正文内容 评论(0)

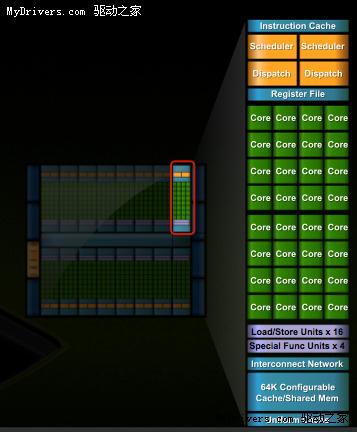
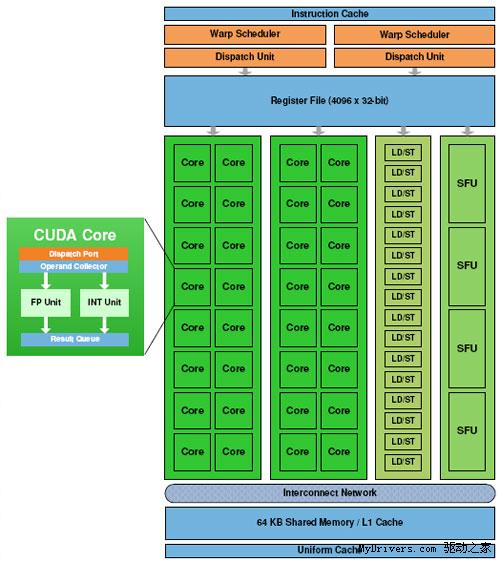
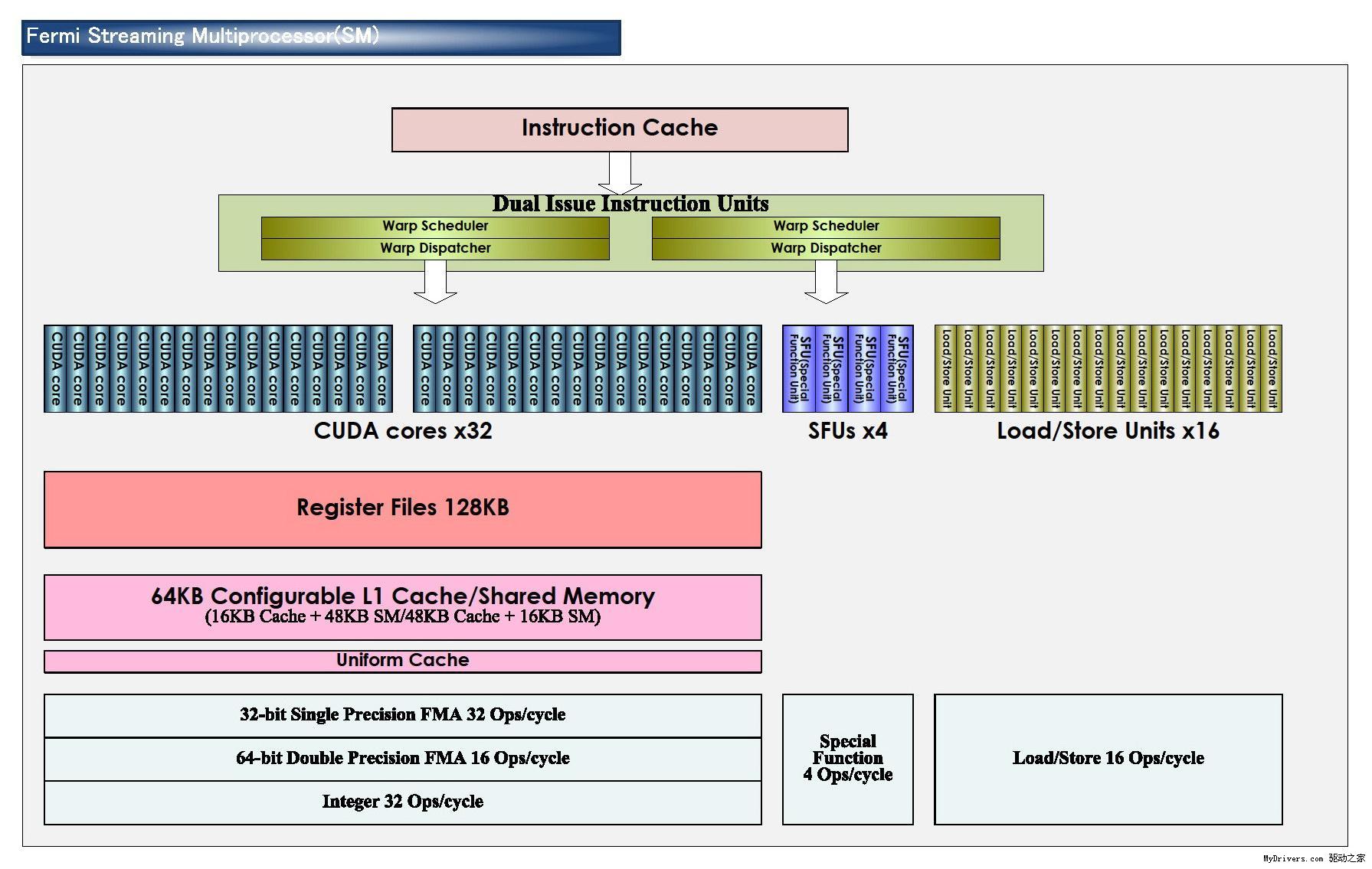
G80/GT200都是8个流处理器构成一组SM(Streaming Multiprocessor),Fermi增加到了32个,最多16组,少于GT200的30组,但流处理器总量从240个增至512个,是G80的整整四倍。
除了流处理器,每组SM还有4个特殊功能单元(Special Function UnitSFU),用于执行抽象数学和插值计算,G80/GT200均为2个。同时MUL已被删掉,所以不会再有单/双指令执行计算率了。
至于SM之上的纹理处理器群(Texture Processor Cluster/TPC),NVIDIA暂时没有披露具体组成方式,而且ROP单元、纹理/像素填充率等其它图形指标也未公布。
2、缓存
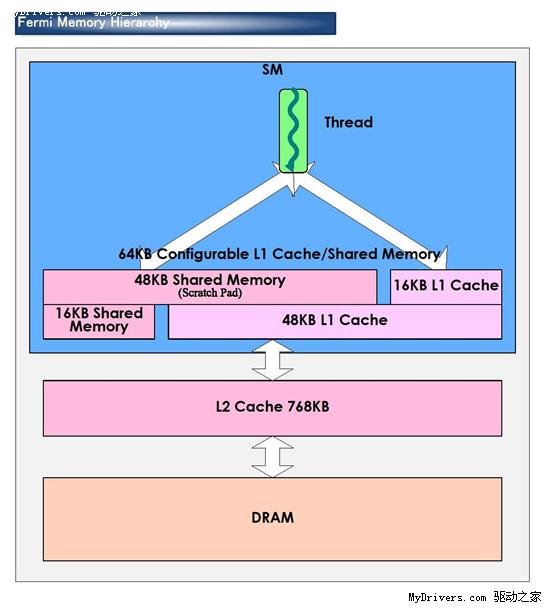
GT200的每组SM都有16KB共享内存,由其中8个SP使用。注意它们不是缓存(cache),而是软件管理的内存(memory),可以写入、读取数据。为了满足应用程序和通用计算的需要,Fermi引入了真正的缓存,每组SM拥有64KB可配置内存(合计1MB),可分成16KB共享内存加48KB一级缓存,或者48KB共享内存加16KB一级缓存,可灵活满足不同类型程序的需要。
GT200的每组TPC还有一个一级纹理缓存,不过当GPU出于计算模式的时候就没什么用了,故而Fermi并未在这方面进行增强。
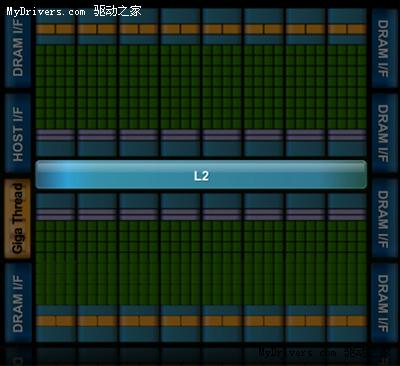
整个芯片拥有一个容量768KB的共享二级缓存,执行原子内存操作(AMO)的时候比GT200快5-20倍。
3、效率
CPU和GPU执行的都是被称作线程的指令流。高端CPU现在每次最多只能执行8个线程(Intel Core i7),而GPU的并行计算能力就强大多了:G80 12288个、GT200 30720个、Fermi 24576个。
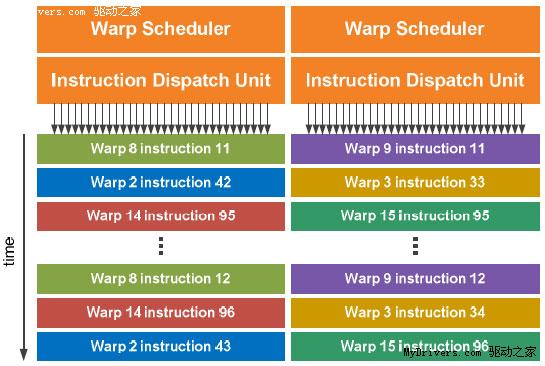
为什么Fermi还不如GT200多?因为NVIDIA发现计算的瓶颈在于共享内存大小,而不是线程数,所以前者从16KB翻两番达到64KB,后者则减少了20%,不过依然是G80的两倍,而且每32个线程构成一组“Warp”。
在G80和GT200上,每个时钟周期只有一半Warp被送至SM,换言之SM需要两个循环才能完整执行32个线程;同时SM分配逻辑和执行硬件紧密联系在一起,向SFU发送线程的时候整个SM都必须等待这些线程执行完毕,严重影响整体效率。
Fermi解决了这个问题,在每个SM前端都有两个Warp调度器和两个独立分配单元,并且和SM其它部分完全独立,均可在一个时钟循环里选择发送一半Warp,而且这些线程可以来自不同的Warp。分配单元和执行硬件之间有一个完整的交叉开关(Crossbar),每个单元都可以像SM内的任何单元分配线程(不过存在一些限制)。
这种线程架构也不是没有缺点,就是要求Warp的每个线程都必须同时执行同样的指令,否则会有部分单元空闲。每组SM每个循环内可以执行的不同操作数:FP32 32个、FP64 16个、INT 32个、SFU 4个、LD/ST 16个。
本文收录在
#快讯
- 热门文章
- 换一波

- 好物推荐
- 换一波
- 关注我们
-

微博:快科技官方
快科技官方微博 -

今日头条:快科技
带来硬件软件、手机数码最快资讯! -

抖音:kkjcn
科技快讯、手机开箱、产品体验、应用推荐...