正文内容 评论(0)

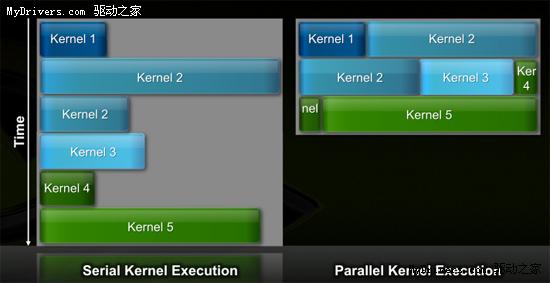
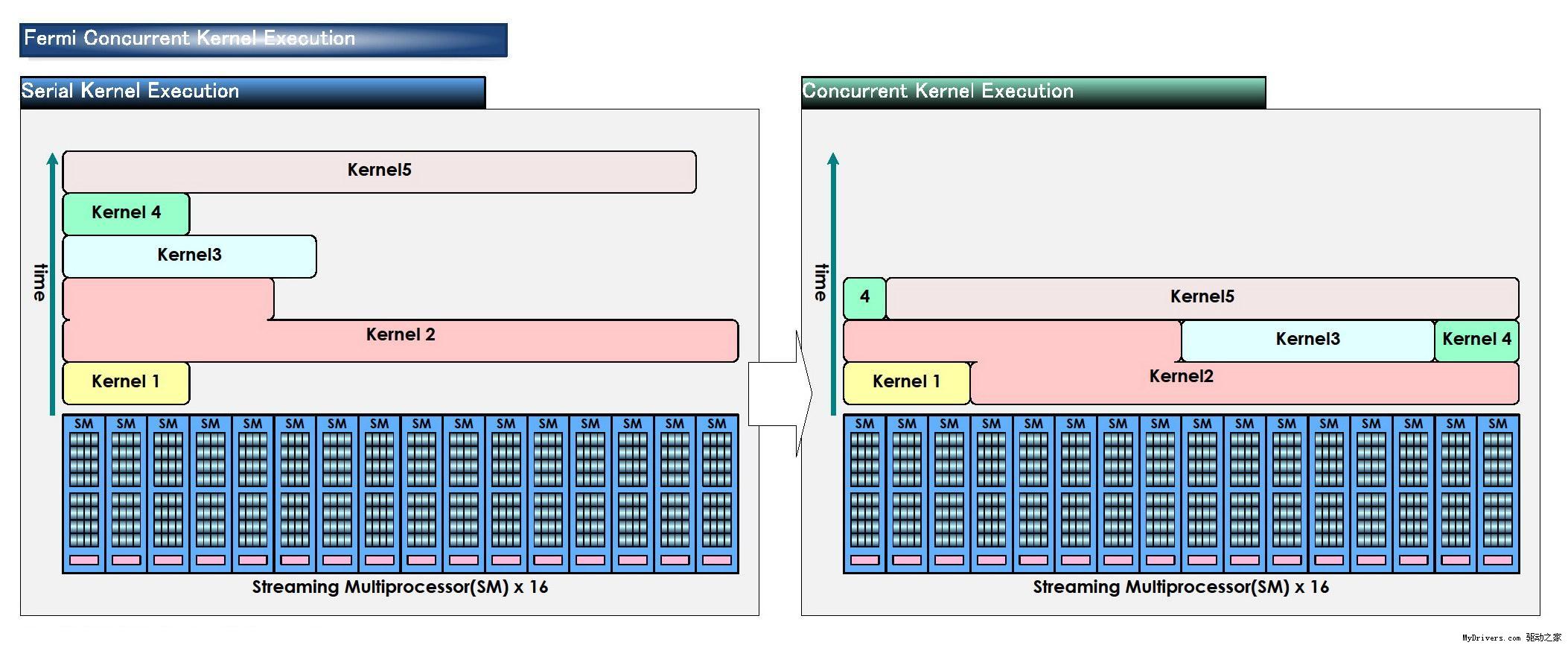
4、并行内核(Parallel Kernel)
在GPU编程术语中,内核是运行在GPU硬件上的一个功能或小程序。G80/GT200整个芯片每次只能执行一个内核,容易造成SM单元闲置。这在图形运算中不是问题,通用计算上就不行了。
Fermi的全局分配逻辑则可以向整个系统发送多个并行内核,不然SP数量翻一番还多,更容易浪费。
应用程序在GPU和CUDA模式之间的切换时间也快得多了,NVIDIA宣称是GT200的10倍。外部连接亦有改进,Fermi现在支持和CPU之间的并行传输,而之前都是串行的。
5、ECC支持
AMD Cypress可以检测内存总线上的错误,却不能修正,而NVIDIA Fermi的寄存器文件、一级缓存、二级缓存、DRAM全部完整支持ECC错误校验,这同样是为Tesla准备的,之前我们也提到过。
很多客户此前就是因为Tesla没有ECC才拒绝采纳,因为他们的安装量非常庞大,必须有ECC。
6、统一64-bit内存寻址
以前的架构里多种不同载入指令,取决于内存类型:本地(每线程)、共享(每组线程)、全局(每内核)。这就和指针造成了麻烦,程序员不得不费劲清理。
Fermi统一了寻址空间,简化为一种指令,内存地址取决于存储位置:最低位是本地,然后是共享,剩下的是全局。这种统一寻址空间是支持C++的必需前提。
GT80/GT200的寻址空间都是32-bit的,最多搭配4GB GDDR3显存,而Fermi一举支持64-bit寻址,即使实际寻址只有40-bit,支持显存容量最多也可达惊人的1TB,目前实际配置最多6GB GDDR5——仍是Tesla。

7、新的指令集架构(ISA)
下边对开发人员来说是非常酷的:NVIDIA宣布了一个名为“Nexus”的插件,可以在Visual Studio里执行CUDA代码的硬件调试,相当于把GPU当成CPU看待,难度大大降低。
Fermi的指令集架构大大扩充,支持DX11和OpenCL义不容辞,C++前边也已经说过,现在又多了Visual Studio,当然还有C、Fortran、OpenGL 3.1/3.2。
最后汇总一下G80、GT200、Fermi的差异:

本文收录在
#快讯
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...