正文内容 评论(0)

自从NVIDIA支持DX10的统一渲染架构G80核心发布以来,半导体工艺的进步使得GPU内置的核心(流处理器)数量越来越多,GPU基础架构改良速度对比CPU也越来越快。GPU的通用计算能力在这几年来得到很大提高。
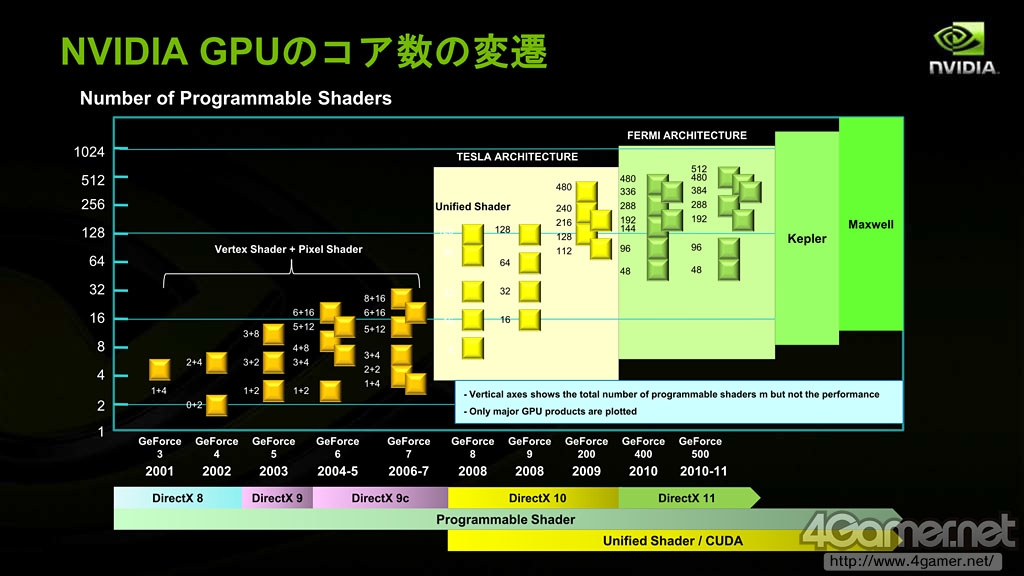
NVIDIA旗下GPU的核心数量变化历史
因为GPU起初是为图形处理设计,对指令集的依存度很低,即使再多线程数量也仍然能保持并行处理性能维持在高水平不变。举例来说,对于3D角色的反射光计算,每个多边形反射光计算中法线处理互不相干,因此多边形数量再多也不会造成瓶颈,GPU的运算能力可以充分发挥。
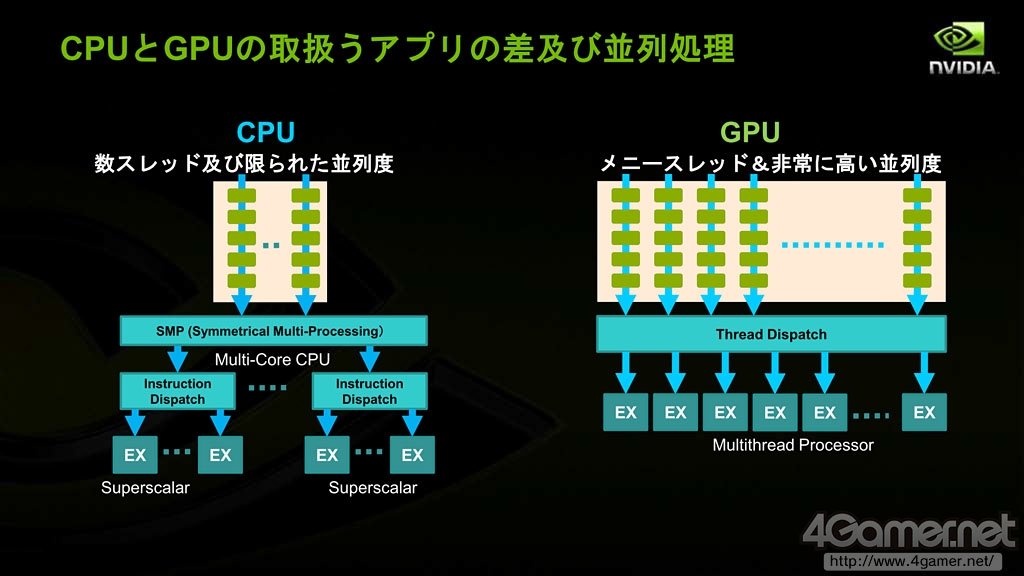
CPU和GPU的并行处理示意图
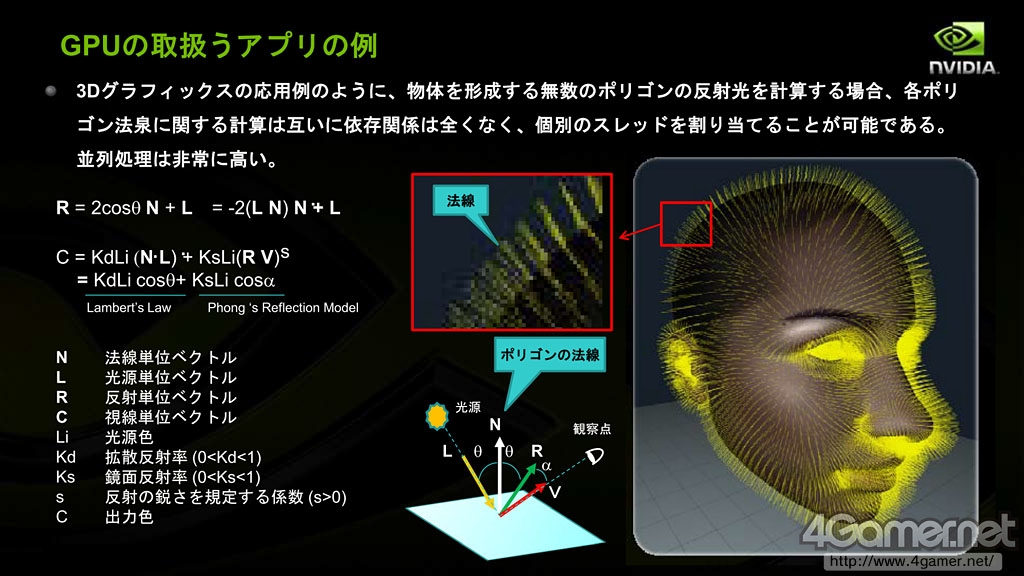
GPU实际并行计算示例:复杂多边形的反射光处理运算
因此,科学运算中最适合利用GPU强大的并行计算能力,馬路徹表示,NVIDIA近年来所力推的Tesla加速卡就是例子,同时取得了很多成果。
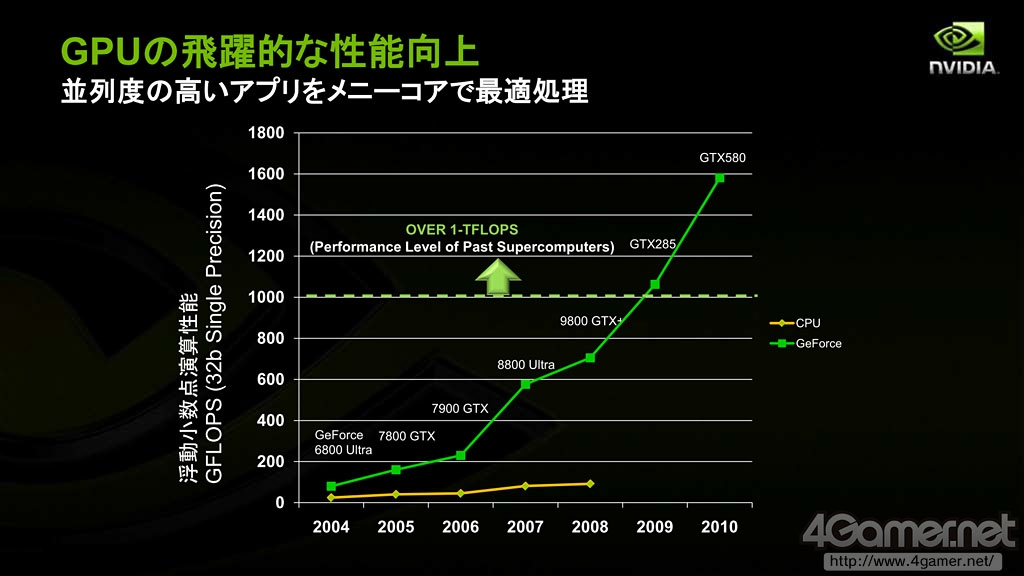
GPU理论浮点运算性能取得了飞跃

GPU并行计算适合多种要求高性能运算的应用
NVIDIA必然开发自家CPU
不过GPU的发展也会受到阿姆达尔定律的影响,当GPU集成的核心数量越来越多时也一定会遇到瓶颈。
解决瓶颈的方法可以是在GPU中加入线程控制机能,用来安排指令优先级和打包指令使其提高执行效率。
NVIDIA在G80架构中首次在芯片和流处理器(SM)级别都加入了线程管理机能"Thread Scheduler",此后随着图形核心的发展,在Fermi架构上Thread Scheduler进化为"Gigathread Engine",使得并行运算性能进一步得到大幅提高。
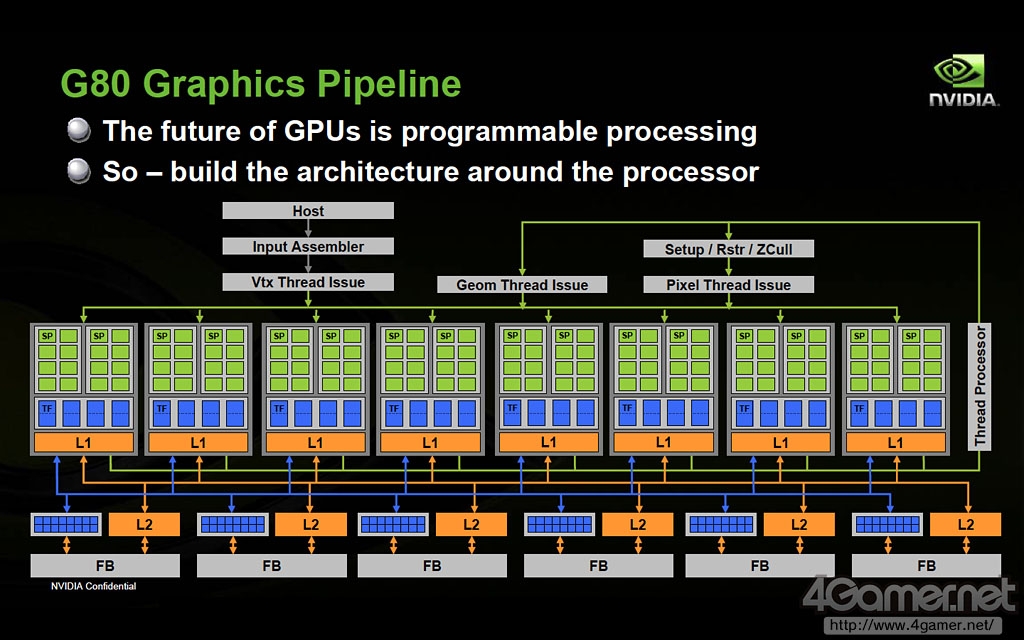
NVIDIA G80核心流水线示意图

NVIDIA GT100(GTX280)核心架构图
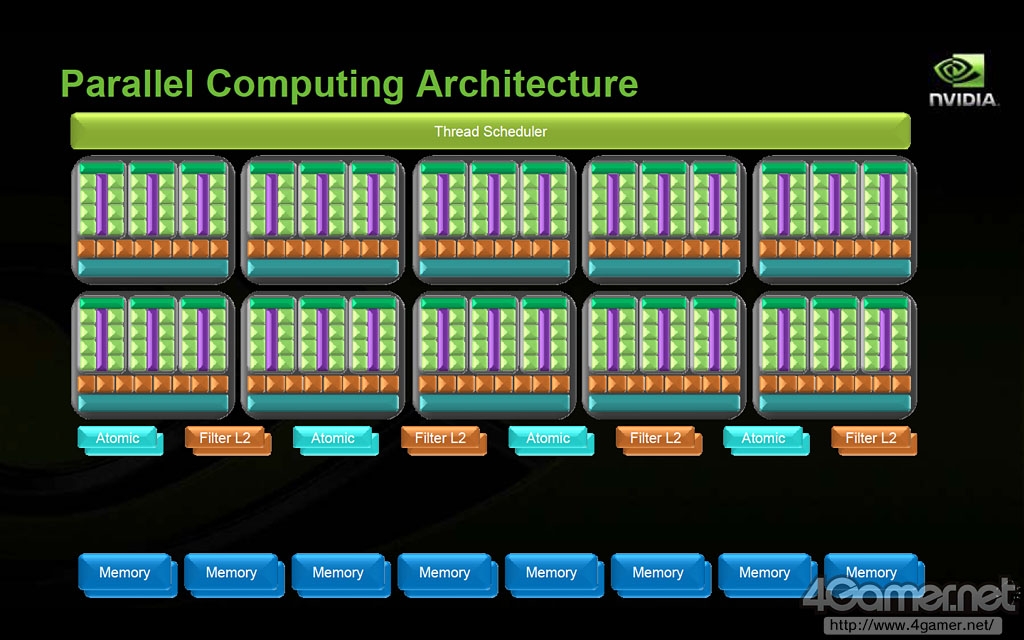
并行计算架构示意图
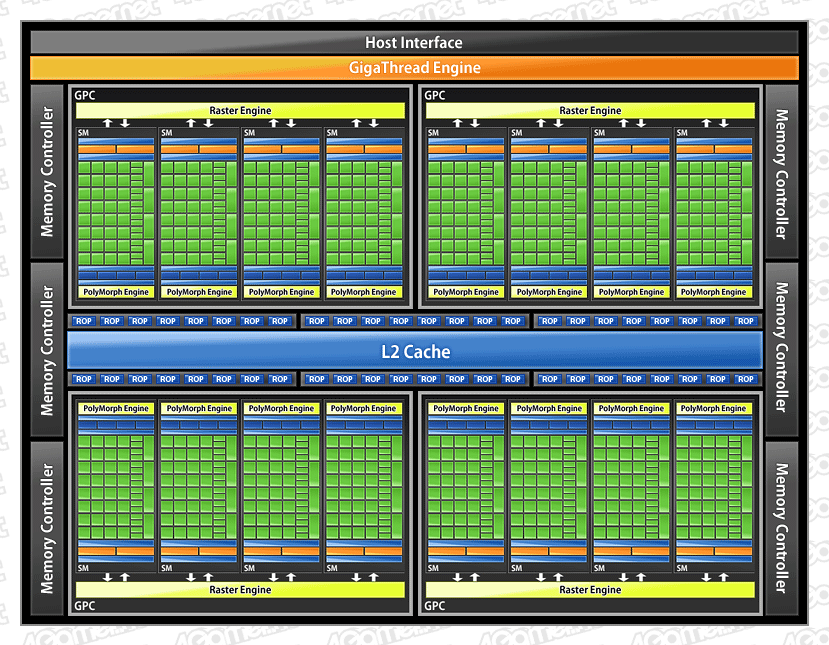
Fermi核心架构图,Thread Scheduler进化为GigaThread Engine
但是,在CUDA Core数量最大已经达到512个的况下,如果再增加势必会给线程管理模块部分带来更高负荷,甚至有发热过高烧毁的危险。因此,为了使GPU的并行计算性能维持优势,需要搭载更加强力的线程控制及管理模块,Project Denver正是为此诞生。
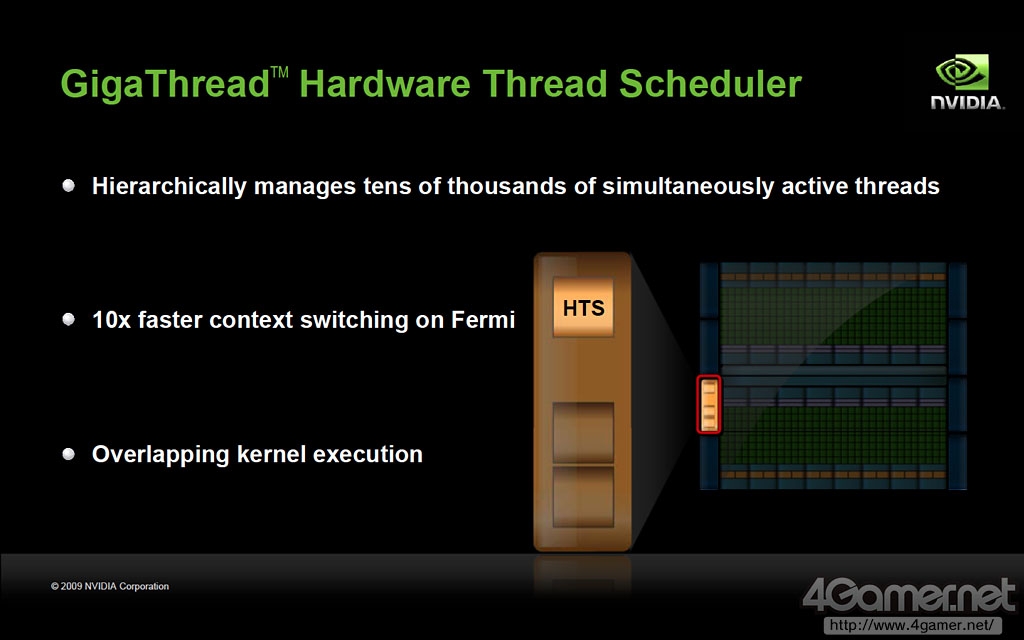
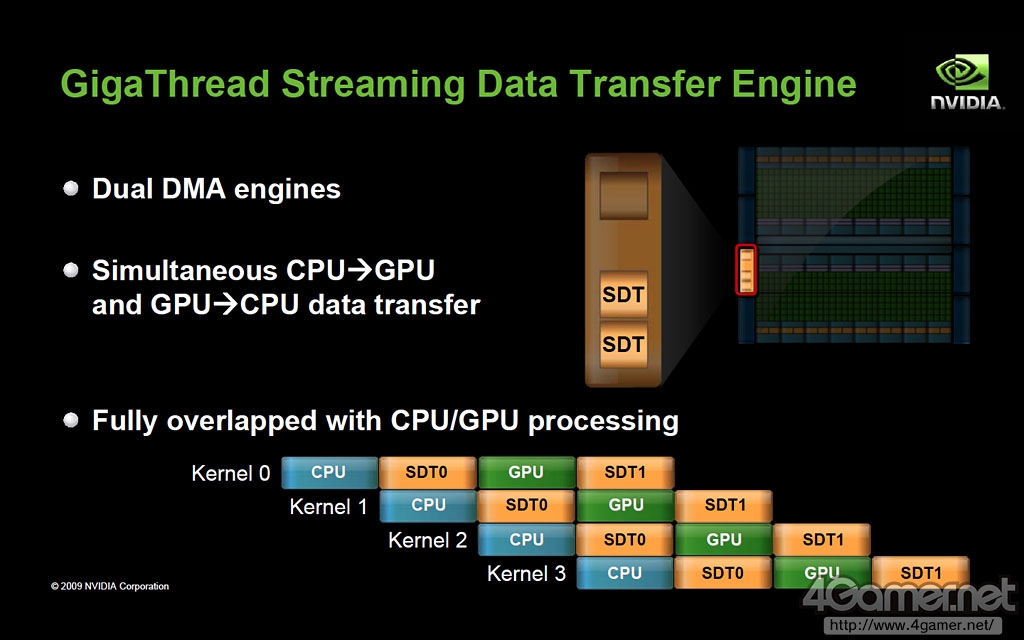
GigaThread Engine介绍,搭载2基硬件级别线程管理DMA引擎
NVIDIA负责产品市场部门的执行副总裁Ujesh Desai确认了Project Denver从三年前就已经开始开发,目标是实现CPU和GPU的统合。

NVIDIA执行副总裁,产品市场部门主管Ujesh Desai
受微软宣布下代操作系统Windows 8将正式支持ARM架构的影响,NVIDIA原本的ARM核心CPU业务范围也将扩大。在3月召开的投资者会议Financial Analyst Day 2011上,NVIDIA总裁兼CEO黄仁勋宣布,Denver的核心将使用未来的Tegra处理器。
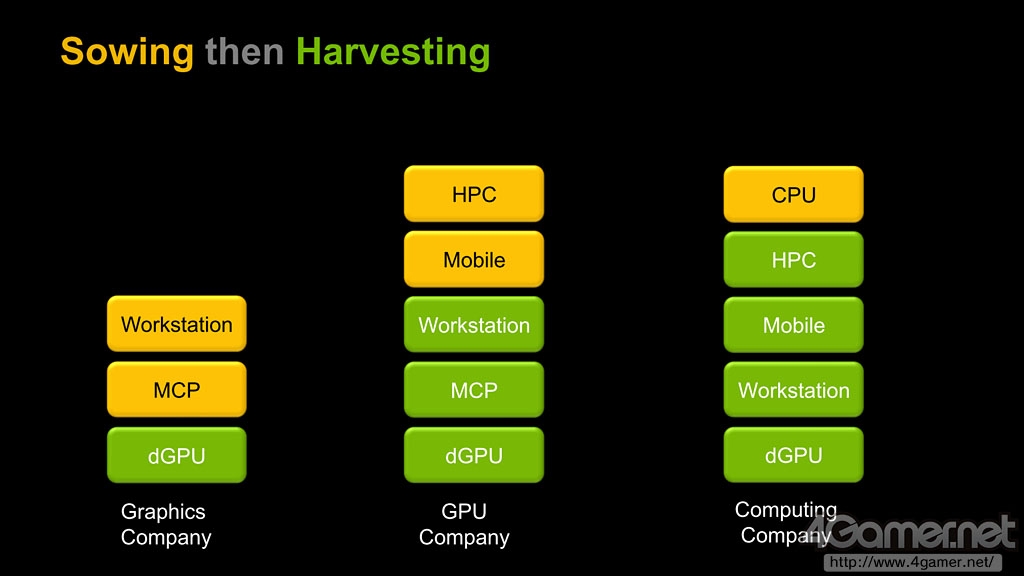
NVIDIA的目标是成为"Computing Company",要实现这一目标CPU业务也是重要的收益来源

2011年5月曝光的Project Denver核心示意图
虽然黄仁勋的说法摆在那里,不过看起来Project Denver和Tegra的关系不是那么简单:NVIDIA移动业务总经理Micheal Rayfield称:“Project Denver和Tegra毫无关系”。他说:“用于移动业务的Tegra最注重目标是省电性能,将不会冒进,沿着ARM提供的Roadmap进行SoC开发。”“Kal-El将是Cortex-A9架构四核处理器,Wayne也自然会沿用下一架构。”表明了Wayne将使用Cortex-A15架构。
同时Desai也从另外一方面验证了上述表态:“Project Denver目标是成为面向HPC(高性能计算)的强力CPU核心,不会像Tegra一样考虑省电。”
本文收录在
#快讯
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...