正文内容 评论(0)

Radeon HD 6900系列终于发布了,不过顶着全新架构的光环,实际性能却并没有很多人想象得那么好。难道真是新架构如此不给力?其实说白了这才是一次真真正正的过渡,AMD以此为试验品,正在为未来做着新的准备。
要理解AMD为什么使用VLIW4 4D式流处理器架构设计,首先必须理解AMD为什么使用VLIW5 5D式流处理器架构设计,而要回答后边这个问题,又必须回到更遥远的DX9时代,种子早在那个时候就已经埋下。
VLIW:超长指令字(Very long instruction word),指的是一种被设计为可以利用指令级并行(ILP)优势的体系结构。一个按照顺序执行指令的非超标量处理器不能充分利用处理器的资源,有可能导致低性能。
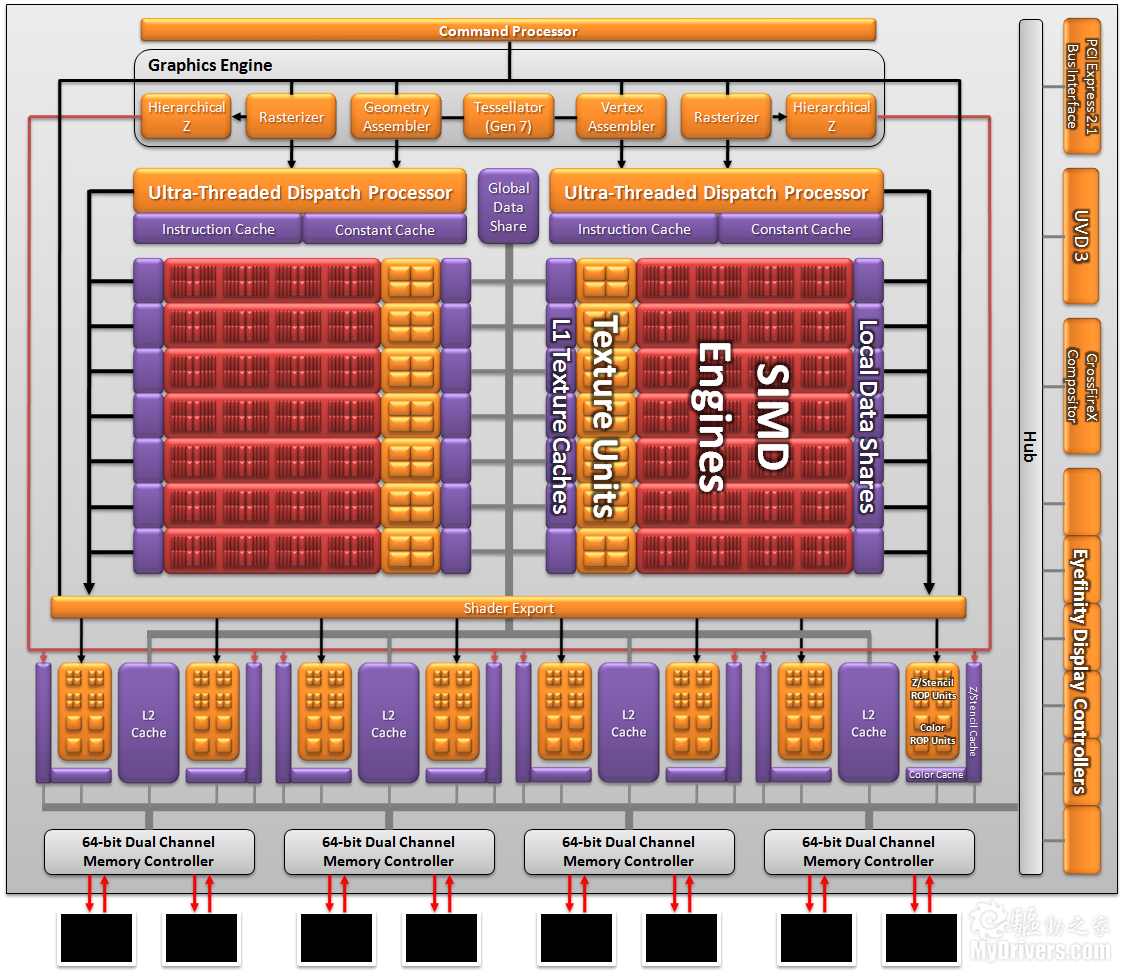
Barts Radeon HD 6800架构图(Cypress 5800类似)
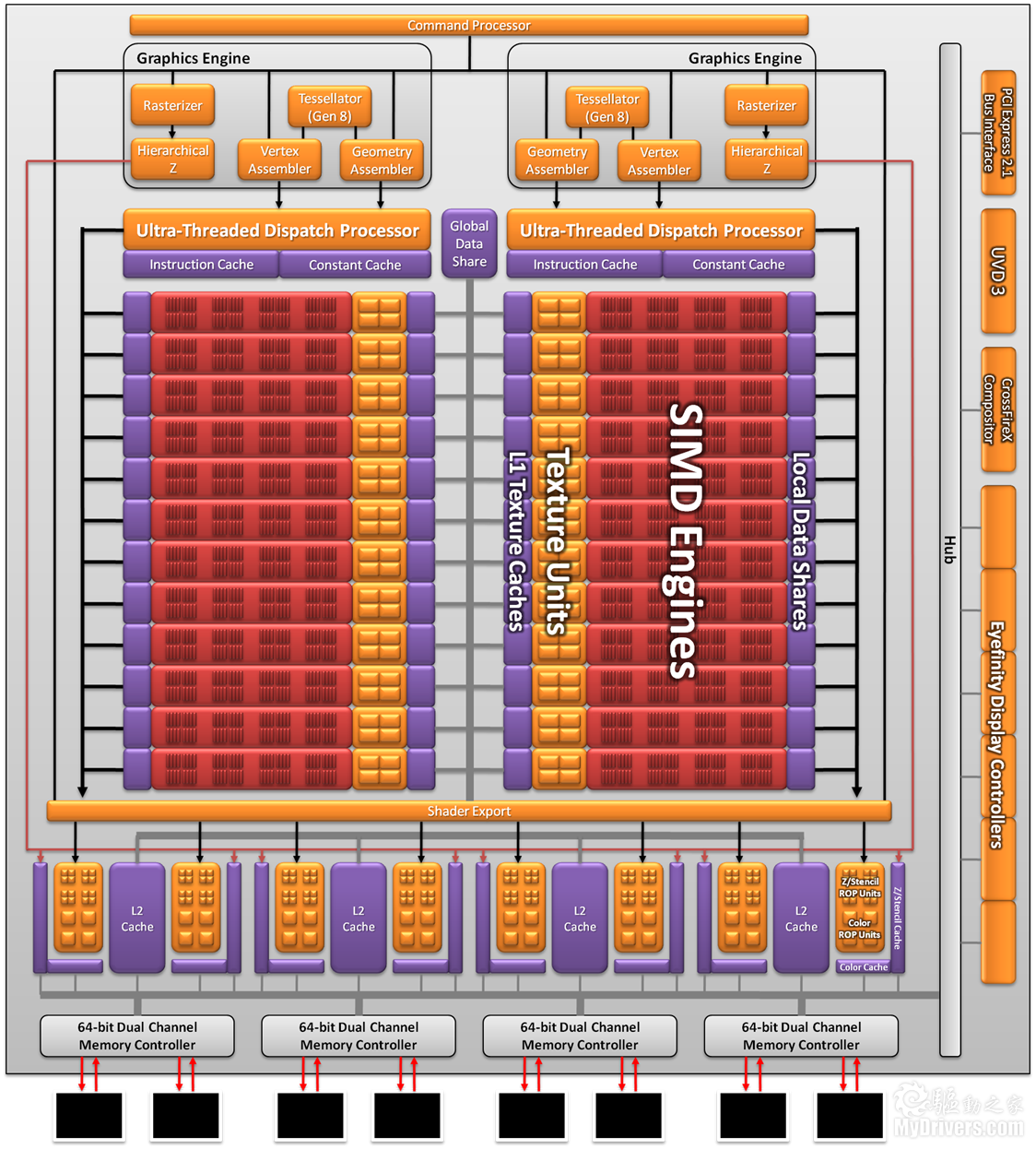
Cayman Radeon HD 6900架构图
想当年着色技术还是新鲜事物,像素和顶点着色器仍是独立的。曾经的ATI为他们的顶点着色器选择了VILW5设计,因为ATI根据自己的数据得出结论,认为这是顶点着色器区块的最佳配置,能同时处理一个四分量点积(比如w、x、y、z)和一个标量分量(比如光照)。
2007年,ATI发布了R600架构的Radeon HD 2000系列,也是自己在PC领域首次引入统一着色架构,而且又一次使用了VLIW5。尽管这是DX10产品,但仍能很好地处理DX9顶点着色。GPGPU通用计算普及之前,这种架构适应得很好。

接下来进入2008年。显卡厂商在规划产品的时候一般都要考虑到两年之后乃至更久的情况,所以Cayman Radeon HD 6900系列的设计那时候就已经着手了。当时GPGPU通用计算才刚刚起步,NVIDIA开始追逐的那个市场最多价值几百万美元,DX10游戏也还没有成型,但是AMD预测认为,通用计算将在两年后(也就是现在)变得非常重要,DX9也会基本让路给DX10/11,所以就必须提前重新评估VLIW5设计的优劣。
果不其然,GPGPU通用计算已经开始大行其道,Windows 7、DX10/11也正在将DX9挤下历史舞台。根据AMD的内部数据,VLIW5架构的五个处理槽中平均只能用到3.4个,也就是在游戏里会有一个半白白浪费了。显然,DX9下非常理想的VLIW5设计已经过时,它太宽了,必须缩短流处理器单元(SPU),重新设计里边的流处理器(SP)布局。
AMD的显卡核心架构非常依赖指令级并行运算(ILP),也就是将指令放在单独一个线程内,和其他可以并行的线程没有任何关联。VLIW5下最理想的情况就是五个指令能够在每个时钟周期里、每个SPU上一起调度执行,但这种概率非常低。按说平均使用3.4个已经不错了,但换算下来还是不足80%,结果就是从工作负载种提取ILP非常困难,导致最好、最坏应用环境相差太多。
与之形成鲜明对比的是线程级并行计算(TLP),那些没有任何关联的线程也可以同时执行。这正是NVIDIA在高端核心上所依赖的设计理念,GF100/GF110都是借助TLP达到高效率的标量架构。
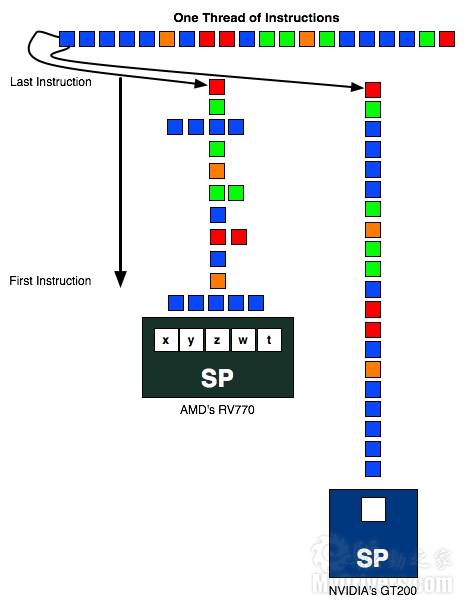
最终,AMD意识到VLIW5架构已经不适合继续发展,必须面向未来准备一种新的高效率架构,不但要提高平均使用率(大于3.4个),还需要适应并行计算负载,结果就是转向VLIW4。
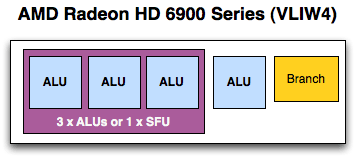
VLIW4相比于VLIW5最特殊的地方就是去掉了体积最大、可同时处理普通整数/浮点操作和超越操作的第五个SP t单元,或者说特殊功能单元(SFU)。这就意味着,每个SPU可以一次性处理的普通整数/浮点操作数从五个减少到四个,同时还可以将三个SP合并起来处理一个超越操作。
这种变化的好处有很多。并行计算方面最明显的就是此前用于特殊单元的内核面积可以节省出来安置更多SIMD引擎,比如Cypress Radeon HD 5800 20个,Cayman Radeon HD 6900就增加到了24个,平均下来后者的着色器区块效率要高10%。与此同时,纹理单元的数量、可以并行执行的线程数量、每个时钟周期可以执行的64位浮点操作数量都随之发生了变化,特别是后者使得AMD GPU的64位双精度运算能力达到了32位单精度浮点的四分之一(以往是五分之一)——事实上单个流处理器单元的计算能力并没有变化,只不过布局的重新设计使得彼此工作的效率更高了。

SP变化的同时,寄存器文件却没动,于是每个SPU的寄存器所承受的压力更小了,因为现在只有四个SP争夺寄存器空间。调度也更简单了,因为需要调度的SP更少,而且彼此完全相同,不需要考虑w/x/y/z单元和t单元的差别。
游戏方面的改善也类似。已经习惯了VLIW5架构的游戏有了更多SIMD引擎可以使用,意味着纹理处理能力更强,计算/纹理的比例也因此降低,有利于那些侧重于纹理和过滤而不是计算的游戏。
当然,任何架构上的变化都会有所牺牲,VLIW4也不例外。对游戏来说,Radeon HD 6900将不再像以前那么好地处理VLIW5型的顶点着色器。一般来说这种游戏都已经很快了,但是如果一开始就受到GPU能力的限制(即显卡是瓶颈),Radeon HD 6900系列就跑不多快。另一大损失就是当超越操作和矢量操作配对的时候,Radeon HD 6800可以每时钟周期处理两个,Radeon HD 6900就需要两个时钟周期。AMD认为这种情况很少见,损失也是值得的。
值得一提的是,AMD仍然认为VLIW4是一种风险性的试验设计,Radeon HD 6900也更像是一个试验品。此时此刻,AMD应该早已完成了真正的试验,正在设计采用28nm工艺的后续新核心,是否继续采用VLIW4也肯定有定论了。
最后,核心架构的变化必然牵涉到驱动程序的转变与配合。坏消息是,很多针对VLIW5架构设计的着色器编译器都没用了,因此初期阶段着色器编译器性能会变差一些。好消息是,随着时间的过去,AMD会逐渐掌握更好地为VLIW4设计编程,Radeon HD 6900系列也有希望在以后的日子里获得性能上的大幅提升(注意只是可能)。
随着VLIW的缩短,部分代码重新编写是必然的了,AMD的着色器编译器也要经历一个代码优化的过程,但如果内核本身就是专为VLIW5而设计的,AMD的编译器就无能为力了。
顺附两种架构可执行操作的对比:
VLIW5:
4 32-bit FP MAD
或者2 64-bit FP MUL/ADD
或者1 64-bit FP MAD
或者4 24-bit Int MUL/ADD
加上1 transcendental或者1 32-bit FP MAD
VLIW4:
4 32-bit FP MAD/MUL/ADD
或者2 64-bit FP ADD
或者1 64-bit FP MAD/FMA/MUL
或者4 24-bit INT MAD/MUL/ADD
或者4 32-bit INT ADD/Bitwise
或者1 32-bit MAD/MUL
或者1 64-bit ADD
或者1 transcendental加上1 32-bit FP MAD
本文收录在
#快讯
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...