正文内容 评论(0)

NVIDIA内部人士透露,其实Project Denver在距今3年半前已经开始初步谋划,初始目的是为了提高GPU的并行计算性能,以及更好对GPU内部指令进行排列管理,需要更强大的处理器,因此开始初步研究CPU的开发。
不过途中突然生变:微软下一代操作系统Windows 8宣布支持ARM架构处理器,NVIDIA也随之对计划作出改变。本文将从NVIDIA的GPU计算部分开始,对该公司CPU开发部门的情况进行整理。
CPU性能的继续提高遇到瓶颈
2011年7月下旬在东京六本木举行的GTC Workshop Japan 2011大会上,NVIDIA日本分公司的馬路徹做了名为GPU架构和GPU计算入门的演讲,其中说明了GPU计算能力的现状。

NVIDIA日本分公司高级解决方案架构师馬路 徹
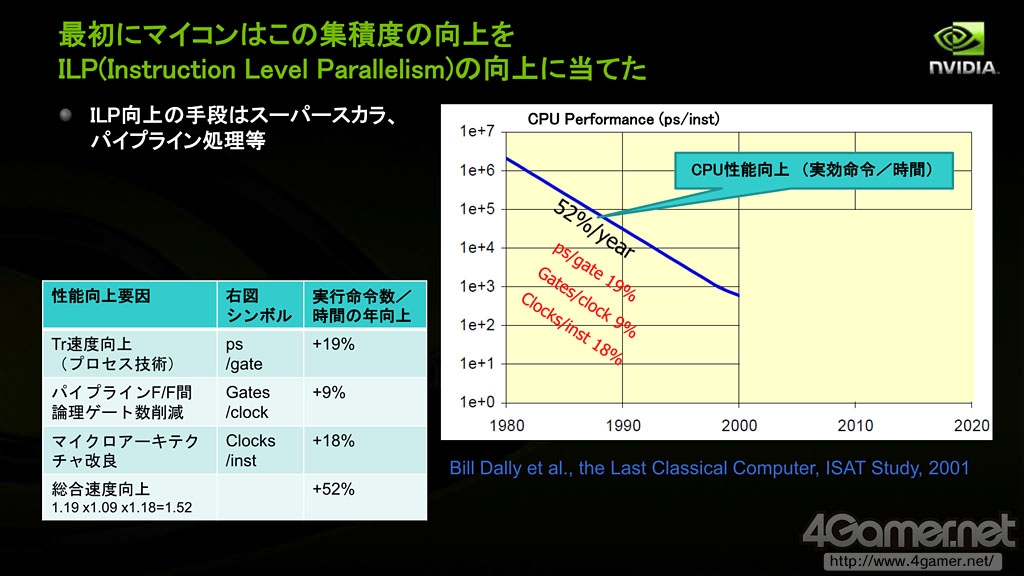
他在演讲中提到:受益于18个月晶体管集成度提高一倍的摩尔定律,CPU的性能在2000年以前顺利提升。2000年之前,平均每年晶体管的速度随着工艺进步提高约19%,Pipeline-F/F(即Flip-Flop,触发器,具有记忆功能短暂保存输入信号的逻辑回路)之间的逻辑门数目每年削减约9%,微架构带来的性能改良每年约18%,总体计算每年CPU提高的性能约(1.19*1.09*1.18-1)*100%=52%
但是在2000年以后,尤其CPU开始受益于多核化的2005年以后,摩尔定律逐渐遇到瓶颈,而和多核处理器并行计算性能有关的阿姆达尔定律(Amdahl's Law)逐渐受到关注。
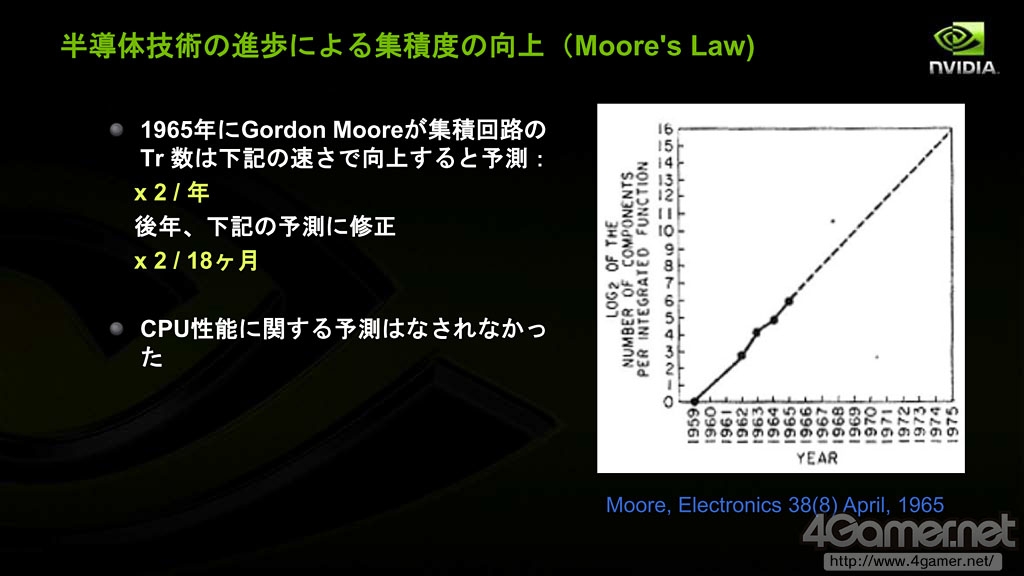
摩尔定律其实不是预测CPU性能提高的规律,而是预测半导体技术提高幅度的规律,主要是晶体管的集成度
2000年前,CPU性能基本按照摩尔定律所预测的幅度逐年提高性能
阿姆达尔定律的准确内容是:固定负载(计算总量不变时),计算机的加速比可用(Ws+Wp)/(Ws+Wp/p)来表示,其中Ws,Wp分别表示问题规模的串行分量(问题中不能并行化的部分)和并行分量,p表示处理器数量。对该式取极限即当处理器数量接近无穷大时,结果为1+Wp/Ws,也就是无论我们如何增大处理器数目,加速比无法高于(据维基百科)。
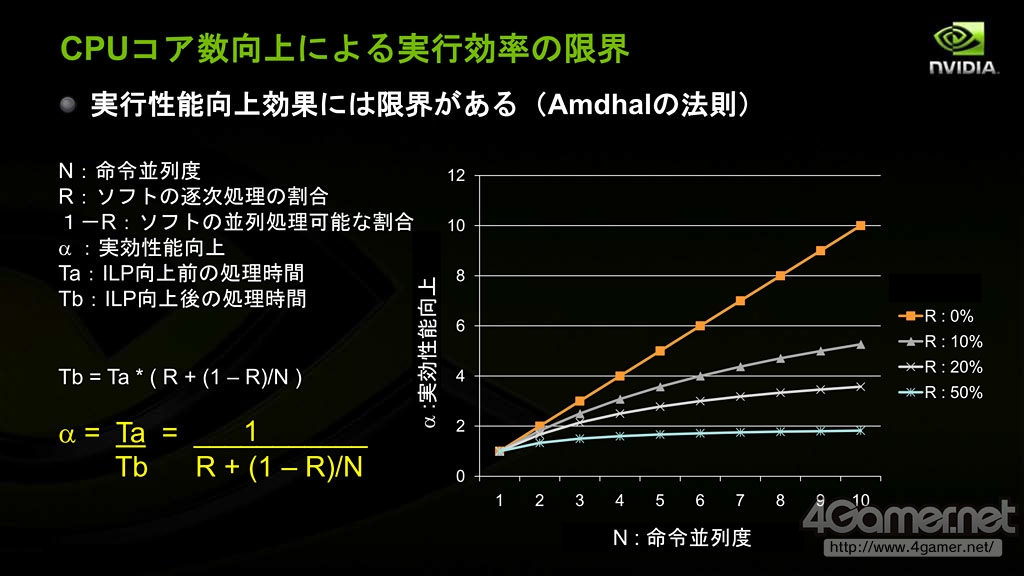
阿姆达尔定律主要描述的是,单纯靠CPU核心数提高改进执行效率是有界限的
根据这一点,馬路徹指出,如果软件应用等不对多核处理作出优化,CPU实际性能提高的幅度将越来越慢,“8核CPU实际性能只有单核的不到4倍,2000年以后CPU性能提升的幅度每年减缓19%”。
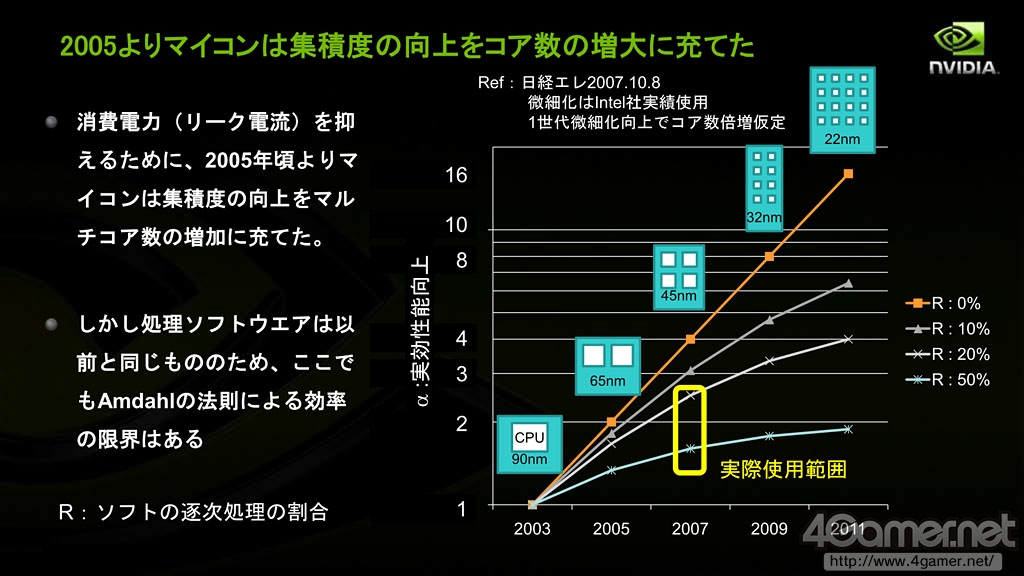
2000年后CPU堆积晶体管的方式转为提高核心数量
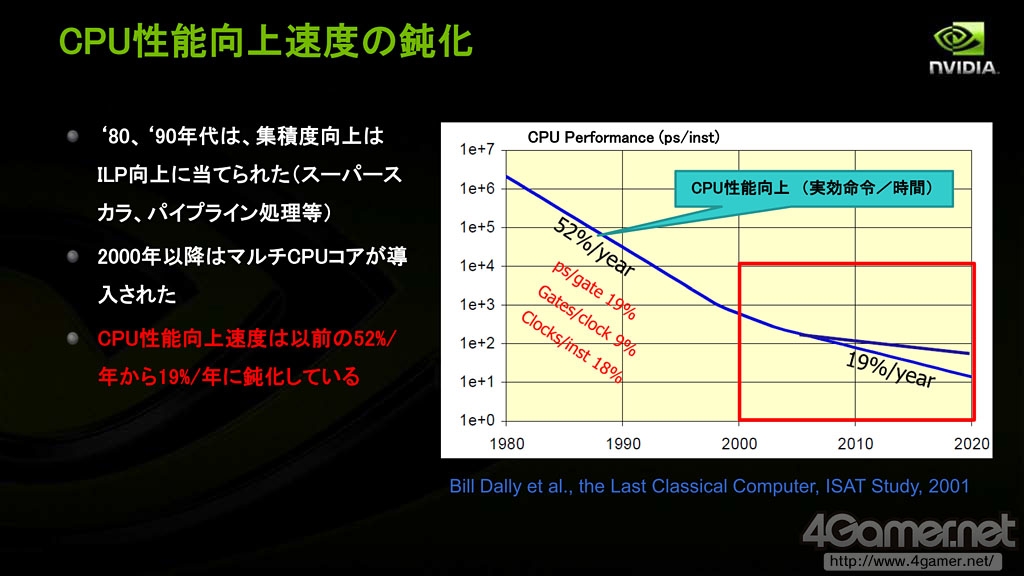
CPU性能提高的速度在逐年放缓
当然,CPU厂商已经预计到阿姆达尔定律所预见的情况出现,将CPU改造成适合并行计算的架构和加入对应的指令集。Intel的MMX,SSD,AVX等强化SIMD计算功能的指令集就是如此;同时Intel还推出了一系列对应多核CPU的开发套件,均为了提高并行计算性能。
不过,这种手段也有界限,最终结果就是,HPC等高性能计算业界纷纷转向原本就拥有适合提高并行计算性能架构的GPU。
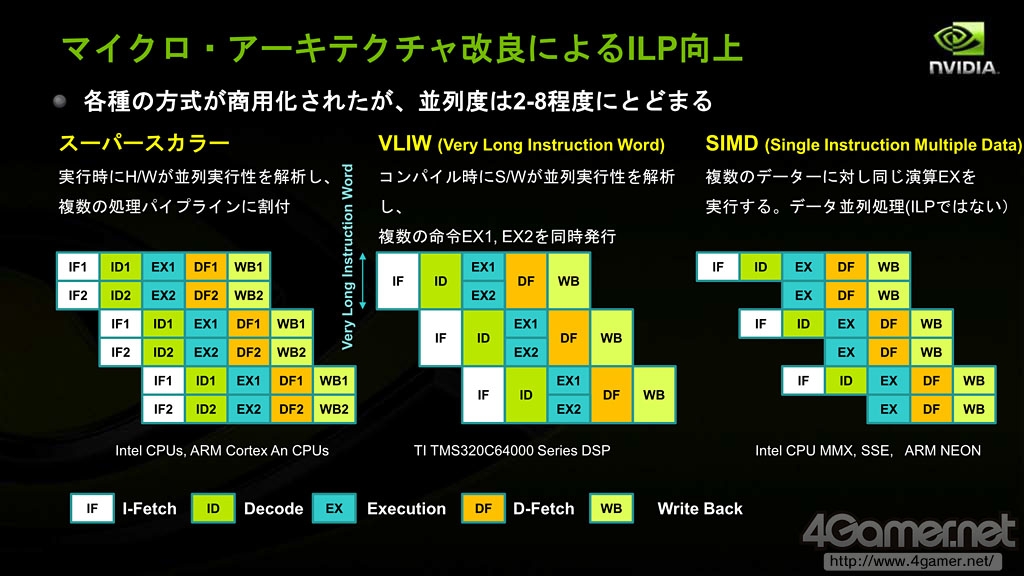
虽然CPU为提高并行计算能力也在逐渐改良微架构,但终究也有界限
馬路徹表示,“由于GPU本身的架构,半导体集成度的增加主要提高的是并行计算性能。即使是现在每年性能提高幅度也有74%左右。”此外,GPU和CPU并行处理性能差也将越拉越大,以浮点运算计,2001年的显示核心浮点性能是当时CPU的30倍,而这一差距在今日已经拉大到1000倍,今后也将继续扩大下去。
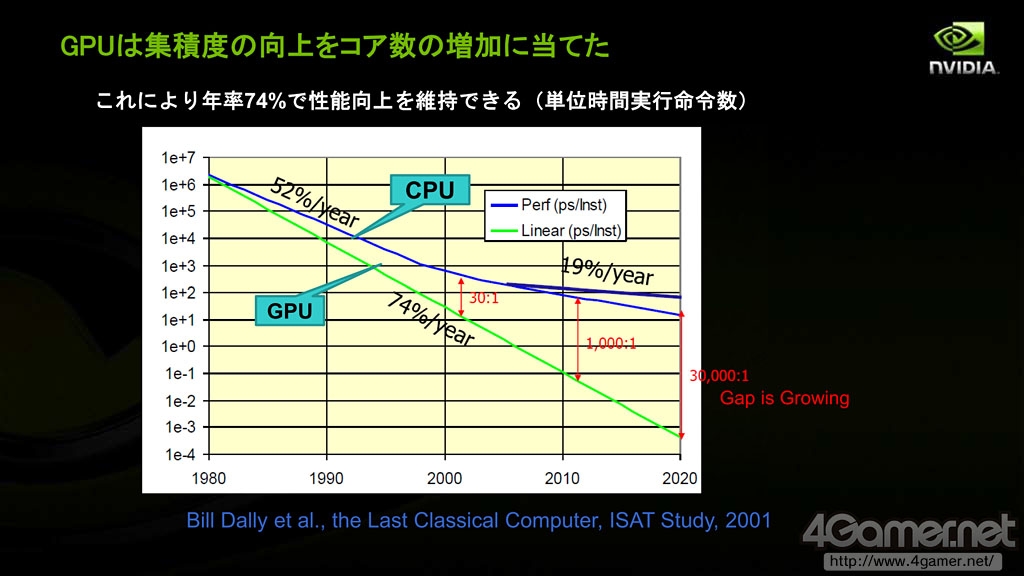
同样依照摩尔定律发展,GPU通用计算能力比CPU提高幅度要大得多
自从NVIDIA支持DX10的统一渲染架构G80核心发布以来,半导体工艺的进步使得GPU内置的核心(流处理器)数量越来越多,GPU基础架构改良速度对比CPU也越来越快。GPU的通用计算能力在这几年来得到很大提高。
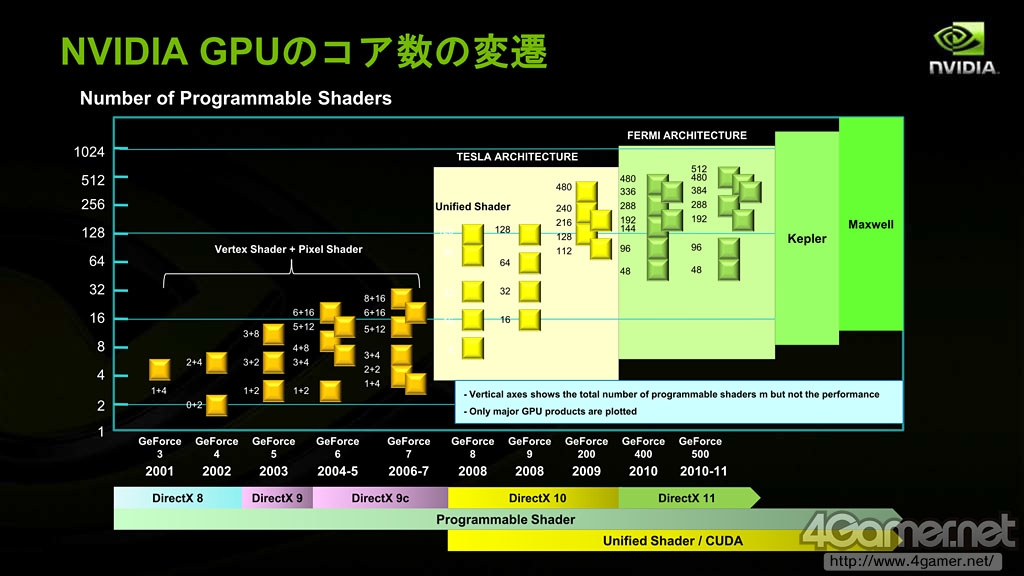
NVIDIA旗下GPU的核心数量变化历史
因为GPU起初是为图形处理设计,对指令集的依存度很低,即使再多线程数量也仍然能保持并行处理性能维持在高水平不变。举例来说,对于3D角色的反射光计算,每个多边形反射光计算中法线处理互不相干,因此多边形数量再多也不会造成瓶颈,GPU的运算能力可以充分发挥。
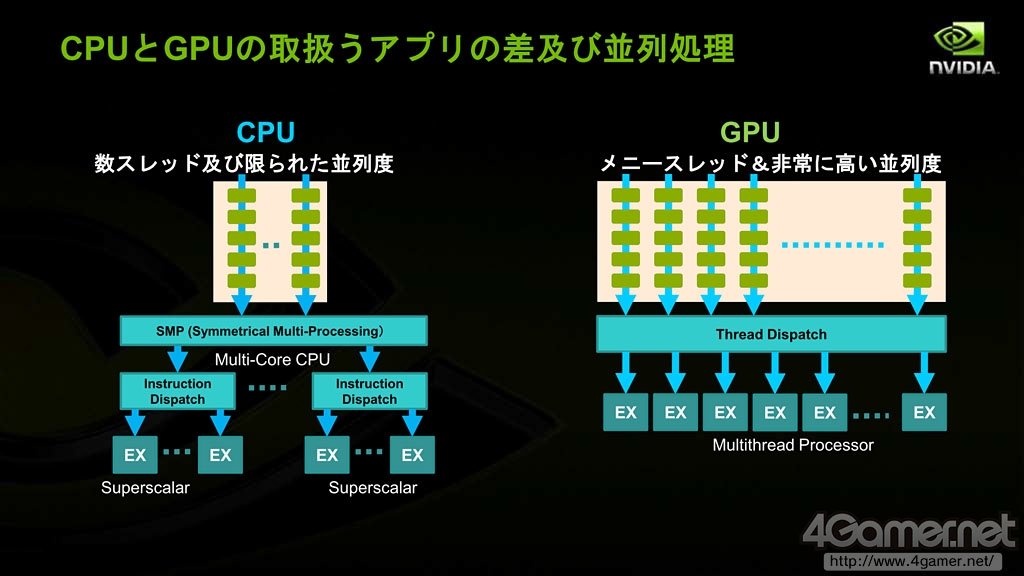
CPU和GPU的并行处理示意图
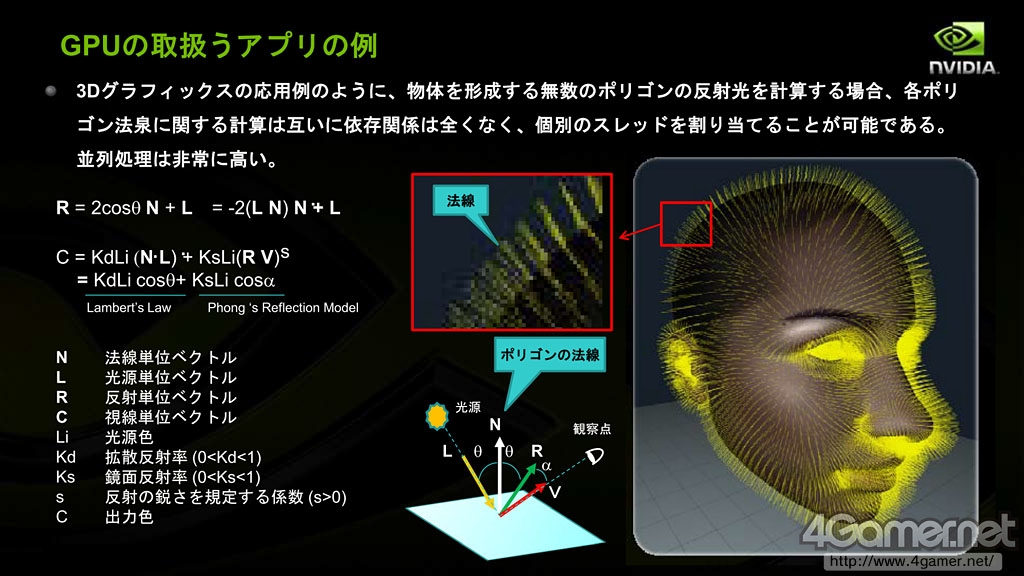
GPU实际并行计算示例:复杂多边形的反射光处理运算
因此,科学运算中最适合利用GPU强大的并行计算能力,馬路徹表示,NVIDIA近年来所力推的Tesla加速卡就是例子,同时取得了很多成果。
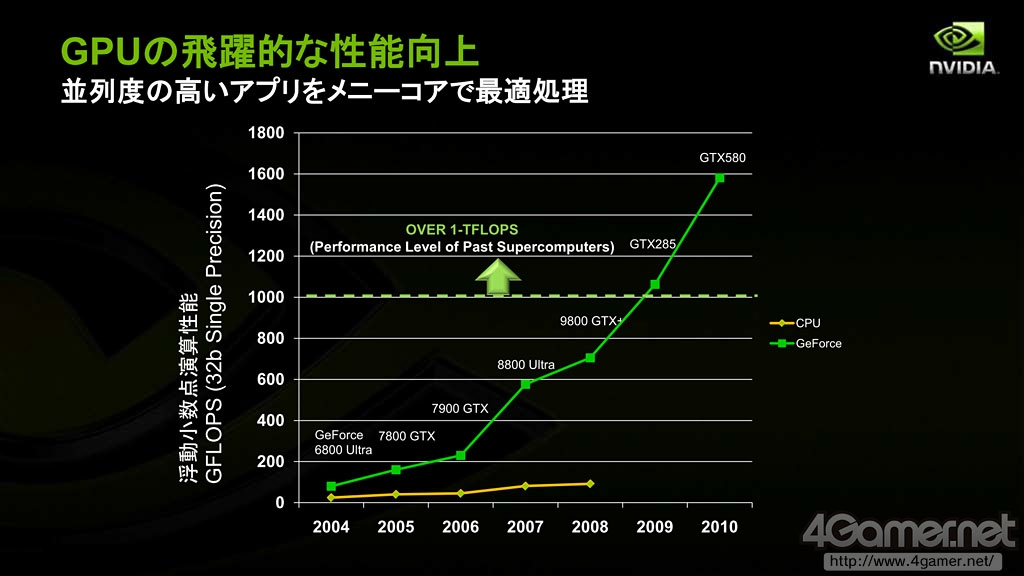
GPU理论浮点运算性能取得了飞跃

GPU并行计算适合多种要求高性能运算的应用
NVIDIA必然开发自家CPU
不过GPU的发展也会受到阿姆达尔定律的影响,当GPU集成的核心数量越来越多时也一定会遇到瓶颈。
解决瓶颈的方法可以是在GPU中加入线程控制机能,用来安排指令优先级和打包指令使其提高执行效率。
NVIDIA在G80架构中首次在芯片和流处理器(SM)级别都加入了线程管理机能"Thread Scheduler",此后随着图形核心的发展,在Fermi架构上Thread Scheduler进化为"Gigathread Engine",使得并行运算性能进一步得到大幅提高。
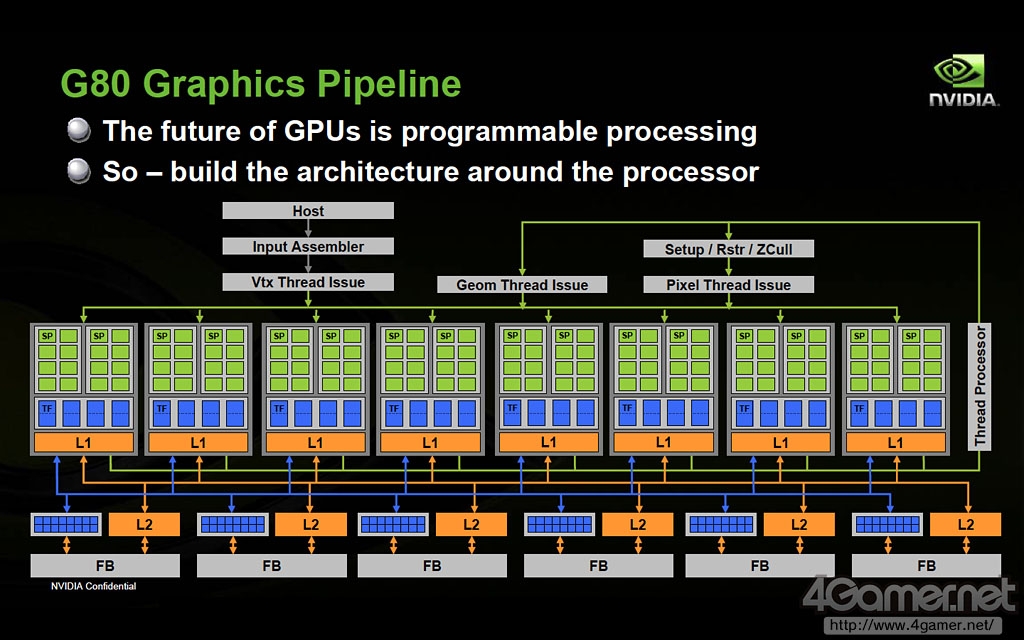
NVIDIA G80核心流水线示意图

NVIDIA GT100(GTX280)核心架构图
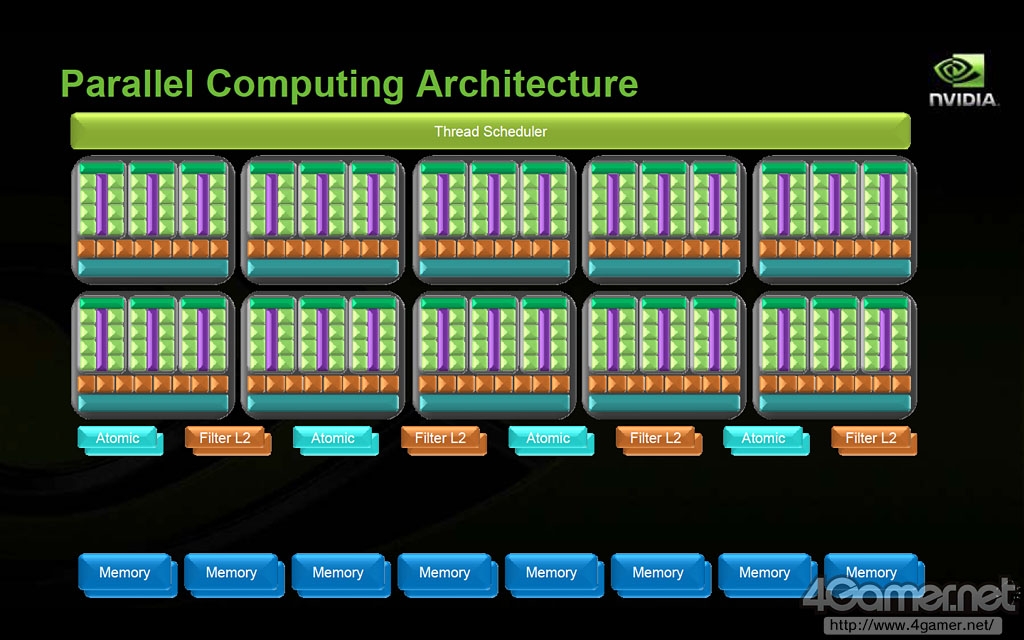
并行计算架构示意图
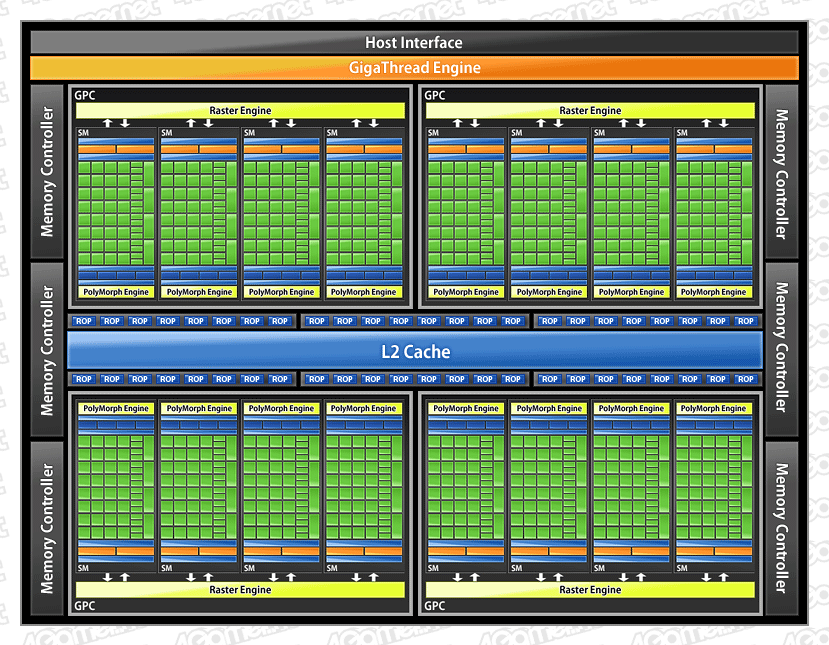
Fermi核心架构图,Thread Scheduler进化为GigaThread Engine
但是,在CUDA Core数量最大已经达到512个的况下,如果再增加势必会给线程管理模块部分带来更高负荷,甚至有发热过高烧毁的危险。因此,为了使GPU的并行计算性能维持优势,需要搭载更加强力的线程控制及管理模块,Project Denver正是为此诞生。
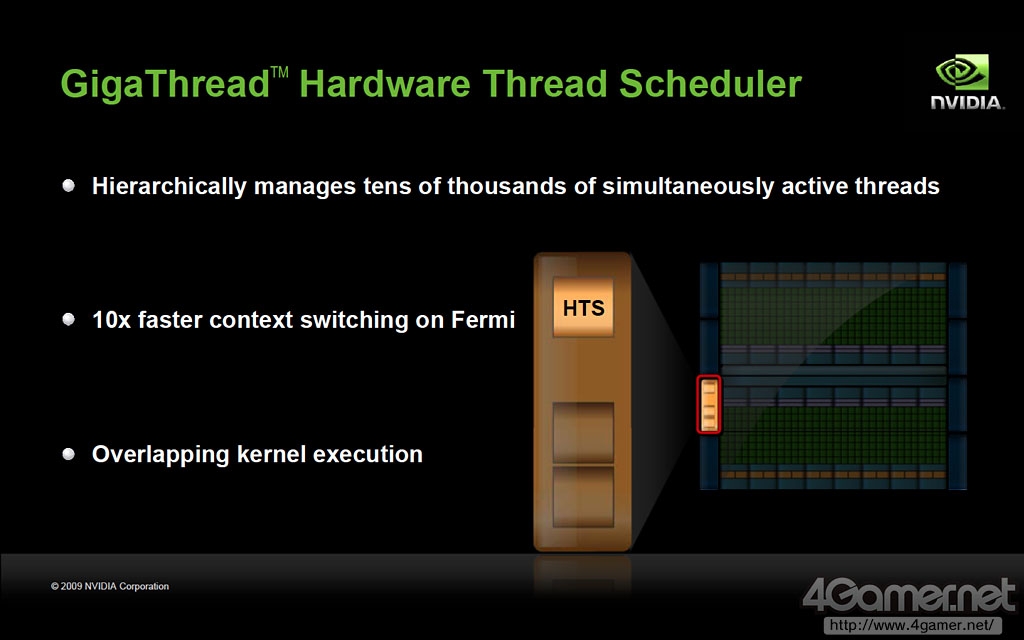
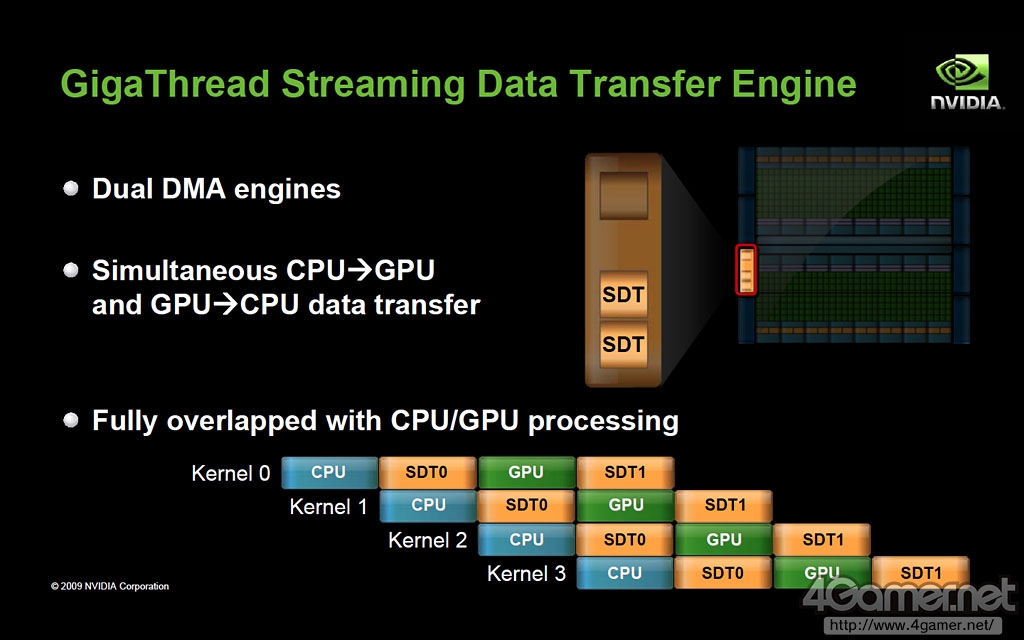
GigaThread Engine介绍,搭载2基硬件级别线程管理DMA引擎
NVIDIA负责产品市场部门的执行副总裁Ujesh Desai确认了Project Denver从三年前就已经开始开发,目标是实现CPU和GPU的统合。

NVIDIA执行副总裁,产品市场部门主管Ujesh Desai
受微软宣布下代操作系统Windows 8将正式支持ARM架构的影响,NVIDIA原本的ARM核心CPU业务范围也将扩大。在3月召开的投资者会议Financial Analyst Day 2011上,NVIDIA总裁兼CEO黄仁勋宣布,Denver的核心将使用未来的Tegra处理器。
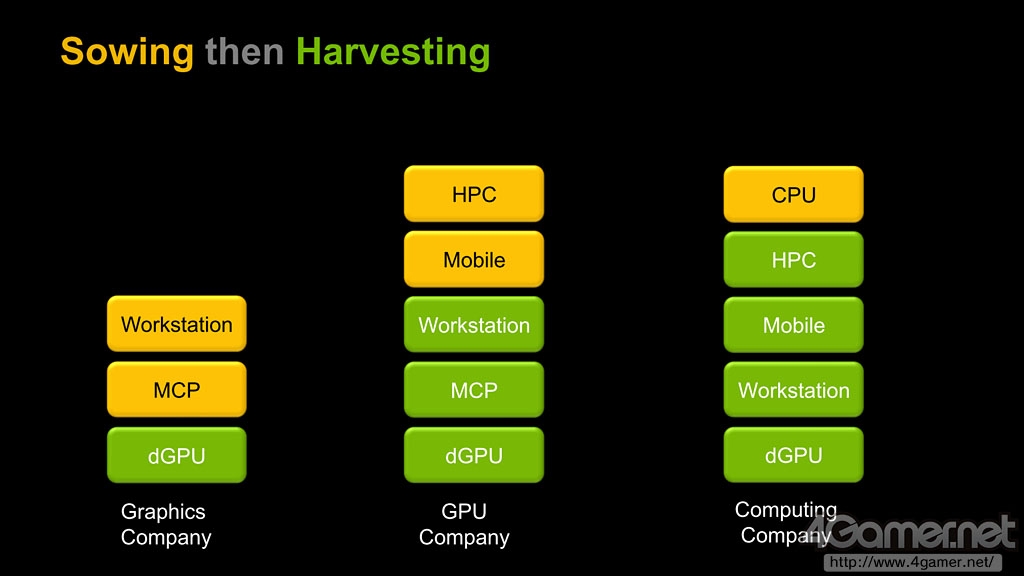
NVIDIA的目标是成为"Computing Company",要实现这一目标CPU业务也是重要的收益来源

2011年5月曝光的Project Denver核心示意图
虽然黄仁勋的说法摆在那里,不过看起来Project Denver和Tegra的关系不是那么简单:NVIDIA移动业务总经理Micheal Rayfield称:“Project Denver和Tegra毫无关系”。他说:“用于移动业务的Tegra最注重目标是省电性能,将不会冒进,沿着ARM提供的Roadmap进行SoC开发。”“Kal-El将是Cortex-A9架构四核处理器,Wayne也自然会沿用下一架构。”表明了Wayne将使用Cortex-A15架构。
同时Desai也从另外一方面验证了上述表态:“Project Denver目标是成为面向HPC(高性能计算)的强力CPU核心,不会像Tegra一样考虑省电。”
Project Denver究竟目的在哪?那么,Project Denver开发的CPU核心究竟是什么样的东西呢?可从2010年11月在美国路易斯安那州新奥尔良市召开的HPC相关技术大会"SC10"上窥见一斑,同时也可从NVIDIA在GTC Workshop Japan 2011上公开的Roadmap中"Echelon"高性能HPC向平台推测出部分内容。

Echelon计划成员实力强劲,包括Cray、美光、洛克希德马丁等著名公司,以及加州大学、斯坦福大学、德州大学奥斯汀分校、佐治亚理工学院、田纳西大学、宾夕法尼亚大学、犹他大学、橡树岭国家实验室等著名科研院校
Echelon计划的来头颇大,主导机关是美国国防部下属的DARPA(国防尖端技术研究开发计划局),目标是在2018年实现ExaScale级别计算能力的超级计算机(UHPC),Echelon的开发受到这一项目的经费资助。DARPA资助经费的规定为,在2014年前完成Phase1阶段的开发,即设计完成硬件部分,同时要报送DARPA审查。
NVIDIA首席科学家Bill Dally在SC10大会上的演讲内容中透露,Echelon为128个SM模块和Project Denver的基础——名为Latency Processor的8个CPU核心所组成,其中每个SM模块含有8个CUDA Core和独立的L0 Cache。据此计算,Echelon芯片整体含有8*128=1024个CUDA Core。

NVIDIA首席科学家Bill Dally
各个SM模块独立命名为"NoC"(Network on Chip)通过内部界面,经由L2 Cache和内存控制器与其他SM相互连接。L2 Cache和CUDA Core数量一样分1024块,单个Echelon芯片中,NoC通过MC与一同封装的DRAM Cube连接带宽可达1.4TB/s。
Echelon芯片的峰值计算性能(以双精度浮点运算记)可达20T FLOPS。NVIDIA设想的每个Echelon机柜搭载32个模块,每个模块封装4个Echelon芯片,这样单个机柜的运算能力可达2.56P FLOPS。Echelon的Phase1(第一阶段)设计就是如此,NVIDIA将在此基础上第二阶段主要考虑继续提高运算性能和降低芯片所消耗的电力。
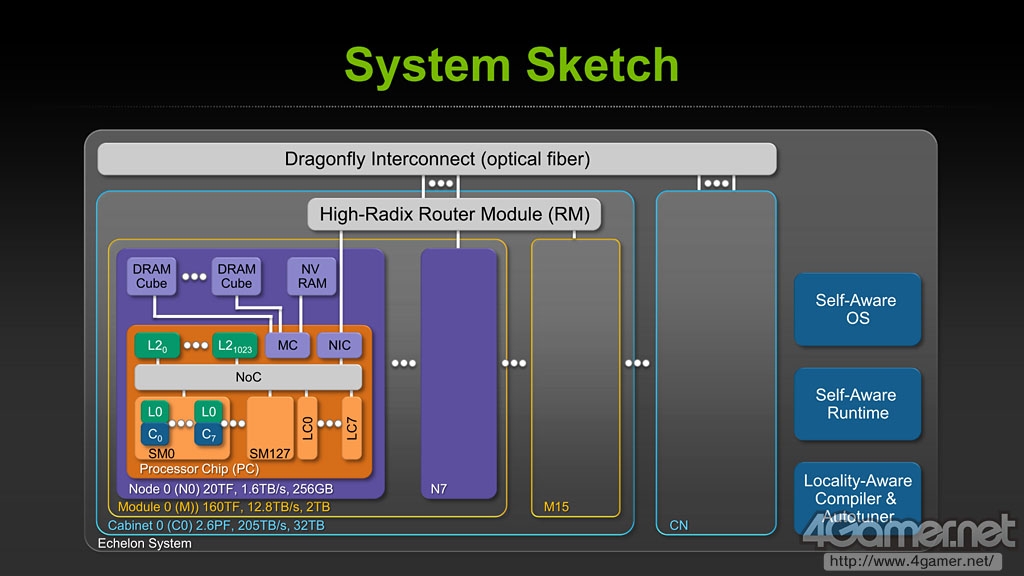
Echelon模块图解
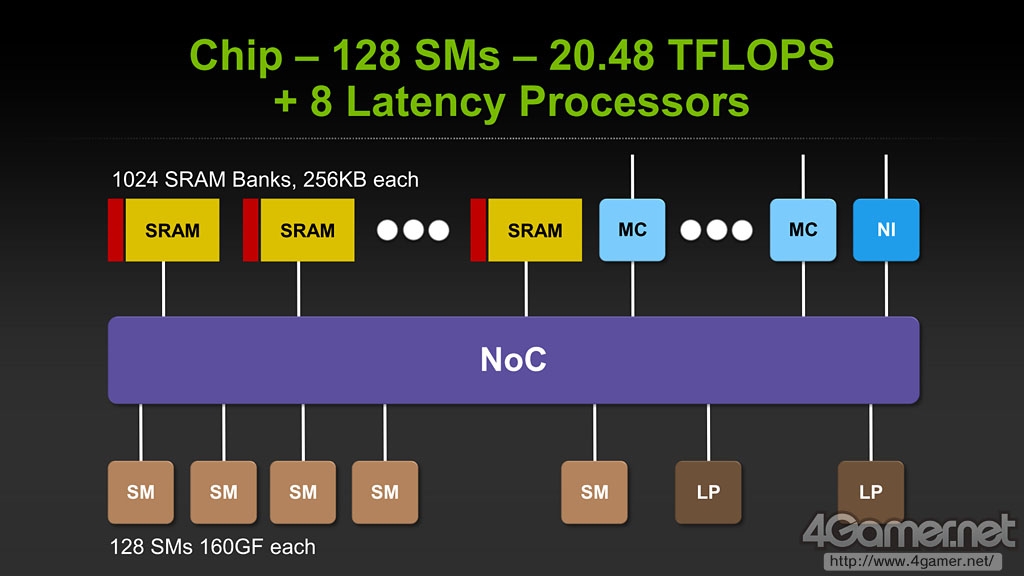
Echelon由128个SM模块和8个Latency Processor组成,后者就是Denver的核心
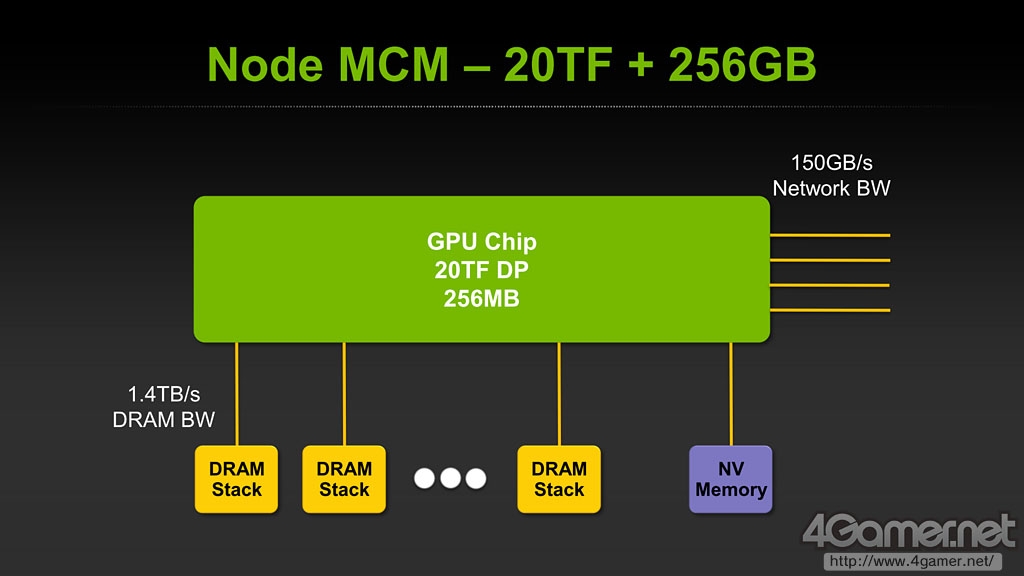
内存和每个Echelon的MCM(Multi Chip Module)Node在同一封装内相连,带宽可达1.4TB/s
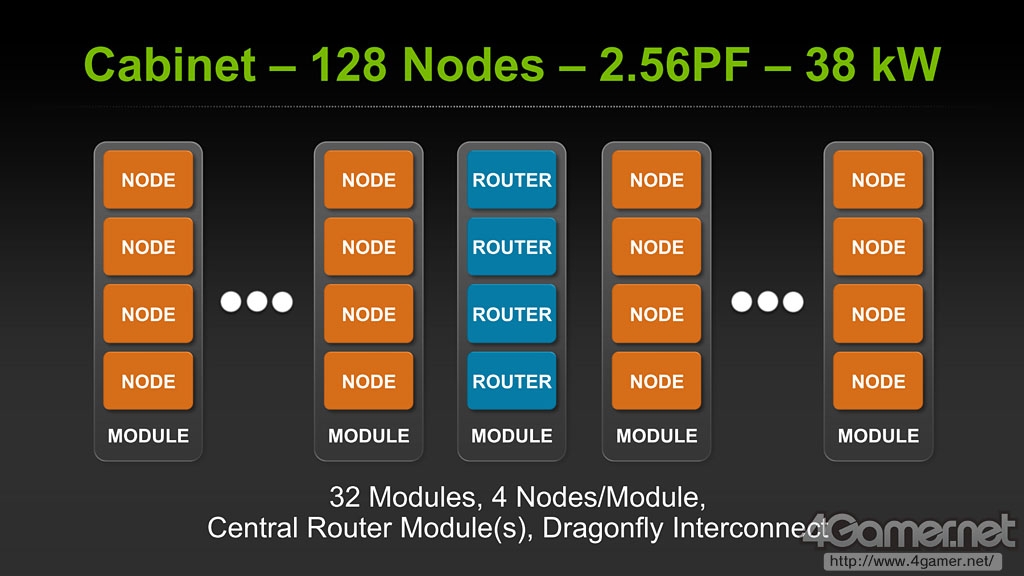
每个Echelon机柜由128个Node(即单Echelon芯片)组合而成,实现2.56P FLOPS的计算能力,功率38千瓦

400个机柜即可实现Exa级别的计算,功率约150万瓦
为了配合UHPC一期开发阶段制造Echelon工程样品的需要,2013年前需要完成Latency Processor即Project Denver的CPU核心开发工作。
这和NVIDIA在GTC Workshop Japan 2011上公开的最新平台路线图相符合,Project Denver将和NV的下下代GPU核心"Maxwell"在同一时段登场。公布的幻灯片将Denver和Maxwell划在了同一个框内,或许Echelon就是Maxwell和Denver核心的组合体?
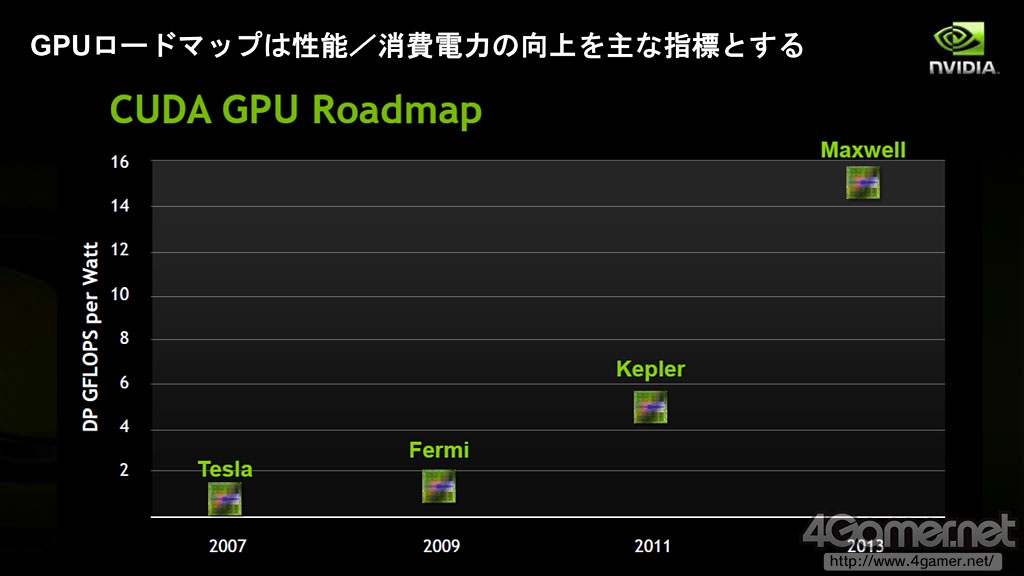
NVIDIA的GPU发展路线图
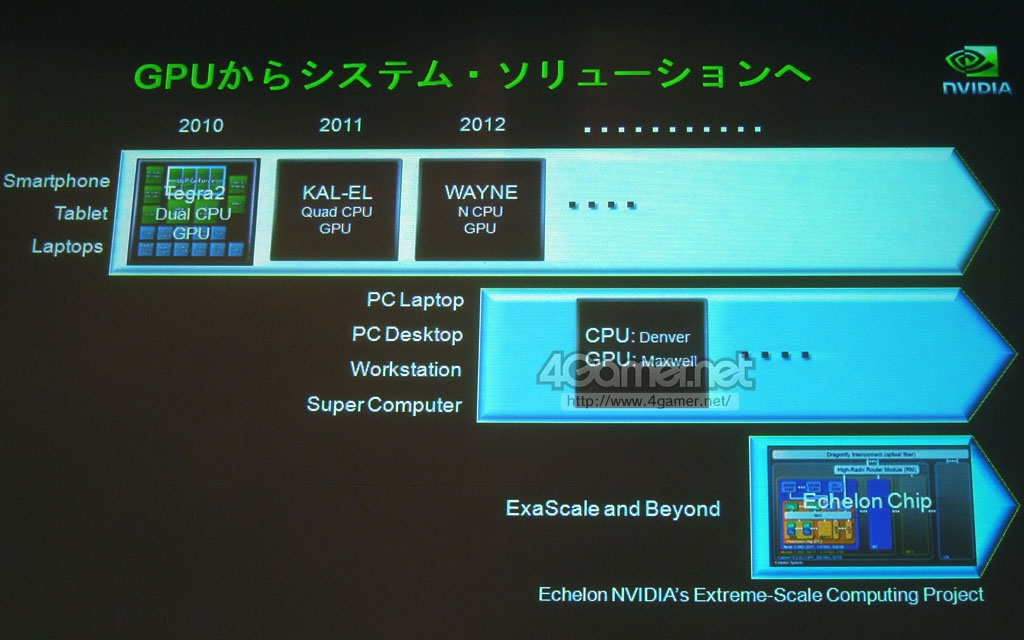
GTC Workshop Japan 2011上公开的各平台框架图
不过和Echelon专注于通用计算不同的是,作为需要兼顾到原本3D应用的GeForce系列芯片,Maxwell不太可能采用像前者一样激进的GPGPU专用架构。根据前面Echelon拥有1024个CUDA Cores实现20T FLOPS计算能力推算,如果Maxwell和Fermi成品旗舰显卡的TDP相当,在250W左右的话,双精度浮点性能大约为3.5-4T FLOPS为Tesla的15倍,Fermi的7.5倍左右,和NV路线图展示的比例相近。但如果两者架构相同,Maxwell的CUDA核心数可能会降到200左右,现在NVIDIA旗舰显卡GTX 580则有512个。由此看来除非NV桌面显卡架构也跟着大变,否则Maxwell和Echelon不太可能采用同样架构,两者的GPU性能不是为同一级别应用设计。
此外,黄仁勋也曾经发表过关于Project Denver性能的评论,他在GPU Technology Conference 2010会议上曾经表示,将GPU和现有的ARM架构CPU(Cortex-A9)整合后,整数运算性能将是原有的3-4倍。如果这里整合产物指的是Project Denver,那么它的性能将是下代ARM Cortex A-15的2倍以上。如果此目标真能实现,那么NVIDIA将在ARM阵营内争夺主导权的战斗中占据上风,Project Denver也将圆满完成目标。
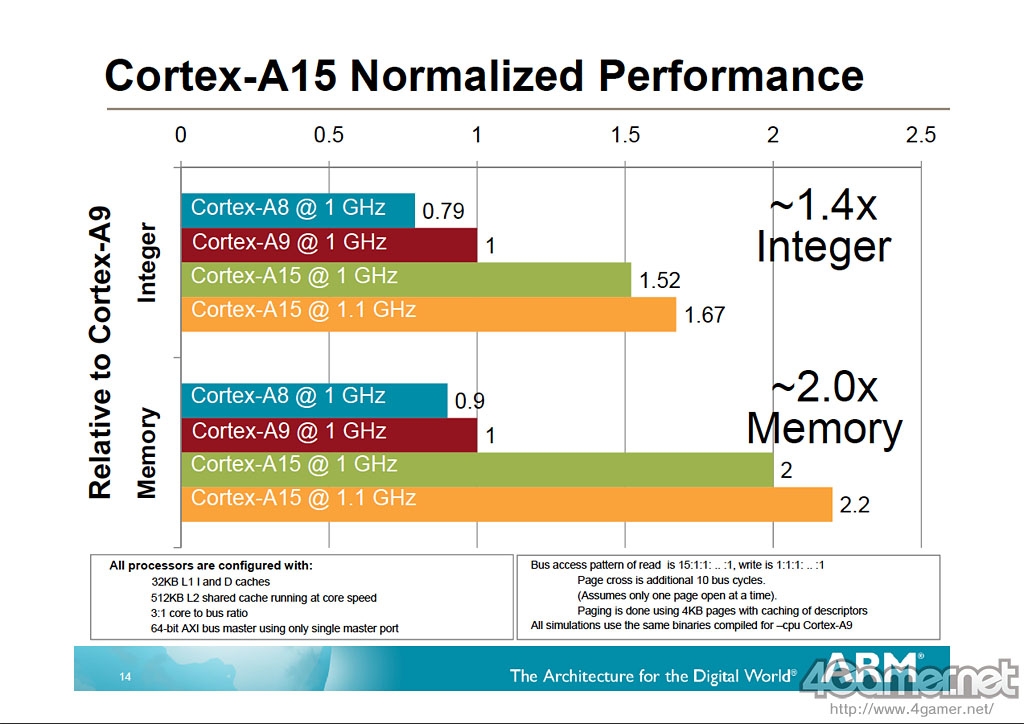
ARM公开的Cortex-A15对比同频Cortex-A9的性能对比图,如果Project Denver是Cortex-A9性能的3-4倍,那么将是Cortex-A15性能的2倍以上
Desai曾经称NVIDIA的CPU核心开发部分在同时推进多个计划,在笔者看来,Project Denver或许还有另外一个出路——进驻基于Windows 8的笔记本电脑用SoC(System on a Chip)市场。
回顾一下前面提到的内容,Echelon、Maxwell和Denver核心的功耗都比较高,进驻笔记本电脑SoC芯片市场的可能性很小。而目前还没有Tegra和Project Denver合并的计划,Tegra处理器在2011年2月MWC 2011大会上公开的路线图也多是针对智能手机和平板电脑市场,并且Tegra的性能目前看来也只适合低端笔记本。 此外,2013年Intel和AMD预计都将力推超薄笔记本电脑所用CPU SoC化,特别是Intel从现在就开始力推Ultrabook概念。难得Windows 8开始支持ARM架构处理器,NVIDIA没理由不参与这一世代的笔记本电脑市场竞争。
这样看来,Tegra可能会从Project Denver的第二代CPU核心开始与后者整合。目前我们得知的消息是,四核Kal-El的下一代Tegra "Wayne"和下下代"Logan"均将使用Cortex-A15架构,而2014年的"Stark"就是Tegra和Denver的最好整合时期。至于Stark以后NVIDIA将怎样活用Project Denver的成果继续发展Tegra品牌产品,我们大可拭目以待。
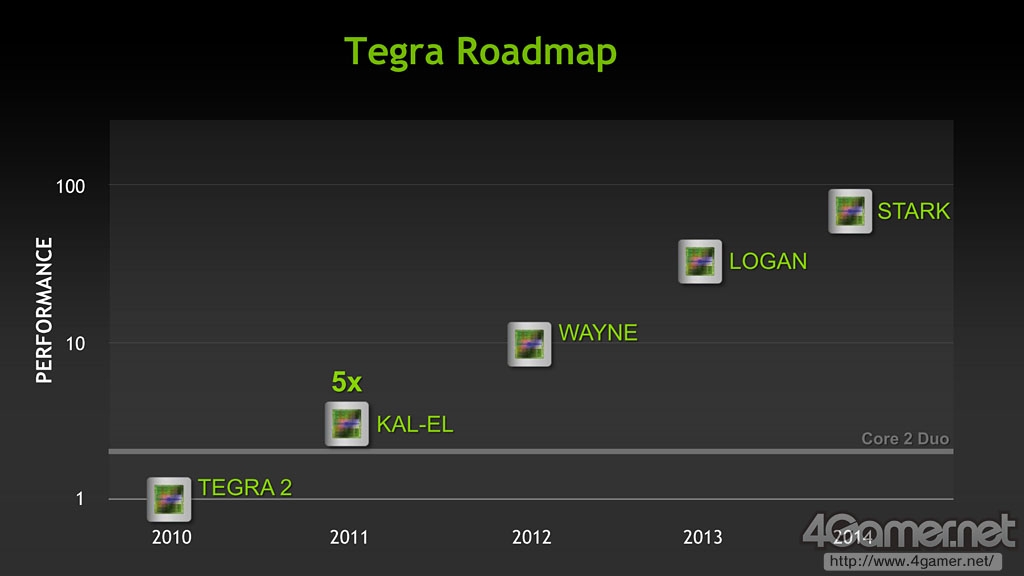
Tegra产品发展路线图
总结:Project Denver是NVIDIA在CPU+GPU混合计算时代掌握市场主导权的最重要计划,此后NV旗下产品将主要分为三大块:着重于GPGPU的高性能计算处理器,3D游戏用GPU和移动设备包括笔记本电脑、平板电脑和智能手机的Tegra三足鼎立,对比最早单GPU和近年来Tegra+GPU的战略做了重大变革。
本文收录在
#快讯
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...