正文内容 评论(0)

HD6970昙花一现:北方群岛5D改4D返璞归真
相信有些读者很早就想问这样一个问题了:既然图形渲染的主要指令是4D矢量格式,那为什么R600要设计成5D的流处理器结构呢?还沿用了5代之久?有结果就有原因,通过对Cayman核心的分析,我们可以找到答案。
R600为什么是5D VLIW结构?
在5D VLIW流处理器中,其中的1个比较“胖”的ALU有别于其它4个对等的ALU,它负责执行特殊功能(例如三角函数)。而另外4个ALU可以执行普通的加、乘、乘加或融合指令。

Barts核心的流处理器结构
从R600开始的Shader是4D+1D的非对等设计,ATI这样做的目的是为了让顶点着色器更有效率,以便能同时处理一个4D矢量点积(比如w、x、y、z)和一个标量分量(比如光照)。
Cayman核心返璞归真,改用4D结构
随着DX10及DX11大行其道,AMD通过自己长期内部测试发现,VLIW5架构的五个处理槽中平均只能用到3.4个,也就是在游戏里会有1.6个白白 浪费了。显然,DX9下非常理想的VLIW5设计已经过时,它太宽了,必须缩短流处理器单元(SPU),重新设计里边的流处理器(SP)布局。
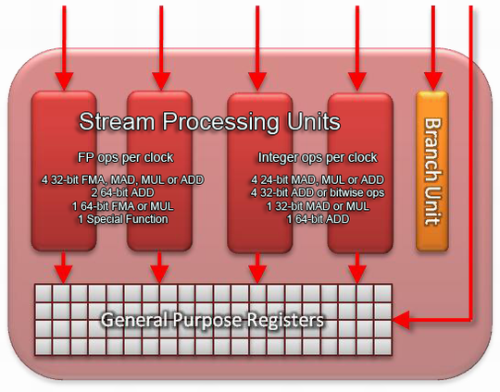
Cayman核心的流处理器结构
于是Cayman核心诞生了,胖ALU下岗,只保留了剩下4个对等的全功能ALU。裁员归裁员,原来胖ALU的工作还得有人干,Cayman的4D架构在执行特殊功能指令时,需要占用3个ALU同时运算。
5D改4D之后最大的改进就是,去掉了体积最大的ALU,原本属于它的晶体管可以用来安放更多的SIMD引擎,据AMD官方称流处理器单元的性能/面积比 可以提升10%。而且现在是4个ALU共享1个指令发射端口,指令派发压力骤减,执行效率提升。双精度浮点运算能力也从原来单精度的1/5提高到了1 /4。
效率更进一步:双图形引擎
前面介绍过,从RV770到Cypress核心,图形引擎和超线程分配处理器都只有一个,但图形引擎内部的Hierarchical Z(分层消影器)和Rasterizer(光栅器)分为两份。
到了Barts核心,超线程分配处理器从一个变成两个。现在的Cayman核心则更进一步,图形引擎也变成了两个,也就是除了分层消影器和光栅器外,几何着色指令分配器、顶点着色指令分配器、还有曲面细分单元都变成了两份:
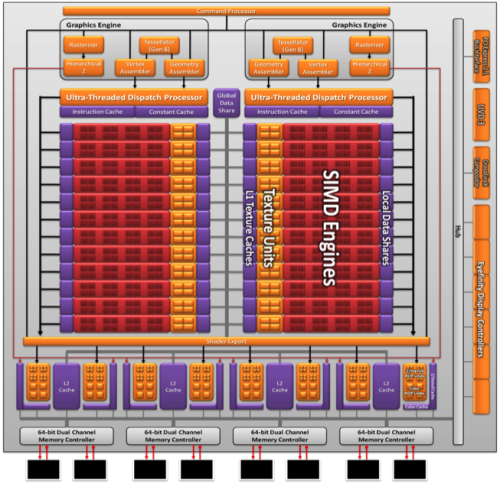
两个曲面细分单元再加上两个超线程分配处理器,AMD官方称HD6970的曲面细分性能可以达到HD6870的两倍、HD5870的三倍。其它方面比如顶点着色、几何着色性能都会有显著的提升。
通用计算效能也有改进
和Cypress、Barts相比,Cayman在通用计算方面也有一定程度的改进,主要体现在具备了一定程度的多路并行执行能力;双路DMA引擎可以同 时透过外部总线和本地显存读写数据;改进的流控制提高了指令执行效率和运算单元浪费;当然双精度运算能力的提高对于科学计算也大有裨益。
不过,这些改进都是治标不治本,VLIW架构从5D到4D只是一小步,只能一定程度上的提高指令执行效率,而无法根治GPU编程困难、复杂指令和条件指令 的兼容性问题。总的来说,Cayman核心依然只是单纯为游戏而设计的GPU,AMD把5D改为4D也是基于提升3D渲染性能的考虑。
本文收录在
#快讯
- 热门文章
- 换一波

- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...