正文内容 评论(0)

[Core和Yonah的不同点:(二) 分支预测单元的改进]
在缩短流水线级数的同时,Core 微架构前端的改进还包括分支预测单元。分支预测行为发生在取指单元部分。包括人们已经熟知的预测单元分支目标缓冲区(BTB)、分支地址计算器(BAC)和返回地址栈(RAS)。并且引入了2个新的预测单元:Loop Detector和Indirect Branch Predictor,其中Loop Detector可以正确预测循环的结束,而Indirect Branch Predictor可以基于全局的历史信息做出预测。而且更难得的是以前分支转移总是会浪费流水线的一个周期而Core 微架构在分支目标预测器和取指单元之间增加了一个队列,在大部分的情况下可以避免这一个周期的浪费,因此可以极大的提高效能。
Core 微架构的乱序执行引擎与Yonah微架构的设计类似,但是引入了更多的资源。
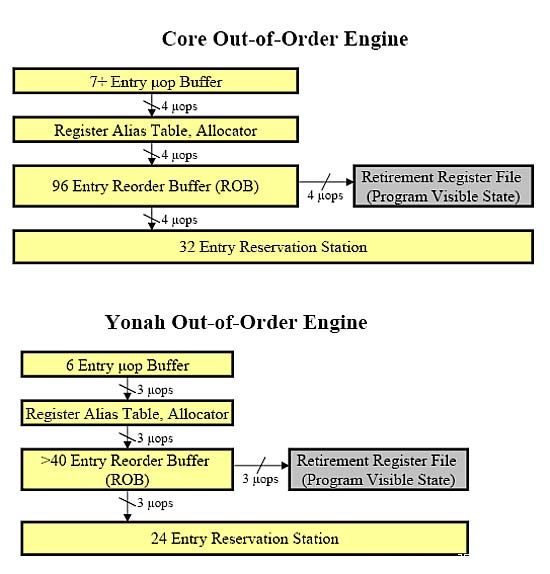
Core和Yonah的乱序执行引擎对比
如图所示,Core微架构与Yonah微架构在乱序执行引擎方面非常相似,包括寄存器别名表(Register Alias Table),分配器(Allocator)和乱序缓冲区(Reorder Buffer)。区别在于,所有的这些单元都被加大加强,这样才可以配合更强劲的前端,容纳和调度更多的微指令,寻求更高的指令级并行度。也就是说,Core的乱序执行引擎实际上是Yonah的乱序执行引擎的强化版。
从图中我们还可以看出Yonah微架构的最大吞吐量是每周期3条微指令,Core微架构的最大吞吐量是每周期4条微指令。Yonah微架构的乱序执行引擎是大于40项,而Core微架构的乱序缓冲区容量是96项。Core微架构的保留站(Reservation Station)同样被加大:从Yonah微架构的24项增大到32项。
Core采取和Yonah相似的乱序执行引擎究其原因是在前代产品成功的前提下节约开发时间和开发费用,少走弯路。当然原封不动是不足以承担对抗K8架构的重任,因此在乱序执行引擎的各方面都作了加强。不过,恐怕Intel在下次架构改变之时就不会那么容易了。
本文收录在
#快讯
- 热门文章
- 换一波

- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...