全被关闭。为此,Nehalem架构处理器中特备设计了PCU(Power Control Unit,功耗控制单元),可以监控操作系统的性能,并且向其发出命令请求。
当CPU的应用负载提高时,系统可以在TDP的允许范围内对核心主频进行超频: 如果4个CPU内核中有部分核心检测到负荷不高,那么其功耗将会被切断,也就是将相关核心的工作电压设置为0,而节省下来的电力就会被处理器中的PCU用来提升高负荷内核的电压,从而提升核心频率最终提升性能。
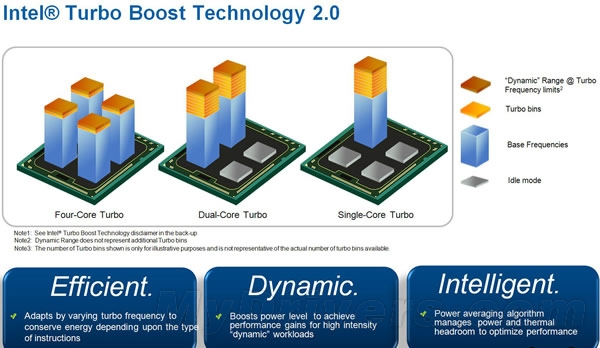
Turbo Boost 2.0
而随着新一代Sandy Bridge架构的发布,Turbo Boost也发展到第二代:Turbo Boost 2.0。Turbo Boost 2.0改进了算法,动态提速单行更高,而CPU的GPU也被纳入了加速范围。相比第一代,Turbo Boost 2.0最大变化就在于可以短时间内突破CPU的TDP上限了(不过依然受限于环境温度),可以进一步提升加速效能。当然,令人不爽的是Turbo Boost仅在Intel的中高端CPU中标配,而更加需要加速提升性能的入门低端产品却都不能享受。

AMD Turbo Core智能加速技术
虽然命名上不同,AMD的Turbo Core却在功能上和Intel的Turbo Boost有着异曲同工之妙。都是利用了处理器在原始频率下的热设计功耗剩余可用空间,在工作负载需要的时候智能地提高全部或者部分核心的速度。不过因为AMD没有电源门控(power gating)技术,所以实现原理和方式有些不同,主要是利用P-State电源管理状态切换。
比如在Phenom II X6 CPU中,正在运行某个对多线程支持不好却需要较高频率的程序,使得CPU中六个核心中的三个或更多核心没有得到使用,那么Turbo Core就会启动,将三个空闲核心的频率由默认频率降为800MHz,而另外的三个核心主频会提升500MHz左右。但是,从最终效果来看,Turbo Core的灵活性并不如Turbo Boost。
首先,空闲核心无法完全关闭,只能切换到低速状态,仍然会有能耗;其次,为了提高其他核心的频率,必须给整个处理器加压,这就会影响功耗而限制了加速幅度;还有就是,加速或者降速只能针对三个(或者两个)核心,而无法单独调节每一个核心。相比之下,Turbo Boost可以将空闲核心降至Core C6接近完全关闭晶体管的状态。

推土机升级到Turbo Core 2.0
所以,在推土机架构处理器上,AMD将Turbo Core技术升级到第二代:Turbo Core 2.0。既然是第二代,改进也是非常值得期待的。首先,Turbo Core 2.0的频率提升空间有了明显提高,也就是所有核开启时,最高能自动超频500MHz,不像Phenom II X6,只有一半核能超500MHz。其次,在只有部分核心满载的情况下,尤其是在运行某些对频率要求比较敏感的程序时,其余低负载核心状态可以达到Core C6(CC6)接近关闭状态,从而使活动核心加速超过500MHz甚至更高。比如,FX-8150的默认频率为3.6GHz,开启加速之后可提升至4.2GHz。最后,也是非常明显的一个改进,那就是Turbo Core 2.0加速只受限于TDP,而不再束缚与CPU温度。所以只要在安全设计范围内,即便是CPU处于较高温度,依然可以保持加速。而且从目前得到的信息来看,不仅是高端的8核,中低端的部分6核甚至4核都能享受到urbo Core 2.0。这一点,AMD显然比Intel更为厚道。
工艺功耗之变:32nm和电源管理除了设计思路、架构转变、性能提升等等,推土机的功耗水平也是非常值得关注的一个方面,尤其是在Intel新一代32nm处理器有着良好功耗表现的情况下,推土机的功耗控制就显得尤为重要。当然,一切都离不开两个方面:制造工艺和电源管理。

GF的32nm新工艺
推土机将会采用GlobalFoundries的32nm新工艺(之前还一直维持在45nm), 除了SOI(Silicon On Insulator,绝缘硅)技术外,HKMG(高K金属门)工艺也将被首次采用。使用HKMG工艺的好处是可以减少栅极的漏电量,降低栅极电容,这也是继续提高制程的关键技术之一。除此之外,11个铜金属层和低K电介质、基于硅锗的拉伸硅、第二代沉浸式光刻等技术也悉数在列,目的就是为了进而使得晶体管的尺寸进一步缩小,减小核心面积,降低整体功耗。
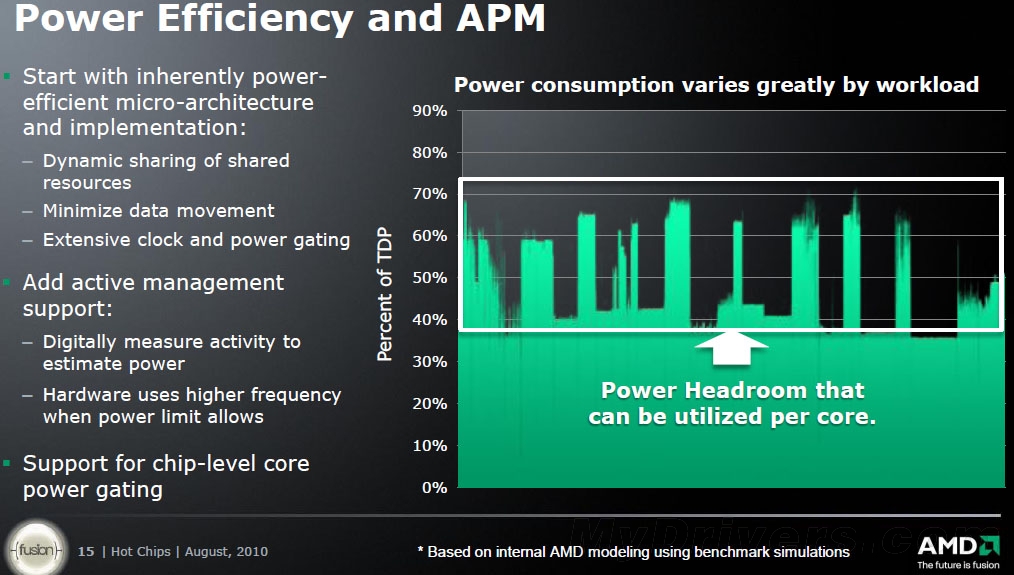
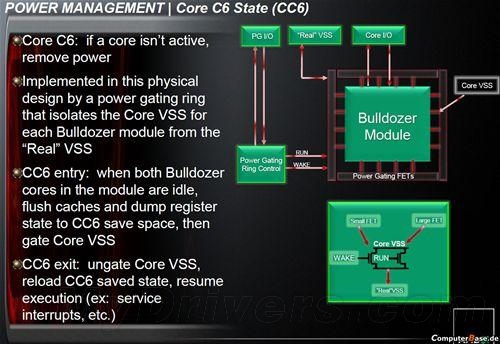
电源管理方面,推土机增加了新的核心状态Core C6(简称CC6),可在某个核心空闲的时候借助功率门控(Power Gating)将其彻底关闭。

当模块内的两个核心全部空闲时,缓存和寄存器状态都转储到CC6保留空间内,然后关掉Core VSS,恢复的时候则重新载入CC6保存的状态,继续执行。
处理器通过核心电源状态(Core P-States)定义多个频率和电压运行点,其中高频率电源状态可以带来更高的性能,但需要更高的电压和功耗;硬件和操作系统会根据核心当前所处的具体电源状态来提供所需的性能,但如果可能的话,会尽量使用更低频率的电源状态,以节省功耗。关于推土机的功耗,目前并没有参考数据,还需实际验证。
总结:一切就绪 只待验证以上章节,我们分别介绍了推土机带来的六大变化:设计思路、核心架构、支持指令、数据总线、智能加速、功耗控制,这六个变化不仅是推土机设计的重点,也是推土机走向成功的关键所在。
首先,设计思路和核心架构的转变可谓AMD自K8架构之后10年中最大的变革之一,在提升CPU性能方面,AMD开辟了除SMT和CMP之外的第三条路,取二者精华去其糟粕,既提升了推土机多线程的执行效率,又很好的控制了成本代价。而支持的指令集除了兼容AVX以外,还保留了SSE5中的优秀特性,势必对今后软件兼容性更加;其次,数据总线提升到HT3.1、内存带宽的扩充以及第二代智能加速Turbo Core 2.0也是推土机的三大看点,很大程度上弥补了以往处理器面对Nehalem以及SNB的劣势。最后,全新的32nm终于使AMD追上了Intel的脚步,改革的电源管理也让推土机在功耗表现方面有了和对手一较高下的资本。

经历了数年磨练,推土机已经相当锋利,也终于将要伴着“轰鸣声”来到我们眼前。我们不期望AMD凭借推土机一己之力搞翻Intel,但至少可以一定程度上扭转目前的颓势。而现在,一切就绪,只待验证!
本文收录在
#快讯
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...