正文内容 评论(0)


K10和K20的特性有所不同,重点也不一样
首先来看K10,它的物理外观与GTX 690显卡没什么区别,但是NVIDIA公布的几项参数耐人寻味,单精度浮点能力为4.58TFLOPS,带宽为320GB/s,作为对比的是GTX 680单精度运算能力3.09TFLOPS,192GB/s带宽,而GTX 690也有5.62TFLOPS,384GB/s带宽,上一代Fermi核心浮点运算能力为1.58TFLOPS,带宽192GB/s。
从参数上看,K10达到了NVIDIA所说的三倍于Fermi家族的单精度浮点能力,但是比GTX 680只提高了50%,带宽也只高了了67%左右,明显不如GTX 690显卡。
由于是同样的架构,Tesla K10很明显在核心和显存频率上做了妥协,由于GK104架构的能效比很高,而HPC领域对功耗、发热也不甚敏感,不知NVIDIA为何将K10的规格定的比GTX 690还低。
现场的图片没有公布K10的显存容量和TDP信息,但是GeForce GRID页面出现的K520显卡规格与K10一致,而显存容量是8GB,TDP是250W,二者其实都是双芯GK104显卡,因此Tesla K10也是8GB显存,250W TDP。(这个功耗低于GTX 690的300W,或许是规格降低唯一可能的解释了)
Tesla K10现在就可以出货,但是它并不是重点,个人觉得它只是个过渡产品,扮演救火队员的角色,因为GK104先天孱弱的双精度运算能力注定了它不可能在HPC市场有多高的成就,NVIDIA之所以推GTX 690上阵是因为GK110架构来的比预期的还要晚。
GK110是NVIDIA针对高性能GPU计算市场开发的架构,之前一直传闻到今年8月份就会发布,但是NVIDIA给出的日期是今年第四季度,不论是28nm产能还是芯片自身的问题,这大半年的空白期总需要有人先顶上,这就是K10的使命了。
Tesla K20与GK110架构
NVIDIA对K20的描述是“3倍双精度浮点性能”,并有Hyper-Q、Dynamic Parallelism等多种并行计算技术加持,这些是现有的GK104架构不具备的。

NVIDIA的PDF资料中介绍了GK110的SMX架构,也是192个CUDA核心
必须要承认,以前泄露的有关GK110架构的消息是错误的,GK110的SMX架构其实跟GK104还是一样的,都是192个CUDA核心,32组SFU单元以及32个LD/ST单元。
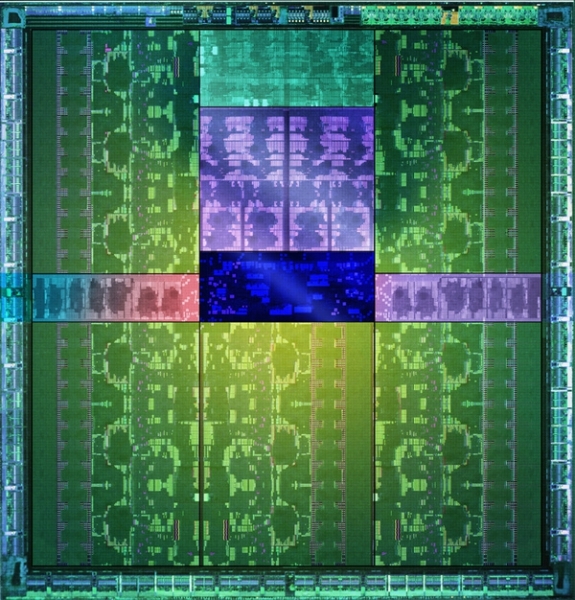
GK110架构图
除去其他的功能单元之外,GK110核心总共有15组SMX单元,2880个CUDA核心,但是Heise声称并非所有单元都是启用的,实际上可能只有13-14组SMX单元,实际CUDA核心是2496或者2688个。
显存位宽是384bit,已为黄仁勋和NVIDIA CTO确认。由于CUDA核心数已经低于之前的报道,显存位宽降到384bit也是很自然的事,如果保持GK104的6Gbps显存速率,那么GK110的带宽将达到288GB/s,终于超过AMD GCN架构的260GB/s了。
NVIDIA给出的3倍双精度浮点性能不知是跟GF110显卡还是跟GF110核心的Tesla加速卡做的比较,GF110的单精度浮点能力为1.58TFLOPS,显卡中的双精度为单精度的1/4,也就是0.4TFLOPS,但是GF110核心的Tesla卡双精度能力可达单精度1/2,大约是0.8TFLOPS。
如此一来,如果以显卡为基础,GK110的双精度浮点性能大约是1.2TFLOPS以上,如果是Tesla卡的3倍,那就是2.4TFLOPS以上,鉴于后者已经超出之前传闻的2TFLOPS的能力,GK110的双精度浮点能力应该是1.2TFLOPS或更高。

Tesla K20配置了6pin+8pin供电接口
核心面积和TDP未知,不过K20配备的是6pin和8pin供电接口,最大TDP不会超过300W。晶体管数量也是一个70亿,准确点说是71亿。
本文收录在
#NVIDIA
- 热门文章
- 换一波
- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...