正文内容 评论(0)

AMD Cypress(RV870)拉开了DX11时代的序幕,NVIDIA Fermi(GT300)正在掀起新的浪潮。今天凌晨,NVIDIA在GPU技术会议上终于揭开了全新架构的秘密,并首次展示了新一代显卡。
一、迟来的怪兽
先看这张图:
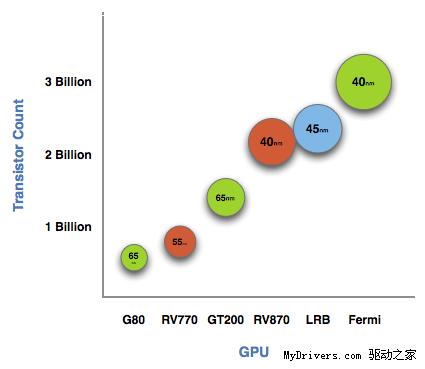
横向是NVIDIA、AMD历代图形核心(以及Intel Larrabee),纵向是晶体管数量,各个圆圈上标注的则是制造工艺——右上角最庞大、最惹眼的就是今天的主角,NVIDIA Fermi。
GT200的14亿个晶体管曾经让我们惊叹,Cypress的21.5亿个相比RV770的9.56亿个增加了一倍多,而Fermi达到了史无前例的30亿个,同样比自己的上一代翻了一番还多,比对手也多了40%。
从最高层面上说,Fermi很简单,无非是512个流处理器,384-bit GDDR5显存,而深层次的架构我们会在稍后逐一揭晓,不过Fermi至今还停留在纸面上,还不是一款真正的产品,所以型号划分、时钟频率、售价等等都还没有确定。事实上,直到两个月前NVIDIA才第一次让人看到了样品,最近不久刚刚获得可以正常工作的芯片,正式发布至少要到今年年底,而全面上市就是明年第一季度的事儿了。
Fermi为什么这么晚?NVIDIA产品营销副总裁Ujesh Desai说了一句:因为设计这么大的GPU实在是太TMD的难了。


首次公布的Fermi核心照
二、来自RV770/GT200的教训
AMD用RV770核心给NVIDIA好好上了一课,庞大而沉重的GT200失去了反击之力,CUDA、PhysX这种对手所没有的功能特性于是成了宣传重点。
作为GeForce业务负责人,Ujesh Desai愿意承担责任,并承认在GT200时代严重失策。根据RV670 Radeon HD 3800的表现,NVIDIA推测其继任者的性能也不过尔尔,但RV770的表现大大出乎意料,而GT200定价过高,最终导致了一夜之间暴降千元的悲剧。
NVIDIAGPU工程副总裁Jonah Alben没有把责任都推到Ujesh身上,承认自己在工程上也有失误。GT300从一开始就应该采用新的55nm工艺,但NVIDIA在130nm NV30 GeForce FX被150nm Radeon 9700 Pro大败之后趋于保守,最后一次使用了65nm工艺,最终成就了一个面积庞大、功耗超高的巨无霸。
虽然40nm工艺进程依然稍微落后于对手,但NVIDIA不会在同一条河里摔倒两次,没有在Fermi上沿用55nm,否则又是一颗无法接受的大芯片。
不过NVIDIA暂时还没有透露Fermi的具体大小,只能估计一下。Fermi和Cypress都是40nm工艺,假设核心面积和晶体管数量呈等比例,那么在后者334平方毫米的基础上,Fermi将是466平方毫米,比576平方毫米的GT200小足足两成。
尽管AMD的Sweet Point策略让NVIDIA吃尽了苦头,不过NVIDIA依然认为最重要的并非首先开发价格较低的小芯片,而是提高大芯片的效率,然后衍生出不同的尺寸和配置规格。期待Fermi的主流版本能在明年尽快出炉。

GT200/RV770/Penryn核心对比
三、不再只是游戏
NVIDIA相信Fermi在3D游戏里会比Radeon HD 5870更快,当然不快也不行,但是如果你只是把Fermi单纯地看作是一颗游戏GPU就错了,因为它的真正目标是Tesla,是高性能通用计算,是个人和数据中心超级计算机——这就是GT300里边那个字母T的含义,它要做一颗通用目的微处理器。
这有点儿像Intel Nehalem架构,确切目标也不是桌面,而是高性能计算服务器领域,所以新的Xeon处理器才在服务器工作站上横扫一片,但游戏性能并不比Core 2 Quad好多少。
NVIDIA声称,要达到同样的性能,使用CPU就得2000台x86服务器,总成本约800万美元,功耗1200kW,而换成GPU只需32台Tesla S1070s系统(如下图),成本不过40万美元,功耗更是仅仅45kW。虽然这里没有算上驱动Tesla所需要的服务器(毕竟GPU不可能完全摆脱CPU),但这部分占得也不会太多。

NVIDIA预计,未来18个月内各高性能市场总价值如下:地震3亿美元、超级计算2亿美元、大学1.5亿美元、国防2.5亿美元、金融2.3亿美元。虽然上个季度Tesla只带来了1000万美元的收入,占NVIDIA总收入的1.3%,但NVIDIA相信它前途无量,所以Fermi架构的很多地方都是专门为此设计的。
其实借着DX10统一渲染的东风,NVIDIA从G80就开始了通用计算的努力,GT200更进一步,但它们主要还是一颗图形芯片,直到Fermi,不但肩负双重使命,而且同样重要。AMD有3A一体化平台,Intel也在开发独立显卡,NVIDIA自然不能坐以待毙,正在朝着视觉计算迈进。

四、Fermi架构解析
1、SP、SM
从高层次上看,Fermi和GT200结构形似,并无太大不同,但往深处看就会发现绝大部分都已经进化。
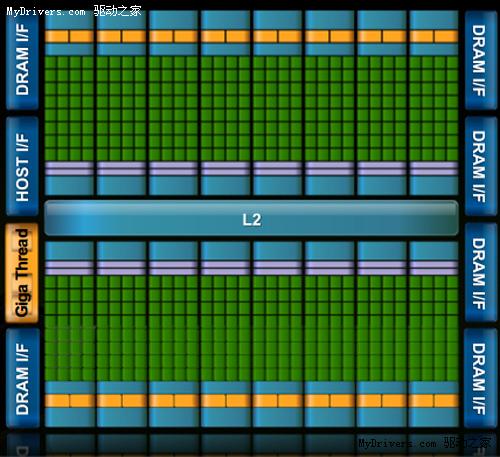
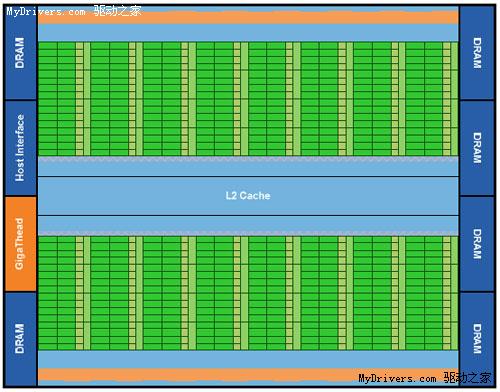
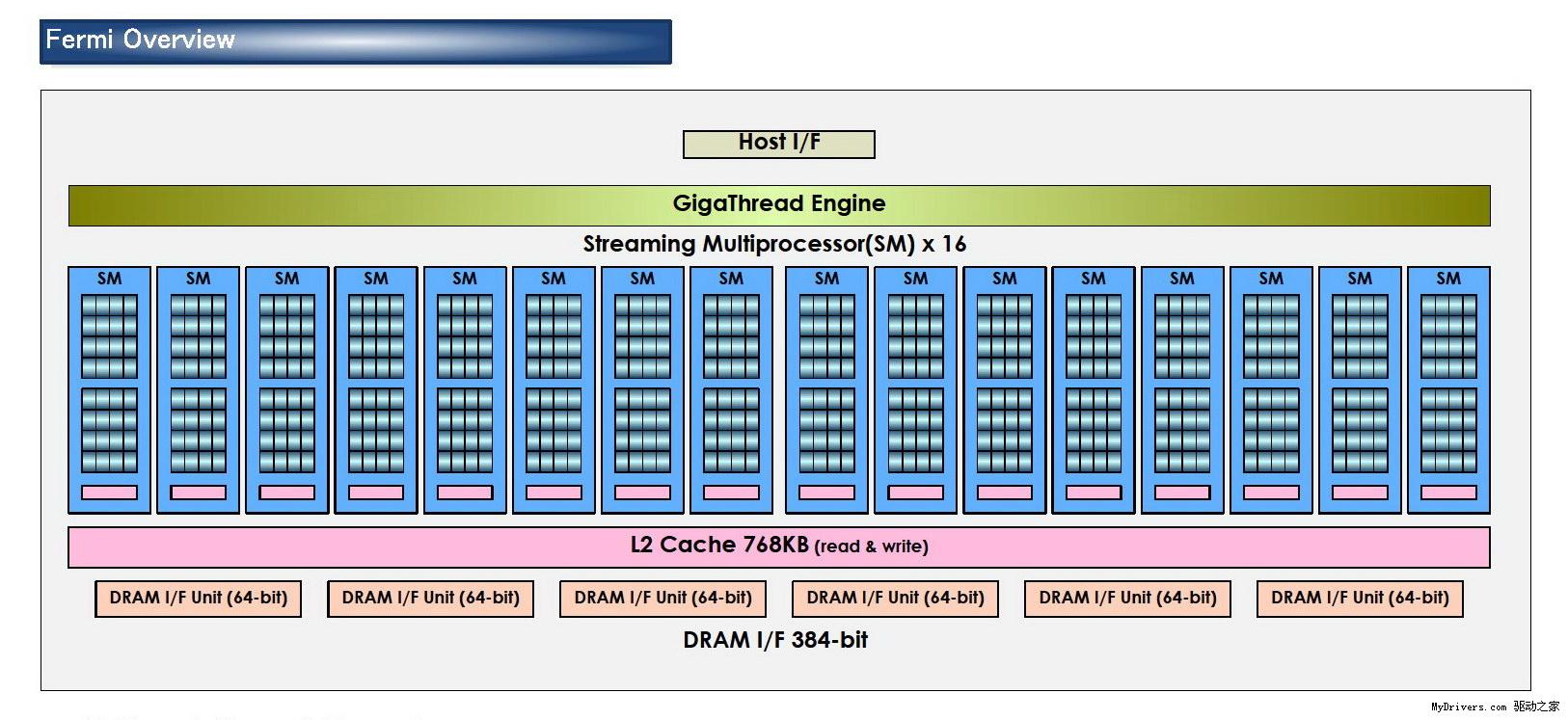
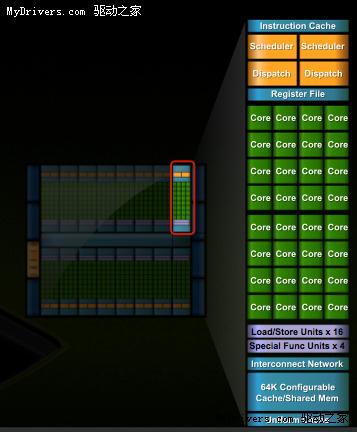
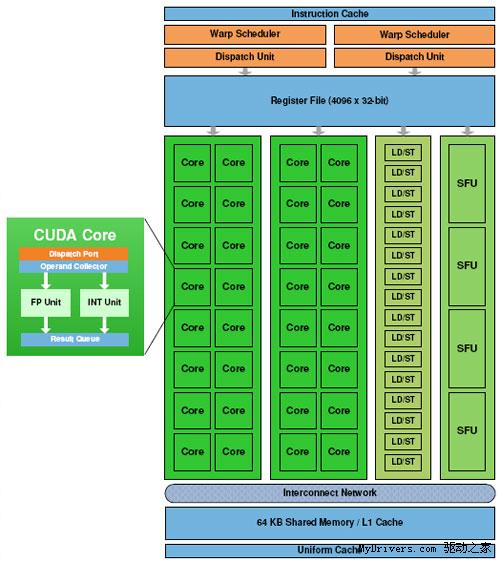
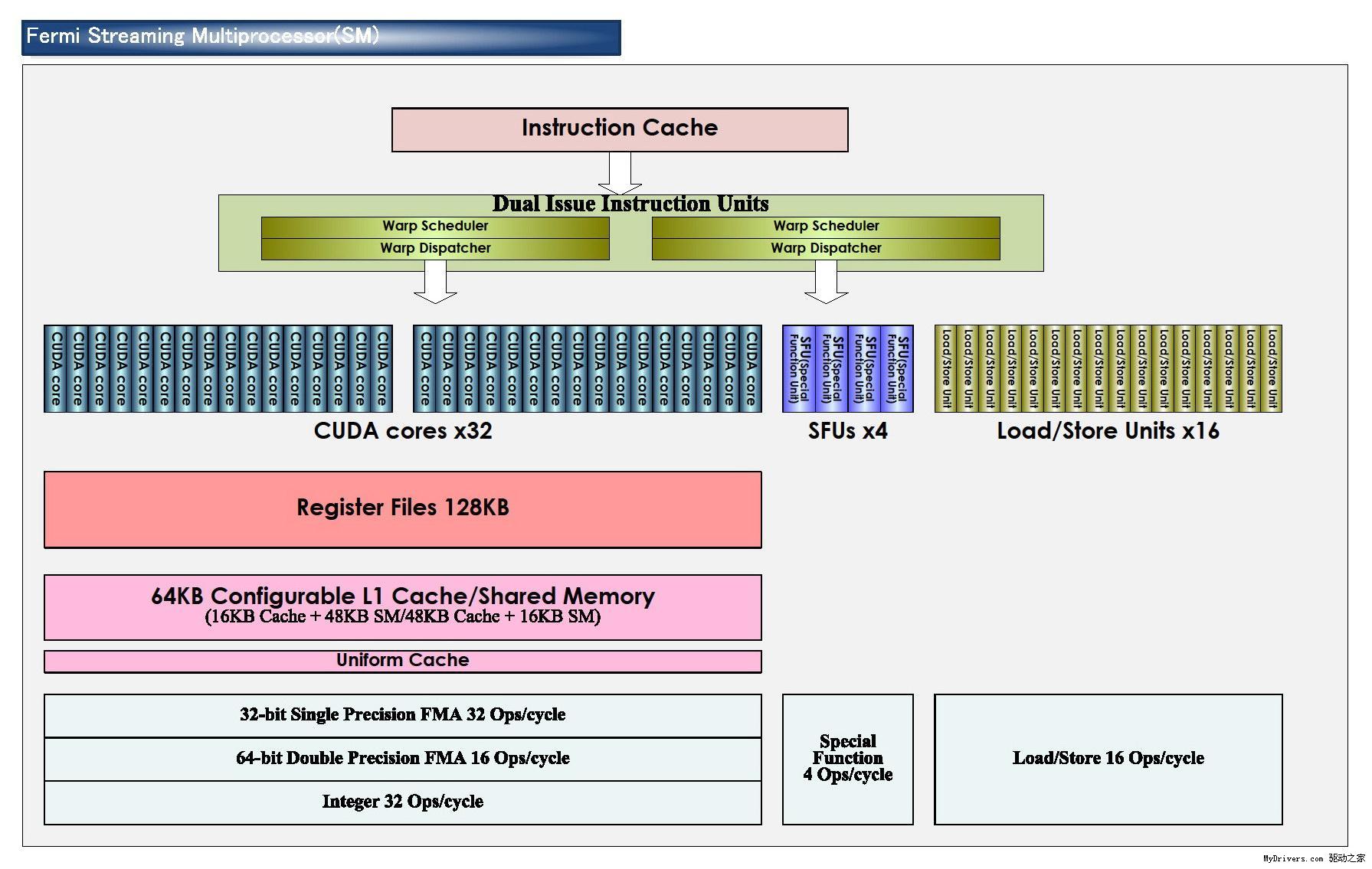
最核心的流处理器(Streaming Processor/SP)现在不但数量大增,还有了个新名字CUDA核心(CUDA Core),由此即可看出NVIDIA的转型之意,不过我们暂时还是继续沿用流处理器的说法。
所有流处理器现在都符合IEEE 754-2008浮点算法(Cypress也是如此)和完整的32位整数算法,而后者在过去只是模拟的,事实上仅能计算24-bit整数乘法;同时全面引入的还有积和熔加运算(Fused Multiply-Add/FMA),每循环操作数单精度512个、单精度256个(G200仅支持单精度FMA)。所有一切都符合业界标准,计算结果不会产生意外偏差。
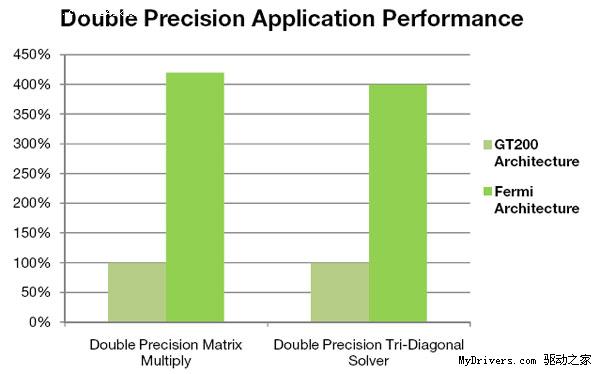
双精度浮点(FP64)性能大大提升,峰值执行率可以达到单精度浮点(FP32)的1/2,而过去只有1/8,AMD现在也不过1/5,比如Radeon HD 5870分别为单精度2.72TFlops、双精度544GFlops。由于最终核心频率未定,所以暂时还不清楚Fermi的具体浮点运算能力(双精度预计可达624GFlops)。
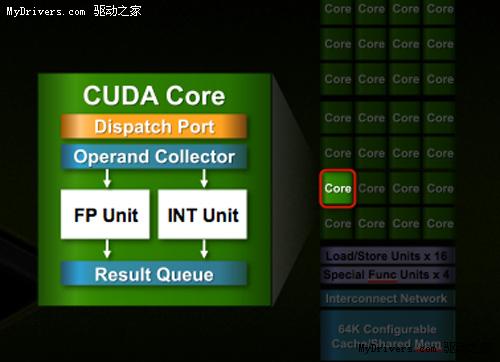
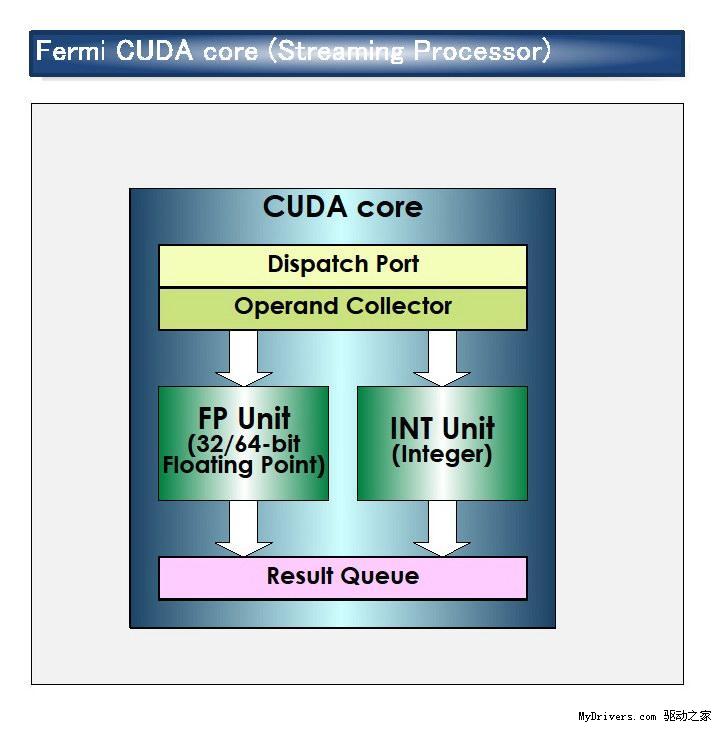
G80/GT200都是8个流处理器构成一组SM(Streaming Multiprocessor),Fermi增加到了32个,最多16组,少于GT200的30组,但流处理器总量从240个增至512个,是G80的整整四倍。
除了流处理器,每组SM还有4个特殊功能单元(Special Function UnitSFU),用于执行抽象数学和插值计算,G80/GT200均为2个。同时MUL已被删掉,所以不会再有单/双指令执行计算率了。
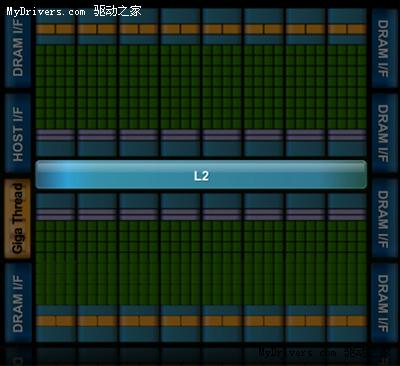
至于SM之上的纹理处理器群(Texture Processor Cluster/TPC),NVIDIA暂时没有披露具体组成方式,而且ROP单元、纹理/像素填充率等其它图形指标也未公布。
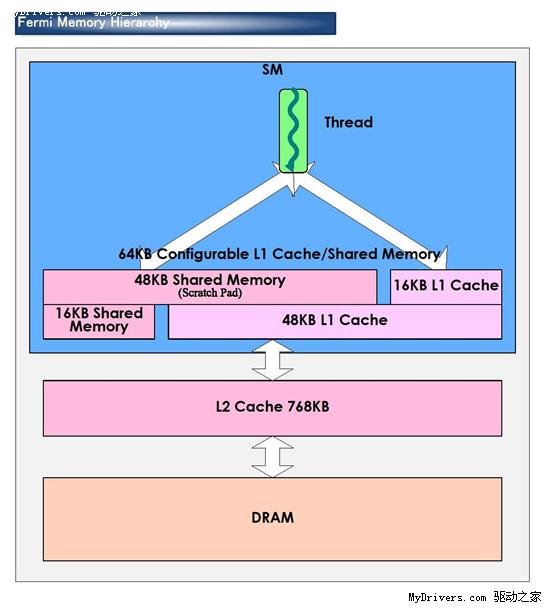
2、缓存
GT200的每组SM都有16KB共享内存,由其中8个SP使用。注意它们不是缓存(cache),而是软件管理的内存(memory),可以写入、读取数据。为了满足应用程序和通用计算的需要,Fermi引入了真正的缓存,每组SM拥有64KB可配置内存(合计1MB),可分成16KB共享内存加48KB一级缓存,或者48KB共享内存加16KB一级缓存,可灵活满足不同类型程序的需要。
GT200的每组TPC还有一个一级纹理缓存,不过当GPU出于计算模式的时候就没什么用了,故而Fermi并未在这方面进行增强。
整个芯片拥有一个容量768KB的共享二级缓存,执行原子内存操作(AMO)的时候比GT200快5-20倍。
3、效率
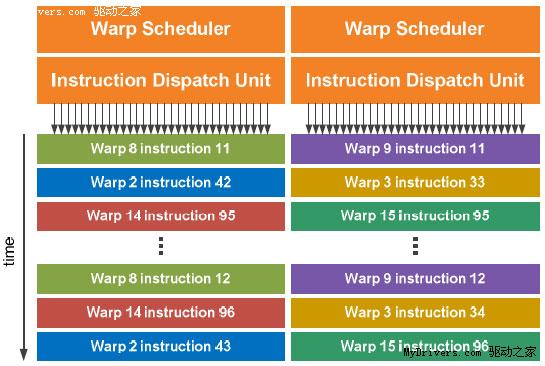
CPU和GPU执行的都是被称作线程的指令流。高端CPU现在每次最多只能执行8个线程(Intel Core i7),而GPU的并行计算能力就强大多了:G80 12288个、GT200 30720个、Fermi 24576个。
为什么Fermi还不如GT200多?因为NVIDIA发现计算的瓶颈在于共享内存大小,而不是线程数,所以前者从16KB翻两番达到64KB,后者则减少了20%,不过依然是G80的两倍,而且每32个线程构成一组“Warp”。
在G80和GT200上,每个时钟周期只有一半Warp被送至SM,换言之SM需要两个循环才能完整执行32个线程;同时SM分配逻辑和执行硬件紧密联系在一起,向SFU发送线程的时候整个SM都必须等待这些线程执行完毕,严重影响整体效率。
Fermi解决了这个问题,在每个SM前端都有两个Warp调度器和两个独立分配单元,并且和SM其它部分完全独立,均可在一个时钟循环里选择发送一半Warp,而且这些线程可以来自不同的Warp。分配单元和执行硬件之间有一个完整的交叉开关(Crossbar),每个单元都可以像SM内的任何单元分配线程(不过存在一些限制)。
这种线程架构也不是没有缺点,就是要求Warp的每个线程都必须同时执行同样的指令,否则会有部分单元空闲。每组SM每个循环内可以执行的不同操作数:FP32 32个、FP64 16个、INT 32个、SFU 4个、LD/ST 16个。
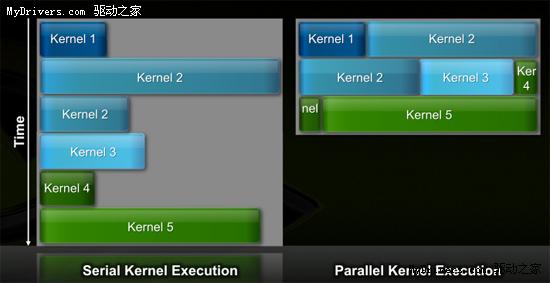
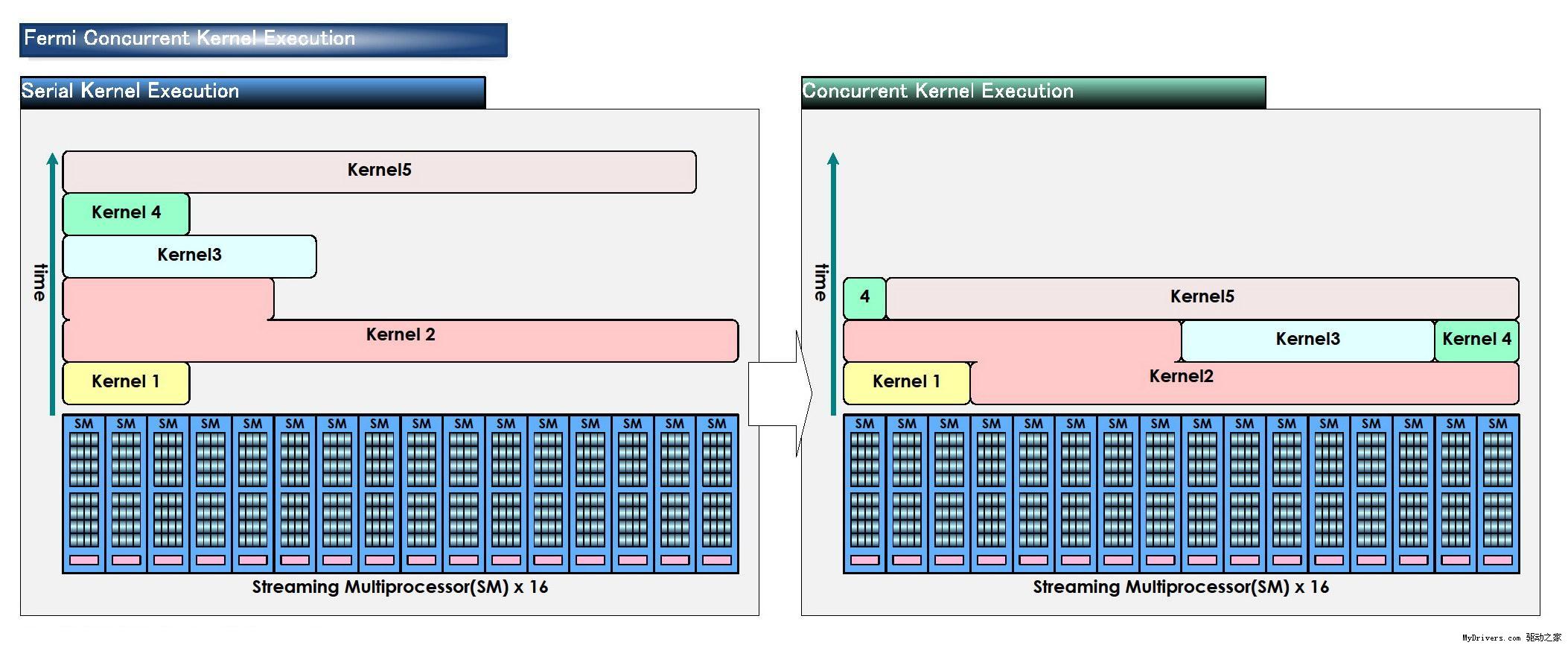
4、并行内核(Parallel Kernel)
在GPU编程术语中,内核是运行在GPU硬件上的一个功能或小程序。G80/GT200整个芯片每次只能执行一个内核,容易造成SM单元闲置。这在图形运算中不是问题,通用计算上就不行了。
Fermi的全局分配逻辑则可以向整个系统发送多个并行内核,不然SP数量翻一番还多,更容易浪费。
应用程序在GPU和CUDA模式之间的切换时间也快得多了,NVIDIA宣称是GT200的10倍。外部连接亦有改进,Fermi现在支持和CPU之间的并行传输,而之前都是串行的。
5、ECC支持
AMD Cypress可以检测内存总线上的错误,却不能修正,而NVIDIA Fermi的寄存器文件、一级缓存、二级缓存、DRAM全部完整支持ECC错误校验,这同样是为Tesla准备的,之前我们也提到过。
很多客户此前就是因为Tesla没有ECC才拒绝采纳,因为他们的安装量非常庞大,必须有ECC。
6、统一64-bit内存寻址
以前的架构里多种不同载入指令,取决于内存类型:本地(每线程)、共享(每组线程)、全局(每内核)。这就和指针造成了麻烦,程序员不得不费劲清理。
Fermi统一了寻址空间,简化为一种指令,内存地址取决于存储位置:最低位是本地,然后是共享,剩下的是全局。这种统一寻址空间是支持C++的必需前提。
GT80/GT200的寻址空间都是32-bit的,最多搭配4GB GDDR3显存,而Fermi一举支持64-bit寻址,即使实际寻址只有40-bit,支持显存容量最多也可达惊人的1TB,目前实际配置最多6GB GDDR5——仍是Tesla。

7、新的指令集架构(ISA)
下边对开发人员来说是非常酷的:NVIDIA宣布了一个名为“Nexus”的插件,可以在Visual Studio里执行CUDA代码的硬件调试,相当于把GPU当成CPU看待,难度大大降低。
Fermi的指令集架构大大扩充,支持DX11和OpenCL义不容辞,C++前边也已经说过,现在又多了Visual Studio,当然还有C、Fortran、OpenGL 3.1/3.2。
最后汇总一下G80、GT200、Fermi的差异:

五、Fermi样卡展示
说了这么半天的架构技术,我也有点儿不耐烦了,下边就来点儿更实际的,看看黄仁勋和Fermi样卡。







(辅助供电接口除了尾部可以看到的八针还有一个六针)

体积、样式和我们想象得差不多,不过输出接口只有一个DVI?别忘了这不是GeForce,而是Tesla。AMD着力宣传ATI Eyefinity单卡多显技术,DVI、HDMI、DisplayPort齐上阵,而NVIDIA把目光投向了高性能通用计算,双雄渐行渐远。
这下知道NVIDIA为什么说DX11不是唯一了吧?绝非只是冒酸水。

本文收录在
#快讯
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...