正文内容 评论(0)


借助单颗 GPU,GPU 技术实现的速度提升可比传统 CPU 高出几个数量级。如果在工作站或计算节点上插入两颗或四颗 GPU,那么其运算应用或游戏的性能可分别翻一番和翻两番。在一个系统中,主处理器的多核功能与 GPU 的协同作用可使性能提升更多。
虽然这一点非常诱人,但多 GPU 和混合型 CPU+GPU 的性能在很大程度上依赖于供应商计算机主板上的 PCIe 总线装置。留心供应商会在 PCIe 总线上偷工减料! 配备了合适的 PCIe 芯片组,multiGPU 应用可以根据系统中 GPU 的数量相应地提高性能。如果系统内的芯片组不恰当,在 multiGPU 上的投资就不会有成效。为什么要浪费资金? 确保 PCIe 芯片组能令您的 GPU 实现所有的性能!
英伟达最近发布的 CUDA 4.0 包含了一系列特性,能简化工作站或计算节点内多 GPU 的使用。爱尔兰高端计算中心 (ICHEC) phiGEMM 库利用 CUDA 4.0 特性实现了同时使用多 GPU 和主处理器的矩阵乘法计算。phiGEMM 的性能提升非常显著,单个 GPU + CPU 的性能与 Linpack HPL 矩阵乘法相等,后者用于评估世界前 500 强超级计算机。在四个 GPU 和一个主处理器之间运行单个矩阵乘法时,phiGEMM 可实现超过1万亿次浮点/秒 (10710 亿次浮点/秒) 的双精度矩阵乘法计算,其所在矩阵比任何一个 GPU 的内存都要大!
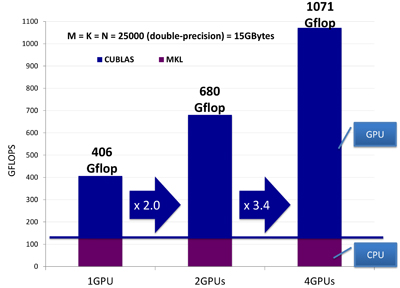
图片 1 展示了对于一个 25000 x 25000 矩阵所实现的性能,两个 2.93 GHz Intel X5670 处理器 12 个核心的运算速度可稳定在 1300 亿次浮点/秒。在没有 Intel 核心带来性能提升的情况下,4 颗英伟达 GPU 性能可达 9420 亿次 64 位浮点运算/秒。换言之,相比单个 CPU,4 核 GPU 的性能提高了 3.4 倍。phiGEMM 库支持免费下载。1
性能不良的 PCIe 总线芯片组造成的影响非常显著。例如,同样的 phiGEMM 矩阵乘法在共用 PCIe 总线上会慢 17%,因为传送数据用的时间会更长。也就是说,每个 GPU 由于共用总线而只得到一半数据带宽。矩阵乘法是展现多 GPU 性能的良好平台,因为随着矩阵规模的增加,运行时间会受限于浮点性能而非数据传送。
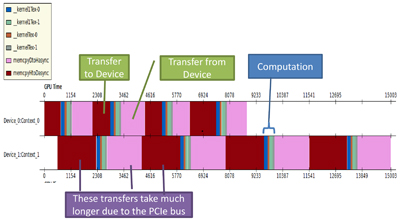
很多供应商宣称他们的系统支持多高速 x16 PCIe 插槽,这在某些性能假设下是符合事实的。为节省资金,某些供应商使用只在一个设备激活时才能实现全部性能的 PCIe 芯片组。图片 2,摘自我的书《CUDA Application Design and Development》,2 说明了某些 PCIe 装置会区分对待多个 GPU 中的某一个。从英伟达 Visual Profiler 的图形输出上可以看到,粉色和红色区域表示数据传输在第二个设备 Device_1:Context_1 上用的时间显著增长。
英伟达 Visual Profiler 输出显示,在用一条劣质 PCIe 总线连接的多 GPU 之间运行 3-D 快速傅里叶变换 (FFT) 时,性能降低接近 60%。 性能之所以有如此显著的下降,是因为相比矩阵乘法,快速傅里叶变换每传送一个数据所进行的计算量要少。更少的计算量意味着相比计算吞吐量数据传输速度对应用的制约更明显。
性能不良的 PCIe 总线对这类应用运行时间的影响更加大。性能下降 60% 意义重大,因为这能抵消多 GPU 带来的优势。Thrust C++ 数据并行应用程序接口在 CUDA 4.0 版中为标准配置。3 借助类属编程和仿函数 (类似于函数的 C++ 对象),可编写 C++ 应用,在 CUDA 矢量和阵列中以高性能大规模并行方式运行。 Thrust 令 CUDA 编程变得简单,因为任何懂得 C++ 的人已经知道如何为 GPU 编写程序。
从 multiGPU 和混合型 CPU + GPU 编程的角度看比较值得关注的是,Thrust 可产生既能在多核处理器上又能在 GPU 上运行的代码! 提供了两个分类符 “__device__ __host__”。这告诉编译器为仿函数产生既能在主机上又能在 GPU 设备上运行的代码。我使用 Thrust 功能编写的应用可利用一个工作站内所有可用的计算资源。
对于这些应用,我喜欢使用基于主机的仿函数和 OpenMP (Open MultiProcessing) 指令明确指定主处理器的并行性。 作为一种应用程序接口,OpenMP 可被大多数编译器支持,可用来创建支持多核处理器的并行应用。注意基于 Thrust 的应用可被透明编译,因而可全部在主多核处理器上运行。无需变更代码! 相反,恰当地定义了一个特殊变量 “THRUST_DEVICE_BACKEND”以指明一个 OpenMP 后端。 Thrust 的编写方式是,编译器产生的代码能在主多核处理器上并行运行而无需 GPU。关于更多信息请访问 Thrust 网站。3
使用 MPI 接口的程序员可使用该基于 Thrust 的功能创建分布式应用,在系统每个 GPU 和主处理器上运行一个单独的 MPI 过程。注意,分布式应用也可在很大程度上使用 PCIe 总线,也可像前面讨论过的 multiGPU 那样暴露供应商 PCIe 装置的缺点。
所有这些信息都指向一个简单、易懂的解决方案:从供应商那里购买性能良好的 PCIe 总线。寻找完全支持向多 GPU 传送数据的高性能 PCIe 总线。即使您的应用暂时用不到多 GPU,也要为潜在的应用设想。可以通过添加额外的 GPU 把性能提升二到四倍。
对于那些运行计算集群的人,性能欠佳的 PCIe 总线会对性能产生负面影响。使用 phiGEMM 库、我列举的快速傅里叶变换或您自己的多 GPU 示例进行的基准测试都应立即暴露出任何问题。不要依赖衡量 PCIe 到单个设备的带宽的结果。只有同时使用多个设备的基准测试才会暴露 PCIe 装置的缺陷。
祝您使用 multiGPU 计算愉快!
本文收录在
#快讯
- 热门文章
- 换一波

- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...