正文内容 评论(0)

2010年财务分析师大会上,AMD不但公布了2010-2012年间的全方位发展路线图,还由公司高级院士Chuck Moore进一步介绍了Fusion APU融合理念。经过四个步骤的发展,Fusion APU将把CPU、GPU从架构底层彻底融合在一起,而不再是简单的物理芯片整合。
后边你还会看到AMD放出的一批Fusion APU高清实物图,这是我们第一次超近距离毫发毕现地欣赏它。

Fusion APU的第一个任务就是消除现有平台上各部分之间的互连瓶颈。北桥模块和内存控制器都已经集成在CPU内部,但是二者之间、内存控制器与内存之间的带宽都只有17GB/s左右,北桥模块与GPU集成显卡之间的带宽更是仅仅7GB/s左右,已经成为瓶颈,特别是集成显卡与内存通信时需要绕道北桥部分。
Fusion APU将它们全部整合到一块硅片之中后,带宽就不是问题了,GPU图形阵列、UVD解码引擎与北桥模块、内存控制器之间的同道高达27GB/s左右,内存控制器和内存之间同样有27GB/s之多。
如此一来,GPU与内存之间也可以直接通信,带宽增加了三倍,即使是同等规模的GPU也能获得执行效率上的显著提高,而且跨芯片通信所需的额外延迟和功耗不复存在,整体封装面积也更加小巧。
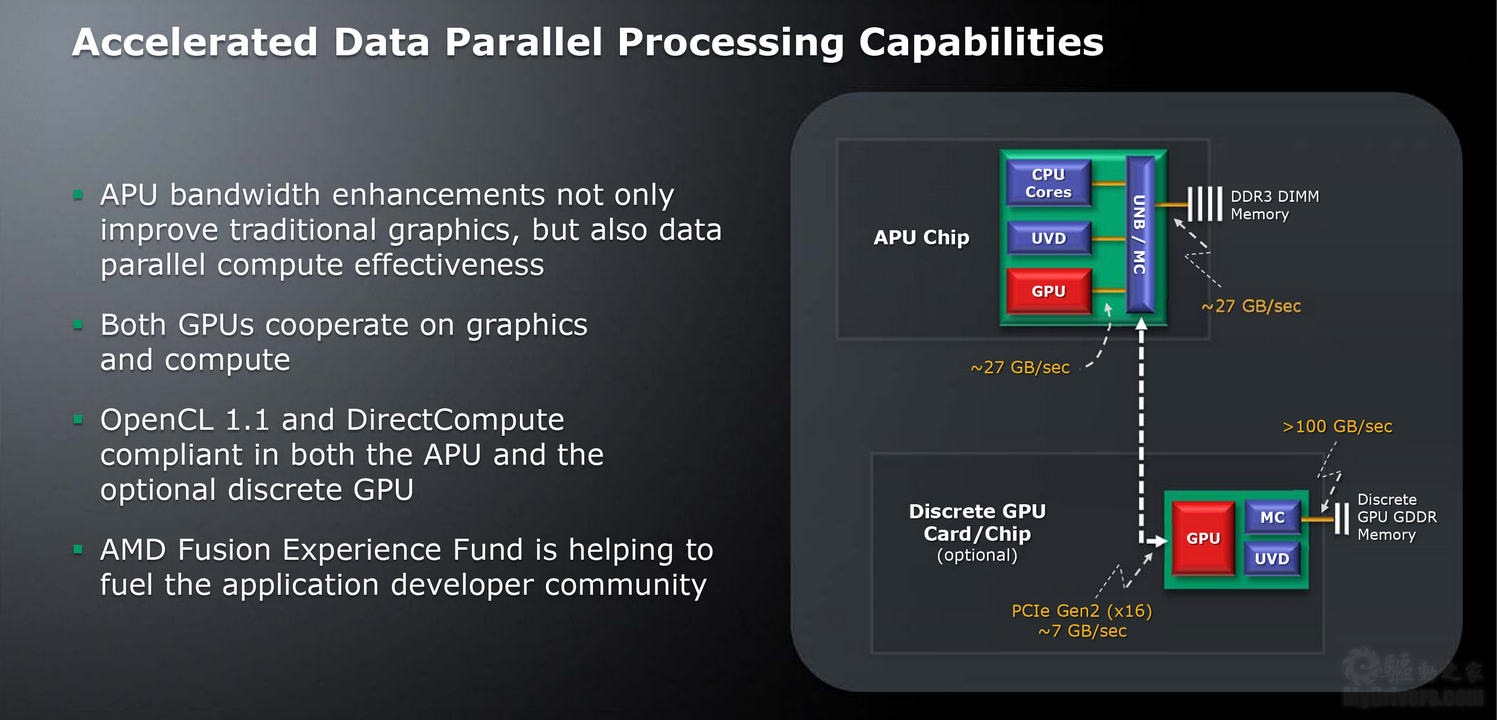
而且Fusion APU并不排斥独立显卡,还可以通过PCI-E 2.0 x16高速总线与其相连。整合的、独立的GPU可以同时进行图形渲染、并行计算,都支持OpenCL 1.1、DirectCompute等并行计算标准。
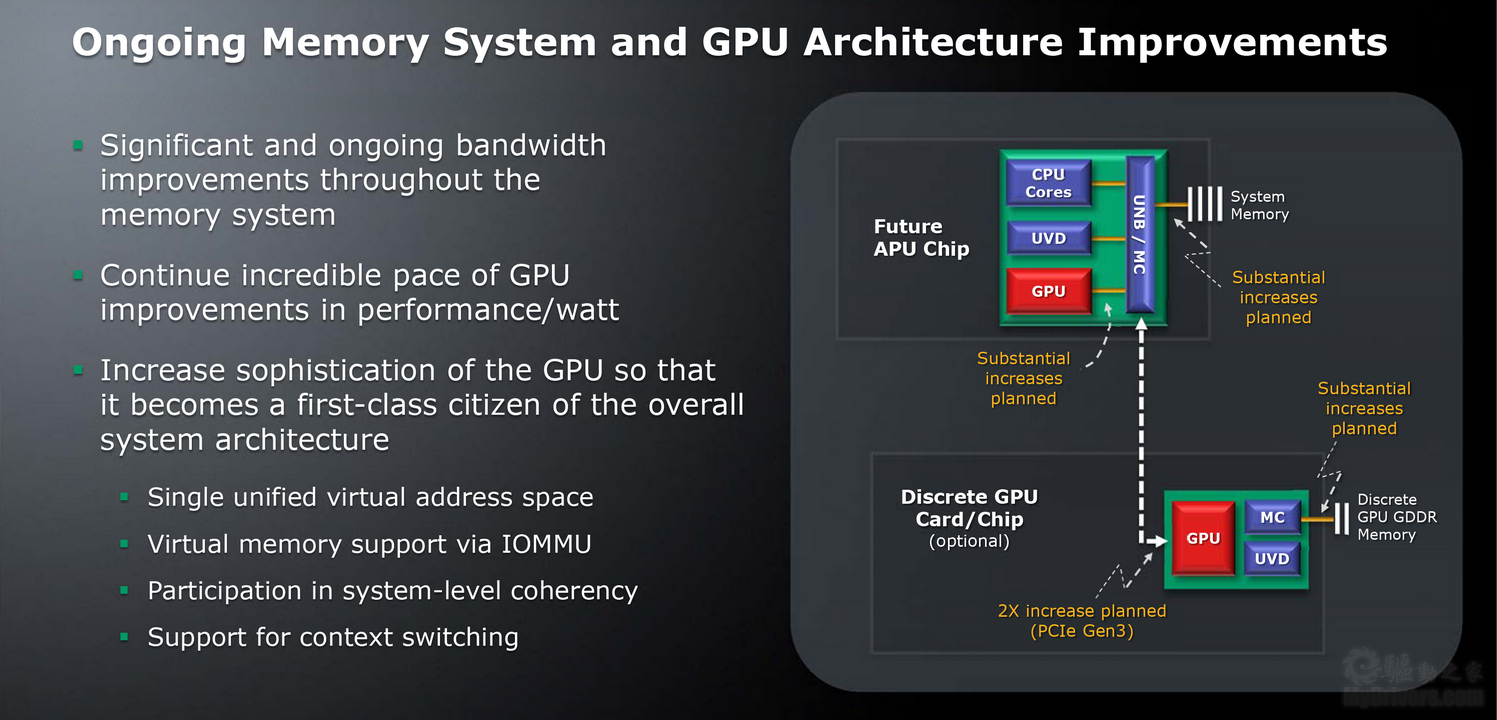
下一步,AMD还会继续全面提升系统互连带宽,包括整合GPU与北桥、内存控制器之间、内存控制器与内存之间、APU与显卡之间、显卡与显存之间,特别是独立显卡将建立在第三代PCI-E 3.0总线基础上,理论带宽翻番。

这就是Fusion APU的四步走策略:第一步“物理整合”(Physical Integration),CPU、GPU集成在一块硅芯片上,辅以高带宽集成内存控制器,再借助开放的软件生态系统促成异构计算。
第二步“平台优化”(Optimized Platforms),CPU、GPU之间互连接口继续增强,并且统一进行双向电源管理,GPU也支持高级编程语言。
第三步“架构整合”(Architectural Integration),实现统一的CPU/GPU寻址空间、GPU使用可分页系统内存、GPU硬件调度器、CPU/GPU/APU一致性内存等等。这才是AMD心目中真正的融合,CPU/GPU真正融为一体。
第四步“架构和系统整合”(Architectural & OS Integration),主要特点包括GPU计算上下文切换、GPU图形优先、独立显卡PCI-E一致性、任务并行运行时整合等等。
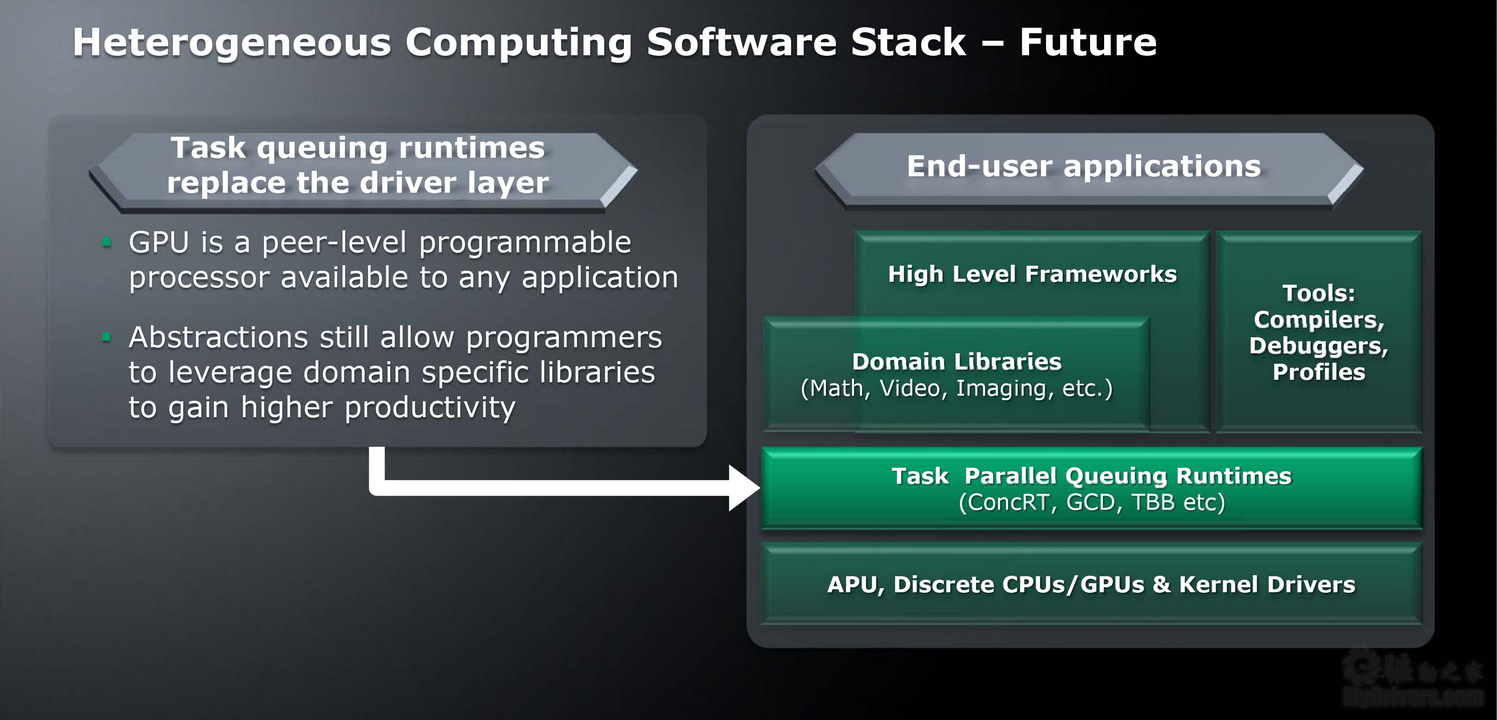
硬件上的这种异构计算融合自然也需要软件生态系统的支持才能发挥威力。根据AMD的设想,驱动层将被任务队列运行时所取代,GPU成为一个对等的可编程处理器,向任何应用程序开放,并且依然允许程序员调用特定领域库来获得更高的效率,诸如ConcRT、GCD、TBB等等。
唠叨了半天都累了,下边开始轻松的图赏时间。
本文收录在
#快讯
- 热门文章
- 换一波

- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...